
凝视视频卫星目标检测算法
2019-01-07 07:28张作省朱瑞飞
航天返回与遥感 2018年6期
张作省 朱瑞飞
凝视视频卫星目标检测算法
张作省1,2,3朱瑞飞4
(1 中国科学院长春光学精密机械与物理研究所,长春 130033)(2 中国科学院大学,北京100049)(3 中国电子科技集团公司第二十八研究所,南京 210000)(4 长光卫星技术有限公司,长春 130000)
为了实现对高分辨率光学遥感视频卫星成像视场范围内的飞机目标进行快速高效检测,提出一种遥感影像快速目标检测方案。文章借鉴深度卷积神经网络模型YOLO系列算法高速检测目标优点,引入端对端式全卷积神经网络构建检目标测算法,通过实验统计和探索光学卫星成像视场范围大小对目标检测准确率和检测速度的影响,结合目标尺度进行网络调优、改进检测模型,得到基于凝视成像视频卫星目标检测的高效算法。运用算法对来自“吉林一号”光学A星及视频3星的影像数据集进行目标检测实验统计,在413张800像素×800像素的静态遥感影像测试集中实现76.2%的平均检测准确率,在同等尺度的遥感视频序列中实现31帧/s的检测速度。该算法成功将深度卷积神经网络技术引入到凝视视频卫星遥感应用领域,有效证明了深度学习技术在遥感视频识别领域的可行性。
视频卫星 目标检测 深度卷积神经网络 卫星遥感应用
0 引言
凝视视频卫星[1-3]作为一种新型对地观测卫星,采用“凝视”成像方式对某一区域进行连续观测,即:随着卫星运动其光学成像系统始终盯着目标区域进行拍摄记录,可以连续观察“凝视”视场内变化。从2017年1月由“快舟一号”甲运载火箭发射的亚米级像素分辨率的商用“吉林一号”视频3星到2017年11月由“长征六号”运载火箭以一箭三星[4-5]方式发射“吉林一号”视频4、5、6星,凝视视频卫星快速发展,高分辨率影像[6]数据急剧增加。为充分利用凝视遥感视频数据,实现对地观测“凝视”视场内重要目标自动检测以及进一步开发更智能的遥感解译系统,从海量高分数据中提取有效特征就成为了其中的关键技术。
传统的目标识别和图像分割方法很难适应海量数据,其所依赖的特征表达均为人工设计,例如:文献[7]处理步骤较多因而算法实现时较为耗时;文献[8]虽能实现实时检测,但其准确率却不符合高精度的要求。这些传统算法强烈依赖数据本身特征,在图像数据增多时难以满足高准确率和高效率的双项指标要求。此外,找到合适的目标特征并设计相应的分类方法是目标检测和识别的核心。如HOG[9]、SHIT[10]等采用通用特征,往往只能表达图像中目标的底层特点,在缺少训练样本时,难以有效地用于复杂场景,其泛化性能受到严重制约。此外,依据具体目标显著性特点设计良好的旋转或尺度不变性的模板进行匹配,也能进行有效分类和识别。但这些特征的设计强烈依赖于专业背景知识、模型固化、参数难以调整,在面对新的复杂场景时难以保证较高的准确性。
近年来,深度卷积神经网络技术(Convolutional Neural Network,CNN)[11]的出现为图像目标检测和识别提供新的思路和研究方法。其实质是构建多层结构的机器学习模型对海量训练数据进行复杂特征的学习,用于之后的分析和预测。因此,其具备强大的影像数据学习能力和高度的图像特征抽象能力,在诸多图像领域取得了革命性的成功。
与传统图像处理场景相比,遥感影像数据有着很大不同:影像尺度大、视场大、目标小且目标像素分辨率低。对遥感视频数据进行目标检测和识别属于大范围、小目标、高速度的检索问题,就检测和识别的准确率而言,其突出困难主要有以下两点:
1)目标形态更加复杂。不同尺度、不同排列角度、不同种类以及不同光照分布和采集影像数据时天气条件的多时相性,使得目标规律性更加难以总结。
2)背景干扰更加明显。由于光学卫星的成像尺度较大,高分辨率遥感影像数据中会出现更多与目标某些图像特征相似的背景干扰。例如:机场中在以飞机为目标时,停机坪中的纹理和阴影、复杂的人造建筑区,都给检测造成了极大干扰。
而近年来,深度卷积神经网络技术的出现为图像目标识别提供了全新的方法,并以高准确率广受关注。将其用于遥感影像数据的动态目标检测和识别时,最主要的问题是其检测速度是否满足实时性的要求。而深度卷积神经网络YOLO(You Only Look Once,YOLO)[12]在传统目标识别领域克服了检测速度的瓶颈,但在识别小目标的任务中精度非常低,其结构建立在牺牲小目标准确的基础上来提升检测效率。在YOLOv2[13]网络的方案中,对传统场景VOC2007[14-15]数据集中平均像素尺度为600像素×600像素的图像可达到70帧/s的检测速度,完全满足实时性要求,实现目标快速检测。
本文结合遥感影像特点对YOLOv2网络结构进行适当改进,通过探索检测时影像与训练集影像的相对尺度对检测模型准确率的影响,首次将深度卷积神经网络应用于凝视视频卫星目标检测,得到适用于凝视视频卫星的高效目标检测方法,填补了光学视频卫星成像领域目标检测方案的技术空白。
1 遥感目标识别方案
1.1 算法架构
不同于传统目标识别方法中常用的区域选择、特征提取、目标分类三个步骤,在YOLO网络框架中,将目标识别问题转化为回归问题。步骤如下:
1)将原图缩放为448像素×448像素,图片划分为7个×7个网格,每一个网格作为一个单元。
2)CNN提取特征和预测:卷积部分提取特征。
3)全连接层预测:每一个单元预测7个包围框,每个包围框对应5个参数(包围框中心位置()、包围框的宽、高以及置信值评分)。
其中置信值评分即为构建网络的损失函数,


