
基于卷积神经网络与高光谱的鸡肉品质分类检测
2019-01-07 12:08:24王九清邢素霞王孝义
肉类研究 2018年12期
王九清,邢素霞*,王孝义,曹 宇
(北京工商大学计算机与信息工程学院,食品安全大数据技术北京市重点实验室,北京 100048)
随着鸡肉在人类日常饮食中的比重日益增加,人们对鸡肉品质的重视也在不断增长,这极大地推动了肉制品品质及安全检测技术的发展[1]。传统的检测方法,如感官分析、理化检测等,都十分繁琐,且难以实现对鸡肉的快速、无损检测[2-3]。基于光谱分析的高光谱图像检测技术[4]将传统的成像技术和光谱技术结合起来,光谱数据能够反映样本的内部品质,图像数据能够反映样本的外部特征[5-6],将二者结合起来可以实现对鸡肉的无损检测,并且在食品质量评估领域中也得到大量的应用[7-8]。然而,高光谱数据维度高、数据量大,具有非线性和复杂性,如果人为地对高光谱数据进行特征提取和数据重建,过程十分复杂,耗时较长,并且难免会造成有效信息的浪费[9-10]。
卷积神经网络(convolutional neural network,CNN)是将人工神经网络和深度学习技术结合产生的一种新型人工神经网络方法[11-12],可以直接将原始数据作为网络的输入,由特征检测层通过训练数据进行学习[13-15],避免了前期复杂的人工特征抽取,极大地简化人为参与的操作过程,在图像识别领域获得了广泛的应用[16-17]。
本研究以鸡肉为研究对象,使用CNN结合高光谱成像技术对鸡肉进行品质分类检测。从鸡肉高光谱数据中提取光谱、彩色图像等信息作为并行输入,建立基于光谱及图像的综合CNN模型,实现对鸡肉的品质检测,并探究高光谱数据中的光谱和图像数据在鸡肉品质分类检测中的作用。
1 材料与方法
1.1 材料与试剂
超市盒装冰鲜鸡肉,500 g/盒,每盒作为1 组(3 个样品),共90 组、270 个样品。将每个样本分为2 份,同时贮存在冷藏室中,以待进行理化检测和高光谱信息采集。
1.2 仪器与设备
M Sorter肉制品光谱检测仪 北京卓立汉光有限公司;Matlab软件(R2014b) 美国MathWorks公司;PyCharm软件(2017.3 x64) 捷克JetBrains公司;Tensorf l ow框架 美国谷歌公司。
1.3 方法
1.3.1 鸡肉理化指标测定
鸡肉理化指标委托华测科技有限公司进行测定。参照GB 5009.228—2016《食品安全国家标准 食品中挥发性盐基氮的测定》[18]中的半微量定氮法测定挥发性盐基氮(total volatile basic nitrogen,TVB-N)含量;参照GB 4789.2—2016《食品安全国家标准 食品微生物学检验菌落总数测定》[19]测定菌落总数。90 组样本的TVB-N含量及菌落总数如表1所示。

