
基于聚类分析的城市公交线路工况构建
2019-01-15 10:09李耀华李忠玉苟琦智任田园邵攀登
重庆交通大学学报(自然科学版) 2019年1期
李耀华,李忠玉,苟琦智,任田园,邵攀登,刘 鹏
(长安大学 汽车学院, 陕西 西安 710064)
汽车行驶工况是描述车辆行驶的速度时间曲线,为确定车辆污染物排放量和燃油消耗量、车辆动力系统参数匹配及新能源汽车整车控制策略的开发与标定提供了重要的参考依据[1-2]。城市客车是城市交通运输的重要载体之一,其交通特性受到城市道路布局、气候条件、人口密度、道路密度等众多因素的影响,地域性较强。目前,我国城市交通汽车行驶工况基本沿用欧洲工况标准,难以反映我国各地实际行驶状况[1,3,4]。
近年来,国内学者对城市客车行驶工况进行了一系列研究并取得了一些成果:王矗等[5]根据线路特点和覆盖区域选择公交线路,判断样本数量,采用聚类分析法构建了北京市城市客车工况,但没有一个统一的指标对采样量进行判断;刘明辉等[6]基于自行开发的设备和系统,分析北京市城市客车特征,构建了北京市城市客车工况,但没有说明选择线路的依据;石琴等[7]基于主成分分析和FCM聚类法构建了合肥市城市客车工况;姜平等[8]采用聚类和马尔科夫法构建合肥市城市客车工况,但是均未说明线路选择依据,也未对采样量进行判定。
笔者基于线路强度法给出了城市公交线路采样线路筛选方法,提出了用于判定工况数据采样量是否饱和的样本综合稳定度指标,并基于聚类分析法构建行驶工况;并以西安市某城市公交线路为例,最后基于误差分析和V-A概率二维分布矩阵相似度验证了文中构建的行驶工况的有效性。
1 汽车行驶数据采集
1.1 采样线路筛选
目前,西安城市公交运营线路达到近200条。如何在众多线路中筛选出具有西安公交工况代表性的公交线路,并用于构建西安市城市公交工况是笔者研究的问题之一。