4)过滤预测框,通过非极大值抑制合并冗余框。
YOLO(v1)使用全连接层进行包围框预测,要把维度为1 470像素×1像素的全链接层重塑为维度为7×7×30像素的最终特征,这样会丢失较多空间信息导致定位不准。YOLOv2移除全连接层(以获得更多空间信息)并借鉴使用Faster-RCNN[16]里的锚定框预测包围框。如图1所示,锚定框即通过对卷积特征图进行滑窗采样,每个中心预测种不同大小和比例的建议框,在Faster-RCNN中取值为9。由于都是卷积不需要重塑,可以很好地保留空间信息,最终特征图的每个特征点和原图每个单元一一对应。

图1 锚定示意
具体步骤如下:
1)去掉最后的池化层确保输出的卷积特征图有更高的分辨率;
2)缩减网络,让图片输入分辨率为416像素×416像素,目的是让后面产生的卷积特征图宽高都为奇数,这样就可以产生一个中心单元;
3)使用卷积层降采样(参数为32),使得输入卷积网络的416像素×416像素图像经卷积提取特征后得到13像素×13像素的特征图;
4)把预测类别的机制从空间位置解耦,由锚定框同时预测类别和坐标。
首先对锚定框的个数和宽高维度进行预选,利用统计学习中的K-means聚类[17]方法,对数据集中的真实包围框做聚类,找到真实目标框统计规律。这样得到更具代表性的先验包围框维度,以使网络更容易学到准确的预测位置。以聚类个数为包围框个数,以个聚类中心框的宽高维度为锚定框的维度。
对来自手工标注的样本数据库中的包围框的宽高(共计12 730组目标框)进行K-means聚类,分别选取5类和9类聚类中心,结果如图2所示。图2(a)是5个聚类中心的聚类结果,图2(b)为9个聚类中心的结果。随着聚类中心增多,重叠度IOU增大,其复杂度也不断增加,为了平衡复杂度和IOU最终选取5种聚类中心。以表1所示的5种聚类中心作为网络训练时的anchor框取值大小,进行模型训练。

