
面向回填优化的作业时长预测
2019-01-24 09:29吴桂宝张文帅廖莎莎王琦琦
小型微型计算机系统 2019年1期
吴桂宝,沈 瑜,张文帅,廖莎莎,王琦琦,李 京,
1(中国科学技术大学 计算机科学与技术学院,合肥 230026)2(中国科学技术大学 超级计算中心,合肥 230026)
1 前 言
高性能计算目前在教育、工业设计等领域的应用需求越来越广,这种趋势在未来的应用越来越明显.它已发展成科学与工程技术问题研究的一种崭新的手段.在科研领域,各学科研究工作与日俱增的高强度的计算需求促使各超算中心更新或扩展设备来提高平台的服务能力,以致对硬件设备的投资越来越大.如何保证预设服务水平协议(SLA)[1],提高资源利用率,降低运行成本是超算中心亟待解决的主要问题之一.
在超级计算系统上,采用回填策略代替先到先服务策略是提高资源利用的一种有效手段,它主要思想是在尽量不延误某些作业执行下把队列后面某些作业提前调度,分配闲置资源.作业选择及回填时机决策是核心.目前已有很多与回填相关的研究[2,3],甚至主流调度系统(如LSF)都内置了回填算法.回填算法是否有效依赖对作业时长的可靠预计,而在实际系统中,用户往往不能提供准确的估计,或者为了保证作业的进行,而提供远远超过作业实际运行时长的预期运行时长.这使得不能在生产系统中直接使用用户提供的作业预期运行时长数据,而需要采用更有效的方法对作业时长进行有效的预测.
现已有很多工作尝试采用各种策略去建模预测网格计算、高性能集群中作业的执行时长.文献[4,5]提出了以代码静态分析为基础的程序预测方法,文献[6]提出基于卷积神经网络对作业脚本建模预测时间,但很多情况无法获得作业源码以及作业脚本,故本文主要探讨黑盒模式下的作业运行时长预测方法.文献[7]提出一种基于MPI通信日志循环收缩的并行作业性能预测方法,这种方法只适合通信骨架比较固定,CPU结点计算比较稳定的并行作业,并且无法在作业执行之前对其进行预测.文献[8,9]都基于K-最近邻算法进行时长预测,这种方法依赖于足量历史数据,且距离函数定义的合理性没有一个统一标准,很难有一个很好地预测效果.文献[10,11]提出一种使用“相似模板”的方法,根据任务特征对作业进行归类来对作业进行预测.文献[12]根据用户提交任务的行为模式来对用户聚类,针对用户所属的类中任务使用指数平滑预测.文献[13]和文献[14]分别使用最简单的滑动均值及Last2均值来预测.文献[15,16]作业性能预测都是基于一种预测多策略诸如Last2均值等最基础的策略来协同预测的模型,类似于组合预测方案,每个作业由一个决策模块来决定其由哪一个单策略模型来预测.这些方法只考虑了作业时长历史序列,易于实现,但对于不规律作业序列来说无法获得有效的预测精度,文献[17]提出使用L2规范化的多项式模型来拟合,但依赖历史时长序列.文献[18]使用PQR产生一颗二叉树,该二叉树的每个节点都是基于基本的机器学习及统计学方法,但是其研究的作业时长与说选属性有一类比较明确的关系,不适应难解释规律性弱的VASP作业.以上所述的方法基本都是基于比较泛化的日志信息来对作业时长进行预测,如队列、用户名、工作目录、计算规模等,这类方法对于规律性差的作业不能很好适应.故本文针对VASP特有作业特征建立预测模型,不依赖于历史作业序列波动性.
本文提出两种新的预测模型.其一是基于贝叶斯的二次预测模型(IRPA),以随机森林回归(RFR)、支持向量回归(SVR)以及贝叶斯岭回归(BRR)三个预测子模型为基石,针对VASP作业的配置参数来抽取特征,并对预测结果进行二次学习;其二是基于径向基神经网络(RBF)以及贝叶斯分类器的混合预测模型(BRBF).在实际系统收集中的作业样本的测试表明,我们提出的两种方法比传统的机器学习方法预测准确度和可靠性都有明显的优势.
2 研究对象与方法
我们以中国科学技术大学超级计算中心的“曙光TC4600百万亿次超级计算系统”(以下简称“TC4600集群”)上,从2017年3月到2017年11月实际运行的VASP作业为对象,研究VASP作业时间预测的方法.
2.1 数据预处理
TC4600集群上作业类型比较多,机时占比信息如图 1所示.数据表明,VASP作业机时占比已达一半,另外VASP作业占比数据统计也将近40%.故本文选择对VASP作业建立预测模型来对其执行时长进行预测,为后期资源的调度优化奠定基础.
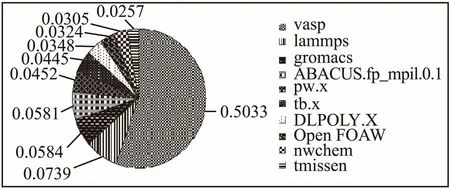
图1 TC4600系统上应用机时分布Fig.1 Distribution of time used by application on TC4600
我们首先抽取VASP的作业特征.作业特征取自工作目录下INCAR、POSCAR、POTCAR和KPOINTS四个文件,作业使用的CPU核心数和运行时间从作业日志中获取.