笔者采用线路强度法对西安城市公交线路进行排序筛选:统计公交站点在西安所有公交线路中出现的频数,并由此计算每条公交线路上所有站点总频数平均值,定义其为线路强度。线路强度的大小与城市公交路线利用程度成正比,客观反映了城市公交线路重要程度和交通信息量大小。
通过对西安所有公交线路强度统计,得到西安公交站点强度最大的前10条线路,如表1。代表线路选取综合考虑该线路的线路强度、站点数、重要区域覆盖范围等因素。前4条线路站点数较少或覆盖区域有限;第1条站点数仅为11,不符合要求;第2、3条线路仅覆盖西安南二环附近区域;第4条线路仅覆盖西安北面部分区域。因此,笔者选取排名第5,线路站点总频数为587,线路强度为22.58的线路来构建西安某城市公交线路行驶工况,其运行线路如图1所示。由图1可明显看出其线路基本覆盖了西安二环内主要公交站点。

图1 某公交线路分布Fig. 1 Route map of a bus line

编号站点总频次线路强度编号站点总频次线路强度128626.00664622.28250425.20757322.04350624.11848321.95454523.70941321.74558722.581063021.72
1.2 采样量饱和判定
笔者采用GPS+CAN总线数据采集装置,采样频率定为1 Hz。通过对选定的城市公交线路正常营运车辆车速和行驶时间等数据进行为期16 d连续不间断采集(采样时间覆盖工作日和休息日和运营期间的各个时段),共得到63次由公交线路起点至终点的运行数据。
理论上,数据采样组数越大,构建得到的工况越能够准确反映实际工况。但是当数据量达到一定值后,继续加大数据采样量,工况准确性也不会得到大幅度提高,也就是数量采样量已达到饱和[5]。因此,科学合理地确定合适的采样量,既保证采样数据量能够满足构建工况要求,又不出现采样数据饱和,对工况构建就显得非常重要。
