
遮挡条件下实时人脸检测*
2019-01-15 08:15:34陈春燕
传感器与微系统 2019年2期
蒋 婵, 黄 晁, 陈春燕
(1.宁波大学 信息科学与工程学院,浙江 宁波 315211;2.宁波中国科学院信息技术应用研究院,浙江 宁波 315100)
0 引 言
人脸检测是计算机视觉领域的研究热点,是其他人脸分析任务的基础,自然环境下,人脸图像受光变化、遮挡、多姿态等不可控的外界因素的影响。造成遮挡的原因有多种,如墨镜、围巾和外景物的遮挡。在检测时,遮挡区域会在图像中产生噪声,极大地影响了人脸检测的准确率。因此,如何减小遮挡的影响,成为了人脸检测技术中亟待解决的问题。
目前人脸检测方法主要包括:基于先验知识的方法[1,2]、基于特征的方法[3~5]、基于模板匹配[6,7]的方法和基于统计的方法。基于先验知识的方法利用人脸具有的特殊结构和形状为先验知识,设计相关启发式算法。这种方法受外界因素影响较大。基于特征的方法主要利用人脸的不变特征进行检测,该方法运算量小,受姿态、光照等外界因素影响不大,对图像质量要求较高。基于模板匹配的方法的准确率较高,模板初始化等操作运算量很大,对图像质量要求很高,受外界因素影响较大。基于统计方法的思想是使用机器学习方法建立统计模型的分类器,然后用分类器进行人脸检测,这种方法的性能取决于机器学习算法对训练样本的学习能力。机器学习算法又可以分成基于概率模型的方法、基于神经网络的方法、基于支持向量机的方法和基于AdaBoost算法的方法。还有一些研究使用了AdaBoost与先验知识相结合的方法,如文献[8]提出了一种AdaBoost 算法和肤色校验相结合的人脸检测方法,有效地提高了人脸检测率,文献[9]使用AdaBoost 算法与肤色特征及几何特征相结合,提高了多角度、多姿态下的人脸检测率。但对于遮挡进行处理的研究并不多。
针对上述问题,本文提出了一种实时的用于遮挡条件下的人脸检测方法。实验验证了本文方法的有效性。
1 样本数据增强
在训练AdaBoost分类器时,需要大量的训练样本,遮挡情况下的训练样本不足,导致了算法对遮挡人脸的学习能力受限[10]。为此,本文提出了一种数据增强的方法,首先对训练集进行手动遮挡处理,然后使用了平均脸的策略,有效地对遮挡区域进行分割和处理,获得类似于自然环境下的遮挡图像,以更好地训练人脸检测器。图1为利用平均脸方法进行训练样本处理的流程。
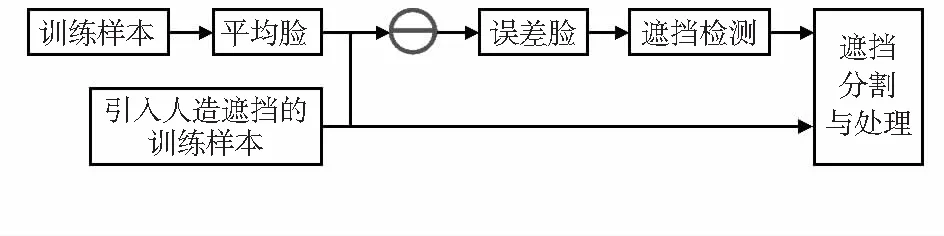
图1 训练样本处理流程
1.1 样本准备
训练图像选用Yale B人脸库。该数据库共包含64种不同的光照情况,分为五个子集,本文选用Subset 1子集(正常光照下采集的图像),Subset 2和Subset 3子集(分别为轻微和中度光照影响的图像)作为训练集。
首先计算3个子集中所有训练样本的平均脸图像。将Subset 2和Subset 3子集图像的眼睛、鼻子和嘴巴分别引入人造遮挡图像,如图2所示。对这些遮挡图像进行处理得到与自然环境下遮挡情况相似的遮挡样本,与3个子集一起作为训练正样本,从而达到数据增强的目的,负样本选择非人脸的图像。
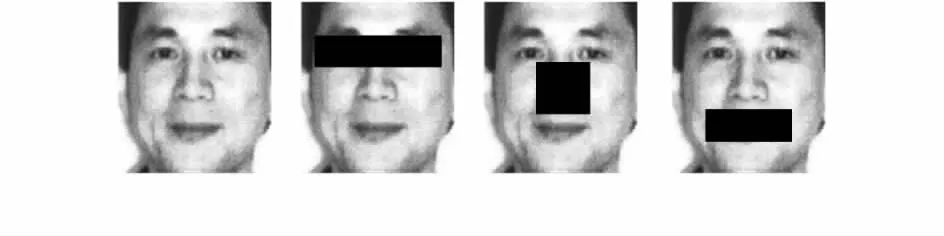
图2 引入人造遮挡图像的样本示例
1.2 平均脸计算
平均脸通过给定的训练样本取平均值得到,其计算过程如图3所示。
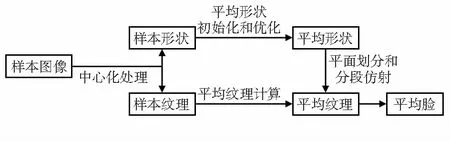
图3 平均脸计算过程
