
基于HMM的声调语音模型研究
2019-01-02 12:44:34易雪蓉
武汉工程大学学报 2018年6期
易雪蓉,黄 巍*,2,胡 迪,蒋 怡
1.武汉工程大学计算机科学与工程学院,湖北 武汉 430205;2.智能机器人湖北省重点实验室(武汉工程大学),湖北 武汉 430205
语言是人类沟通的重要工具,语音识别是人工智能研究的重要领域。20世纪50年代,贝尔实验室设计了第一个语音识别系统,实现了对孤立数字的语音识别[1]。20世纪60年代,提出了时间归一化打分机制、音素动态跟踪技术和动态规划算法,有效地解决了语音信号的特征提取和不等长语音匹配问题[2]。20世纪70年代,模式识别思想、线性预测编码等技术被应用于语音识别中,识别对象从孤立词转移到连续语音[3]。20世纪90年代及以后,隐马尔科夫模型(hidden markov modol,HMM)、高斯混 合 模 型(gaussian mixed model,GMM)被提出[4],基于GMM-HMM的语音识别框架得到广泛使用和研究,文献[5]通过改进语音特征参数相邻帧的相关性,进一步提高GMM-HMM的准确度;文献[6-7]使用GMM-HMM识别了连续语音的声调。目前,深度学习技术也被应用于语音处理系统[8-11],由于它对训练数据和硬件资源有着极高的要求,限制了其使用范围。
现代汉语是一种有声调的特殊语音,音素和声调组合可以构成无数个多音字和同音字的发音。一方面,同一个汉字在不同的声调下代表不同的意义,另一方面,相同的读音可能代表完全不同的汉字,因此,与印欧语系的语言相比,声调和上下文信息对汉语语音的识别具有更重要的作用[12]。
本文在语音模型中添加声调,并使用字转移概率捕获上下文信息,修改HTK[13]工具包以适应汉语语音识别问题,实验结果证明了声调对近音字识别的重要性,同时字转移概率的引入能有效提高同音字识别的准确率。
1 基于HMM的声调语音模型
GMM-HMM语音识别系统的框架图如图1所示,其结构主要由3部分组成:语言模型、字典和语音模型[14]。

图1 语音识别系统框架Fig.1 Framework of speech recognition system
1.1 声调语音模型
GMM-HMM通常由λ={O,S,π,A,B}来描述[15],其中 O 代表L个观测向量集合{o1,o2,…,oL},S是 K 个 HMM 状态的集合 {s1,s2,…, sK},π={π1,π2,…,πK}是初始状态分布,A是所有状态转移概率所构成的矩阵(aij)(aij表示从状态i到状态j的转移概率),B是状态观测符号的概率分布{bi(oj)}K*L(bi(oj)表示在状态si下观察到观测向量oj的概率)。一个HMM的生成模型M如图2所示[13],图2中1,2,3,4,5,6代表状态 s1,s2,s3,s4,s5,s6。

