
一种基于词向量的模糊查询扩展方法
2019-01-18 12:42:24陈淑巧江海欢
四川师范大学学报(自然科学版) 2019年1期
陈淑巧, 邱 东, 江海欢
(重庆邮电大学 理学院, 重庆 400065)
随着高速发展的互联网时代的到来,网络已经成为人们获取信息、了解世界的重要方式之一.目前,全球互联网用户总量已经超过10亿,随之而来的是互联网上文本信息数量的不断增加,个人和组织拥有的文本信息数量也呈几何级数增长.因此,如何在日益增长的数据流中得到有价值的信息,是目前研究的一个十分重要的课题.
传统的信息检索技术,是基于普通集合和布尔逻辑进行检索,以经典集合论和布尔代数为理论基础[1],通过将需要检索的文本信息表示成布尔表达式的形式,与用户所查询的表达式进行逻辑比较,进而得到所需的相关文本,采用此方法进行检索的模型,就是常说的布尔检索模型[2].由于查询简单且容易理解,也是生活中最常见的检索模型.在传统的布尔检索模型中,没有相关度的概念,这导致检索结果不能按照对查询的相关性进行排序输出,且检索出的结果取决于查询与文本信息的匹配情况,控制输出量的难度大.同时,文本信息只有完全匹配时才能将其检索出来,但是在现实生活中存在大量的模糊性信息,如果使用布尔检索模型很难得到理想的检索效果.1989年,Yasushi等[3]等在模糊集合论的基础上,首次提出了基于词词关联矩阵的模糊检索模型.考虑到基于词词关联矩阵的模糊检索模型只根据词词之间的相关性,而忽略了查询词与整个查询信息之间的关联性,造成“词不匹配”问题.2000年,Mandala等[4]提出通过引入相似性叙词表来实现查询扩展.2007年,马晖男等[5]在此基础上,提出了通过使用WordNet之类的语义词典,在查询项中加入其相关的同义词进行模糊查询扩展.2012年,Liu等[6]等提出利用本体库,将查询信息映射成为本体中的概念,来达到语义扩展的目的.
针对“词不匹配”问题,大部分学者都试图通过已知标定信息,对相关查询语句进行扩展,降低该问题对检索效果的影响.但互联网上信息的飞速膨胀,导致大量无标注数据的出现,如何学习到大规模无标注信息中有价值的内容,成为了一大难题.2006年,Bengio等[7]首次正式提出神经网络语言模型,并在利用该模型学习语言的过程中,提出了词向量的概念.其采用局部梯度下降对权值进行调整,但这样利用非凸目标函数进行求解会导致局部最优.2007年,Hinton等[8]提出了利用多层人工神经网络模型,进行逐层训练的想法,打破了此前神经网络发展的瓶颈.由于在以往的神经网络语言模型中,只考虑到利用神经网络对语言模型进行建模,而忽略作为模型训练结果之一的词向量,使得词向量没有达到很好的效果.2013年,Mikolov等[9]在Hinton的想法上,设计出效果更好的词向量的CBOW(continuous bag-of-words)模型.利用CBOW模型,可以将无标注的文本信息简化成向量空间中的向量进行计算,得到向量空间上的相似度,也就是说此模型训练得到的词向量不受查询信息和文本内容等标定数据稀疏的影响.
本文利用CBOW模型训练出的词向量的这一优点,以词向量计算出的相似词作为查询信息的扩展项,提出一种对模糊检索进行基于词向量的查询扩展方法,以改善模糊检索中出现的“词不匹配”问题.
1 模糊检索
布尔检索模型是最传统也是最成熟的检索模型,在信息检索领域中有着广泛的应用,模糊检索模型则是在布尔检索模型的基础上,结合模糊集合理论进行改进后的产物[2-3].它定义了查询语句与相关文献之间的模糊关系.模糊检索模型将文本信息与查询数据在一定程度上相关起来,对查询语句中的每一个词假设存在一个包含模糊文本信息的集合与之相关.也就是将每一个查询词定义为一个模糊集合,集合中的元素是进行检索的文本信息.检索文本信息集中的每一篇独立的文本,对每一个查询语句中的查询词都有一个隶属度.
1.1基于词词关联矩阵的模糊检索
1.1.1构建关键词矩阵 词词关联矩阵[3]是由相关文本信息中提取的关键词与查询词之间的语义关系值组成的词词矩阵,即以关键词与查询词共同组成的集合中的元素作为行、列.假设词词关联矩阵用Wk×k表示,则k表示集合中元素的个数.矩阵中的元素wij,对应词i和词j之间的语义关系值,它表示2个词之间的语义相似度,为了使其取值范围在区间[0,1]内,使用(1)式进行计算
w
(1)
其中,Nij表示同时含有词i和词j的文献数量,Ni和Nj分别表示含有词i和词j的文献的数量.当wij取为0时,表示2个词之间的语义几乎完全不相关;当wij取为1时,表示2个词之间的有最强的相关性.
