
融合CHI与信息增益的情感文本特征选择
2019-01-09 10:18黄梦莹张晓滨
西安工程大学学报 2018年6期
黄梦莹,张晓滨
(西安工程大学 计算机科学学院,陕西 西安 710048)
0 引 言
互联网的发展,使人们可以从多个途径获得自己需要的信息,互联网用户可以通过网络发表自己对某人某事某物的看法,记录自己在某个时间的心理状态,而这些用户上传的情感文本数据使越来越多的情感评价体系应运而生.因而如何高效地获取情感文本中表达的对人、事、物的情感信息,分析用户的情感倾向,从而获取有用的信息已是大势所趋.文本情感分析是对带有感情色彩的主观文本进行分析处理[1].分析用户的情感倾向首先需要对用户的文本数据进行分析,找到其文本的情感特征词.
卡方统计量和信息增益的特征选取方法是特征选择算法中效果较好的2种特征选取方法,其主要是对传统文本进行特征选择的方法,但由于两者都存在各自的不足,从而导致文本的分类效率不高,因此出现了很多对这2种方法进行改进的算法.刘海峰等[2]基于特征项的不同分布角度,实现对CHI模型的逐步优化以及裴英博等[3]通过对传统CHI方法特征选择精度的影响因素进行分析,提出了消除特征项与类别负相关对特征选择精度影响的改进算法.以上两者是在卡方统计量的方法上进行改进,都是基于传统的文本实验分类,并不适用于情感文本.另外有基于特征项在文本中的位置信息和词频信息,对CHI算法做出改进[4]的方法,以及基于微博文本的特征信息,提出了适合微博特征提取的改进的CHI特征提取算法[5]和黄章树等[6]通过降低负相关低频词在特征选择算法中的权重,减小其对模型的影响.这三者虽然在一定程度上减小了卡方统计量的方法对文本分类的影响,但是对文本的信息处理上会花费更多的时间.
在信息增益的方法上,郭亚维等[7]将传统的信息增益算法引入平衡因子中从而得到一种新的算法,虽然提高了分类效果,但平衡因子的取值不确定;李学明等[8]考虑到特征词在类内、类间的分布对其权重的影响,提出一种基于信息增益与信息熵的TFIDF算法.文献[9]提出了一种基于卡方特征选择改进的文本分类方法,以上两者在一定程度上提高了分类性能,但局限性较大.上述是基于这2种方法中的某一种方法进行的改进算法,最终都能实现对文本分类效率的提高.而考虑到这2种方法又是特征选择算法中最有效的2种方法,GHAREB等[10]通过对几种特征选择算法与增强的遗传算法相结合,在遗传算法的基础上提出了一种混合特征选择方法,该方法虽然能提高分类效率,但是花费的时间相对较高.文献[11]通过对文本挖掘中常用的几种特征选择算法的分析与比较,在文本意义的基础上提出的一种新的文本数据特征选择方法.LIU等[12]提出一种新的结合LW索引与序列正向搜索算法的特征选择方法,在收集大量的文本数据基础上能有效地提高文本的特征选择.文献[13]基于自适应遗传算法的特征选择方法,采用不同的术语加权方法和分类算法对自然语言呼叫路由的文本分类进行了研究; HE等[14]通过添加权重系数来平衡特征项对分类的影响.文献[15]虽然实现了这2种方法的集合,对这2种方法进行了改进,但该方法是基于普通文本特征的选择,对于情感文本并不适用.
上述方法都是基于传统文本的分类,相对于传统文本,情感文本是更加细化的传统文本,情感文本包含的情感词、态度、观点词更多.因此,在研究情感文本的分类过程中,并不仅仅是将文本分类,而且同时还要分析情感文本的正向或负向的情感.在当代互联网的情景下,获取文本情感的倾向能够更好地分析用户的情感,从而实现对用户的分析与推荐,有更好的用户体验.本文在分析2种传统的特征选择算法的基础上结合研究现状对2种方法进行融合,实现对情感文本的特征选取.通过对均衡与非均衡的情感文本语料进行分类实验,实验证明该方法能有效地提高情感文本的分类效率.