图2 聚类结果
表1 聚类中心
Tab.1 Clustering center 像素

最终算法如图3所示。给定一个输入图像,将图像划分成S×S的网格,对于每个网格,均预测5个包围框,每个包围框对应5个坐标值:中心坐标(x,y),包围框的宽和高(w,h)以及相应的类别概率值。由于传统场景图像尺度与遥感影像尺度相差甚远,需将遥感影像进行适当的切分以训练合适的检测模型。
1.2 面向光学遥感数据的特征迁移学习
在目标识别与图像分类领域,当训练一个高识别效率和强泛化性能的深度卷积神经网络模型时,需要大量带标签的样本数据。之前多数深度学习模型面向自然场景的目标识别任务数据量庞大且取得了非常优秀的成绩。根据文献[18]的结论,在最后一层全连接层之前的网络层称为瓶颈层,瓶颈层的输出节点向量可以被看作任何图像的一个更加精简且表达能力更强的特征向量。在新数据集上直接利用训练好的神经网络对图像进行特征提取,再用提取得到的特征向量作为输入来训练新的单层全连接网络处理新问题。
在光学遥感领域鲜有成熟的公开数据集,本文采用迁移学习的方法将在大样本数据库预训练好YOLOv2的模型应用在基于“吉林一号”光学A星的遥感影像数据构成的样本数据库中,有效地构建了面向光学遥感影像数据的目标识别和实时动态目标跟踪的深度卷积神经网络模型。
YOLOv2低层卷积结构提取图像的通用特征,如边缘检测;中层和高层卷积结构包含识别和分类有关的特征。迁移学习指的是网络顶层的迁移,最有效的方式是将顶层分类目标替换为飞行器,采用网络微调的方式利用少量样本进行训练实时飞行器目标识别模型。
1.3 针对光学遥感影像数据的目标识别实验
由于“吉林一号”光学A星的载荷相机每一景成像的大小为20 000像素×20 000像素,像素分辨率为0.72m,影像中机场中的飞机所占像素大致在20像素×20像素至300像素×300像素区间范围内,在图中所占比例在0.1%~1.5%的区间范围。人眼距屏幕距离约为0.5m,考虑视觉系统衍射极限:



图4 遥感场景切分后的待检测区域
1.4 静态遥感影像目标识别仿真
首先,基于静态光学遥感影像数据进行卷积神经网络的实验对127张“吉林一号”光学A星原始影像进行切割,建立样本集为2 413张800像素×800像素大小的来自全世界各地的机场影像数据,其中2 000张作为训练集,413张作为测试集。基于此样本集,分别使用YOLOv2和Faster-RCNN(ResNet)进行训练并测试,为了更加清楚的表示两种模型的检测性能,用P-R曲线来验证实验结果。在P-R曲线中,曲线与坐标轴所包围的面积,代表测试平均准确率(Average Precision,AP)。其定义如下:

式中代表查准率(精准率);代表查全率(召回率)。定义如式(5)、式(6):
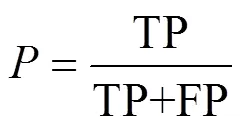

式中TP表示飞机目标被正确检测数量;FP表示不是飞机的干扰目标被检测为飞机的数量;FN表示飞机目标没有被检测的数量。
实验时,得到如图5所示的曲线。其中,红色曲线代表YOLOv2结果,对应AP1,蓝色曲线为Faster-RCNN(ResNet)的结果,对应AP2。其中横轴为模型的查全率,纵轴是检测的查准率。由图可知,Faster-RCNN(ResNet)的检测结果要高于YOLOv2,但其在测试集中1.2s/帧的检测速度远低于YOLOv2的3.2ms/帧的检测速度。考虑到视频影像特点,在实际使用时,YOLOv2更具有借鉴价值。