所抽取的作业特征属性集如表 1 所示.
表1 针对VASP作业抽取的特征属性
Table 1 Feature attributes extracted for VASP jobs

属性说明CORE-NUM作业使用的CPU核心数EXETIME作业使用的时间(Walltime)KPOINTSK点个数VOLUME系统体积PREC计算精度控制NELMIN电子自洽迭代最小步数EDIFF自洽迭代收敛标准EDIFFG原子弛豫收敛标准ICHARGE初始电荷密度构造方法ENCUT平面波切断动能ISYM体系对称性LREAL投影计算在实空间还是倒空间NELM电子自洽迭代最大步数NBANDS能带数量ISPIN是否进行自旋极化计算ISTART是否为续算
每个属性的具体含义以及缺失的默认值的计算方式可以参考VASP官方手册.
我们所选的数据集将所有ISTART值为1的作业排除在外,因为此类作业是重新调度从断点处执行的,这种情况下在没有额外信息时是无法预测的.
为了进行模型的建立,需要下面几个步骤将作业的信息转变为数值向量:
1)将参数数值化.对于IRPA模型,离散值属性将值one-hot编码成01向量,整个向量长度为属性可取值的个数,向量每个位置对应该属性一个可取的值.对于BRBF模型,离散值属性将值数字化,一个数字代表一个类型值.
2)将ECUT 值三次方,而后将所有连续属性值归一化.
3)EXETIME值取以10为底的log值,作为目标值.
2.2 数据特征分析
在我们考察的16700多个作业中,对作业时长按照每半小时进行分类,各类占比如表 2所示.
表2 作业运行时长分布
Table 2 Distribution of jobs runtime

时间范围/分钟作业占比0~300.55730~600.09660~900.04990~1200.033>1200.265
由于VASP作业的难预测性,我们很难用平均相对误差等传统的时间预测标准来评价模型预测的有效性,故这里我们使用准确率(ACC)和召回率(REC)来衡量预测模型对于作业时间长度进行分类的性能.ACC其定义如公式(1)所示,T表示一段时间范围(如30~60分钟),Spre(T)表示预测时间落在在T这个范围的作业集合,Strue(T)表示真实执行时间在T范围的作业集合.
(1)
召回率(REC)其定义如公式(2)所示,各标识含义同上.
(2)
通过分析VASP作业数据特征,首先采用比较合适的传统的机器学习模型RFR、SVR以及BRR来对作业时长的分类进行预测.同时采用文献[19]中基于parzen窗采样进行概率密度估计的纯统计的方法(PDR)作为一个对比实验的基准方法.RFR模型是对决策树和回归树的扩展[20],用于预测连续的目标值,SVR在文献[21]被用来预测旅行时间,BRR是对传统岭回归模型的拓展[22],这些方法都很适合时间预测的回归问题.
各模型预测的准确率和召回率如表 3和表 4所示.可看出:三种传统的机器学习方法在短时间作业上预测准确率和召回率都比较好,相对于PDR有更好的预测效果;再者,对于不同的情况,不同的方法互有优劣:RFR对于真实时长在30分钟之内的任务预测效果更好,SVR对于30~60分钟的作业预测比其他两个模型更精准,而BRR对于150~180分钟的作业的预测性能在三个模型中是最优的.
表3 各模型不同时间范围作业的预测ACC指标对比
Table 3 Comparison of ACC criterion of different models for jobs in different time range
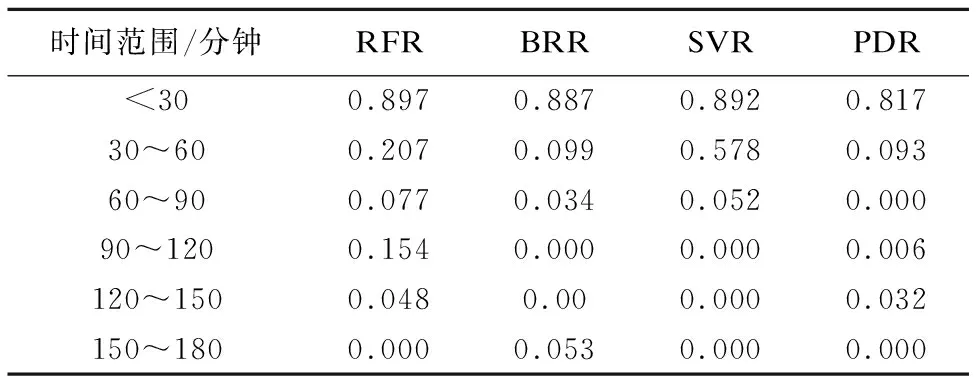
时间范围/分钟RFRBRRSVRPDR<300.8970.8870.8920.81730~600.2070.0990.5780.09360~900.0770.0340.0520.00090~1200.1540.0000.0000.006120~1500.0480.000.0000.032150~1800.0000.0530.0000.000
结合表 2的作业按执行时长的分布情况来看,在实际的回填策略中,其实我们对作业时长的预测没必要在过小的时间粒度下有很高的准确性,也没必要在每个时间范围都要求预测准确,这对于VASP来说很难实现的.因此,在下面的讨论中,仅分别以1小时和2小时为分界线对作业预测结果进行统计分析.因为如果我们能够较为准确的判断出短时间的作业,那么就可以用它们填补系统在等待大规模作业运行时的空闲时段,对于回填优化具有重要意义.