1 传统特征选择算法
1.1 CHI特征选择算法
CHI统计方法是通过比较实际值与理论值判断理论假设的正确与否,在计算CHI值时假设2个变量相互独立.假设特征变量t与类别c相互独立,则t对于类别c的CHI统计量表示为
(1)
式中:A表示属于类别c且包含特征词t的文档数;B表示不属于类别c但包含特征词t的文档数;C表示属于类别c但不包含特征词t的文档数;D表示既不属于类别c也不包含特征词t的文档数;N表示文档总数.式(1)计算特征词t与类别c之间的相关性,当t与c相互独立时,χ2(t,c)=0;当t与c相关性越强,χ2(t,c) 值越大,即特征词t中包含的能鉴定类别c的信息越多.
1.2 信息增益方法
在信息增益中,衡量重要性的标准为选出的特征词能否将该文本与其他的文本进行区别,该特征词带来的信息越多,则该特征越重要,即计算有特征t与无特征t之间信息熵的差值.对分类器来说,类别C为变量,取值范围为C1,C2,…,Cn,而该类别出现时分别对应的概率为P(C1),P(C2),…,P(Cn),n表示类别的总数.此时的分类器的熵表示为
(2)
对于无特征t的情况,指的是分类器中虽然包含特征t,但是t已经固定不变.此时信息的熵就是计算特征t固定时的信息熵,即条件熵.则无特征t时的信息熵计算公式可以表示为
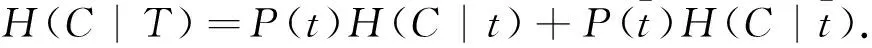
(3)
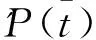
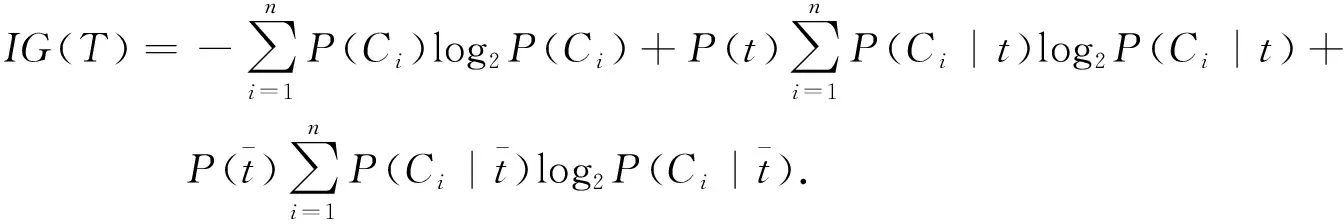
(4)
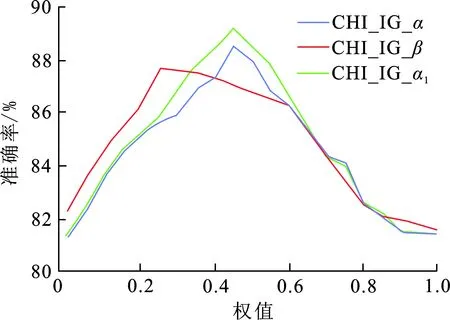
图 1 权值α,β与Random Forest分类器准确率的关系Fig.1 Relationship between α,β and accuracy of random forest classifier
2 基于传统特征算法的改进
CHI统计量的计算过程忽略了特征词t的频数,即用该方法计算的CHI统计值导致在某类文章的每篇文档都出现一次的特征值大于该类文章中99%的文档中出现10次的特征值大.基于信息增益的整个算法过程可以看到它只能考察特征对整个分类器的贡献,而不能具体到某个类别上,如果有的特征词对某个类别有区分度,但是对其他类别没有什么区分度给分类带来的信息则较少.为了降低这2种方法不足带来的影响,本文提出了一种改进的特征选择方法,即融合信息增益与CHI的特征选择算法.可以在2种方法中取一个权值α,综合2种算法的弊端,
CHI-IG(T,C)=αIG(T)+(1-α)χ2(t,c).
(5)
同时为了区分情感特征词与普通的特征词,在选取的特征词中,对情感特征词的CHI-IG(T,C) 值乘上β值.即
CHI-IG(T,C)=(βy+1)×[αIG(T)+(1-α)χ2(t,c)].
(6)
式中:y取0和1,当特征词为情感特征词时,y取1,反之取0.
