
面向文本命名实体识别的深层网络模型
2019-01-24 09:29李慧林柴玉梅孙穆祯
小型微型计算机系统 2019年1期
李慧林,柴玉梅,孙穆祯
1(郑州大学 信息工程学院,郑州 450001)2(华中科技大学 公共管理学院,武汉 430070)
1 引 言
命名实体识别是自然语言处理领域的一项基本任务,是信息抽取和信息检索的前提,自1995年第六届信息抽取会议(The sixth Message Understanding Conference,MUC-6)将命名实体识别作为评测任务后,命名实体识别的研究发展迅速,如新闻领域、金融领域、微博媒体领域等.但是,由于生物医学领域的复杂性及多变性,医疗文本中的命名实体通常比一般领域的实体长度更长,而且更具有专业性和针对性,病历文本中实体类型众多且存在简单实体和复杂实体的嵌套情况,越来越受到研究人员的关注.电子病历(Electronic Medical Records,EMRs)作为医疗文本的一种形式,是指基于一个特定系统的电子化病人记录,该系统提供用户访问完整准确的数据、警示、提示和临床决策支持系统的能力.病历中包含大量的隐私信息(Protected Health Information,PHI),如患者的个人信息、地址、联系方式、医生的个人信息及医院名称地址等.隐私信息的存在使得传统的各个医疗机构间信息不共享,公共临床信息资源库缺乏,导致许多基于临床医学的研究无法良好地开展,甚至造成重复的研究,浪费大量的时间和成本.为了保护这些隐私信息,需要对电子病历进行匿名化处理.1996年,美国出台HIPAA法案,详细规定了电子病历中需要保护的用户隐私信息.
命名实体识别任务常用的方法有早期基于规则和词典的方法[1],基于传统机器学习的方法[2-4],以及近年来基于深度学习的方法[5-7].Sweeney[8]提出了第一个基于规则的匿名化系统,尝试使用“常识模板”识别隐私信息.Yang[9]基于词典和规则从医院出院摘要中提取药物信息,构建了许多词汇资源来描述不同类别药物或形态特征.基于规则和词典的方法考虑了数据的结构和特点,具有较好的识别效果,但对数据具有依赖性,可移植性差,而且手工编写规则耗费大量的时间和精力.
基于机器学习的方法具有更好的可移植性,对未登录词也具有较好的识别效果,常用的机器学习模型有支持向量机模型(Support Vector Machine,SVM)、隐马尔科夫模型(Hidden Markov Model,HMM)、条件随机场模型(Conditional Random Field,CRF)等.Guo[10]使用支持向量机在医疗出院摘要中识别个人健康信息,SVM模型可以很容易地适应一个新的领域,并实现良好的性能.Szarvas[11]使用决策树实现隐私信息的识别,添加了两个新的特征并应用迭代学习方法,利用文本结构化中给出的信息来提高识别的准确性.
还有联合了规则、词典和机器学习的混合方法,其中使用较多且性能较好的是联合条件随机场和规则,条件随机场模型由Lafferty[12]于2001年提出,它能够融合大量的特征,在命名实体识别和序列标注中具有很好的性能.Wellner[13]使用CRF模型和规则对电子病历中的隐私信息进行匿名化处理,并引入词典以减少错误.YANG[14]等针对中文电子病历,提出了一套适合的命名实体和实体标注体系,为信息抽取提供了基础.WANG[15]等提出了一种基于实例的迁移学习方法,基于条件随机场进行实验分析.LI[16]等得到三种词表示方法后,将其作为CRF和SVM的特征进行半监督学习从而提高了性能.
近年来,基于深度学习的命名实体识别发展迅速,Chiu[17]提出了一个新的神经网络结构,使用一个双向LSTM-CNNs结构,可以自动的探测词级别和字符级别的特征,从而避免了大部分的特征工程.Ma[18]提出一种双向的LSTM-CNNs-CRF端到端的实现模型,无需功能工程或数据预处理,从而使其适用于各种序列标注任务.Dernoncourt[19]设计了一种基于人工神经网络的命名实体识别工具,用户可以使用图形化的界面对实体进行注释,之后使用注释好的数据来训练人工神经网络,从而对新文本中实体的位置和类别实现预测.Peters[20]使用大量的无标注数据训练一个双向神经网络模型,用这个训练好的模型来获取当前要标注词的向量,再将该向量作为特征加入到原始的双向RNN-CRF模型中.Rei[21]使用注意力机制将原始的字符向量和词向量拼接加入了权重求和,使用两层传统神经网络隐层来学习权值,从而动态地利用字符向量和词向量.
