
基于机器视觉的煤矸石多工况识别研究
2019-02-19 13:01:30窦东阳
煤炭工程 2019年1期
沈 宁,窦东阳,杨 程,张 勇
(1.神华宁煤集团 太西洗煤厂,宁夏 石嘴山 753000;2.中国矿业大学 化工学院,江苏 徐州 221116)
中国能源结构的特点使得煤炭在今后的很长一段时间内依然会是主体消耗能源[1]。对于+50mm的原煤,在分选精煤前,通常需要进行手选矸石操作[2]。手选矸的劳动力强度大、选矸操作面的工作环境恶劣、并且人工分选的效率低。机器视觉技术是一门多学科交叉的综合学科,人类通过视觉获取外部信息,机器视觉技术被研究用来代替人类视觉进行工作[3-5]。在选煤行业中,机器视觉被应用于煤矸石识别领域,剔除原煤中的矸石。机器视觉是用相机代替人眼进行测量,计算机代替人脑进行分析,操控现场的执行设备完成矸石剔除。通过相机将原煤转换成图像信号,传递给图像识别系统,根据图像信息提取图像表面特征,最终进行识别判定。
1 图像表面特征
1.1 特征提取
人工选矸的主要根据操作工对原煤表面的观察,由经验判断将矸石挑出来。基于机器视觉的煤矸石识别中,特征提取的目的是从一幅图像中得到有效信息,在煤矸石识别中,颜色和纹理特征能帮助我们正确的分类煤与矸石[6-8]。
采用RGB空间的R分量、G分量、B分量;HSV空间的H分量、S分量、V分量;灰度空间的灰度值描述颜色。提取颜色直方图的一阶矩、二阶矩、三阶矩作为图像的颜色特征。
提取灰度共生矩阵的能量、对比度、相关性、熵;Tamura纹理的粗糙度、对比度、方向度作为图像的纹理特征。
原煤图像采集系统如图1所示。

图1 视频图像采集系统
对于煤与矸石的图像提取28个特征用于后续的识别研究,见表1。

表1 图像表面特征汇总
1.2 特征初筛
对于特征数据集采用统计观察的方法进行初步筛选,对于相近特征值可以选择其中的一个特征作为代表,剔除冗余特征,降低数据集维度。在煤与矸石特征数据集的可视图中,能够直观的发现一些规律,RGB颜色空间特征可视化图如图2所示。

图2 RGB颜色空间特征可视化图
在煤与矸石表面特征中,Fe1≈Fe4≈Fe7,Fe2≈Fe5≈Fe8,Fe3≈Fe6≈Fe9,R分量、G分量、B分量的特征值相等且灰度值是由RGB颜色空间的三个分量线性组合得到的。因此,选择Fe19、Fe20、Fe21作为代表特征,将RGB颜色空间的特征整体剔除。初步分析剔除后特征见表2。