在均衡语料的实验特征维度为1 600时.采用随机森林分类算法计算的α,β值与CHI-IG特征提取算法情感文本分类准确率之间的关系如图1所示.从图1可以看出,CHI-IG-α表示初始值α,CHI-IG-β表示在初始值α最优的情况下计算的β值,CHI-IG-α1表示在β的值固定且为最优值的情况下调整后的α值.由图可知曲线CHI-IG-α随着权值α逐渐增大,CHI统计量的不足带来的影响逐渐减小,当α达到0.48时,准确率达到最高;当权值α超过0.48之后,信息增益方法(IG)不足带来的影响逐渐增大,准确率逐渐降低.因此可知公式(5)中的α取0.48时分类器的准确率最高.CHI-IG-β和CHI-IG-α1是在CHI-IG-α的基础上对权值进行调整,以达到最优的权值.CHI-IG-β是在同样的实验数据条件下,且α的值固定为最优值的情况下计算的β值与CHI-IG特征提取算法情感文本分类准确率之间的关系曲线,β值取0.25时分类器的准确率最高.考虑到式(5)中的α值的计算未涉及到β值,所以需要在β值最优的情况下再次测试α值.CHI-IG-α1是在相同的实验数据条件下,且β的值固定为最优值的情况下计算的α值与CHI-IG特征提取算法情感文本分类准确率之间的关系曲线,α值取0.45时分类器的准确率最高.因此,最终确定的特征选择算法的计算公式为
CHI-IG(T,C)=(0.25y+1)×[0.45IG(T)+0.55χ2(t,c)]
(7)

3 结果与讨论
对数据进行的预处理包括去掉分词、停用词、繁简转化、替换奇异词等.其中分词使用中国科学院的汉语分词系统NLPIR[16].去除分词后的停用词和链接等无用信息.进行特征选择时,采用传统的卡方统计量、信息增益算法以及本文改进的融合算法.实验平台采用WEKA3.7数据挖掘开源工具,对文本分类进行验证.分别采用随机森林算法和支持向量机分类算法进行分类实验.
分别采用卡方统计量方法、信息增益方法以及本文提出的CHI-IG方法进行不同维度的特征提取,用SVM进行分类,结果如图2,3所示.
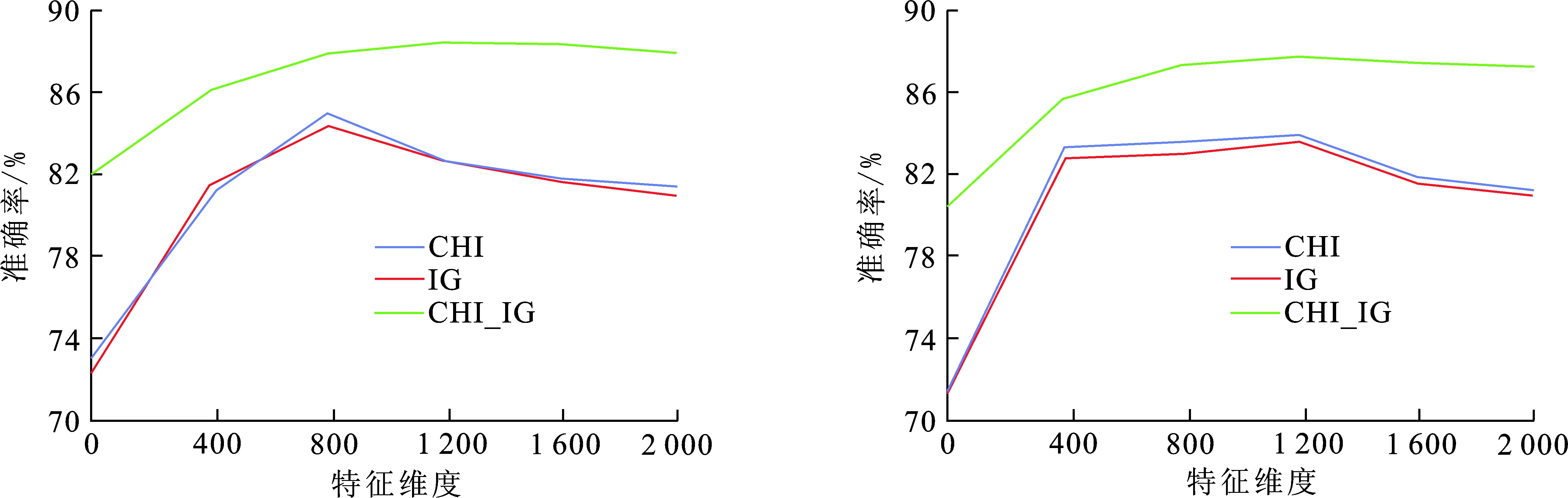