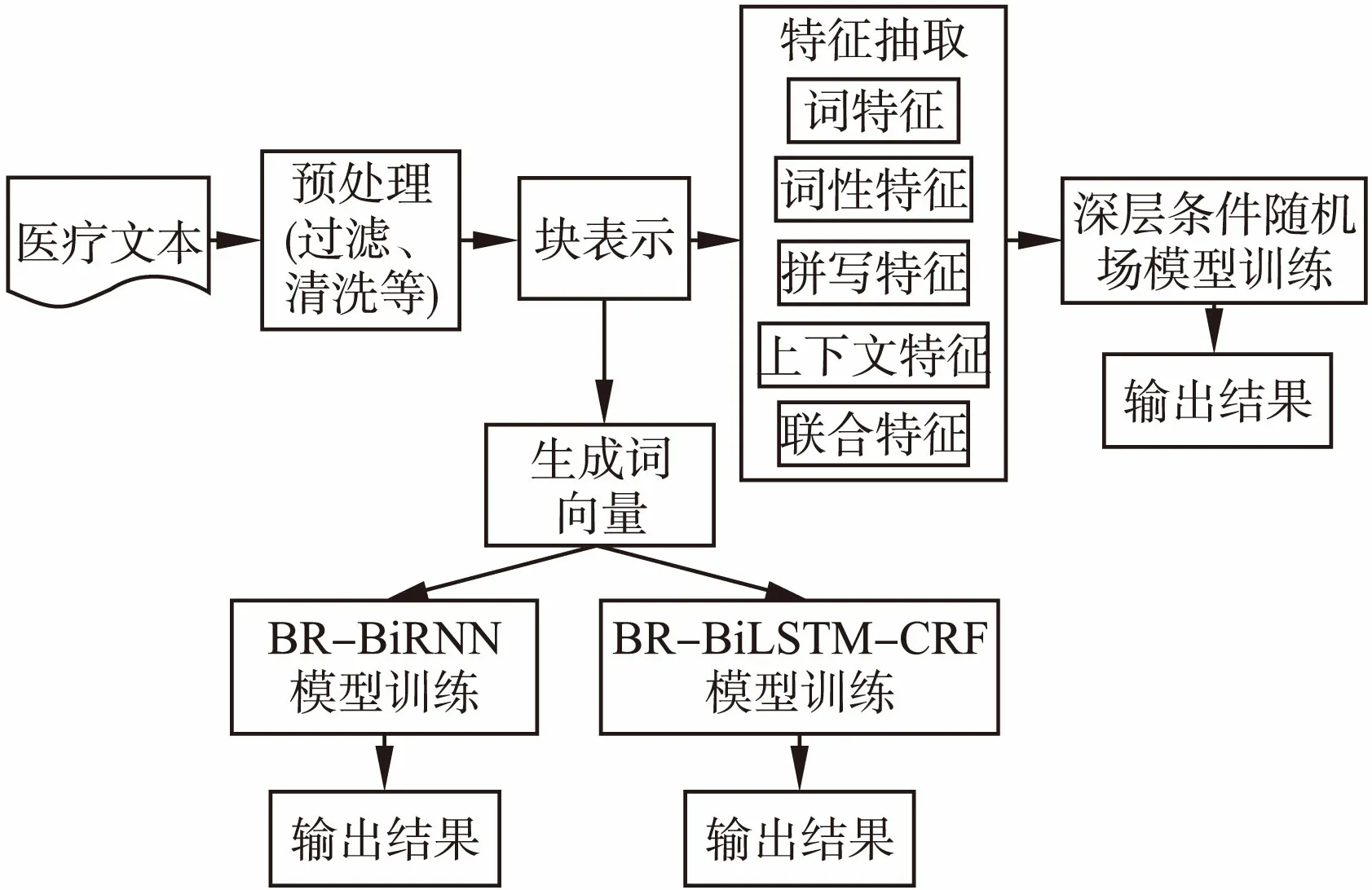
图1 命名实体识别整体流程Fig.1 Overall process of named entity recognition
本文采用多种深层网络模型实现命名实体识别任务.深层条件随机场模型融合了多种特征,条件随机场模型没有独立性假设的约束,可以更好地利用上下文特征,深层条件随机场模型将复杂的实体识别问题分解为多个子问题,加入边界特征,针对每个子问题分别在不同层进行实现.BR-BiRNN(Block Representation Bidirectional Recurrent Neural Network)模型基于块表示将医疗文本转化为词向量,加入词性向量后组成新的向量,以此向量作为循环神经网络的输入,由输出层输出预测结果.BR-BiLSTM-CRF(Block Representation Bidirectional Long Short Term Memory and Conditional Random Field)模型同样基于块表示方法,结合了双向长短期记忆网络和链式条件随机场,将前向LSTM和后向LSTM的输出拼接为新的向量作为后层条件随机场的输入,识别流程如图1所示.
2 基于深层条件随机场的命名实体识别
2.1 链式条件随机场
条件随机模型可以看成是一个无向图模型或马尔科夫随机场,用来标记序列化数据,对于给定的观察序列,计算其整个标记序列的联合概率.将命名实体识别视为序列标注任务,使用线性链条件随机场解决序列标注问题,针对电子病历文本,随机变量X={x1,x2,…,xn}表示观察序列,随机变量Y={y1,y2,…,yn}表示相应的标记序列,P(Y|X)表示在给定X的条件下Y的条件概率分布,则条件随机场可表示为:
(1)
(2)
式中,fk(yi-1,yi,x,i)是特征函数,λk是对应的权值,Z(x)为归一化项,对于一个条件随机场模型,已知观察序列X时,最可能的标记序列可以表示为:
Y*=argmaxYP(y|x)
(3)
使用条件随机场训练模型,给定一个输入句,P(Y|X)值最大的那个就是输出的标记序列,即输入句中词序列对应的实体类别序列.
2.2 深层条件随机场模型
条件随机场模型更好地利用了上下文的优势,在序列标注任务中更有优势,本文在传统条件随机场模型的基础上进行改进,提出了深层条件随机场模型.深层条件随机场模型对问题进行拆分,将复杂的实体识别问题分解为子问题:实体边界检测和确定实体类别.针对子问题分别在模型中的不同层进行实现,首先是实体边界检测,由第一层线性链条件随机场完成,之后是确定实体类别,由第二层线性链条件随机场完成.深层条件随机场模型的第一层输出为实体边界特征,并不涉及具体实体类别,包括隐私实体的开始,隐私实体的内部、隐私实体的结束、单个词构成的隐私实体和非隐私实体,由于只有五种类别更利于学习有效特征且提高了训练效率,第二层通过第一层的学习为最终分类提供支持.本文深层条件随机场模型中第二层的输入不仅包括第一层的输出,还包括原始词特征、词性特征及上下文特征,其结构如图2所示.
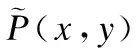
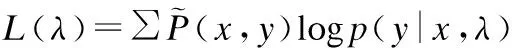
(4)
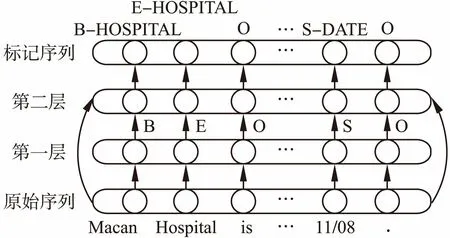
图2 深层条件随机场模型Fig.2 Deep conditional random field model
取对数并引入惩罚项解决过度学习问题,则对数似然函数形式为:
(5)
对参数的估计只使用最近m次迭代的曲率信息来构造海森矩阵的近似矩阵,根据对数似然函数对相应的参数λk求一阶偏导数.得到参数后,对于未标记的序列,求其最可能的标记序列,使用动态规划算法,将全局最优解的计算分解为阶段最优解的计算,得到第一层网络的输出结果,将此结果传递到第二层网络,加入了第一层的输出结果,联合考虑当前词的实体边界特征和其他特征,最终输出实体标记序列.
2.3 条件随机场特征模板
特征模板定义了从训练集中提取特征的方法,本文对训练集进行处理后抽取如下特征:
词特征:词本身特征.
词性特征:词的词性.
拼写特征:如是否包含数字或特殊符号等.
上下文特征:当前词及其前后若干词组成的观察窗口.
联合特征:如t0p-1,t0表示当前词,p-1表示前一个词的词性.
原子特征模板描述了当前词及其词性信息等,利用多个特征进行模型的训练与学习,本文选用的模板见表1.