图5 PR曲线
对图4切分得到的3 000像素×2 000像素的影像利用训练好的YOLOv2模型进行飞机检测得到如图6所示的结果。从图6可以看出,有明显的漏检情况发生,一些清晰的目标被遗漏,用黄色框标出,这是难以接受的。由此引发了以下的思考:模型训练时采用的训练集尺度与实际使用模型进行目标检测时使用的图像尺度,对目标检测的准确率是否有影响?如果有,这种影响关系怎么体现?
将图6切分成四块一样大的图像再次进行检测,切分后检测效果如图7所示。对比可以发现检测效果得到较大提升,在图7(c)部分三左下角遗漏掉一架纹理和颜色特征不明显的飞机,并未出现错检。由此证明,实际使用时影像尺度对准确率是有直接关系的,需要探究这种尺度关系对模型稳健性的影响。
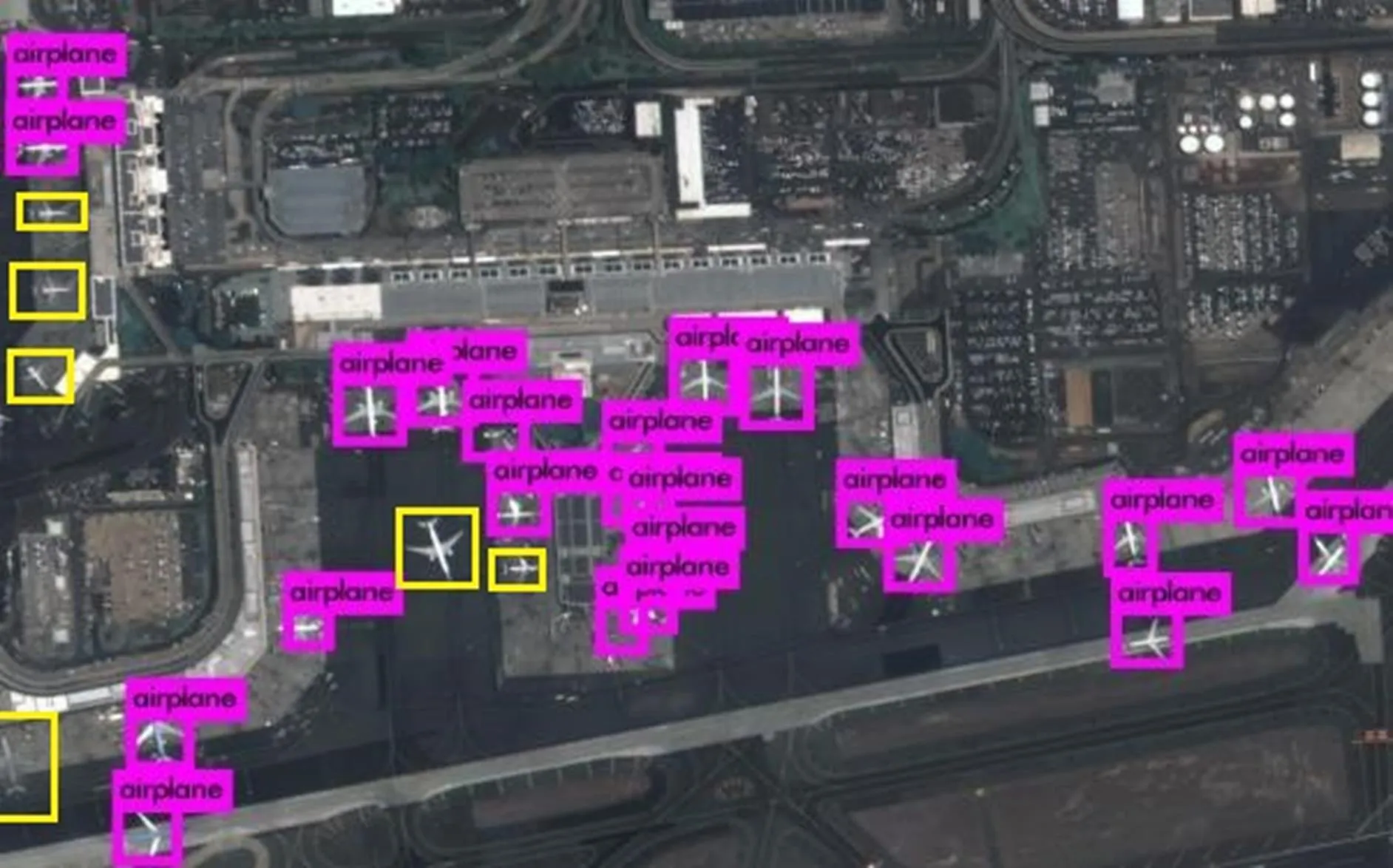
图6 整体识别结果

图7 切分后的识别结果
针对训练好的检测模型对不同尺度的遥感影像数据进行检测的漏检率与影像相对尺度的关系,进行统计学实验。对“吉林一号”视频星拍摄得到的影像分别切分100像素×100像素、200像素×200像素、…、5 000像素×5 000像素各50张,利用训练好的YOLOv2模型进行检测。其漏检率统计结果如图8所示。由图可知,当测试集与训练集的相对尺度大小为100%时,目标的漏检率最低。当相对尺度低于50%或高于180%时,最终识别结果由于出现漏检率高于10%的情况,该尺度影像不可使用训练得到的模型进行直接检测。