表 1 鸡肉样品的TVB-N含量及菌落总数Table 1 TVB-N content and total bacterial count of chicken samples
1.3.2 高光谱数据采集
采样时间为贮藏第1、6、7、10、13、16、20、23、27、31天的每天下午2点,共计10 个采样时间点。每个时间点取出9 组高光谱样品和9 组理化样品,同时进行高光谱数据采集和理化指标测定。其中,高光谱样品贮藏在冷藏箱中,由华测公司在实验前1 h将样品送到实验室。
高光谱数据采集过程:在实验室内,使用M Sorter肉制品光谱检测仪采集鸡肉的高光谱数据,波长范围390~1 020 nm,曝光时间3.75 ms。
刚采集到的高光谱数据可能会受到光照不均或镜头暗电流的影响,带有大量噪声,需要对其进行黑白校正[20]。校正后的鸡肉高光谱数据按照公式(1)计算。

式中:R为校正后的鸡肉高光谱数据[21];I为原始鸡肉高光谱数据;W为镜头对准白板时的全白标定图像;B为镜头盖住时的全黑标定图像。
1.3.3 高光谱数据提取
高光谱数据有极高的分辨率,其庞大的数据中存在大量冗余的多重共线性信息,其中既包含灰度值、纹理、TVB-N含量及菌落总数等有用信息,也包含无用的噪声信息[22-23]。使用CNN省略了人为数据降维和特征抽取过程,只需对高光谱数据中的光谱数据及彩色图像数据进行提取和预处理,主要步骤如下:1)提取感兴趣区域[24],并进行非均匀性校正。在鸡肉的原始高光谱图像上随机提取尺寸为66×66的区域作为感兴趣区域,采用光谱标准化的非均匀性校正方法进行处理;2)提取校正后感兴趣区域的平均光谱及彩色图像。采集到的高光谱数据,其光谱范围为390~1 020 nm,大约每2.47 nm为1 个波段,共分为256 个波段,平均光谱是对感兴趣区域的每个波段上的光谱值取平均,即平均光谱是长度为256的一维向量;分别取第107、70、36个波段的灰度图像作为R、G、B分量,合成彩色图像;3)对光谱进行去噪预处理,保存处理前后的数据;4)对彩色图像进行滤波等预处理,保存处理前后的数据。
1.3.4 高光谱数据预处理
光谱数据预处理方法主要有标准化、微分预处理及多元散射校正等[25-27]。标准化能够消除由微小光程或样品薄厚不均匀引起的光谱变化;微分预处理可以分辨重叠峰,辨识较小但是较为明显的特征峰,消除背景层的干扰并提高图像分辨率,由于该过程中会引入一定的噪声,故不使用该方法;多元散射校正可以有效消除鸡肉样品颗粒不一致、分布不均匀所导致的散射问题,修正高光谱扫描样本的光程误差。因此,本研究使用标准化和多元散射校正对高光谱数据进行预处理。