笔者选取平均车速V、平均运行车速Vm(不包括怠速时间的平均速度)[9]、加速Pa、减速Pd、匀速Pc和怠速Pd比例这6个具有统计意义的特征值作为指标来分析其变化趋势与采样次数的关系。图2(a)为平均车速和平均运行车速随采样次数的变化关系。图2(b)为加、减、匀、怠速比例随采样次数的变化关系。
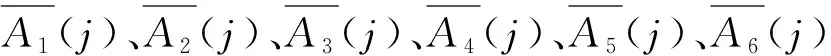
(1)
(2)
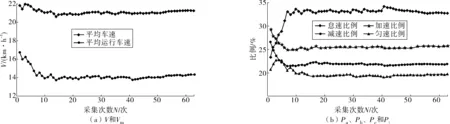
图2 参数随采样次数变化关系Fig. 2 The variation of parameters changing with sampling times
西安某城市公交线路63组采样数据的样本综合稳定度K计算结果如图3所示。由图3可知:综合稳定度随采样次数增加逐步收敛至0。定义当连续5次采样样本稳定度|K|<α,其中:α为显著性水平,取α=0.002 5,即可认为样本采样量已饱和,满足了采样量要求。当采样次数达到42次,之后连续5次的K<0.002 5。由此可知,当采样次数为46次,则满足样本采样量饱和的条件。此时,构建工况所需样本已达到饱和,可停止采样,从而为判定采样饱和提供了判断依据。
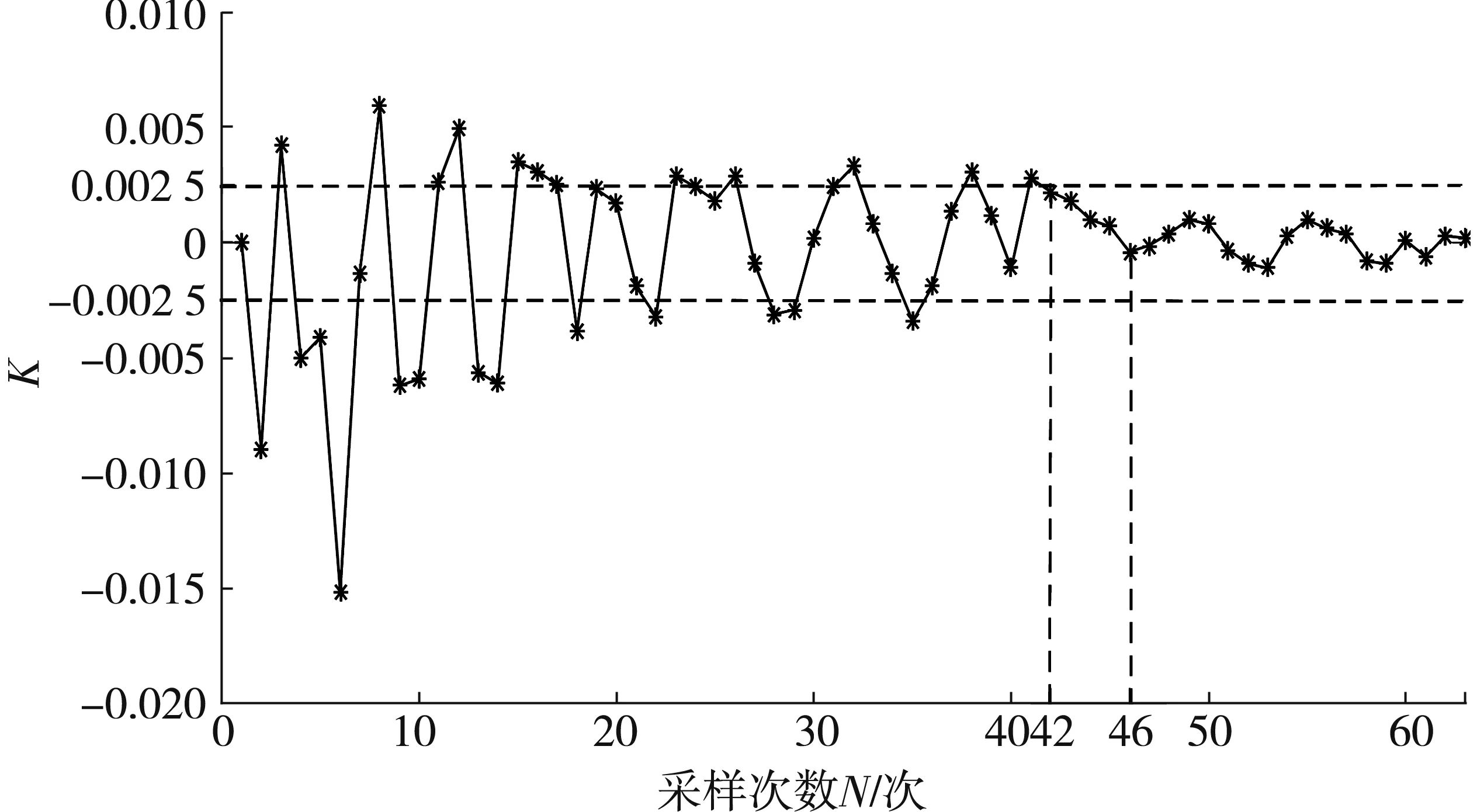
图3 综合稳定度K随采样组数变化关系Fig. 3 The variation of comprehensive stability index K changing with sampling times
2 行驶工况构建
笔者采用短行程+聚类分析法构建行驶工况,流程如图4。
考虑到城市客车启动、制动频繁,笔者将相邻两个怠速点之间持续时间不小于20 s的行驶过程划分为一个短行程。若两个怠速点之间持续时间小于20 s,将其计入到下一个短行程中去,从而保证数据的完整和连续。由上文可知,当采样46次,数据量已满足构建工况所需的要求。笔者对46组数据进行短行程划分,共得到1 998个短行程。