图8 漏检率与相对像素大小关系
对“吉林一号”视频3星遥感视频影像进行动态目标识别,实验环境如下:系统Ubuntu16.04,CUDA8.0,cudnn5.1,OpenCV2.4.10,显卡Quadro K5200。仿真结果如图9所示,在800像素×800像素的遥感视频影像中实际实现的识别速度为0.032 3s帧,即可达到31帧s,完全满足实时性要求。

图9 遥感视频实时识别结果
2 结束语
在对遥感影像数据的挖掘中,算法成功将卷积神经网络技术应用于遥感影像数据目标识别领域。通过构建针对视频卫星影像的动态目标识别网络框架,分别对高分辨率静态影像和动态遥感视频进行实验,在800像素×800像素的静态遥感影像中实现76.2%的识别准确率,同时对视频序列可实现31帧/s的识别速度。此外,通过实验统计探索训练数据集与测试数据集中样本的相对大小对模型准确率的影响,有效地证明深度学习技术在遥感识别领域的可行性,对于进一步开发遥感视频卫星实时目标检测和识别算法具有参考价值。但本文依然存在不足:训练生成的模型在多尺度的目标识别中存在着明显的缺陷,如何改进网络和识别方法以实现多尺度目标的高准确性识别需进一步探索;此外,在保证识别速度的前提下,算法如何提高模型的准确率依然需要进一步改进。
[1] 姚烨, 乔彦峰, 钟兴, 等. 凝视成像降质模型的超分辨率重建[J]. 光学学报, 2017, 37(8): 109-118. YAO Ye, QIAO Yanfeng, ZHONG Xing, et al. Super-resolution Reconstruction of Staring Imaging Degraded Model[J]. Acta Optica Sinica, 2017, 37(8): 109-118. (in Chinese)
[2] 朱厉洪, 回征, 任德锋, 等. 视频成像卫星发展现状与启示[J]. 卫星应用, 2015(10): 23-28. ZHU Lihong, HUI Zheng, REN Defeng, et al. Status Video Imaging Satellites Development and Inspiration[J]. Satellite Application, 2015(10): 23-28. (in Chinese)
[3] 张曼倩. 吉林林业一号卫星[J]. 卫星应用, 2017(3). ZHANG Manqian. Jilin Forestry-1 Satellite[J]. Satellite Application, 2017(3). (in Chinese)
[4] 科轩. 快舟一号甲成功发射“一箭三星”开启中国商业航天新时代[J]. 中国航天, 2017(1): 23-24. KE Xuan. KZ-1 Successfully Launched “One Vehicle with Triple-satellites” to Open a New Era of China's Commercial Space[J]. Aerospace China, 2017(1): 23-24.(in Chinese)
[5] 商显扬, 杜朋, 王桂娇, 等. 一箭三星发射结构布局及斜推分离技术研究[J]. 强度与环境, 2018, 45(1): 7-11. SHANG Xianyang, DU Peng, WANG Guijiao, et al. Research of Structural Layout and Inclined Separation for One Vehicle with Triple-satellites[J]. Structure & Environment Engineering, 2018, 45(1): 7-11. (in Chinese)
[6] 李果, 孔祥皓. 静止轨道高分辨率光学成像卫星发展概况[J]. 航天返回与遥感, 2018, 39(4): 55-63. LI Guo, KONG Xianghao. Development of High-resolution Optical Imaging Satellites in Geostationary Orbit[J]. Spacecraft Recovery & Remote Sensing, 2018, 39(4): 55-63. (in Chinese)
[7] 姚远, 姜志国, 张浩鹏. 基于层次化分类器的遥感图像飞机目标检测[J]. 航天返回与遥感, 2014, 35(5): 88-94. YAO Yuan, JIANG Zhiguo, ZHANG Haopeng. Aircraft Detection in Remote Sensing Image Based on Hierarchical Classifiers[J]. Spacecraft Recovery & Remote Sensing, 2014, 35(5): 88-94. (in Chinese)
[8] 王旭辉, 刘云猛, 裴浩东. 基于嵌入式图像处理平台的实时多目标识别算法[J]. 科学技术与工程, 2014, 14(3): 227-230. WANG Xuhui, LIU Yunmeng, PEI Haodong. One Real-time Multi-target Recognition Algorithm Based on the Embedded Image Processing Development Platform[J]. Science Technology and Engineering, 2014, 14(3): 227-230. (in Chinese)
[9] DALAL N, TRIGGS B. Histograms of Oriented Gradients for Human Detection[C]//Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on, IEEE, 2005: 886-893.
[10] COMANICIU D, MEER P. Mean Shift: A Robust Approach Toward Feature Space Analysis[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(5):603-619.
[11] HINTON G E, SALAKHUTDINOV R R. Reducing the Dimensionality of Data with Neural Networks[J]. Science, 2006, 313(5786): 504-507.
[12] REDMON J, DIVVALA S, GIRSHICK R, et al. You Only Look Once: Unified, Real-time Object Detection[C]//Computer Vision and Pattern Recognition, 2016. IEEE Computer Society Conference on IEEE, 2016:779-788.