表2 初步分析后特征
2 基于Relief权重的特征递归剔除
2.1 Relief特征选择算法
特征选择是从提取的全特征F{f1,f2,…,fn}中寻找到子集特征F′{f1,f2,…,fm},n为全特征个数,m为子集特征个数。特征选择不会改变原始特征空间的属性,只是减少原始特征的数目,从全特征中选取具有代表性、分类能力强的特征作为新特征。
Relief算法根据特征参数的分类能力,为每个特征参数赋予不同的权重值[9]。Relief算法对于特征权重是基于特征对近距离样本的分类,具体的算法思想为从样本训练集中随机选取一个样本A,从与A同类别的样本中寻找到一个最邻近样本点B,从与A不同类别的样本中寻找到一个最邻近样本点C,计算样本A、B距离DAB和样本A、C距离DAC。样本点的一个类类和类间最邻近点计算公式可以表示为:
DAB=‖A-B‖
DAC=‖A-C‖
在某一维特征中,如果样本点与同类别样本的该维距离小于样本点与不同类样本的距离,则可以说明该维特征对样本分类起到正贡献,增加该特征的权重。相反,如果样本点与同类别样本的该维距离大于样本点与不同类样本的距离,则可以说明该维特征对样本分类起到负贡献,减小该特征的权重。重复多次随机抽样n次,计算各维特征n次平均权重,权重越大表明该维特征对样本分类能力越强,相反则表明分类能力越弱。两类数据分类中,特征Fe的权重表示为:
W(Fe)=Wf-∑diff[Fe,A,B]/n+
∑diff[Fe,A,C]/n
函数diff定义为:
其中,Wf为特征的初始权重,都置0,max(Fe)为训练集中该维特征最大值,min(Fe)为训练集中该维特征最小值,n为重复次数。
通过Relief算法计算各个特征的权重,特征权重值越大,该特征在识别中的贡献度越大,反之贡献度越小。
2.2 SVM算法
手选矸是通过人在工作中的长期经验进行矸石挑选。通过大脑积累之前获得的煤和矸石的表面状态不同的经验,在下次的识别中,做出准确判断,识别出矸石。利用计算机系统实现人肉眼对煤与矸石的模式识别有很多方法,如神经网络、KNN、支持向量机等[10-13]。
支持向量机方法就是在训练集中寻找最大分类间隔的分类面,得到推广能力强的分类模型。支持向量机的方法对煤与矸石进行识别时采用libsvm工具箱,libsvm中对于惩罚参数和核函数参数用c和g来表征。采用5折交叉验证和网格搜索来确定最优c和g,训练集识别率最高时的c、g值就是模型的最优值。
2.3 SVM-RFE方法
在SVM全特征识别的基础上,采用基于Relief特征权重的支持向量机特征递归剔除,即SVM-RFE方法来进行特征选择[14]。
SVM-RFE方法是特征选择与分类器模型结合的一种分类方法,用于剔除全特征中的冗余特征,找到最优特征子集。SVM-RFE方法的思想为:通过Relief算法计算特征权重值,循环剔除数据集中权重值最小的特征,采用网格搜索和K-CV交叉验证的方法确定训练集循环剔除最小特征后的分类模型参数c和g的最优值,并在最佳参数下对测试集进行识别预测。
3 多工况识别实验