图4 短行程瞬态工况构建流程Fig. 4 Construction process of transient condition of short distance trip
定义26个表征站点运动区间特征的特征值作为评价站点运动区间的准则数。26个特征值分为两类,一类是描述性特征值共15个,主要用来进行主成分分析及聚类分析,包括行驶距离L(km)、运行总时间T(s)、加速时间Ta(s)、怠速时间Ti(s)、减速时间Td(s)、匀速时间Tc(s)、最大速度Vmax(km/h)、平均速度Vmean(km/h)、平均运行车速Vmr、速度标准偏差Vsd(km/h)、最大加速度Amax(m/s2)、平均加速度Amean(m/s2)、平均减速度Dmean(m/s2)、最大减速度Dmax(m/s2)、加速度标准偏差Asd(m/s2);另一类为统计性特征值,共11个,主要包括加速、减速、匀速、怠速比例及各速度段速度分布比例{P(0-10],P(10-20],…,P(60-70]}等[9]。1 998个短行程的各特征值和实验数据总体特征值分别如表2、3。
表2 各短行程特征值Table 2 Eigenvalues of each short distance trip

表3 实验数据总体特征值Table 3 General eigenvalues of experimental data
由表3可知:该线路城市客车平均车速较低,怠速比例较高,这也反映出西安市南北干线交通比较拥堵的特点。
由于特征值之间存在耦合,笔者采用主成份分析法进行降维,消除之间的关联。由于运行距离、运行总时间、加速时间、怠速时间、减速时间、匀速时间、最大速度、速度标准偏差、最大加速度、加速度标准偏差这9个特征值是累积特征值,不具备统计意义,故笔者选取除此以外的15个特征值作为试验数据总体特征值进行主成份分析。