表1 原子特征模板
Table 1 Atomic feature template
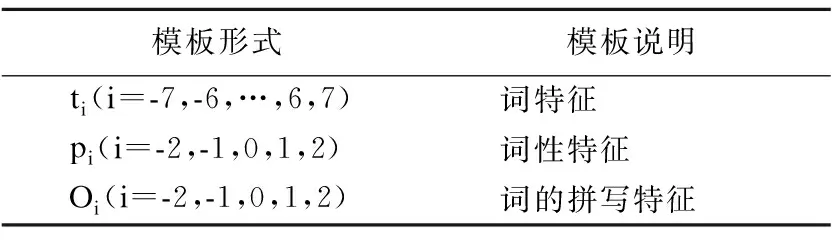
模板形式模板说明ti(i=-7,-6,…,6,7)词特征pi(i=-2,-1,0,1,2)词性特征Oi(i=-2,-1,0,1,2)词的拼写特征
表2中,组合特征相对原子特征加入了多种特征的组合形式,能表达出更多的上下文信息,因此对原子特征进行特征组合,构成新的组合特征模板.
特征函数集由特征模板产生,初始特征函数集为空,依次取出特征模板中的模板与训练文件中的每个对应项进行匹配,若生成的特征函数不在特征函数集中,就将新产生的函数加入到集合中,即针对每一个模板,遍历训练文件中的每个对应项,生成对应的特征函数.生成的特征函数是二值函数,若原始序列和状态序列满足条件则特征函数值为1,否则为0,之后使用最大似然估计法训练求解特征函数的权重,训练得到权重后即生成了模型,输入测试数据即可实现预测.一个模板生成的函数的数量是L*N,其中L是训练集中的类别数量,N是从模板中扩展处理的字符串种类.
表2 部分组合特征模板
Table 2 Some combination feature template
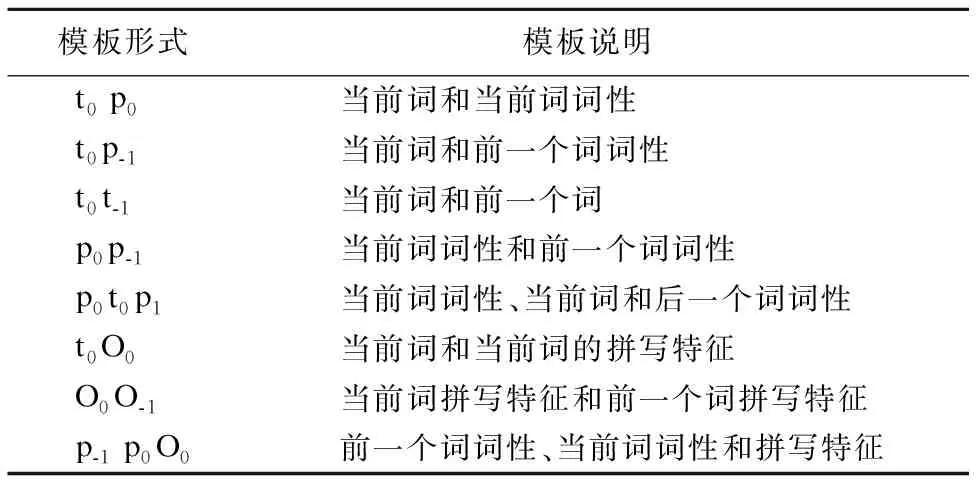
模板形式模板说明t0 p0当前词和当前词词性t0p-1当前词和前一个词词性t0t-1当前词和前一个词p0p-1当前词词性和前一个词词性p0t0p1当前词词性、当前词和后一个词词性t0O0当前词和当前词的拼写特征O0O-1当前词拼写特征和前一个词拼写特征p-1 p0O0前一个词词性、当前词词性和拼写特征
3 基于BR-BiRNN的命名实体识别
3.1 循环神经网络
RNN可以对时间序列上的变化进行记录,更适合处理变长或具有时序关系的数据,常用于词性标注或命名实体识别等序列标注任务中.循环神经网络中,序列当前的输出不仅与当前的输入有关,还与前面的输出有关.循环神经网络一般包含一个输入层x向量、一个隐藏层s向量和一个输出层o向量.
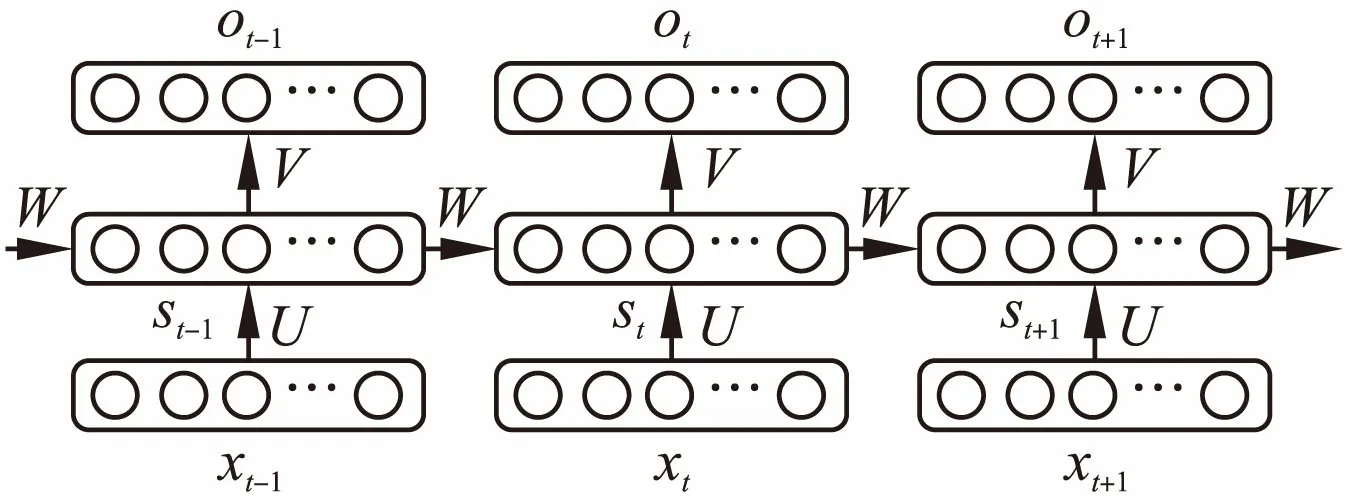
图3 循环神经网络Fig.3 Recurrent neural network
图3中,xt是网络在t时刻的输入,st是隐藏层的值,ot是输出值,st-1是上一次隐藏层的值,U是输入层到隐藏层的权重矩阵,V是隐藏层到输出层的权重矩阵,W是隐藏层上一次的值作为这次输入的权重矩阵.st的值不仅与xt有关,还与st-1有关,循环神经网络的隐藏层为:
st=f(Uxt+Wst-1)
(6)
输出层为:
ot=g(Vst)
(7)
f和g是激活函数,f一般是非线性的激活函数,如sigmoid函数,tanh函数或ReLU函数,g是softmax函数.