1.1.2利用关键词矩阵计算隶属度 对于模糊检索模型来说,每一个查询词都对应一个包含模糊文本信息的集合.令Di表示与词i相关的模糊文本信息集合,则对于任意一篇独立的文本信息dj,它隶属于集合Di的隶属度Rij[2]用(2)式进行计算
R
(2)
其中,Wik表示词i和词k的语义关系值,词k是独立文本dj中的词.⊕是定义如(3)式的模糊算子[3]
(3)
则(2)式,即任意一篇独立的文本信息dj,它隶属于集合Di的隶属度Rij可化简为:
Rij=1-
(4)
1.1.3转换用户查询 通常在检索时会向计算机输入一条包含多个查询词的查询语句,传统的布尔检索将这些查询词之间的关系,用布尔逻辑表达进行替代.而模糊检索模型则是利用“真值表法”[10],将查询语句转换成为由极小项组成的主析取范式[3],其中,令Q(h)-表示查询语句中起否定作用的查询词的集合,Q(h)+表示查询语句中起肯定作用的查询词的集合,则任意一篇独立的文本信息di,隶属于整个查询语句的隶属度Ti(h)为
(5)
其中Rij表示独立文本信息di对于相应的查询词的隶属度.
2 词向量
词向量技术是一种通过对语言模型中的词进行分布式表达的词表示方法.其在训练过程中将词转化成为稠密向量,且该向量对于相似的词,对应向量间的距离也相对相近,因此,可以利用词向量来计算词词之间的相似度.CBOW模型是Mikolov等[9]在2013年提出一种训练词向量的模型.如图1所示的CBOW模型网络结构,从中可以看出CBOW模型包含3层:输入层、投影层和输出层.输入层为对应输入上下文的one-hot编码,投影层将输入的初始向量进行求和累加,输出层对应一个树结构,它是以上下文中的词作为叶子节点,各词在语料信息中出现的次数作为权值构造的树结构.CBOW模型的核心思想是在已知当前词wt的上下文wt-2、wt-1、wt+1、wt+2的情况下预测词wt.

图 1 CBOW模型网络图
Mikolov等[11]在提出CBOW模型时,分别给出了基于分层Softmax和负采样技术的2套设计框架来提升最后一层神经网络的效率.本文采用的是负采样技术,其借鉴了C&W模型[12]中构造负样本和噪声对比估算(NEG)的方法[13],来提高训练速度并改善所得词向量的质量.假设需要预测词w,已知词w的上下文C(w),则对于已知的C(w),词w是一个正样本,其余的词为负样本.通过已知上下文C(w)的负样本对目标函数(即(6)式)进行最大化
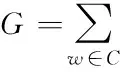
(6)
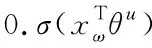
再利用随机梯度上升法对(6)式进行优化,分别考虑G(w,u)关于θu和xw的梯度计算:
(7)
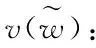
θu=θu+η[Lw(u)-σ(xTwθu)]xw,
(8)
这样,达到了增大正样本概率的同时降低负样本概率的目的,训练出优质的词向量.
3 基于词向量的模糊查询扩展
3.1查询扩展众所周知,在自然语言中,一个词语可能表达几种意义,同样几个不同的词语可能表达相同的意义[14].当进行检索查询时,计算机可能不会将包含与输入的查询词意义相同、但词语不同的文档返回.查询扩展便是通过增加与查询词有相似语义的词进行检索改进查询效率.本文利用CBOW模型训练得的词向量,计算查询项的相似词,对查询项进行扩展,具体步骤如下:
1) 对输入查询语句进行分词、词性标注.为避免无用信息的干扰,对语句进行去停用词处理.保留查询项中的形容词、副词及被其修饰的查询核心词,将其组成查询项的关键词集合.
2) 提取关键词集合中相关词的词向量.利用空间向量的余弦距离,即通过(9)式计算词之间的相似度:
sim(X,Y)=cos
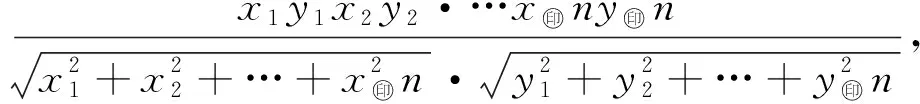
其中X(x1,x2,...,xn),Y(y1,y2,...,yn)为空间中任意2个向量,θ为两向量的夹角.