高光谱图像的采集过程中难免会带有一定的噪声干扰,影响图像的质量,进而影响模型的分类效果,因此要对采集到的图像进行滤波,本研究采取均值滤波的方法对鸡肉的彩色图像进行预处理。
CNN的主要结构如图1所示,其主要由输入层、若干个卷积层和池化层、全连接层以及输出层构成[28-29]。

图1 CNN结构Fig. 1 Structure of CNN
利用从高光谱数据中提取并经过预处理的光谱及图像数据建立光谱-图像联合的综合CNN模型,模型结构如图2所示。一维光谱数据输入到一维卷积部分,提取光谱特征;二维彩色图像输入到二维卷积部分,提取图像特征。通过特征融合层,将光谱特征和图像特征联合起来,连接到全连接层,最后通过输出层得出分类结果。
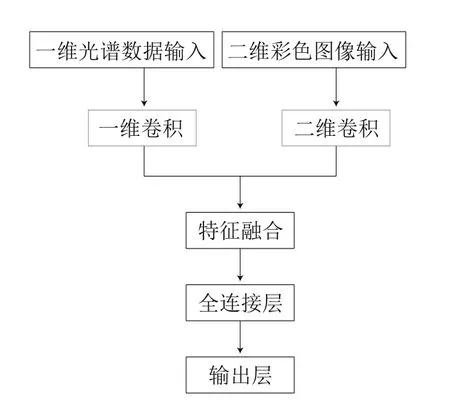
图2 综合CNN模型结构Fig. 2 Structure of integrated CNN model
1.3.5.1 一维卷积部分

图3 一维卷积部分结构Fig. 3 Structure of one-dimensional convolution
经过预处理的光谱数据长度为256,深度为1,将其作为一维卷积部分的输入,其结构如图3所示。其中,设计为三层卷积是为了与二维卷积层数一致,便于对比。3 个卷积层的卷积核尺寸要与输入数据相匹配,将卷积步长设置为1,设计多种核尺寸组合,如(9,9,9)、(9,5,9)、(9,5,7)等,将分类效果最好的尺寸组合(9,9,9)作为一维卷积部分的核尺寸,各层卷积核的数量根据经验设置;池化层选择最大池化,核尺寸均为2,步长为2,即将特征图的尺寸压缩为原来的1/2;最后,一维卷积部分输出结果为120 个长度为25的特征向量。
1.3.5.2 二维卷积部分
经过预处理后的彩色图像尺寸为66×66,深度为3,将其作为二维卷积部分的输入,其结构如图4所示。其中,根据输入的尺寸将卷积层数设置为3最佳,设置步长为1,3 个卷积层的核尺寸也设计了多种:(3×3,5×5,5×5)、(3×3,5×5,7×7)等,效果最佳的是(3×3,5×5,5×5),各层核数量根据经验设置;池化层选择最大池化,核尺寸均为2×2,步长均为2,相当于将特征图压缩为原来的1/4;最后,二维卷积部分的输出结果为270 张尺寸为5×5的特征图。

图4 二维卷积部分结构Fig. 4 Structure of two-dimensional convolution
1.3.5.3 特征融合层
从卷积部分得到的图像特征,其特征值的数量6 750(5×5×270)远大于光谱特征值的数量3 000(25×120),因此在本层首先要对图像特征进行压缩。数据压缩层就是一个包含3 000 个神经元的全连接层,将6 750 个图像特征值作为输入,输出个数为3 000,即为特征值数量压缩;然后,将3 000 个光谱特征加上3 000 个图像特征,组成长度为6 000的高光谱特征,接入到全连接层。