图3 表面类型
基于机器视觉的煤矸石识别的核心是原煤的表面特征,在实际的选矸过程,原煤表面状态存在不同类型,而相同批次的原煤表面状态基本相同,现将原煤的表面类型分为表面因型(a):外表面无煤泥且表面干燥;表面类型(b):外表面无煤泥且表面湿润;表面类型(c):外表面覆盖干煤泥;表面类型(d):外表面覆盖湿煤泥,分别对应实际中的脱泥后干燥、脱泥后淋湿、含原生煤泥、原生煤泥选前淋湿。对4种表面类型进行识别,研究不同表面类型的识别效果。煤和矸石的4种表面类型如图3所示。其中,左边为煤的图像,右边为矸石的图像,(c)类型和(d)类型的覆盖煤泥均为散点状覆盖,并且是开采后的原始覆盖状态。该样本矸中带煤和煤中带矸的比例都比较低。
通过分析表面类型局部放大图,在宏观上可以观察出图像间存在区别,提取的表面特征特征也必然存在差异。因此,需要对不同表面类型分别进行识别试验。试验采用宁夏白芨沟矿原煤进行对比验证。试验分为4组进行,每种表面状态制备70个样品,共280个样本。试验安排如图4所示。
图4 试验安排
3.1 ①组:外表面无煤泥且表面干燥
对白芨沟矿外表面无煤泥且表面湿润的煤和矸石进行基于Relief算法特征权重的支持向量机特征递归剔除分类研究,结果见表3。特征剔除顺序为:Fe28→Fe11→Fe12→Fe18→Fe21→Fe26→Fe14→Fe16→Fe24→Fe19→Fe15→Fe13→Fe10→Fe17→Fe20→Fe22→Fe27→Fe23→Fe25。
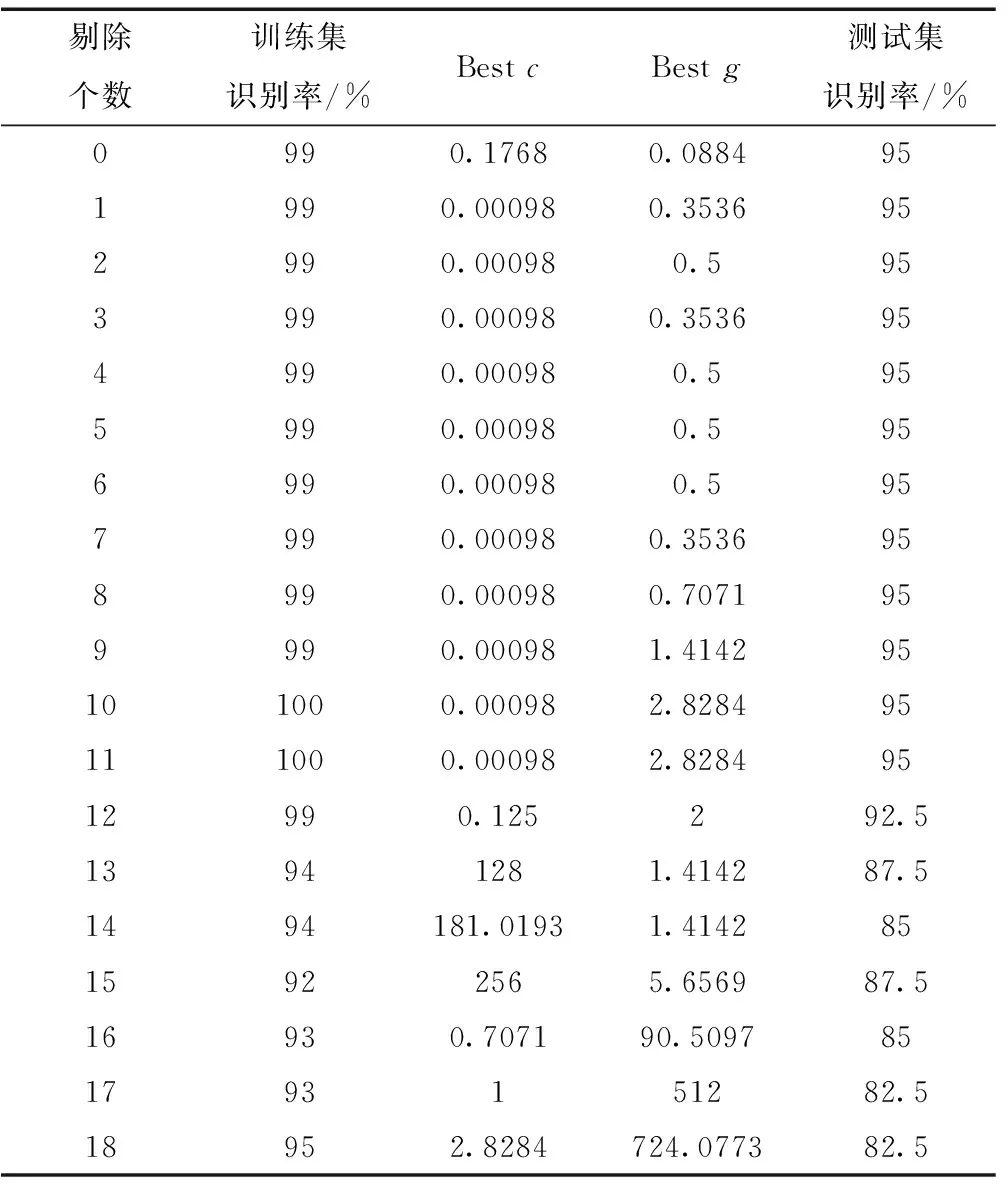
表3 表面类型(a)特征递归剔除参数选择和识别
从表3中可得,最优子集为特征权重排名前8的特征属性,测试集最高识别率为95%。
3.2 ②组:外表面无煤泥且表面湿润
对白芨沟矿外表面无煤泥且表面湿润的煤和矸石进行基于Relief算法特征权重的支持向量机特征递归剔除分类研究,结果见表4。特征剔除顺序为:Fe21(-0.0012)→Fe18(-0.0007)→Fe23(0.0076)→Fe27(0.0082)→Fe16(0.0102)→Fe17(0.0103)→Fe19(0.0106)→Fe20(0.0113)→Fe14(0.0135)→Fe25(0.0151)→Fe22(0.017)→Fe24(0.0192)→Fe11(0.0267)→Fe13(0.0273)→Fe26(0.0345)→Fe15(0.043)→Fe12(0.051)→Fe28(0.0757)→Fe10(0.1177)。