3) 取与对应词相似度最大的前N个词,作为扩展项.
3.2模糊查询扩展方法的基本流程基于词向量查询扩展的模糊检索方法流程如图2所示,主要通过一下步骤进行检索:
1) 构建一个大规模无标注数据集,并通过分词、词性标注、过滤停用词进行预处理操作,在此基础上对处理后的数据集采用CBOW模型进行训练,得到相应的词向量;
2) 构建作为检索内容的文本信息数据集,同样通过分词、词性标注、过滤停用词的预处理操作后,从每一篇文档中提取20个关键词(这些关键词能大体概括该文章的内容);
3) 对查询语句进行预处理,根据余弦距离计算出相似度,将查询项中的每个词,扩展N个相似词,并把查询语句转换为极小项的主析取范式;
4) 利用提取的关键词与扩展后的查询词,组成词词关联矩阵,得到词与词之间的关系值,历遍整个数据集,计算出每篇文章隶属于查询语句的隶属度;
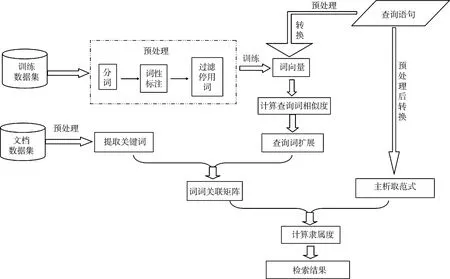
图 2 模糊查询扩展方法流程图
5) 排序后输出相应检索结果.
4 实验与分析
本文设置了2组实验.第1组实验,在同一组文本数据集下对基于词向量的模糊扩展检索和基于词词关联矩阵的模糊检索进行综合对比实验.第2组实验,就不同查询扩展项的数量N对模糊检索效率的影响进行了分析.
4.1实验数据为保证实验的可靠性,本文将3.2 G的维基百科中文语料和在网上爬取的包含政治、经济、文化、医学、历史等多方面共17 901篇文章和新闻语料作为CBOW模型的语料训练集.分别从政治、军事、经济、文化、医学、历史、体育等9个领域各选取150篇共1 350篇文献,作为文本数据集进行检索.
4.2评价标准一般地,评价信息检索系统的性能水平采用查准率ρPr(precision)和查全率ρRe(recall)作为量化指标[15].
查准率是指检出的相关文献数占检出文献总数的百分比,反映检索准确性,其补数就是误检率;查全率是指检出的相关文献数占系统中相关文献总数的百分比,反映检索全面性,其补数就是漏检率[16]:
ρPr=
(10)
ρRe=

从(10)、(11)式可以看出查全率和查准率之间存在一定的互斥性.当提高查全率时,查准率便会相应的降低;当降低查全率时,查准率便会相应上升.为了更准确的判断检索效率,这里还加入了查全率和查准率的调和平均值H(harmonic average)这一指标进行判断,即
(12)
为得到实验数据,计算出相关比例,让20名实验人员,分别对检索结果进行选择,综合20人的意见得到每个查询的相关文档.
4.3实验过程与结果分析本文用CBOW模型训练,将词向量维数设置为100,上下文窗口大小订为5,保留词语出现频数大于1的词,并取0.025作为模型的学习率,进行100次迭代训练,得到相应词向量,表1为词向量训练结果的抽样.