表4 各模型不同时间范围作业的预测REC指标对比
Table 4 Comparison of REC criterion of different models for jobs in different time ranges

时间范围/分钟RFRBRRSVRPDR<300.9840.9740.9670.47730~600.0360.0270.1110.26460~900.0530.2110.6840.00090~1200.1250.0000.0000.063120~1500.0210.0000.0000.064150~1800.0000.1000.0000.000
3 优化模型
由于VASP作业训练样本的特征空间的局部性,静态的预测模型无法一直正常工作,所以需要周期性训练来学习获取新特征空间特性以适应后续作业,整个VASP作业预测系统结构图如图2所示.
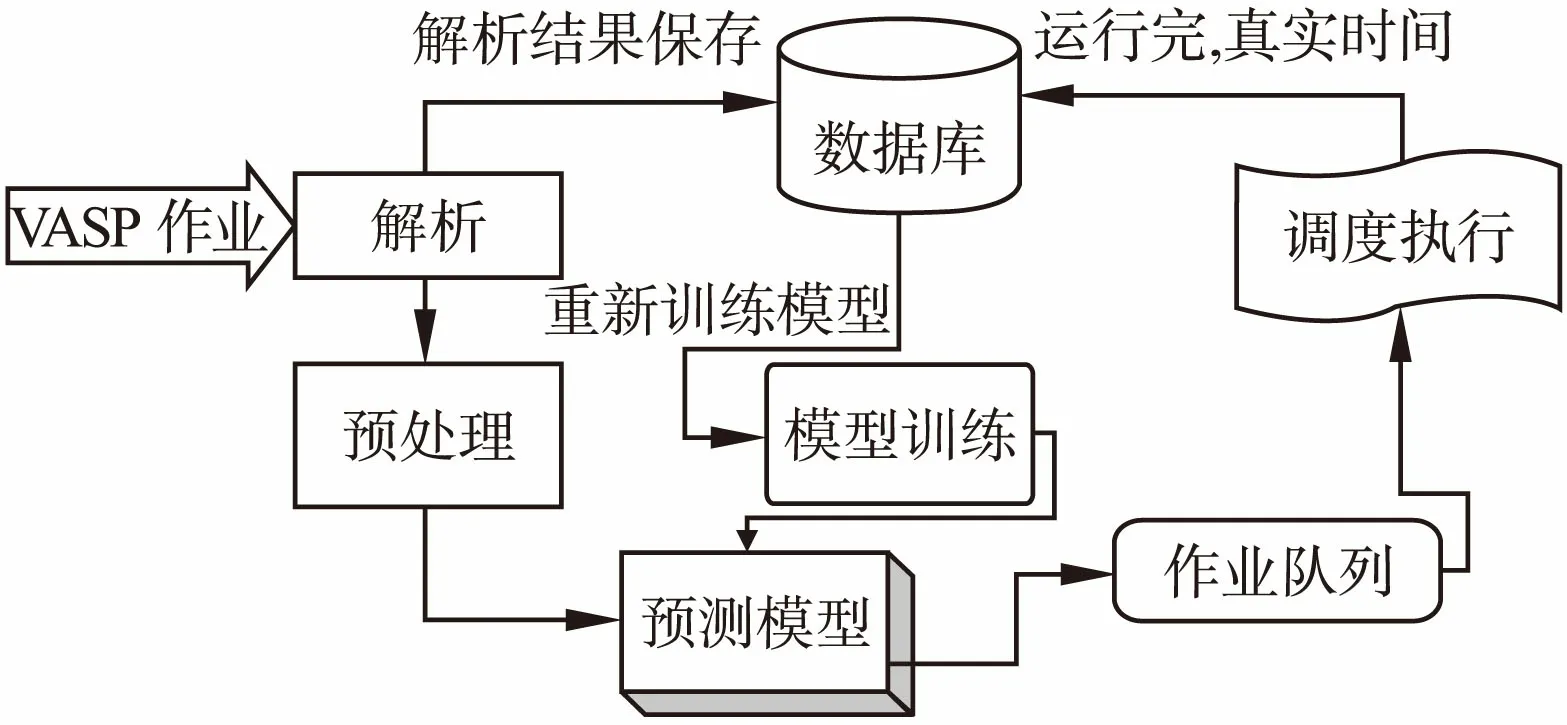
图2 VASP作业预测系统结构Fig.2 Runtime prediction system structure for VASP tasks
VASP配置参数值多为离散值,代表作业的一个计算标准.对于数值连续的属性,这些值大小与作业运行时长也并没有一类非常明确的函数关系,单一且基础的预测模型以及普通的回归分析可能无法带来更好的预测性能.
3.1 IRPA模型
鉴于上述情况和实际测试的结果,我们在三个比较适用的预测模型RFR、SVR和BRR的基础上,提出基于BAYES分类的二次预测模型IRPA.
