
减压馏分黏度指数的近红外预测研究
2019-01-10 09:16任小甜褚小立田松柏朱新宇
石油炼制与化工 2019年1期
任小甜,褚小立,田松柏,朱新宇
(中国石化石油化工科学研究院,北京 100083)
黏度指数是表征油品黏温性能的一种重要参数,也是润滑油基础油生产过程中重点监测的一项关键指标,减压馏分油(VGO)是目前润滑油基础油生产的最主要原料之一,建立VGO黏度指数的快速分析方法对指导润滑油基础油的原料选择、生产控制和过程优化具有重要意义。目前黏度指数是通过首先测定油品在40 ℃和100 ℃下的运动黏度,然后经过计算得到,但这种方法的实验步骤繁琐,操作费时费力。近红外光谱(NIR)是目前石油化工产品在线分析中应用最广泛的一项快速分析方法,NIR主要反映化合物中X—H(X为C,N,O)基团合频和倍频的振动,包含丰富的结构和组成信息[1],结合化学计量学方法,可以用于石油馏分的各项物性参数和组成信息的快速测定。油品的黏度指数与其结构和组成有密切的关系,所以使用NIR快速测定VGO的黏度指数是可行的。目前文献中报道的黏度指数近红外预测模型主要集中在润滑油基础油和成品润滑油,其定量校正方法为线性的偏最小二乘[2](PLS)以及非线性的自组织神经网络和反向传播(BP)神经网络[3-5]等。这些方法主要采用PLS和主成分分析(PCA)的方法对光谱变量进行降维处理来提取主因子,然后以主因子得分为输入特征进行线性和非线性的建模。由于VGO的组成比较复杂,有些与性质相关的结构基团在近红外光谱中没有响应或响应很低,不同基团的协同效应使VGO的很多性质和近红外光谱信息呈现非线性的关系,所以用非线性校正方法建立VGO黏度指数的预测模型可能是更合理的思路。本课题采用随机森林(RF)回归算法构建VGO黏度指数的预测模型,这种方法能全面地反映出VGO的黏度指数和其近红外光谱信息之间的非线性关系,准确度高,不易过拟合。首先结合特征重要性度量和递归特征消除法进行NIR光谱的波长变量选择,然后通过交叉验证法确定模型的超参数(回归树数量nt和节点分裂的特征数nv),最终建立起完整的预测模型。
1 实 验
1.1 样品及标准数据
收集70个VGO样品,这些样品切割自不同产地的原油,其黏度指数范围为17~151,平均值为86,样品覆盖范围较宽,具有很强的代表性。
用GB/T 265方法测定VGO样品在40 ℃和100 ℃下的运动黏度,然后按照GB/T 1995 方法计算相应的黏度指数。
1.2 光谱采集
采用Thermo Fisher 公司生产的傅里叶变换近红外光谱仪(ANTARIS Ⅱ型)进行VGO样品的光谱采集,样品池为0.5 mm比色皿,采集条件为恒温65 ℃,分辨率为8 cm-1,累积扫描次数为128,光谱范围为3 500~10 000 cm-1。
1.3 数据预处理及建模
对于样品的NIR光谱,采用S-G二阶微分(21点)进行处理以消除噪声和样品色度的影响,选取4 500~9 000 cm-1范围内的波长点作为模型的输入变量X,共计1 168个波长点;对于黏度指数的数据,由于其分布范围太宽,不同样本间的数值差异较大,将其进行对数转换作为模型的输出变量y,由此确定样品的数据集。
利用SPXY方法[6]将数据集划分为63个训练集和7个验证集,这种方法根据样品之间的欧式距离在特征空间中均匀地选取样本,计算距离时同时考虑光谱特征和性质特征,这样使样本划分得更加均衡,构建的预测模型更具代表性。
1.4 RF回归