样本中心化将所有图像中的人脸移动到图片的中心,便于平均脸的计算。中心化分为两步,首先将图像中所有的特征点的横纵坐标分别相加,然后除以特征点的个数得到每幅图像中人脸当前的中心点坐标,然后进行中心坐标到图片中心坐标的变换,人脸中所有特征点均进行这样的变换,即实现了所有形状样本的中心化。平均特征点位置初始化就是简单的平均位置计算,即对所有样本图像中对应的人脸特征位置的坐标数值进行求和取均值得到的。
1.3 遮挡分割和处理
遮挡区域检测是后续遮挡区域处理的关键一步。为了更快地区分遮挡区域和非遮挡区域,将遮挡图像和平均脸图片进行多次差值运算,得到误差脸图像。
本文采用水平集分割方法[11~14]从误差脸中得到遮挡区域的描述,水平集方法将n维曲面的演化问题转化为n+1维空间的水平集函数曲面演化的隐含方式来求解,水平集函数曲面的演化遵循式(1)所示的Hamilton-Jacobi方程
在鸡群内发现球虫病、白痢病等,并且鸡体表面存在虱、螨等寄生虫,容易导致鸡群感染。相关设备在使用期间给鸡带来外伤或者母鸡的病原性、生理性等,都将导致鸡啄癖的发生。
(1)
式中F为曲线上各点的演化速度,方向沿着曲线的法线方向,通常与图像梯度和曲线曲率有关。
假设C为一条封闭的活动轮廓,然后用水平集函数φ的零水平集φ(t=0)代替曲线C(t),曲线C内部的点组成了遮挡区域,在曲线外部的是非遮挡区域,从而将遮挡区域和非遮挡区域分割开。
自然环境下眼睛的遮挡物多为墨镜、帽檐等,嘴巴和鼻子多为口罩、围巾遮挡,针对不同的部位,对分割好的遮挡区域进行像素和形状的近似处理,获得类似于自然环境下的遮挡图像。处理后的图像和YaleB的3个子集作为训练样本的正样本。通过这种方法有效地避免了遮挡样本不足导致的召回率不高的问题。结果表明,相对于未经处理的遮挡图像训练的人脸检测器,使用处理后的遮挡图像作为样本训练的人脸检测器可以在自然环境下获得更高的人脸召回率,检测速度也达到了实时的效果。
2 AdaBoost算法
2.1 Haar特征和积分图
Harr特征也叫矩阵特征,人脸检测中常使用的四种Haar特征图4所示,每个特征的特征值的定义为图中白色矩阵像素值与黑色矩形像素值之差。

图4 基本的Haar特征
Haar特征可以经过各种平移、缩放、旋转的扩展,仅一个32×32的子窗口内会有几十万个Harr特征,计算量非常庞大,所以,为了提高计算效率,引入了积分图,可以快速计算Haar特征的特征值。
定义输入图像I,在像素点A(x,y)处的积分图为
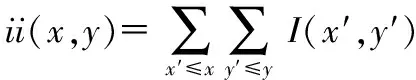
(2)
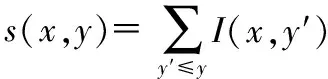
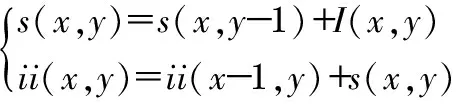
(3)
2.2 级联结构的AdaBoost人脸检测器
AdaBoost算法的思想是将大量的分类能力一般的弱分类器通过一定方法叠加,构成一个具有很强分类能力的强分类器。将AdaBoost算法最早应用到人脸检测上的是Jones M和Viola P[15],提出了一种基于级联结构的AdaBoost分类器。其检测过程如图5所示。

图5 级联检测器的检测过程
级联人脸检测器由多个强分类器组成,每一级的强分类器都采用AdaBoost算法进行训练。具体的训练方法如下:
1)给定n个样本图像(x1,y1),(x2,y2),…(xi,yi),…,(xn,yn),xi为输入样本图像,yi为类别标志,其中,yi=0,1分别表示其为非人脸样本和人脸样本。
2)初始化权重
式中m和l分别为非人脸样本和人脸样本的数量。
3)训练T轮,Fort=1,2,…,Tt
a.归一化权重