3.2 块表示方法
将命名实体识别视为序列标注任务,则需要对原始语料进行处理,将文本表示为适合序列标注的块表示方法.本文采用两种块表示方法:BIO表示法和BIOES表示法.BIO表示法的B(Begin)表示命名实体的开始,I(Inside)表示命名实体的中间,O(Outside)表示命名实体的外部,即该词不是命名实体.BIOES表示法中的BIO与上述相同,此外使用E(End)表示命名实体的结束,S(Single)表示单独的实体,即该实体仅由一个词语组成.不同的块表示方法对命名实体识别有不同的影响,图4给出了两种表示方法.

BIO representation:On/O 9-27/B,/O she/Oexperienced/O another/O Episode/O of/Oconstipation/O and/O impaction/O,/O came/O to/OLiccam/B Community/I Medical/I Center/I./OBIOES representation:On/O 9-27/S,/O she/Oexperienced/O another/O Episode/O of/Oconstipation/O and/O impaction/O,/O came/O to/OLiccam/B Community/I Medical/I Center/E./O
图4 BIO和BIOES表示法
Fig.4 BIO and BIOES representation
3.3 词向量的生成
以句子为单位表示为词向量的集合,词向量是将语言中的词进行数学化表达的方式,将词映射为相应的词向量,所有的词向量构成一个词向量空间,每个词向量视为该空间的一个点,引入空间距离就可以计算词之间的相似性,通过这种数学化的表示,更利于挖掘语言中的相关特征,算法1以BIO表示法为例,给出了词向量的生成过程.
算法1.词向量生成算法
输入:训练数据集lex_train,ne_train,测试数据集lex_test,ne_test,词典dicts
输出:训练好的词向量train_set,test_set
1.words2idx=dicts[0];//将词转换为词向量
2.labels2idx=dicts[1];//将标签转换为词向量
3.idx2word=dict((k,v)for v,k in words2idx.iteritems());
4.idx2label=dict((k,v)for v,k in labels2idx.iteritems());
5.O_idx=labels2idx[′O′];
6.Initialize B_idx_list 和I_idx_list 为空;//初始为空
7.For k,v in idx2label.iteritems()
8. If v.startswith(′B′)
9. B_idx_list.append(k);
10. Elif v.startswith(′I′)
11. I_idx_list.append(k);
12.End for
13.For each lex_train[i][j] in lex_train
14. lex_train[i][j]=words2idx[lex_train[i][j]];//生成词向量
15.End for
16.For each ne_train[i][j] in ne_train
17. ne_train[i][j]=labels2idx[ne_train[i][j]];//生成词向量
18.End for
19.For each lex_test[i][j] in lex_test
20. lex_test[i][j]=words2idx[lex_test[i][j]];//生成词向量
21.End for
22.For each ne_test[i][j] in ne_test
23. ne_test[i][j]=labels2idx[ne_test[i][j]];//生成词向量
24.End for
25.训练集词向量集合train_set=[lex_train,ne_train];
26.测试集词向量集合test_set=[lex_test,ne_test];
词典由大量语料生成,将文本表示为词向量形式后,将每个词的词性同样的表示为向量形式,文本中第i个句子可以表示为向量si=(t0,t1,…,tm),其中tj是句子中的第j个词的词向量,第i个句子对应的词性向量ci=(p0,p1,…,pm),其中pj是第j个词的词性向量,把词向量和词性向量拼接为一个新的向量,拼接后的向量为xi=[ti,pi],以此向量xi作为BR-BiRNN模型的输入.数据集中由于每个句子长度不同,采用窗口策略对语料进行处理,实验后设定窗口大小为5,即神经网络的输入x(i)={xi-2,xi-1,xi,xi+1,xi+2},表示当前词的向量及其上下各两个词的向量.当前词为句首词时,由于其前面并没有词,用负1填充,当前词为句尾词时类似.
3.4 BR-BiRNN模型
引入双向循环神经网络模型BiRNN,基于块表示方法训练神经网络,BR-BiRNN模型包含一个前向RNN层,一个后向RNN层,对前后两个方向时间序列上变化进行记录,经softmax层后输出标注结果,其结构如图5所示.
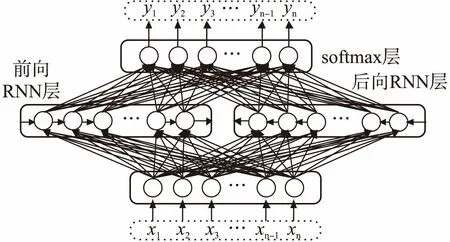
图5 BR-BiRNN模型Fig.5 BR-BiRNN model
将文本预处理后转化为块表示方式,进而处理每个词生成对应的向量,以向量作为神经网络的输入,传递给前向RNN和后向RNN,把前向RNN和后向RNN的输出拼接传递给softmax层,由softmax输出序列{y1,y2,…,yn},即各个词对应的预测标签,算法2描述了训练过程.
算法2.BR-BiRNN模型的训练算法
输入:医疗文本
输出:训练后的BR-BiRNN模型
1.将文本表示为向量形式;
2.While 不满足终止条件 对样本 do
4.ht=σ(zt)=σ(Uxt+Wht-1+b)
5.ot=Vht+c
8. (1-y(i))log(1-h(w,b)(x(i)))]
11.End while
4 基于BR-BiLSTM-CRF的命名实体识别
4.1 LSTM记忆单元结构
简单的RNN由于存在梯度消失和梯度爆炸,难以处理长距离依赖的问题,长短期记忆网络LSTM是RNN的一种变形,它不仅可以保存短期的输入,还能保存长期的状态,LSTM增加了一个图6所示的单元状态c,用来保存长期状态.