IRPA结构如图3所示,子模型为RFR、SVR和BRR,上层模型为BAYES分类器,BAYES是一种以概率为基础的方法[23],可以用来综合各子模型优势.
训练模型时首先训练各个子模型,对于每个待预测作业,将子模型预测值与该作业的真实值进行对比,可以得到一系列四元组如公式(3)所示.
[pv1,pv2,pv3,label]
(3)
其中,pv分别为各子模型预测值,label对应预测值与真实值误差最小的子模型.针对系列四元组再训练一个BAYES分类器,label为目标变量.
整个模型建立好之后,对于一个新作业的到来,先通过预处理获取作业特征向量作为模型输入,子模型的预测结果作为RF分类器的输入,分类器输出一个对应每个标签的概率向量如公式(4)所示.
[pb1,pb2,pb3]
(4)
最后根据公式(5)计算出最终的预测值PV.
(5)
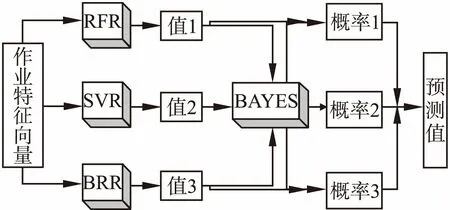
图3 IRPA预测模型结构Fig.3 Structure of prediction model IRPA
公式(5)中各变量和式(3)和式(4)描述的变量相同.
3.2 BRBF模型
鉴于VASP作业运行时长与特征很难有一个定性的函数关系来做拟合回归,而径向基神经网络(下面统称RBF模型)是通过径向基函数(RBF)来做非线性变换[24,25],训练时利用样本内插值的方式来拟合任何未知的函数(包括非线性函数),这就是RBF的优势及魅力所在.
故BRBF就是基于RBF模型的,其模型如图4所示,分类是以ISPIN,ISYM,LREAL以及PREC四个离散属性值作为key来分类,若存在key对应的RBF子模型,则使用该子模型来对作业特征x进行预测.否则,使用BAYES和RBF相结合的泛模型来进行时间预测.
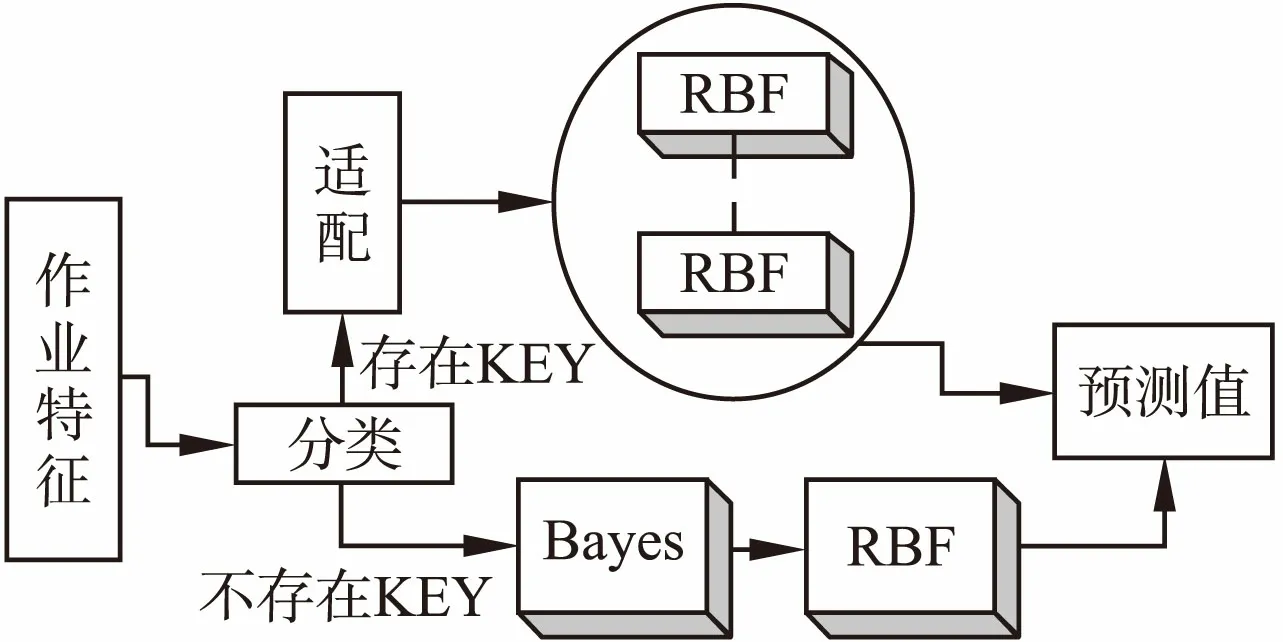
图4 BRBF预测模型结构Fig.4 Structure of prediction model BRBF
泛模型是指针对整个训练数据集训练的RBF模型,本文根据作业时长分布划分为56个时间段,泛模型是把一个贝叶斯分类器在每个时间段的概率输出作为RBF模型的数据源.BAYES分类器对于n维特征x判定为类yi的概率如公式(6)及公式(7)所示.