由计算可得,前4个主成分累计贡献率已达到84.9%。故选取前4个主成分进行聚类分析,聚类结果如表4所示。由表4可知:第1类工况平均车速最低,为5.94 km/h,怠速比例最大,为0.694,代表拥堵工况;第2类工况平均车速为11.59 km/h,怠速比例为0.317,平均加速度、平均减速度比较大,代表一般工况;第3类工况平均车速、平均运行车速最高,分别达到17.14、22.39 km/h,怠速比例最低,为0.235,平均加减速度比较低,代表通畅路段工况。这3类片段数量分别为250、569和1 179个,比例约为1∶2∶5。因此,从这3类中依次选取偏差最小的1、2、5个短行程,组合成西安某线路城市客车行驶工况(文中称XADC-NO.X)。
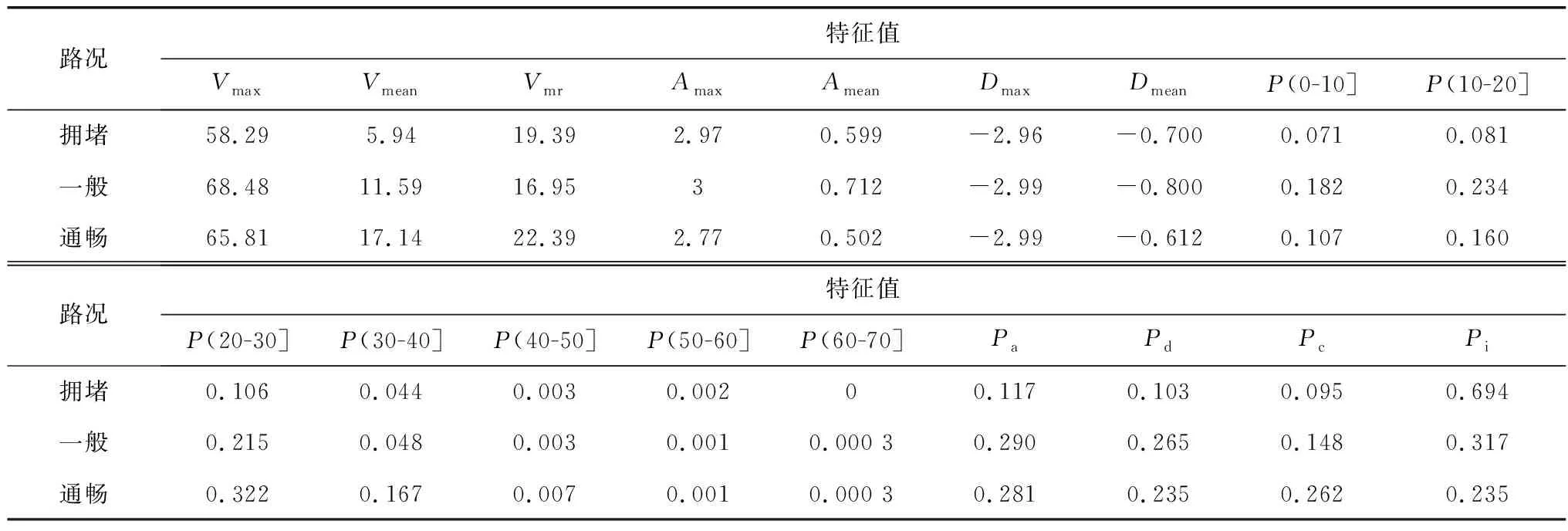
表4 各类短行程平均特征值比较Table 4 Comparison of average eigenvalues of short distance trip
为从各类中找出能代表各类特征的短行程,用式(3)来描述该短行程与所属类样本总体的偏差。
(3)

计算结果如表5。根据结果选取片段1 821、1 617、427、1 806、1 014、1 966、645、859共8个短行程,从而组成西安某线路城市客车行驶工况(XADC-NO.X),如图5。XADC-NO.X工况各特征值如表6。

表5 各类短行程与所属该类样本误差Table 5 The sample error between all kinds of short distance trips and their clustering
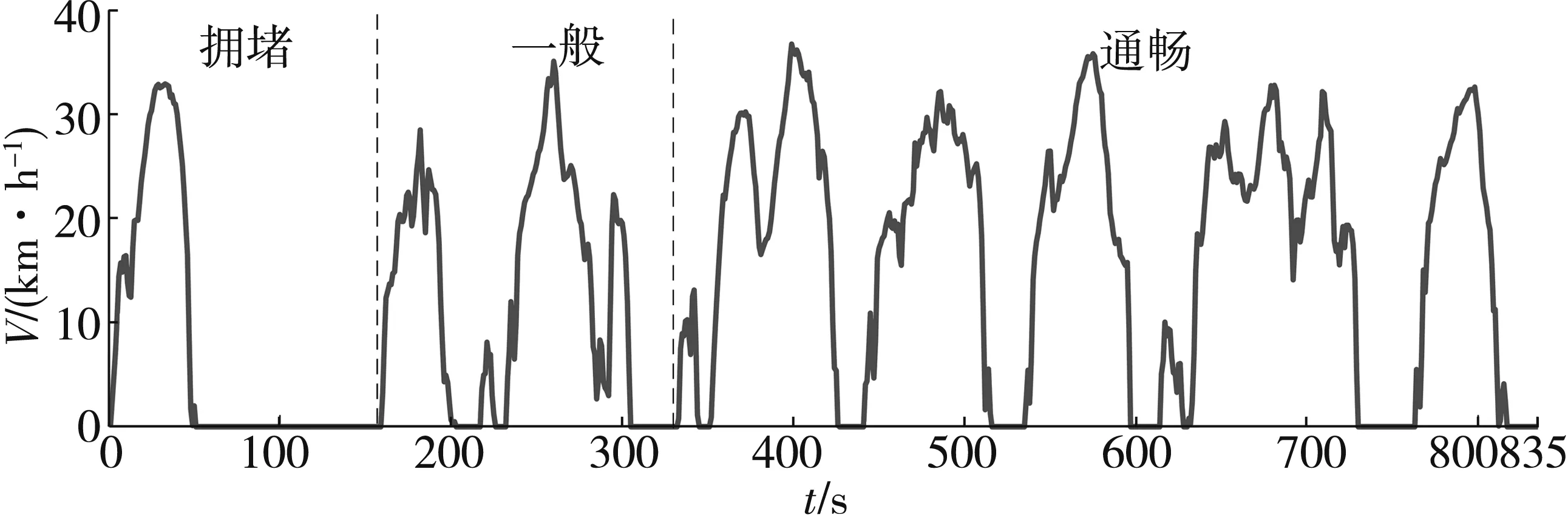
图5 西安某线路城市客车行驶工况(XADC-NO.X)Fig. 5 Xi’an city bus driving cycle of a line (XADC-NO.X)