1.3.5.4 全连接层
其次,在实际进行教学内容分层的过程当中,必须要综合考虑学生的实际接受能力,并在此基础上保证教学内容的针对性,是每一名学生能够有效地了解到所讲解的具体内容。
全连接层共有2 层,神经元的个数分别设定为2 000和800,即将特征值数量进一步压缩。为了防止过拟合,在每一层后都增加了Dropout层[30-31],其作用是将全连接层的神经元输出以一定概率将其暂时置零,这样每一次训练的都是不同的网络。Dropout示意图如图5所示,左侧为一个正常的神经网络,右侧是引入Dropout层的神经网络。
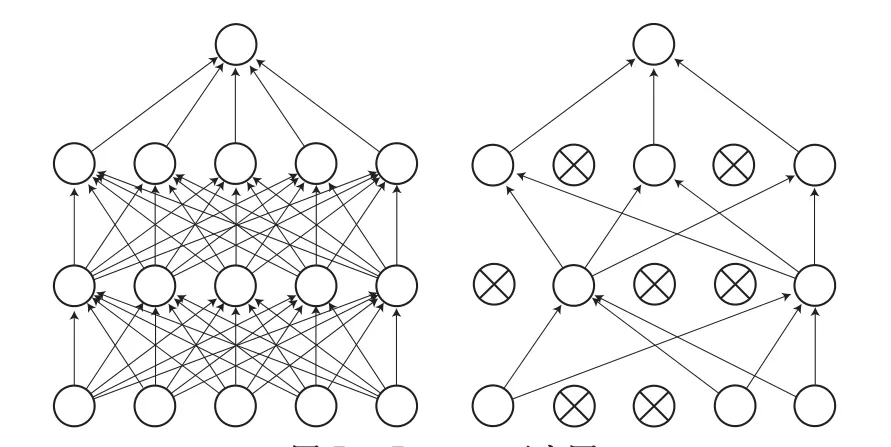
图5 Dropout示意图Fig. 5 of Dropout
1.3.5.5 模型的主要参数
Dropout层只在训练时起作用,其将全连接层神经元输出置零的概率P=1-Keep_prob,如果Keep_prob的值过小,将大大增加训练时间;其值过大则起不到很好的防止过拟合的效果。训练时Keep_prob的理想值为0.5,此时Dropout随机生成的网络结构最多,实际应用中一般选择0.5~0.8之间的值,本研究中Keep_prob设置为0.7。测试时,由于Dropout层不起作用,将Keep_prob设置为1.0。
由于Dropout层的存在,使用固定学习率会使得模型精度产生振荡,不利于精度的收敛。因此,本研究使用指数衰减法,即每经过一定的迭代周期,学习率乘以固定的衰减系数,获得指数衰减学习率[32],使后期模型的训练更加稳定。初始学习率为0.001,衰减率为0.96,衰减周期为10,即每训练10 次,学习率衰减为原来的96%。
1.3.5.6 模型评价标准——准确率和损失函数
准确率是指使用测试集对训练好的模型进行分类检测时,分类正确数据的百分比。准确率按照公式(2)计算。

式中:acc为准确率/%;n为测试集的数据总数;a为分类正确的个数。
损失函数表示预测值与实际值的不一致程度[33],损失函数越大表示不一致程度越高,模型的效果越差;反之,模型的鲁棒性就越好。本研究使用交叉熵损失,损失函数按照公式(3)计算。
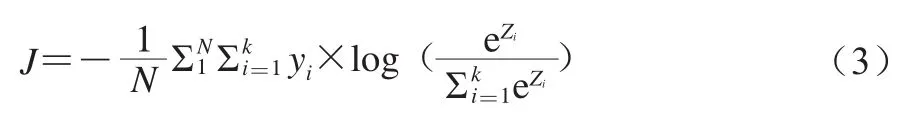
式中:J为损失函数;N为样本个数;k为类别数;ezi为类别i的网络输出指数;yi为类别i的真实标签。
1.6 模型的训练
根据测得的TVB-N含量和菌落总数数据以及GB 16869—2005《鲜、冻禽产品》[34]和GB 2707—2016《食品安全国家标准 鲜(冻)畜、禽产品》[35],可将鸡肉品质等级划分为可食用和不可食用2 类,在此基础上将鸡肉品质等级进一步划分为新鲜、次新鲜、初级腐败、中度腐败和重度腐败5 个等级,划分依据如表2所示。根据表2中的分类标准,结合采集到的理化指标,将所有样本分为5 类。