(6)
(7)
而对于x中值连续的属性xk来说,其条件概率如公式(8)及公式(9)所示.
P(xk|yi)=g(xk,μyi,δyi)
(8)
(9)
输出结果为一个分类(时间范围)概率向量X,如式(10)所示,最后该X向量是作为一个RBF网络的输入,以预测最终的执行时间.
X=[P(y1|x),P(y2|x),…,P(ym|x)]
(10)
整个BRBF模型的训练如步骤如下所示:
1)针对整个训练集Atrain预处理作业特征,根据每个作业key来分类.
2)对于同一个key作业数>3000的作业集B的数据,只取连续值属性并进行归一化处理,针对该数据集B训练子RBF网络,RBF网络结构如图5所示.

图5 RBF神经网络结构Fig.5 Structure of RBF neural network
3)针对所有训练数据集Atrain按作业ID排序,前60%作业执行时间离散为类别(时间范围),训练一个BAYES分类器.
4)后40%作业作为BAYES分类器测试集产生概率向量集X,以此来规范RBF输入.
5)将X作为RBF输入,log(time)作为目标值,训练一个总RBF模型.
RBF可以处理传统方法难于解析的规律性,具有非常良好的泛化能力,在很多领域诸如多分类,故障检测以及回归分析等得到成功应用[26,27].
为了防止RBF网络过拟合,我们对RBF训练数据集聚m(文中m值为56)个类,对于类p都有一个由均值向量μp以及一个偏扩展常数δp确定的径向基,预测输出函数如公式(11)及公式(12)所示.
(11)
(12)
由于带中心化的RBF的等式组行数远大于列数,即训练样本数p远大于径向基个数m,如公式(13)所示.
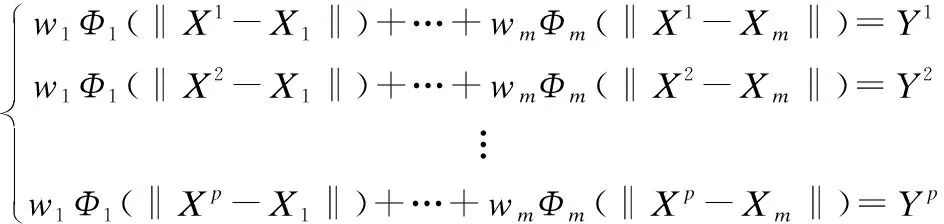
(13)
再者预测模型周期性训练时要求训练速度尽可能快,所以通过计算Ф的伪逆Ф+来计算W权值,计算见公式(14)和公式(15)所示.
W=Φ+Y
(14)
Φ+=(ΦTΦ)-1ΦT
(15)
4 实验结果与分析
整个实验所用的数据集A为TC4600平台上采集的16700多个VASP作业,该实验面向真实生产环境,A按作业ID排序(时间先后).将A划分两部分,前80%作为模型训练集Atrain,后20%作为模型的测试集Atest.对于IRPA模型,Atrain的前60%作业作为各子模型的训练集,后40%作为它们的测试集,之后,基于测试集的预测结果与其对应的真实值构建如式(1)所示的四元组,作为下一层BAYES分类器的训练数据集.总之,Atrain用来训练整个模型,Atest用于测试IRPA以及BRBF两个模型的预测性能.
为了说明我们所提出模型的优越性,我们使用一些基准预测模型作为IRPA以及BRBF模型的实验对照组.图 6是按照一小时为界限的分类预测情况,五种方法分别是传统的三种机器学习方法RFR、SVR、BBR和我们设计的两种预测新方法IRPA、BRBF.每种方法左侧的空白柱状图表示准确率,即预测出来的短时作业有多大的几率真实运行时间小于1小时.右侧斜线柱状图表示召回率,即对于所有小于1小时的短时间作业,预测出来也是短时间作业的有多大的比例.