LSTM单元c的内容由3个门来控制,分别是输入门it、遗忘门ft、输出门ot.输入门it控制前一时刻的单元状态ct-1有多少保留到当前ct,遗忘门ft控制当前输入xt有多少保留到当前ct,输出门ot控制ct有多少输出到LSTM的当前输出值ht,使用如下定义实现:
it=σ(Wiht-1+Uixt+bi)
(8)
ft=σ(Wfht-1+Ufxt+bf)
(9)
ot=σ(Woht-1+Uoxt+bo)
(10)
(11)
(12)
ht=ot·tanh(ct)
(13)
其中,W和U是权重矩阵,b是偏置向量,·是按元素乘,σ和tanh是激活函数.σ函数定义为:
(14)
tanh函数定义为:
(15)
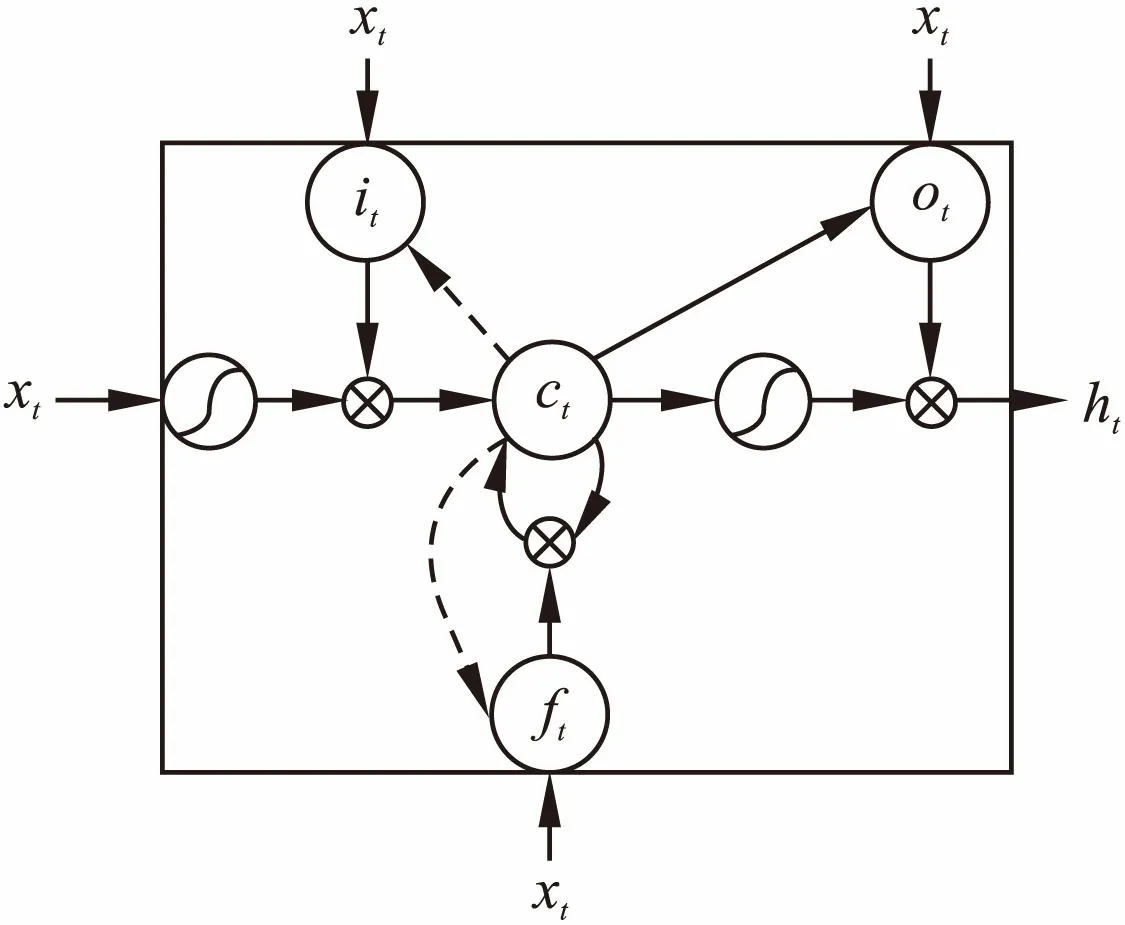
图6 LSTM单元组成结构Fig.6 The cell structure of LSTM
LSTM单元记录长期依赖信息,针对复杂问题可以利用到距离当前位置很远的上下文信息,适合处理时间序列中间隔和延迟非常长的场景.
4.2 BR-BiLSTM-CRF模型
单向LSTM仅利用了过去的上下文信息,而双向LSTM同时利用了过去和未来两个时间方向上的上下文信息.BR-BiLSTM-CRF模型基于块表示方法,使用双向的LSTM模型检测隐私实体边界,可以实现自动提取特征,连接到链式条件随机场层输出实体类别,它接收双向LSTM的输出作为输入,同时仅再加入词和词性特征,而不需要人工总结和添加其他特征.
隐私实体边界检测不仅与当前词向量前面的词向量有关,还与当前词向量后面的词向量相关,因此本文采用双向LSTM更有效地利用数据之间的整体序列信息来检测实体边界,采用CRF识别实体类别,如图7所示,其基本思想是训练序列向前和向后形成两个LSTM网络,分别利用了过去和未来的上下文信息,它们同时连接到一个输出层,之后再连接到一层CRF上.
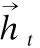
图7 BR-BiLSTM-CRF模型Fig.7 BR-BiLSTM-CRF model
(16)
式中,w和b是需要训练的参数,m是样本的个数,x(i)是第i个样本值,y(i)是第i个样本的标签,h(w,b)(x(i))是第i个样本用参数w和b预测得到的y值.训练过程首先是前向计算,分别计算出LSTM前向层和后向层的值,刚开始训练时,输出值和预期值不同,接着计算每个神经元的误差项值,损失函数是交叉熵函数,之后使用梯度下降法,更新网络参数,LSTM反向传播误差项包括两个方向:一个是空间上,将误差项向神经网络的上一层传播,一个是时间上,从当前t时刻开始,计算每个时刻的误差.重复此一系列步骤,直到误差小于给定值,一般是一个很小的数,算法3描述了训练过程.
算法3.实体边界识别的训练算法
输入:医疗文本
输出:训练后的实体边界识别模型
1.将文本表示为词向量形式train_set=[lex_train,ne_train];
2.While 不满足终止条件,对train_set do
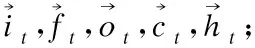
6. 计算损失:将预测得到的结果h(w,b)(x(i))和期望值
7.h(x(i))比较,得到损失函数J(w,b);
9. 更新参数:w←w+Δw,b←b+Δb;
10.End while
经过双向LSTM获得隐私实体边界结果后,连接一层条件随机场,将边界特征作为条件随机场的输入,构建BR-BiLSTM-CRF模型,由最后一层的条件随机场确定实体类别.由于条件随机场模型的当前输出考虑了上一输出结果,因此对实体识别这样的序列标注问题更具有优势,如I后面可以有多个I,但O后面不应出现I,相比于一般分类器输出独立的分类结果,条件随机场的输出有效利用了前后的标签来预测当前标签.