表 2 鸡肉品质分级标准Table 2 Chicken quality grading criteria
将分类好的数据按照5∶1的比例随机分成训练集和数据集。使用训练集进行训练,即将高光谱数据作为输入,将分类标签作为输出来调试模型;使用测试集来检验模型的鸡肉品质分类预测精度,即将高光谱数据作为输入预测样本分类,然后将预测分类与实际分类进行对比。
首先,将光谱和图像数据作为并行输入,即将一维光谱数据输入到一维卷积部分,将二维图像数据输入到二维卷积部分,对综合CNN模型进行训练,共训练5 000 次;然后,去掉综合CNN模型的二维卷积部分,得到1D-CNN模型,将一维光谱数据作为1D-CNN模型的输入,对模型进行训练,共训练5 000 次;去掉其一维卷积部分,形成2D-CNN模型,将二维图像数据作为2D-CNN模型的输入,对模型进行训练,共训练5 000 次。
2 结果与分析
2.1 高光谱数据标准化
由于采集到的高光谱图像中或多或少含有曝光过度点,这会对分类产生极大的影响,在提取目标区域后,采用光谱标准化的方法进行非均匀性校正。校正后的三维高光谱数据按照公式(4)计算。

式中:Xij为校正后的三维高光谱数据在(i,j)像元上的光谱;Dij为原始三维高光谱数据在(i,j)像元上的光谱;N为原始高光谱数据D中所有光谱的总均值;n为Dij中256 个光谱值的平均值。
处理前后的彩色图像如图6所示,校正前的图像中亮点即为过曝点。

图6 非均匀性校正效果图Fig. 6 Rendering of non-uniformity correction
2.2 经预处理所得高光谱数据
对高光谱数据进行预处理的结果如图7所示。可见,经过标准化和多元散射校正的光谱,其反射特性得到保留,差异性和平均光谱得到加强。
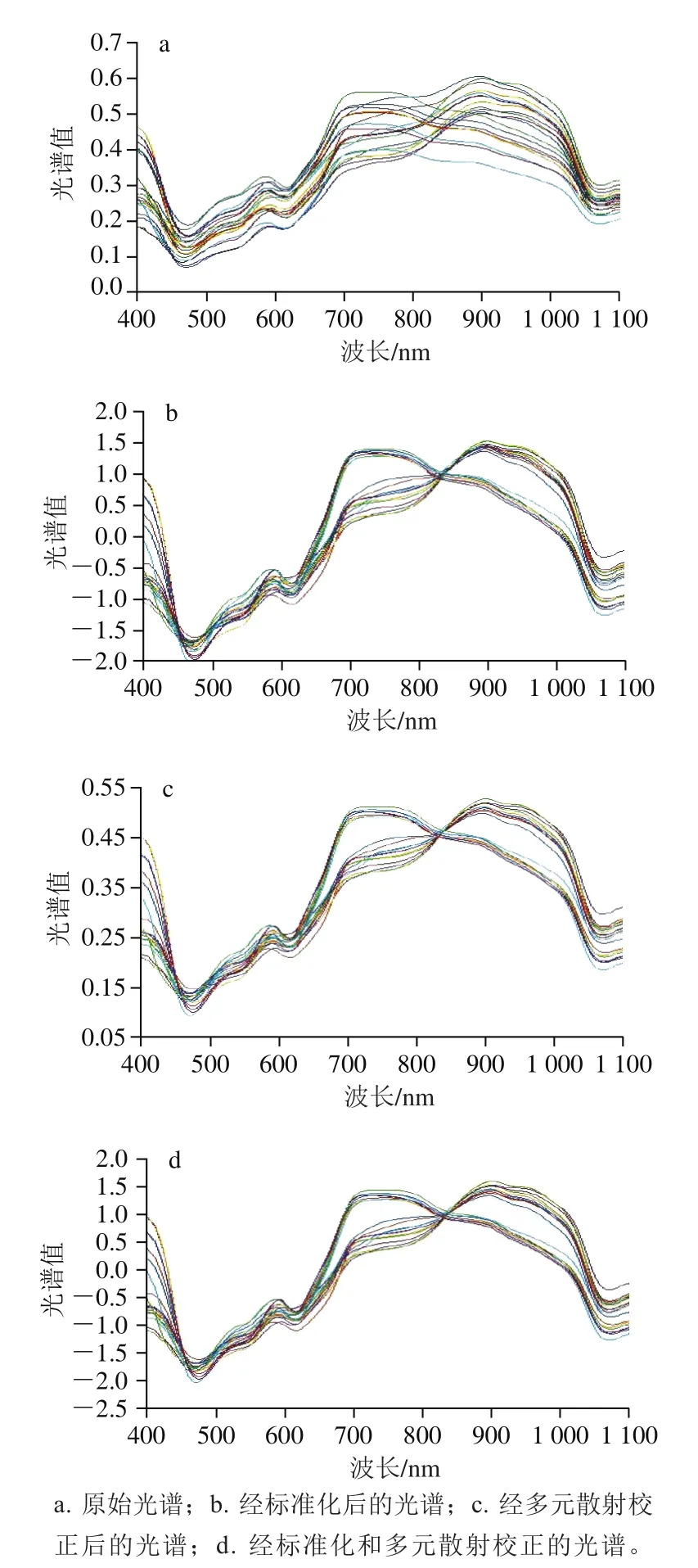
图7 光谱预处理效果图Fig. 7 Raw and pretreated spectra
2.3 彩色图像的预处理
图像数据预处理过程如图8所示,经过均值滤波的图像虽然滤除了噪声,但图像也变得模糊,边缘轮廓不明显,因此对滤波后的图像再进行锐化,锐化后的图像边缘轮廓得到了加强,鸡肉的纹理更加清晰。
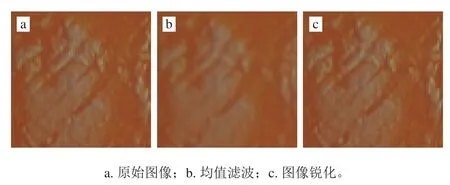
图8 彩色图像预处理效果图Fig. 8 Rendering of color image pretreatment
2.4 模型的测试
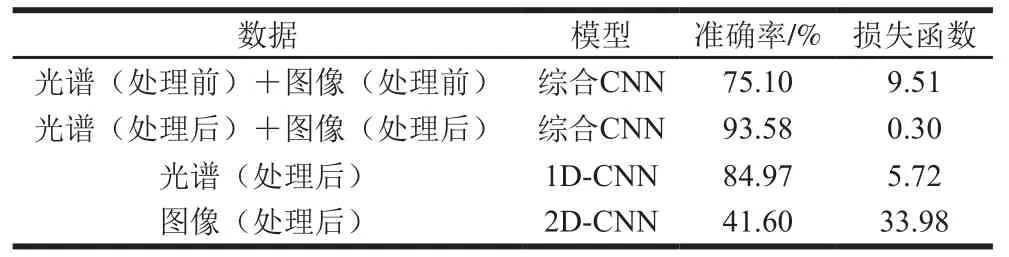