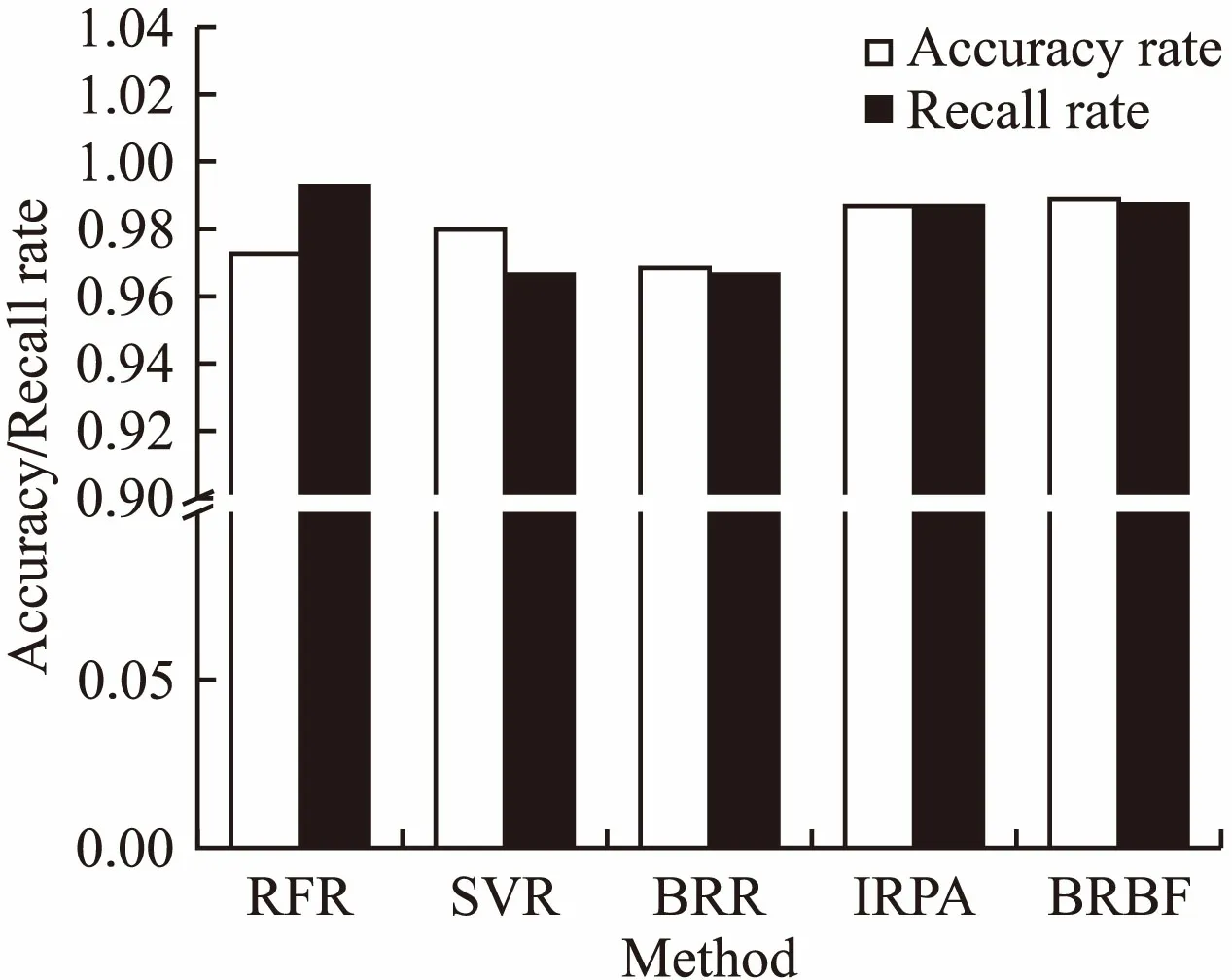
图6 按1小时划分的预测结果比较(16700个样本)Fig.6 Comparison of prediction for 1-hour division (16700 samples)
一般来说,准确率和召回率很难同时提高:如果想提高准确率,那么就要对判定条件要求更为严格,会造成处于临界点附近的作业更倾向于被否定,从而造成召回率降低;而如果想提高召回率,那么就要对判定条件要求更宽容,同样会降低准确率.
从图 6中可以看出,同时考虑准确率和召回率,我们的两种新方法IRPA和BRBF比传统方法RFR、SVR和BRR都要好,它们的准确率高于其它方法.而且BRBF模型在REC值比肩IRPA模型的情况下具有最高的预测准确率.
图7是按2小时为短时间作业和长时间作业的分界点测试的结果.这里传统方法召回率更好,但准确率下降,尤其是SVR,准确率显著下降.而我们的新方法,在召回率有所提高的基础上,有效的避免了准确率的下降,显示出更好的稳健性.
而且,就目前生产系统上VASP作业时长分布,很大一部分都是短作业,所以资源预留时作业队列中一般不乏短时长作业,所以此类情况下预测的准确率往往更加重要.其次,为了说明模型的有效性,我们把每个方法预测时长小于1小时的作业按绝对误差升序排序,取前90%算平均相对误差(MRE),这样做是为了排除某些未考虑因素而导致的MRE异常偏高,再者面向回填的预测只关注预测较准确的90%已意义重大.MRE结果如表5所示,可以看到BRBF的MRE是最低的,其次是IRPA,BRBF就MRE比IRPA提升约12.3%,该两个模型就MRE来说相对其他几个子模型有明显的优势.