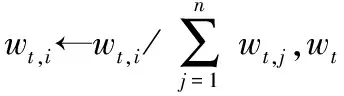
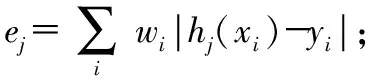
c.根据最低误差et选择最优弱分类器ht。
d.更新权重
4)将T个弱分类器组合成一个强分类器
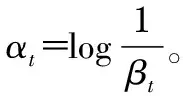
2.3 人脸检测
检测时保持待检测图像的大小不变,不断改变检测窗口的大小,使用不同大小的窗口遍历整个图像来完成检测,这种方法的运算量会比图像金字塔方法(固定窗口大小,缩放待检测图像)小很多。
检测时使用的是滑动窗口的方式,同一张人脸中可能会出现几个检测框,需要使用一定的方法保留唯一的最优检测框。目前常用的方法合并窗口的方法有非极大值抑制(nonmaximal suppression,NMS)和并查集方法。本文使用的是非极大值抑制的方法。
非极大值抑制对多个检测框进行合并主要通过两个指标:Score和IOU(intersection-over union,就是重叠面积),对于每一个待合并的检测框,分类器会给出一个Score 表示当前候选框的置信度,尽量保留置信度较高的候选框。IOU对于位置相邻的检测框,如果重叠面积大于一定的阈值则进行合并。
3 实验与结果分析
本文的实验环境为 Inter Core i5-6500CPU,操作系统为 Windows 7,使用Visual Studio 2015 进行C++语言编程实现。
本文使用检测速度、PR曲线(召回率为x轴,精确率为y轴的直角坐标系)和mAP(式(4))对算法进行评估,与未经过处理的遮挡图像作为训练集训练的AdaBoost检测器的检测的结果进行对比,根据多次实验的数据描绘出PR曲线,并根据式(4)计算出mAP值,结果如图6所示
(4)
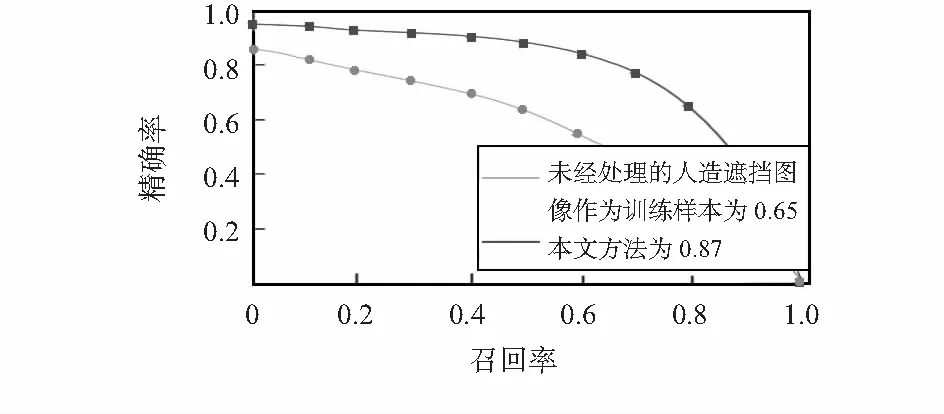
图6 不同训练样本的检测结果对比
由图6可以看出,本文方法的mAP值高达0.87,比直接使用人造遮挡图像作为训练样本训练的检测器检测的mAP值高出0.22,检测速度也达到了毫秒的级别,可以实现实时检测。
4 结 论
本文针对遮挡人脸的检测率不高和训练样本不足的问题,引入人造遮挡图像,并对遮挡图像进行一系列处理,得到近似于自然环境下的遮挡图片,从而解决了遮挡条件下训练样本不足的问题。然后训练并使用AdaBoost算法进行人脸检测。结果表明本方法能够有效地提高遮挡条件下的人脸召回率和精度,同时可达到实时检测。本文前半部分主要是如何检测出遮挡部位并进行处理,这种方法不仅仅适用于检测,对识别任务和图像修复任务等都具有重大的意义。本文的方法在光照强度大的情况下的检测效果还不太理想,这也是下一步继续努力的方向。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
科技创新与应用(2020年6期)2020-02-29 10:39:27
动漫星空(2018年9期)2018-10-26 01:17:14
电子测试(2018年1期)2018-04-18 11:52:35
北京理工大学学报(2016年6期)2016-11-22 11:17:22
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
电视技术(2016年9期)2016-10-17 09:13:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
发明与创新(2015年33期)2015-02-27 10:40:09