T/sL/kmTaTdTcTi8353.21225191143276VmeanVmrVsdVmaxAmeanAmax13.8520.6812.3036.69.480.5482.265DmeanDmaxAsdP(0-10]P(10-20]P(20-30]-0.651-2.6490.5360.1160.1650.279P(30-40]P(40-50]P(50-60]P(60-70]PaPd0.1090000.2690.229PcPi0.1710.331
3 行驶工况有效性分析
为评价分析文中构建工况的有效性,笔者选取Vmean、Vmr、Vsd、Amean、Dmean、Asd、Pa、Pd、Pc、Pi共10个影响较大且具有统计意义的特征参数作为误差评估指标。各个误差指标和平均误差计算分别如式(4)~(5)。
(4)
(5)

由式(4)~(5)计算得出总体采样数据与构建工况之间的平均误差为7.3%。
为了进一步验证构建得出行驶工况有效性,笔者给出总数据与构建工况的速度-加速度联合分布概率矩阵(V-A矩阵),如表7、8。由表7、8可知:该线路速度和加速度主要分布区间为[0,35]km/h和[-0.9, 0.9]m/s2。计算可得总数据与构建工况在该区域的概率分别为0.878和0.886,两者误差为1.36%。

表7 样本数据总体V-A概率二维分布Table 7 V-A probability 2-D distribution of total experimental data
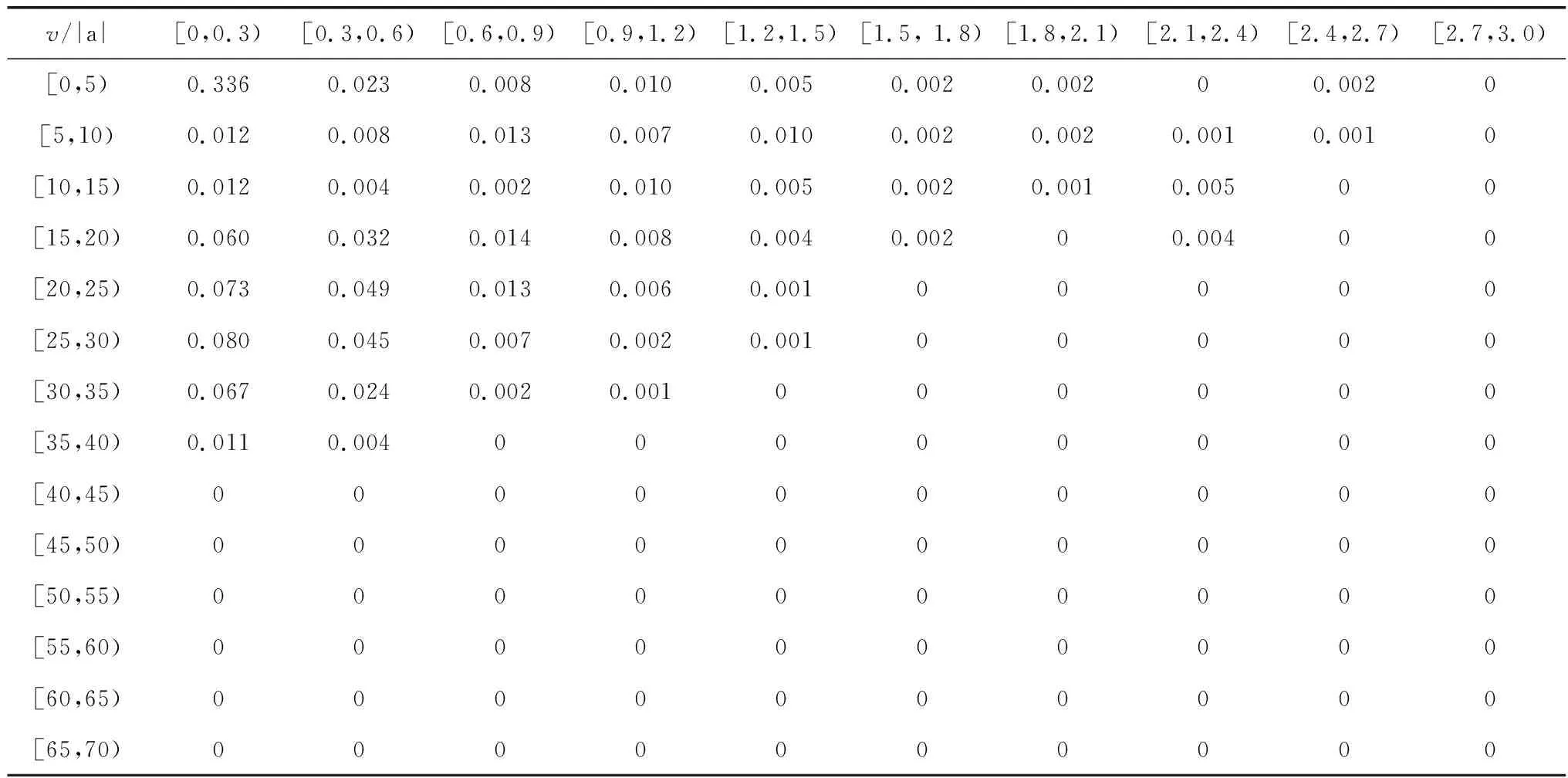
表8 构建工况数据V-A概率二维分布Table 8 V-A probability 2-D distribution of construction data