(a) 均衡语料 (b) 非均衡语料图 2 不同维度下SVM分类器的准确率Fig.2 Accuracy of SVM classifier in different dimensions
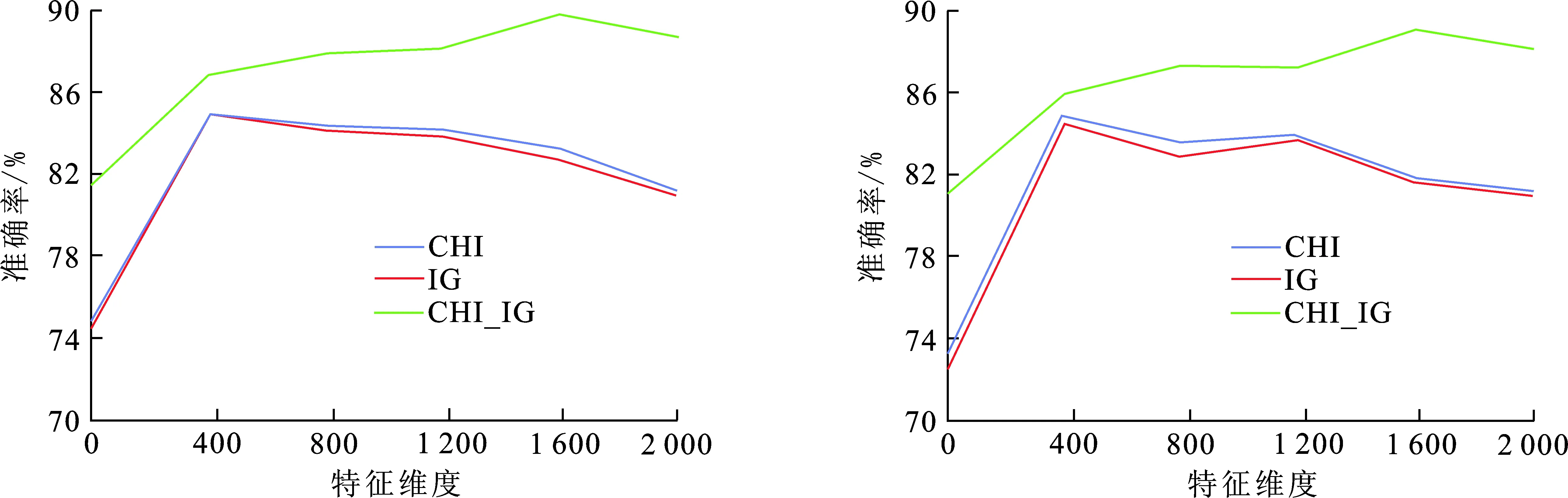
(a) 均衡语料 (b) 非均衡语料图 3 不同维度下Random Forest分类器的准确率Fig.3 Accuracy of Random Forest classifier in different dimensions
从图2可以看出,随着特征维度的增加,改进的CHI-IG特征提取算法相比于传统的卡方统计量以及信息增益算法在提取不同维度的特征时,改进的算法SVM分类的准确率都有所提高,在选取1 200维度的特征时准确率达到最高,分别是88.37%和87.85%.说明在采用改进的CHI-IG情况下情感文本分类的准确率得到了提高.
从图3可以看出,随着特征维度的增加,3种方法的分类准确率都有所增加,而改进的CHI-IG特征提取算法相比于另外2种算法,其分类准确率提高较大,在选取1 600维度的特征时准确率达到最高分别为89.86%和89.13%.说明在采用改进的CHI-IG情况下情感文本分类的准确率得到了较大提高.
4 结束语
本文基于对传统的信息增益与卡方统计量特征选择算法的分析,提出改进的特征选择算法并应用在情感文本的分类上,通过对比实验证明该算法在情感文本的分类上得到了较大提高.在后续的研究中可以将该方法应用在不同的研究领域.
猜你喜欢
计算机系统应用(2021年9期)2021-10-11
北京航空航天大学学报(2021年6期)2021-07-20
电子制作(2019年19期)2019-11-23
电子制作(2018年19期)2018-11-14
计算机技术与发展(2018年8期)2018-08-21
中国机械工程(2017年22期)2017-12-02
自动化学报(2017年5期)2017-05-14
电子制作(2017年23期)2017-02-02
电子制作(2016年1期)2016-11-07
智能系统学报(2015年4期)2015-12-27