RF回归算法是一种基于分类和回归树(CART)的集成学习算法,其在装袋(bagging)的思想上进行了改进,主要利用2个随机过程来增加模型的泛化性,首先通过有放回的随机抽样得到不同的样本子集,分别对这些样本子集构建不同的回归树,在树的每个节点分裂时,然后每次都随机抽取一定数量的特征进行分裂,这2个随机过程可以有效地降低模型的方差,避免过拟合,增加模型的泛化性。RF模型中构建的弱学习器是大量的回归树,其算法的基本思想是不断地将训练集中的样本进行二分类,从根节点开始,以分裂后左右分叉中样本的平方误差最小化作为分裂规则,选择最优的分裂特征及对应的最佳分裂点进行分支,依次分裂,最大限度地生长,最后将样本分配到不同的叶节点中,每个叶节点中包含的所有样本的平均值为该节点的计算值。预测时,将待测样本依次代入每颗回归树进行计算,利用所有树的计算结果平均值进行预测。这种模型训练时间短,不需要进行特征数据的预处理,且模型可以给出每个特征的重要度用于特征选择,对离群的异常样本不敏感,稳健性好,有较强的泛化能力和较高的准确度。
RF算法采用有放回的自助抽样来生成样本子集,构建一颗回归树时,训练集中每个样本未被抽中的概率为(1-1/N)N,N为样本数,当N足够大时,此概率收敛于1/e≈0.368,即每颗回归树中大约有36.8%的样本参与建模训练,这些样本被称为袋外样本(OOB),其可作为验证集对RF回归模型的泛化性能进行评价。对于训练集中的每个样本,将其作为OOB样本,利用不包含该样本的回归树进行对应的性质预测就叫做袋外估计,保证RF中的回归树足够多,每个训练样本都能得到一个袋外估计的计算值,这样利用袋外估计就可以起到验证集的作用,属于无偏估计[7]。
2 结果与讨论
2.1 波长变量选择
近红外光谱中有上千个波长变量,其中包含有不少冗余的信息,比如与待测性质相关性很小的波长点,在建模之前进行波长选择可以简化模型,同时针对待测性质选择最有效的光谱区间和波长点可以使预测模型更加准确,稳健性更好[8]。在近红外预测模型中,最常用的是相关系数法,即选择与待测性质相关系数较高的波长区间进行建模,但相关系数只能表示变量之间的线性相关关系,显然不适用于预测非线性的黏度指数模型。
根据RF回归算法中对特征重要性的度量,通过递归特征消除法进行波长变量的选择。RF中,回归树的每个节点都表示不同的特征分裂条件,是以分裂后的方差最小化为准则,目的是为了将训练集的样本不断划分,将性质取值接近的样本分到同一节点中,总的来说就是通过划分降低整个训练集样本的方差。所以,计算出回归树中某个特征对于方差的降低量,再对RF中的所有树取平均值,将该特征的平均方差减少量作为其重要度。
本研究使用递归特征消除法进行近红外光谱的波长变量选择,基本步骤如下:①从训练集样本出发,构建一个RF模型(nt=60),计算出各波长变量的重要度,并将其按照降序排列,利用袋外估计的方法计算训练集样本的校正标准偏差(RMSEC);②从当前波长点中删除重要度最小,即排序在最后的2个点,得到一个新的特征子集;③利用新的特征子集重新构建RF模型,计算其中每个波长变量的重要度并排序,利用袋外估计的方法计算训练集样本的RMSEC;④重复②和③的步骤,直至剩下2个波长点;⑤记录上述所有特征子集计算得到的RMSEC,选择取值最小的子集作为最后优选的波长变量子集。
不同波长点数的变量子集下训练集样本的RMSEC见图1。从VGO的近红外光谱中取10个特定波长点(4 900,5 140,5 690,5 760,5 880,6 800,7 460,8 330,8 340,8 590 cm-1)的子集时就可以得到最小的RMSEC,此时构建的预测模型泛化性能最强,稳健性最好。

图1 不同波长点数的变量子集下训练集样本的RMSEC
2.2 模型调参