笔者利用空间矢量余弦定理求出这两个V-A分布概率矩阵的相似性[10]。将表7、8的两个10×14矩阵转换成两个140维矢量A和B,如表9。两矢量夹角的余弦值,即为V-A分布概率矩阵的相似系数Ω,其计算如式(6)。
(6)
式中:n为矢量长度;θ为两矢量之间夹角。
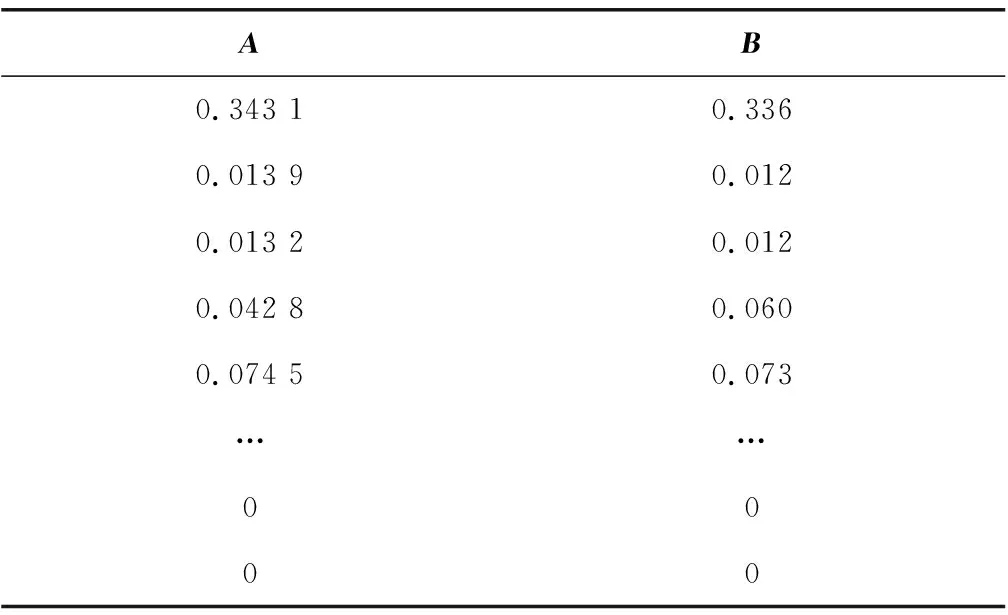
表9 矢量A和BTable 9 Vector A and B
通过计算,可得总数据与构建工况的V-A分布概率矩阵的相似系数为0.995 7。
经以上分析,说明通过数据收敛判断和聚类法构建工况所得结果与样本总数据误差较小,接近实际行驶工况,能反映出该线路实际工况特征,可用于运行于该线路工况车辆的参数匹配及控制策略开发。
4 结 语
笔者重点讨论了城市客车行驶工况数据采集线路筛选方法和采样量判定方法;并以西安某线路为例,详细介绍了基于聚类分析构建特定线路客车行驶工况方法。
笔者解析出西安某线路城市客车拥堵、正常及通畅这3类典型工况。并根据比例合成工况XADC-NO.X,其与试验总体数据平均误差为7.3%,且构建工况数据与样本总数据V-A矩阵相似系数为0.995 7,表明聚类法构建工况误差较小,符合实际行驶工况,可用于运行于该线路工况车辆参数匹配及控制策略开发。
猜你喜欢
数学物理学报(2021年6期)2021-12-21
数学物理学报(2021年5期)2021-11-19
数学物理学报(2021年3期)2021-07-19
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
汽车观察(2019年2期)2019-03-15
汽车观察(2018年12期)2018-12-26
汽车观察(2018年10期)2018-11-06
北京汽车(2017年3期)2017-10-14
环球人文地理·评论版(2016年11期)2017-03-24
环球人文地理·评论版(2016年12期)2017-03-24