5 实验与结果分析
5.1 数据集
实验采用Informatics for Integrating Biology and the Bedside(I2B2)2006年、2014年英文评测数据集和某医院妇产科中文医疗文本.I2B2是美国国立卫生研究院资助的国家生物医学中心,2006年评测数据中隐私实体通过XML标签来标记,共包含年龄、日期、医生姓名、医院名、证件号码、地址、患者姓名、电话共8种命名实体.2014年数据集格式较2006年有较大变化,通过命名实体在整个文本中的偏移量来标记,其中的隐私实体类别也比2006年更复杂,共有7个大类,分别是姓名、职业、地址、年龄、日期、联系方式和证件号码,大类下又更进一步划分为多个小类.妇产科医疗文本来自某医院真实数据,包括入院诊断、住院经过、出院诊断等,标注格式与2006年I2B2格式一致.中文数据首先进行分词处理,其他处理步骤与英文语料一致.实验语料中隐私实体数量见表3.
评价指标采用精确率P、召回率R和F值:
(17)
(18)
(19)
精确率是评估预测结果中目标实体所占的比例,召回率是评估召回目标实体的比例,精确率和召回率越高,说明实验结果越好,然而一般精确率高时召回率低,召回率高时精确率低,因此,加入F值评价指标,F值综合考虑了精确率和召回率,是精确率和召回率的调和平均值.
表3 训练集和测试集中PHI实体分布
Table 3 Train set and test set of PHI named entity distribution

2006 I2B2评测2014 I2B2评测妇产科数据集训练集测试集训练集测试集训练集测试集样本数66922079051477601940词数3947451661054956593205902370432656512命名实体数14253524517389114623643711635
5.2 实验结果与分析
实验共使用了三个数据集,在提出的三种不同的深层网络模型下进行实验:深层条件随机场模型、BR-BiRNN模型、BR-BiLSTM-CRF模型.并与传统的SVM、HMM和CRF模型进行对比.实验发现BIOES块表示法比BIO块表示法结果更优,表4给出的实验结果均是在BIOES表示法下的结果,其中,训练SVM使用高斯核函数,HMM-DP模型是Chen等人对HMM的改进结果,CRF是未做改进的基本CRF模型,分别仅使用了原子特征和原子+组合特征,Deep CRF模型是本文提出的深层条件随机场模型,BR-BiRNN模型、BR-BiLSTM-CRF模型是本文提出的另两种基于循环神经网络的深层网络模型.本文提出的三种模型在I2B2中心2006年和2014年的评测数据集中F值均超过90%,在妇产科医疗文本中F值超过85%.针对每种具体的实体类别,表5以2014年评测数据集为例给出了每个隐私实体类别的精确率、召回率和F值.
表4 不同模型结果对比
Table 4 Comparison of the results of different experimental conditions
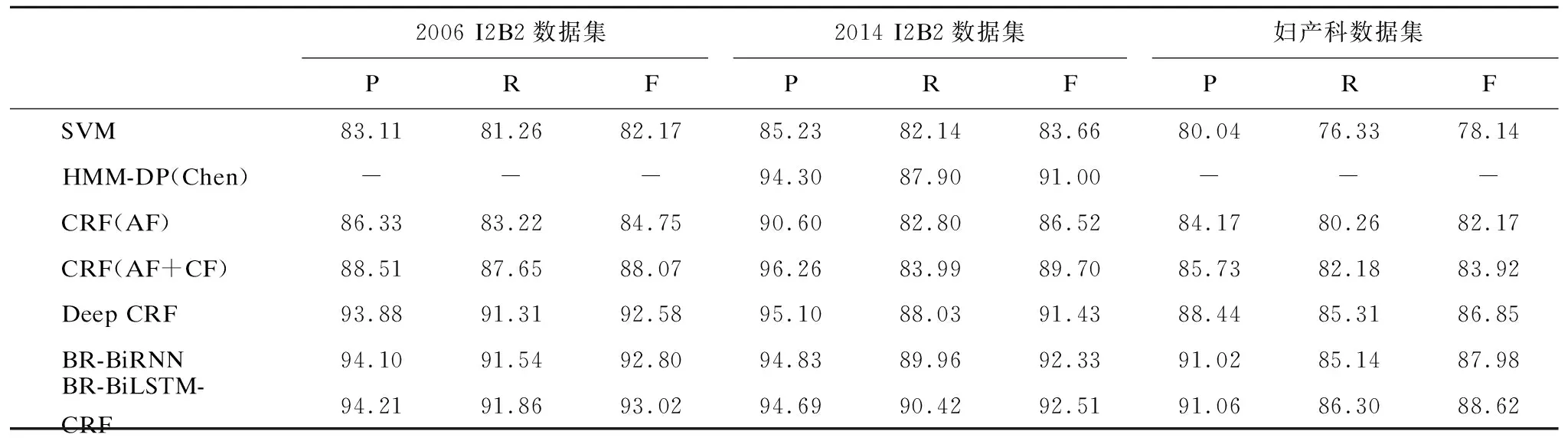
2006 I2B2数据集2014 I2B2数据集妇产科数据集PRFPRFPRFSVM83.1181.2682.1785.2382.1483.6680.0476.3378.14HMM-DP(Chen)---94.3087.9091.00---CRF(AF)86.3383.2284.7590.6082.8086.5284.1780.2682.17CRF(AF+CF)88.5187.6588.0796.2683.9989.7085.7382.1883.92Deep CRF93.8891.3192.5895.1088.0391.4388.4485.3186.85BR-BiRNN94.1091.5492.8094.8389.9692.3391.0285.1487.98BR-BiLSTM-CRF94.2191.8693.0294.6990.4292.5191.0686.3088.62
由表4可知,CRF模型在原子特征的基础上加入组合特征后,性能有所提高,因为组合特征包含了更多的上下文信息,能为模型的正确输出提供更多支持,因此本文深层条件随机场模型在检测隐私实体边界时,采用了原子特征和组合特征,深层条件随机场模型比传统的机器学习模型如SVM、HMM等的精确率和召回率都有所提高,整体F值得到提高.BR-BiRNN模型基于循环神经网络,不需要额外的专业领域知识,可以自动提取特征.BR-BiLSTM-CRF模型结合了神经网络层和条件随机场层,F值在三个语料上分别达到93.02%、92.51%和88.62%.妇产科医疗文本是中文语料集,由于中文预处理需要分词,存在一定的分词误差,其F值低于I2B2评测任务英文语料集结果.I2B2评测数据集是公开数据集,本文提出的三种深层网络模型与评测任务提交结果对比如表6所示.