表4 表面类型(b)特征递归剔除参数选择和识别
从表4中可得,最优子集为特征权重排名前17的特征属性,测试集最高识别率为97.5%。
3.3 ③组:外表面覆盖干煤泥
对白芨沟矿外表面覆盖干煤泥的煤和矸石进行基于Relief算法特征权重的支持向量机特征递归剔除分类研究,结果见表5。特征剔除顺序为:Fe15(0.022)→Fe26(0.0235)→Fe18(0.0252)→Fe21(0.0254)→Fe24(0.0354)→Fe28(0.0412)→Fe14(0.0414)→Fe13(0.0443)→Fe11(0.0453)→Fe20(0.0465)→Fe17(0.0467)→Fe25(0.0468)→Fe27(0.0476)→Fe12(0.0482)→Fe23(0.0536)→Fe22(0.0637)→Fe16(0.1077)→Fe19(0.1093)→Fe10(0.1853)。
从表5中可得,最优子集为特征权重排名前5的特征属性,测试集最高识别率为95%。

表5 表面类型(c)特征递归剔除参数选择和识别
3.4 ④组:外表面覆盖湿煤泥
对白芨沟矿外表面覆盖湿煤泥的煤和矸石进行基于Relief算法特征权重的支持向量机特征递归剔除分类研究,结果见表6。特征剔除顺序为:Fe24(0.0028)→Fe14(0.0029)→Fe27(0.0053)→Fe17(0.0053)→Fe13(0.0055)→Fe20(0.0056)→Fe23(0.0084)→Fe15(0.0238)→Fe25(0.0416)→Fe19(0.052)→Fe18(0.0523)→Fe16(0.0533)→Fe21(0.0567)→Fe26(0.059)→Fe22(0.0606)→Fe10(0.0614)→Fe11(0.0632)→Fe12(0.0638)→Fe28(0.2091)。

表6 白芨沟矿表面类型(d)特征递归剔除参数选择和识别
从表6中可得,最优子集为特征权重排名前9的特征属性,测试集最高识别率为100%。
以上数据集中训练集和测试集样本是随机选取的,单次的实验结果可能存在偶然性。对于4组试验,每组试验再进行4次训练集和测试集随机取样,样本数量保持不变,进行最优子集下的识别试验,4组试验分别在各自最优特征子集下进行的随机取样识别结果见表7,用于检验试验结果是否存在偶然性。其中,均值为5次随机试验识别率的平均值。

表7 基于最优特征子集的5次识别
由表7分析可知,5次随机取样的训练集和测试集在最优特征子集下的识别结果差距很小,5次的平均值也说明了随机取样的识别率波动很小。表明基于Relief权重的特征递归剔除能够剔除冗余特征,提高多工况识别效率和稳定性。
4 结 语
基于机器视觉的煤矸石识别是对煤和矸石的图像进行识别,从图像中提取28个颜色和纹理特征,进行初步分析,剔除RGB空间特征,通过Relief算法计算各个特征的权重值作为特征的评价指标。将原煤的表面分为外表面无煤泥且表面干燥、外表面无煤泥且表面湿润、外表面覆盖干煤泥、外表面覆盖湿煤泥4种表面类型。针对白芨沟矿,选择SVM构建识别模型,并且通过特征递归剔除方法寻找最优特征子集,多次随机取样的最优特征子集下的识别效果波动小,准确率高。因此,提取的图像表面特征具有代表性,可以很好的区分实际工况下的煤和矸石。值得一提的是,如果矸中带煤过高,可能会制约本方法的应用。
猜你喜欢
语数外学习·高中版下旬(2023年7期)2023-09-25 00:45:13
山西冶金(2022年3期)2022-08-03 08:40:28
选煤技术(2022年1期)2022-04-19 11:15:04
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28 11:06:20
陕西煤炭(2021年6期)2021-11-22 09:12:26
选煤技术(2021年3期)2021-10-13 07:33:36
煤炭与化工(2021年5期)2021-07-04 02:52:12
矿产综合利用(2020年1期)2020-07-24 08:51:28
南京大学学报(数学半年刊)(2020年1期)2020-03-19 02:24:44
中国煤炭(2016年1期)2016-05-17 06:11:40