表 3 实验结果Table 3 Experimental results
使用测试集来检验模型精度。由表2可知:基于光谱数据的1D-CNN模型准确率为84.97%,损失函数为5.72;基于彩色图像数据的2D-CNN模型准确率为41.60%,损失函数为33.98;基于处理后光谱数据和彩色图像数据的综合CNN模型准确率达93.58%,损失函数为0.30。实验结果证明了CNN结合高光谱技术在鸡肉品质检测中的可行性,并且联合使用鸡肉的光谱和图像数据模型准确率更高,损失函数更小,其分类效果优于使用单一数据的分类模型,同时也证明光谱数据所包含的鸡肉品质信息远高于彩色图像数据。另外,基于预处理之前数据的综合CNN模型准确率为75.10%,损失函数为9.51,说明对输入数据进行预处理是十分必要的,这一过程能够有效提高模型的精度。
3 结 论
以鸡肉为研究对象,结合国家生化检验标准(TVB-N含量和菌落总数),根据高光谱数据的图像、光谱等信息,建立CNN模型,对鸡肉进行品质分类研究。其中,综合鸡肉高光谱数据中的光谱及图像信息的综合CNN模型,分类效果最好,准确率和损失函数分别达93.58%和0.30,而基于光谱信息的1D-CNN模型和基于图像信息的2D-CNN模型的准确率分别为84.97%和41.60%,损失函数分别为5.72和33.98。这表明综合使用鸡肉的光谱和图像数据,鸡肉的内、外特征得到了充分利用,使信息更加丰富,有效提高了模型的精度;并且,光谱数据可以提供比图像数据更多的有效信息,在鸡肉品质信息中占比重更大,对鸡肉品质检测的影响更大;另外,使用未经过预处理数据的综合CNN模型准确率为75.10%,略低于基于经过预处理数据的综合CNN模型,说明CNN虽然省去了人工特征提取的过程,可以直接将原始数据作为输入进行实验,但是对数据进行预处理仍然是必不可少的,这一过程可以使模型得到优化,从而更有效地对鸡肉品质进行快速、无损的分类检测。
猜你喜欢
国学(2020年1期)2020-06-29 15:15:30
电子制作(2019年16期)2019-09-27 09:34:46
饮食与健康·下旬刊(2019年11期)2019-03-08 14:33:43
今日农业(2019年16期)2019-01-03 11:39:20
宠物世界·猫迷(2017年7期)2018-01-25 13:23:41
数学物理学报(2017年6期)2018-01-22 02:26:53
摄影之友(影像视觉)(2017年1期)2017-07-18 11:12:16
自动化学报(2017年5期)2017-05-14 06:20:56
故事作文·低年级(2017年2期)2017-03-01 13:27:49
东北电力大学学报(2015年1期)2015-11-13 05:20:36