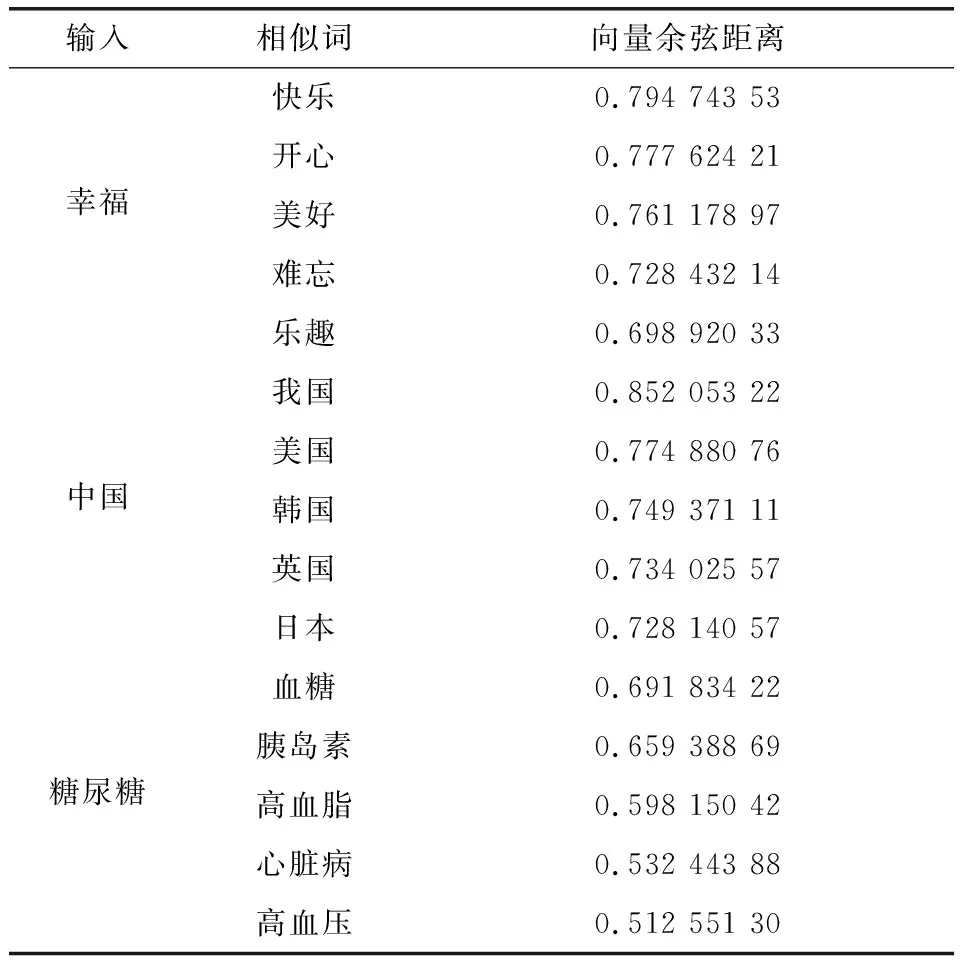
表 1 词向量训练结果抽样
从表1可以看到,通过计算词向量间的余弦距离能较为准确地找到与目标词有相似语义环境的词.
4.3.1综合对比实验 在包含9个不同领域、共1 350篇文献的数据集中,把查全率、查准率和两者的调和平均值作为评价指标,将阀值φ取为1,分别使用基于词词关联矩阵模糊检索和经过词向量查询扩展,将扩展项数量取N=5后进行检索实验,实验结果如表2和图3 所示.
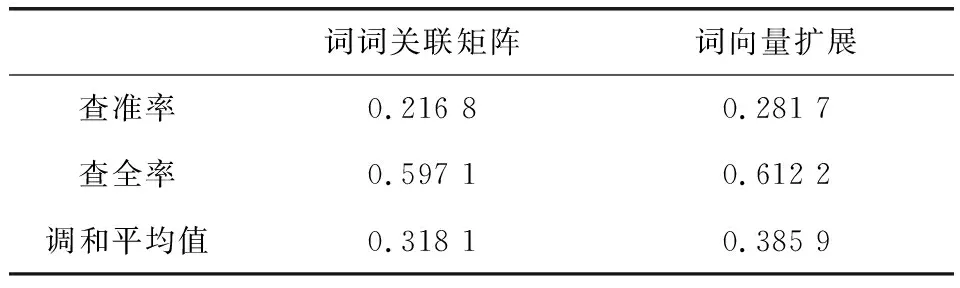
表 2 综合实验对比结果
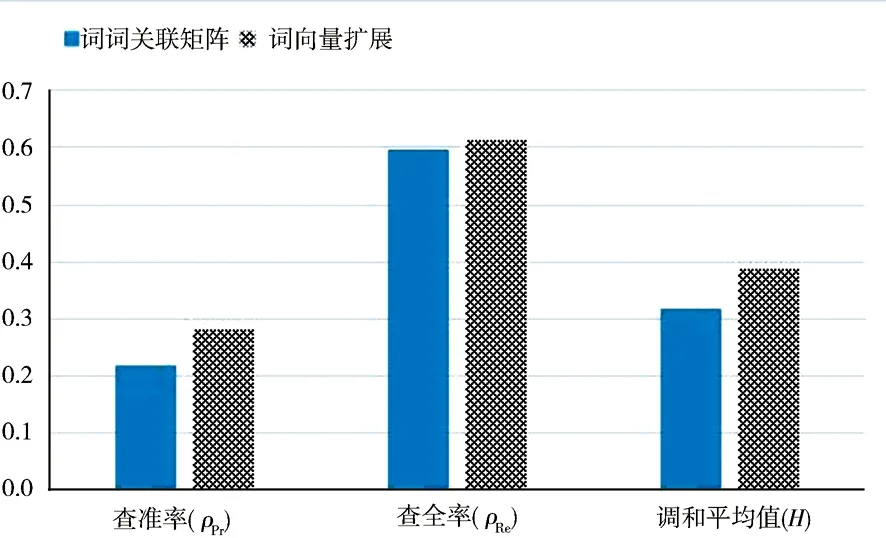
图3检索结果对比柱形图
Fig.3Columnchartofretrievalresults
可以看出,通过查询扩展改进后的模糊检索模型评测的结果优于基于词词关联矩阵的模糊检索模型,查全率、查准率及两者的调和平均值分别提高了1.51%、6.49%和6.78%,说明基于词向量的查询扩展可以改进查询效果,从一定程度上克服“词不匹配”问题.