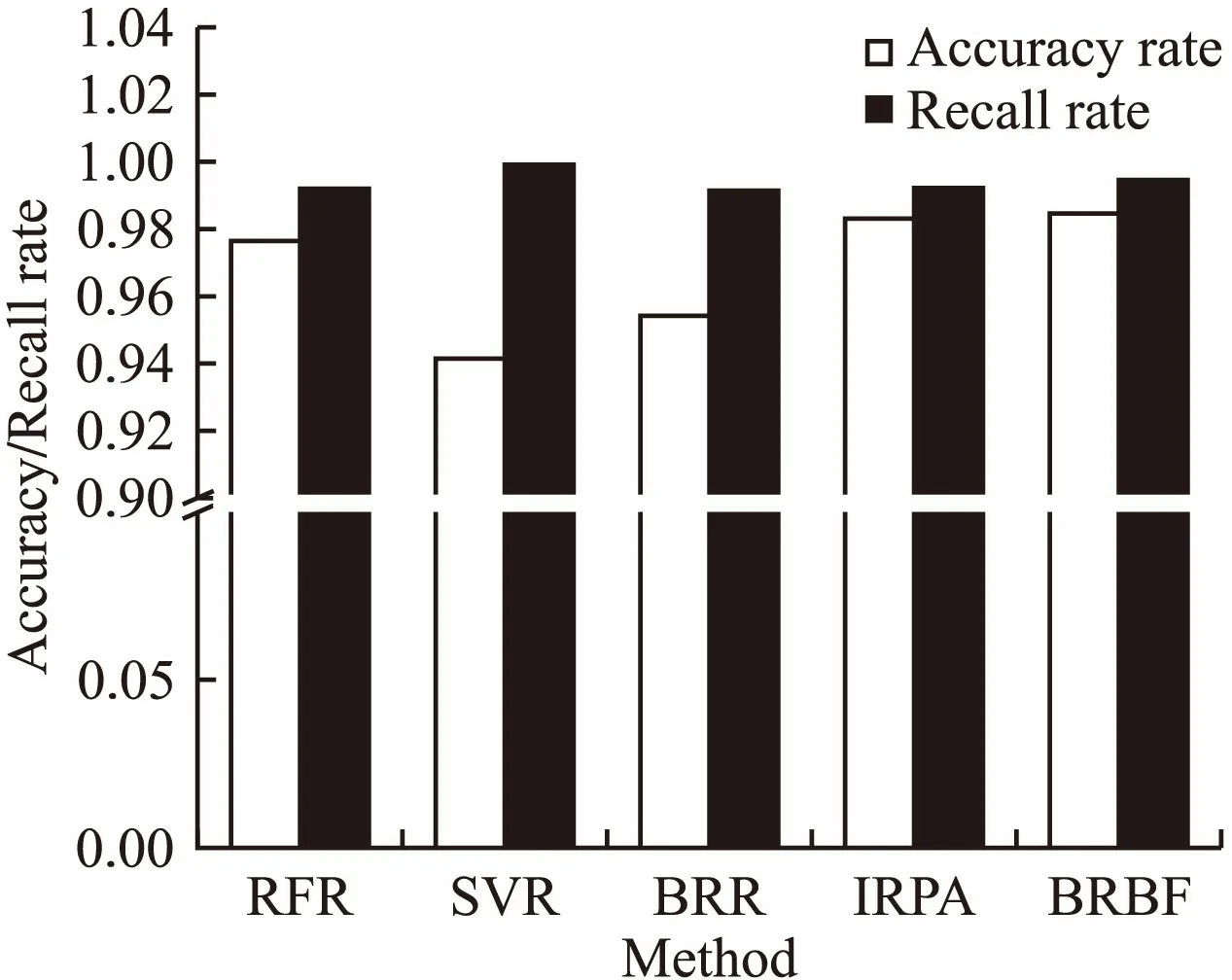
图7 按2小时划分的预测结果比较(16700个样本)Fig.7 Comparison of prediction for 2-hour division (16700 samples)
表5 各模型预测1小时内作业前90%的平均相对误差
Table 5 Mean relative error for the first 90% of VASP jobs which predicted within 1-hour

模型MRERFR0.268SVR0.372BRR0.532IRPA0.203BRBF0.178
上面的任务测试集中,超过90%的任务时长都小于1个小时,导致测试结果差别不太大——即使按照90%比例完全随机选择,也会有接近90%的概率猜中小于1小时的短时长作业.我们选择了另外一段时间5600多个VASP作业数据进行测试.整个VASP实验数据集的测试集中,约68%的作业时长在1小时内,接近75%的作业执行时间在2小时内.由于作业数据集过小,而BRBF训练依赖于较大的样本数,因此只能测试IRPA与其他基准方法.为了进一步说明我们工作的有效性,我们增加了文献[12]的方法UBCETE作为对照组,按照1小时和2小时分类的预测结果如图8和图9所示.可以看出:首先IRPA在两个分类情况下都具有最高的准确率,尤其是相对于真实占比来说优势很大,尽管在召回率上稍差,但对于为回填算法提供小作业的预测来说,准确率更重要;其次,SVR在1小时分类的情况下,召回率严重下降,而IRPA模型则在两种分类的情况下都有稳定的性能;最后,UBCETE方法的预测准确率整体来说较低,相比其他基本方法没有任何优势.这很大程度是由于用户行为的不规律性以及VASP作业内部的复杂性.