[13] REDMON J, FARHADI A. YOLO9000: Better, Faster[C]//2017 IEEE Conference on Computer Vision & Pattern Recognition. Honolulu, USA: IEEE, 2017:6517-6525.
[14] KOBETSKI M, SULLIVAN J. Apprenticeship Learning: Transfer of Knowledge via Dataset Augmentation[C]// Scandinavian Conference on Image Analysis. Springer, Berlin, Heidelberg, 2013: 432-443.
[15] MARKUS K, JORMA L, VILLE V. The 2005 PASCAL Visual Object Classes Challenge[J]. Lecture Notes in Computer Science, 2015, 111(1): 98-136.
[16] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6):1137-1149.
[17] ANIL K. Data Clustering: 50 Years beyond K-means[J]. Pattern Recognition Letters, 2010, 31(8): 651-666.
[18] DONAHUE J, JIA Y, VINYALS O, et al. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition[C]//International Conference on International Conference on Machine Learning.Eprint arXiv:1310.1531, 2014.
Target Detection Algorithm of Staring Video Satellite
ZHANG Zuoxing1,2,3ZHU Ruifei4
(1 Changchun Institute of Optics, Fine Mechanics and Physics, Chinese Academy of Sciences, Changchun 130033, China)(2 University of Chinese Academy of Sciences, Beijing 100049, China)(3 The 28th Research Institute of China Electronics Technology Group Corporation, Nanjing 210000, China)(4 Chang Guang Satellite Technology Co., Ltd, Changchun 130000, China)
In order to realize fast and efficient detection of aircraft targets in the field of view of high-resolution optical remote sensing video satellite, a fast target detection scheme for remote sensing images is proposed. Using the detection capability of the deep convolutional neural network model YOLO series algorithm at high speed, an end-to-end full convolutional neural network was introduced to construct a detection algorithm. The influence of optical satellite imaging field of view on the target detection accuracy and speed was explored by experiments and statistics. And then, by tuning network and improving detection model based on the target scale, an efficient algorithm for gaze imaging video satellite target detection was obtained from data of Jilin-1 Optical Satellite and Video Satellites-3, which achieved a detection accuracy of 76.2% in 413 static remote sensing images with 800×800 pixels, and had a detection speed of 31 frames per second in remote sensing video sequence. Deep convolutional neural network technology was successfully introduced into the field of remote sensing applications for staring video satellites,which proved the feasibility of deep learning technology in the field of remote sensing video recognition.
video satellite; target recognition; deep convolution neural network; satellite remote sensing application
TP753
A
1009-8518(2018)06-0102-10
10.3969/j.issn.1009-8518.2018.06.012
2018-04-02
吉林省科技厅重点科技攻关项目(20170204034SF);国家重点研发计划(2016YFB0502605)
张作省,男,1993年生,2018年获中国科学院长春光学精密机械与物理研究所光学工程硕士学位。研究方向为基于深度学习技术的遥感影像目标检测。E-mail:zhangzuoxing1993@163.com。
朱瑞飞,男,1986年生,2013年获中国科学院长春光学精密机械与物理研究所博士学位。主要研究方向为基于遥感影像数据挖掘。
(编辑:庞冰)
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
马克思主义哲学研究(2020年1期)2020-11-26
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
互联网天地(2016年1期)2016-05-04