4.3.2查询扩展数N的分析 本文中关键的一步是利用词向量计算得出查询项的相似词,利用相似词对查询项进行扩展.如何取到最合适的查询扩展数N的值,保证检索效率达到最优是一个值得探讨的问题.下面通过依次取N=0,2,4,5,6,8,10,12,14,15,16,18,20,22,24,26,28,30,以查全率和查准率的调和平均值为评价标准,进行实验,实验结果如图4 所示.
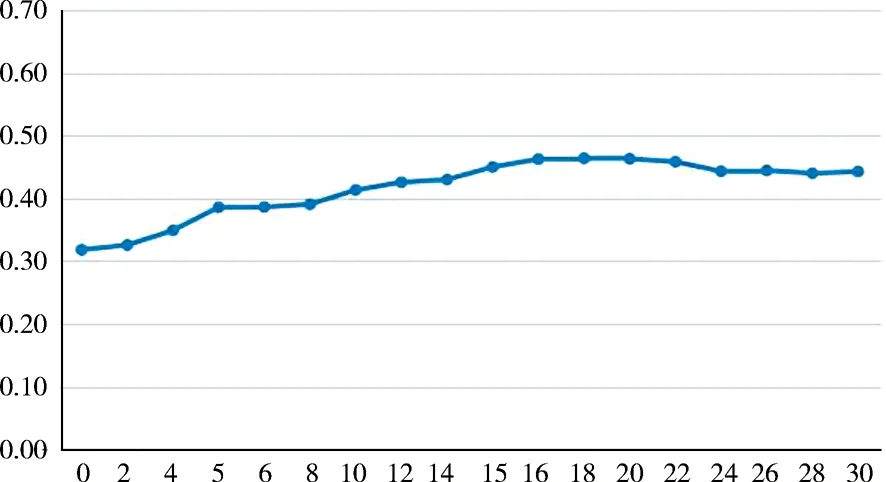
图 4 扩展数N分析图
从图4中可以看到随着参数N的变化,查全率和查准率的调和平均值也跟着改变.当查询扩展数N∈[0,15]时,调和平均值不断增加;当查询扩展数N∈[15,20]时,相对的调和平均值逐步达到了最大值;当N>20时,调和平均数相对有所降低,但基本保持平稳状态.这是因为随着N不断增大,扩展项的数量不断增多,但扩展项与对应的查询项的相似度却开始降低.所以在进行查询扩展时,最好取N∈[15,20]作为相应扩展项的数量.
5 结束语
本文结合词向量和词词关联矩阵,提出一种新的模糊扩展查询方法,改善了因大规模无标注数据导致的“词不匹配”问题.实验表明,相对于传统的基于词词关联矩阵的模糊检索模型,基于词向量的模糊扩展查询方法对模糊检索效果有所提升.本实验只初步地对此方法进行了探索,很多环节还待进一步完善.未来将在本文的基础上尝试取不同阀值对文本进行检索,扩大训练语料库,改进关键词的提取方法,提高检索效率.
猜你喜欢
贵州师范学院学报(2022年12期)2023-01-16 11:32:06
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19 08:38:40
现代电子技术(2018年20期)2018-10-24 04:39:04
现代情报(2018年11期)2018-01-07 09:41:14
现代电子技术(2017年23期)2017-12-20 13:23:31
长春师范大学学报(2017年8期)2017-09-03 10:02:59
计算机应用(2016年10期)2017-05-12 11:02:20
湖北民族大学学报(自然科学版)(2016年3期)2016-11-29 01:27:41
计算机光盘软件与应用(2013年6期)2013-08-08 08:26:50
中国管理信息化(2009年10期)2009-06-19 08:24:28