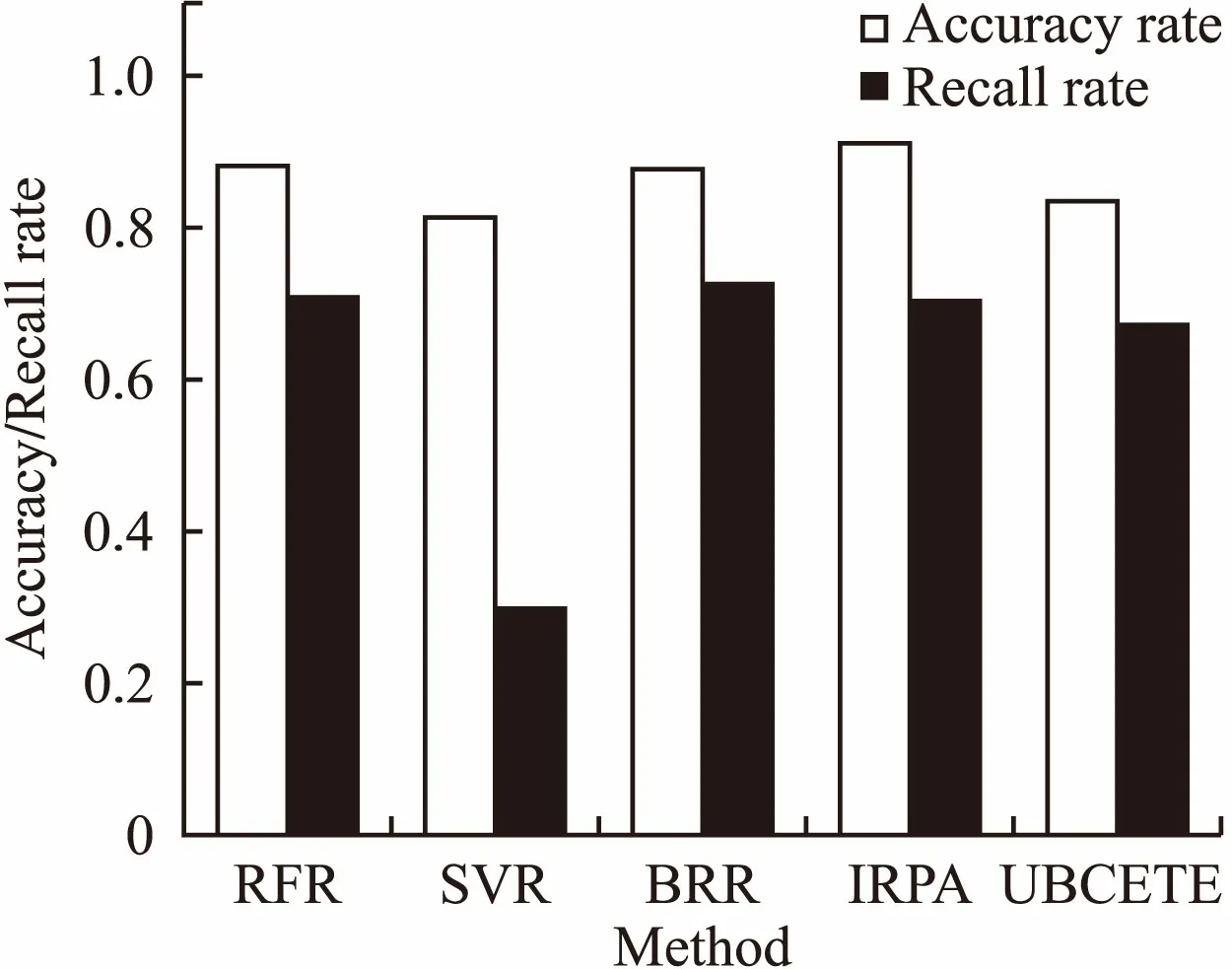
图8 按1小时划分的预测结果比较(5600个样本)Fig.8 Comparison of prediction for 1-hour division(5600 samples)
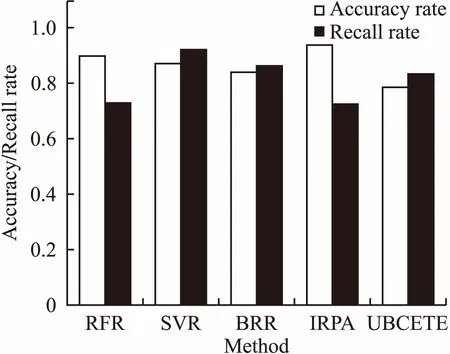
图9 按2小时划分的预测结果比较(5600个样本)Fig.9 Comparison of prediction for 2-hour division(5600 samples)
5 结 语
传统的作业时间预测方法往往适应的是内部计算模式比较简单稳定或者作业序列具有较强规律性的情况,但是由于VASP作业本身的复杂性及不确定性,这些方法无法简单根据调度系统日志信息以及作业历史序列来对VASP作业执行时间进行预测.故我们通过解析VASP输入文件,并且结合资源需求特征提出了二次预测模型IRPA和基于神经网络的混合模型BRBF.IRPA通过BAYES来综合各个子模型的优势来达到更好的预测准确率,并且通过概率权重使得预测更加稳定.BRBF通过特定特征分类后训练子RBF网络,并且利用BAYES输出概率规范泛模型中RBF的输入,以此来获得对预测性能的优化.
鉴于这些模型的准确性依赖于训练集样本在特征空间的分布,因此未来的工作一方面是将尝试将这些模型由静态训练拓展成增量式训练,以此达到动态学习的目的.另一方面我们将使预测模型与回填调度相结合,通过分析资源的优化效率来显式评估这些预测模型的价值.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
电子产品世界(2022年4期)2022-04-21
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
计算机系统应用(2021年2期)2021-02-23
健康体检与管理(2021年10期)2021-01-03