以上述优选出的波长变量作为新的输入特征,用训练集样本构建RF回归模型,模型中有2个重要的超参数,即回归树数量nt和每个节点分裂时使用的特征数nv。回归树的数量越多,模型的方差越小,但会增加计算负担;减少nv,构建的回归树之间的相关性会减少,可以增强模型的泛化性,但会造成预测准确度下降。所以,要对这2个超参数进行优选,以降低模型的方差,进一步增强模型的泛化性能。本研究使用10折交叉验证的方法对这2个超参数依次进行寻优,计算不同取值超参数下的交叉验证均方误差(MSECV),取值最小时对应的超参数即为最优值。回归树的数量与MSECV的关系见图2。分裂波长点数与MSECV 的关系见图3。首先确定nt的最佳值,如图2所示,当nt为150时,MSECV取值达到最小;固定nt为150,对分裂时使用的波长点数nv进行寻优,由图3可知,当nv为5时,MSECV达到最小值。

图2 回归树数量与MSECV的关系
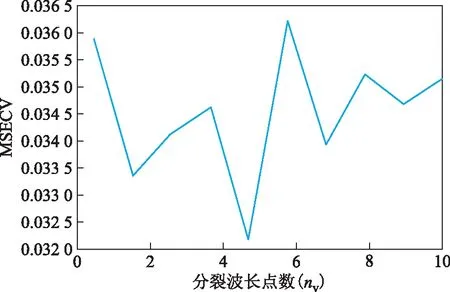
图3 分裂波长点数与MSECV 的关系
2.3 构建RF回归模型
以10个波长变量为输入特征,在63个训练集样本上构建包含有150颗回归树的RF,其中回归树上的节点分裂时随机抽取5个波长变量进行分裂,这样构建起一个稳健预测VGO黏度指数的RF回归模型。对于训练集样本,模型的RMSEC为4.03,决定系数R2为0.98,黏度指数的实验值和预测值对比见图4。从图4可以看出,黏度指数的实验值和预测值的相关性很好,同时由袋外估计方法计算的R2为0.88,表明模型的泛化能力较好。上述结果表明,RF回归模型能较好地拟合所有的训练集样本,筛选出10个特征波长也能代表VGO中与黏度指数最相关的结构信息,模型的准确度高,稳健性好。

图4 训练集样本的黏度指数实测值和预测值对比
基于上述黏度指数的RF回归模型,对验证集中的7个VGO样本进行预测,其预测标准偏差RMSEP为2.28,决定系数R2为0.98,将这7个样本黏度指数的实测值和预测值进行对比,结果见表1。从表1可以看出,通过RF回归模型预测的黏度指数与实测值基本一致,最大偏差为4,说明此模型具有很强的泛化能力,不易过拟合,能较准确地预测训练集以外的样本。总的来说,RF回归模型能全面地反映出VGO的近红外光谱信息和其黏度指数之间的非线性关系,模型的准确度较高,泛化性好,覆盖范围广,具有一定的应用价值。在后续的模型维护工作中,需要增加VGO的训练样本,进一步提高模型的准确度和预测范围。
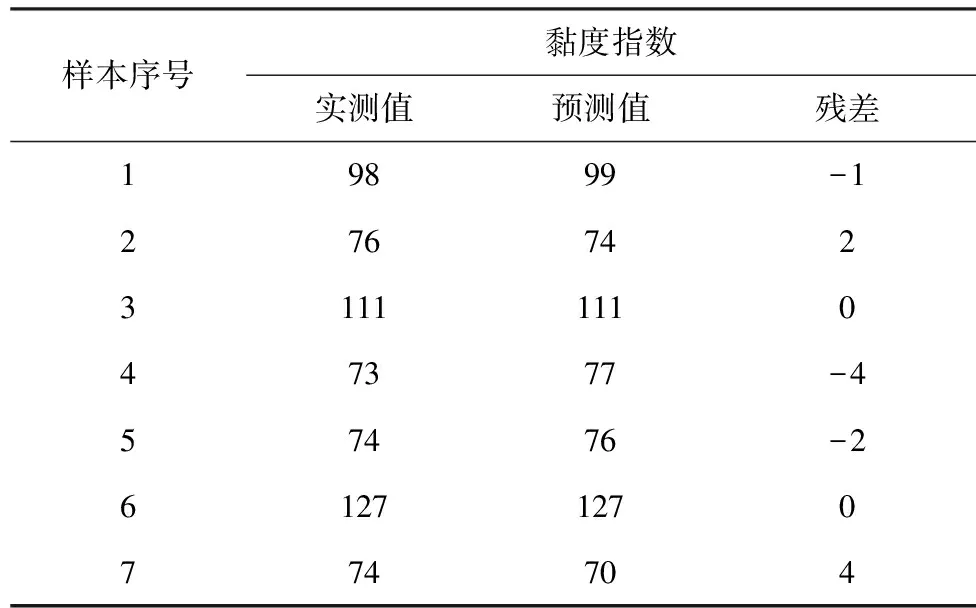
表1 验证集样本的黏度指数实测值与预测值比较
3 结 论
(1)利用RF回归算法,建立了VGO黏度指数的近红外预测模型,包括利用递归特征消除法从近红外光谱中提取10个特征波长,通过10折交叉验证法确定模型的两个超参数,最终确定了一个准确度高、稳健性好的非线性预测模型。
(2)利用此模型,可以通过近红外光谱快速地计算出VGO的黏度指数,其准确性与标准方法相当,泛化性好,能基本满足生产过程中快速分析的需求,具有一定的实用价值。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
阅读(科学探秘)(2021年8期)2021-09-01
空间科学学报(2021年1期)2021-05-22
上海公路(2019年3期)2019-11-25
中国塑料(2017年2期)2017-05-17
中南大学学报(自然科学版)(2016年2期)2017-01-19
中国照明(2016年4期)2016-05-17
肇庆学院学报(2016年5期)2016-03-11
中国光学(2015年5期)2015-12-09
中国当代医药(2015年26期)2015-03-01