表5 每个实体类别的结果对比
Table 5 Comparison of the results of each named entity specics
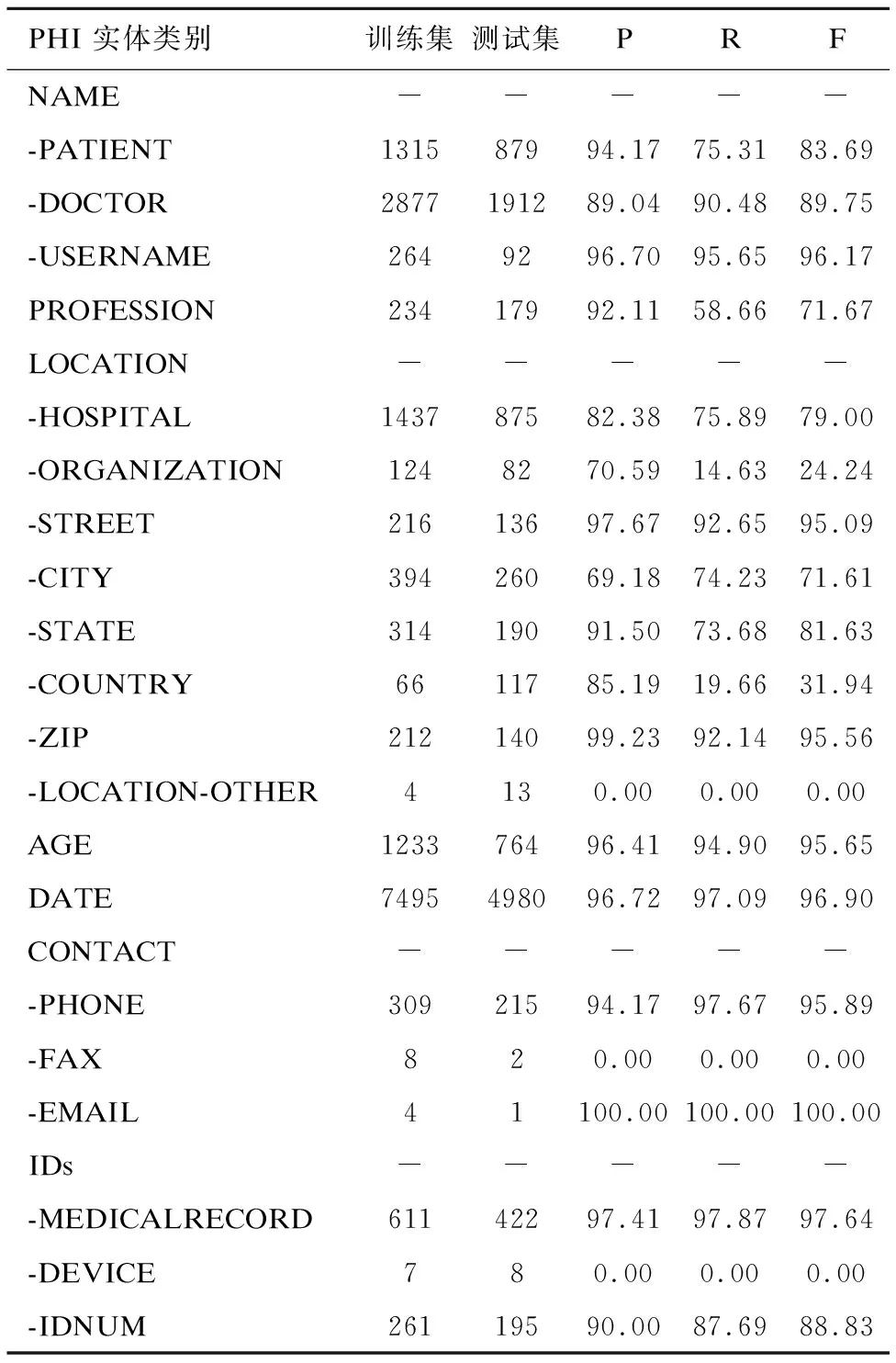
PHI 实体类别训练集测试集PRFNAME------PATIENT131587994.1775.3183.69-DOCTOR2877191289.0490.4889.75-USERNAME2649296.7095.6596.17PROFESSION23417992.1158.6671.67LOCATION------HOSPITAL143787582.3875.8979.00-ORGANIZATION1248270.5914.6324.24-STREET21613697.6792.6595.09-CITY39426069.1874.2371.61-STATE31419091.5073.6881.63-COUNTRY6611785.1919.6631.94-ZIP21214099.2392.1495.56-LOCATION-OTHER4130.000.000.00AGE123376496.4194.9095.65DATE7495498096.7297.0996.90CONTACT------PHONE30921594.1797.6795.89-FAX820.000.000.00-EMAIL41100.00100.00100.00IDs------MEDICALRECORD61142297.4197.8797.64-DEVICE780.000.000.00-IDNUM26119590.0087.6988.83
表6 本文模型与I2B2评测结果F值对比
Table 6 Compare to I2B2 shared task submissions

2006 数据集2014 数据集评测结果0.76-0.960.44-0.93Deep CRF模型0.92580.9143BR-BiRNN模型0.92800.9233BR-BiLSTM-CRF模型0.93020.9251
分析对各个具体类别隐私实体的识别情况,对三个数据集中每一类实体的识别结果如图8、图9、图10所示.结合表5和图8、图9、图10可知,模型对于“DATE”、“ID”、“USERNAME”、“ZIP”、“EMAIL”、“MEDICALRECORD”和“PHONE”的识别率较高,因为它们一般具有较为固定的格式或特点.当数据集中个数很少时,难以学到更多信息,如2006年训练集中“AGE”仅有13个,测试集中“AGE”也仅有3个,因此F值为0,类似的还有2014年的“LOCATION-OTHER”、“FAX”和“DEVICE”.但数据集中个数较多时,其识别效果较好,如2014年“AGE”由于样本的增大,其F值超过90%,妇产科中文语料中“AGE”F值也很高.“DOCTOR”和“PATIENT”都属于人名,深层条件随机场网络加入了实体边界特征,BR-BiRNN、BR-BiLSTM-CRF模型引入循环神经网络,考虑了时序信息,使得更好地利用上下文信息,但是由于它们的格式和特点较为相似,容易互相错分.“LOCATION”、“ORGANIZATION”和“COUNTRY”的识别结果较低,因为它们往往是多个词语组成的长词组,有的其中包含有介词或符号,在进行识别时,往往是只识别出了实体中的部分词语作为了隐私实体.大部分类别都是精确率较高,召回率较低,把很多隐私实体标记为了非隐私实体或其它类别的实体,提高召回率将对F值有较大影响.
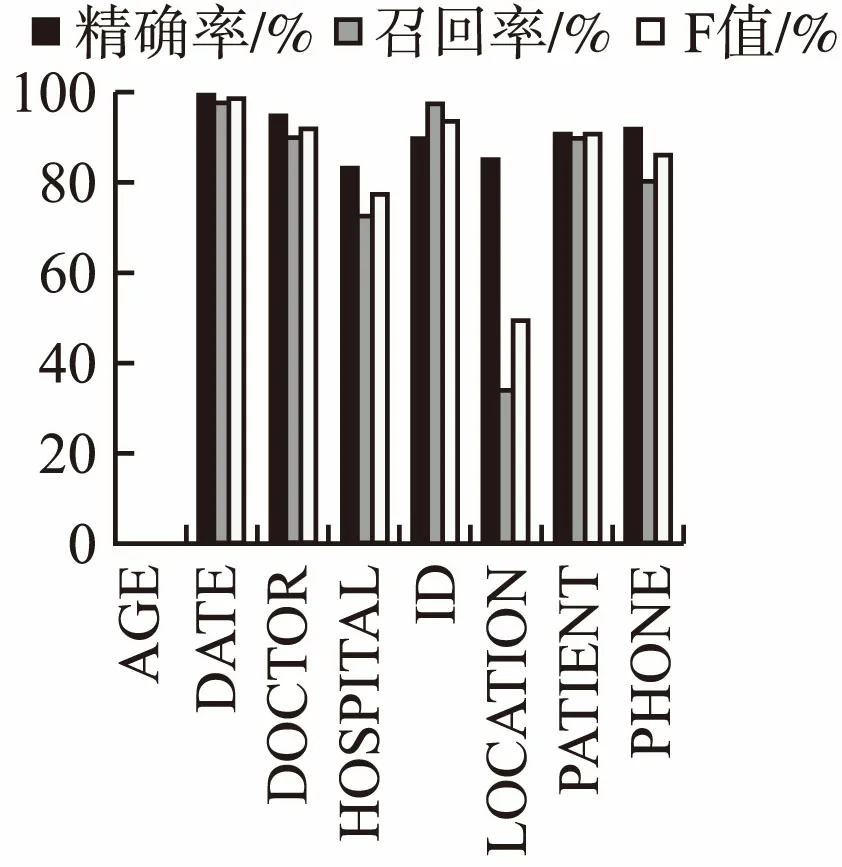
图8 2006 I2B2命名实体识别结果Fig.8 2006 I2B2 NER results
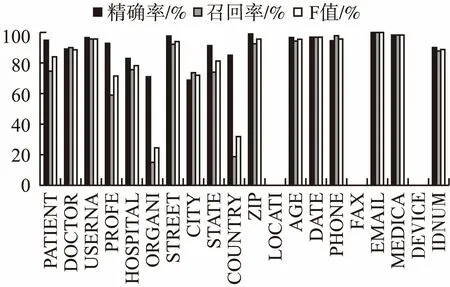
图9 2014 I2B2命名实体识别结果Fig.9 2014 I2B2 NER results
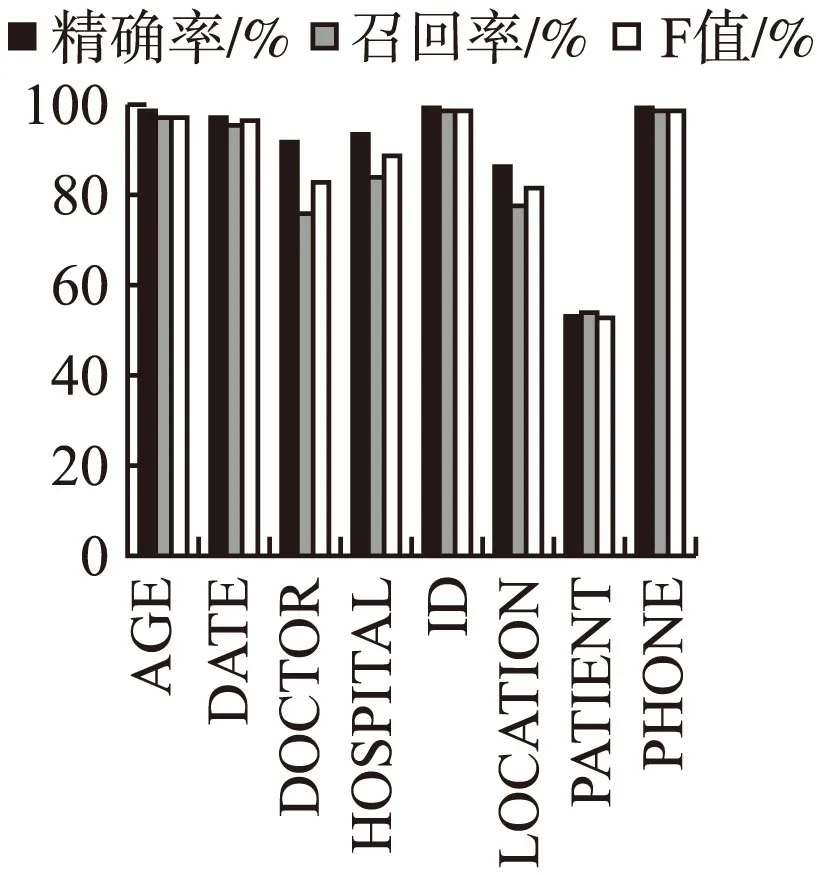
图10 妇产科文本命名实体识别结果Fig.10 Obstetrics and gynecology department NER results
6 结束语
对医疗文本中隐私实体的识别视为命名实体识别任务,提出了三种深层网络模型:深层条件随机场模型、BR-BiRNN模型、BR-BiLSTM-CRF模型.深层条件随机场模型将复杂任务分为多个子任务,每个子任务在不同层实现,针对命名实体识别任务,首先采用原子特征和组合特征检测实体边界,得到实体边界特征后,将此特征传入后层网络,识别实体类别输出标签序列.BR-BiRNN模型基于块表示方法,引入双向循环神经网络,将文本处理后表示为向量形式,自动提取特征,训练后输出预测标签序列.BR-BiLSTM-CRF模型结合了神经网络层和条件随机场层,由双向LSTM模型得到实体边界特征,传递给最后的条件随机场层输出实体标注结果.与传统的机器学习方法相比,深层网络模型在不同数据集上的F值都有所提高,提高了识别效果,说明了实验的有效性.后续工作将对如何更有效地自动提取特征,提高召回率以及提高复杂组织名和地名的识别效果进行探索.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国外汇(2019年18期)2019-11-25
当代陕西(2019年5期)2019-03-21
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
中国诗歌(2017年12期)2017-11-15
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