图2 HMM的生成模型Fig.2 HMM Generation Model
作为一个例子,在M的一个实例中,出现状态X=(s2,s2,s3,s4,s4,s5)并观察到观测向量序列O=(o1,o2,o3,o4,o5,o6)的概率为:
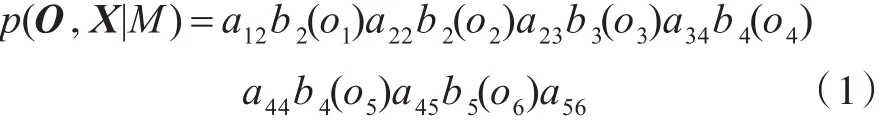
在基于GMM-HMM的语音识别应用中,X是未知隐藏的,则:
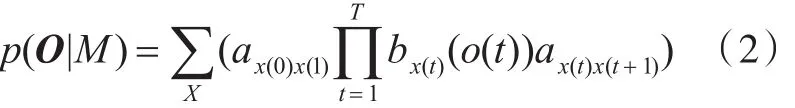
x(0)是模型的初态,x(T+1)是模型的终态。
当观察到观测序列 O=[o(1),o(2),…,o(t)]时,最可能出现的未知状态序列X应该是使得观测向量序列O出现的可能性最大的状态序列,即:
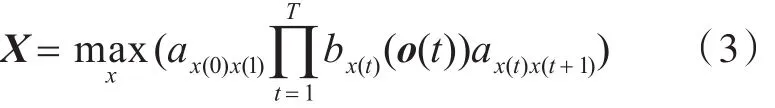
本文的实验中一个模型M对应一个音素W,即p(O|W)=p(O|M)。
在汉语中,一个汉字读音就是一个音节,每个基本音节由3个部分组成:声母、韵母和声调[16],声母和韵母又是由音素组成的复合音。声母有23个,韵母有39个,音素包含辅音22个和元音10个,辅音对应声母,元音对应韵母。汉语拼音声母、韵母和音素对照见图3[17],其中-i(前)为zi,ci,si发音的尾部部分,-i(后)为 zhi,chi,shi发音的尾部部分。声调有4种,其中仅由声母和韵母构成并实际存在的声韵结合体据统计一共有400多个,将这些声韵结合体与音调组合成音节共记1 200多个[18]。在实际生活中,汉语口语中的音调不仅仅是一声、二声、三声和四声,还存在轻声。为了识别的准确性和全面性,在本文实验的声调模型中,除了标准规定的四种声调外,另加了一种轻声,构成5种声调,见表1。最后添加了声调的音素模型有81个,声调仅跟在每个音节的最后一个音素后(见图4)。

表1 声调模型对应表Tab.1 Mapping table of tone model

图3 汉语拼音声母、韵母和音素对照图Fig.3 Comparison of Chinese Pinyin initials,finals and phonemes

图4 音素-声调模型内容Fig.4 Content of phoneme-tone model
从图3和图4中可以看出:新模型与声韵母-音调组合相比较降低了复杂度,与传统音素模型相比较提高了精确度。部分传统音素从1个细分成5个,让识别过程中的分类更加精细,如图5和图6所示,图5是传统音素建立HMM模型的示意图,音素相同发音不同的汉字所生成的HMM模型是一样的;图6是声调-音素建立HMM模型的示意图,添加声调模型后,音素相同发音不同的汉字所生成的HMM模型是不一样的。传统模型中音素相同发音不同的汉字因为共用相同的HMM模型,最后计算的 p(O|M)相等,无法选取最优字;声调-音素模型中音素相同发音不同的汉字因为HMM模型的不同,最后计算出的 p(O|M)不一样,根据实际情况选择可能性最大的概率,可以让识别结果更准确。
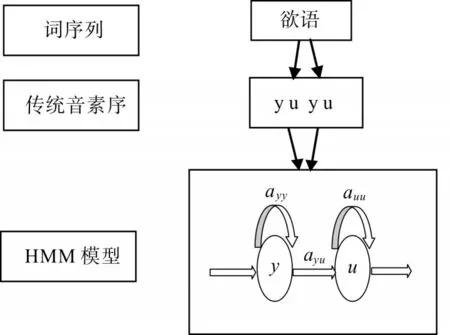
图5 基于传统音素的HMM模型示意图Fig.5 Schematic diagram of HMM model based on traditional phoneme

图6 基于声调-音素的HMM模型示意图Fig.6 Schematic diagram of HMM model based on tone-phoneme
1.2 字转移概率语言模型
语音识别应用中常用的语言模型是基于N-gram的统计语言模型。N-gram模型采用的是Markov假设[14],即当前字出现的概率仅与前1个字有关系。
用 A=(start,a1,a2,a3,…,am,end)表示一段待识别的字序列,ai表示其中的一个字,根据语音模型的处理结果,可以从词网中选取出ai的所有同音字,然后计算每一个字出现的概率,选取概率最大的字组成最后识别出的字序列,若概率相同则选取同音字里出现的第一个字。
假设用 w1,w2,w3,…,wm-1,wm表示完整的句子中出现的每一个字,根据Markov假设,字wi出现的概率为:
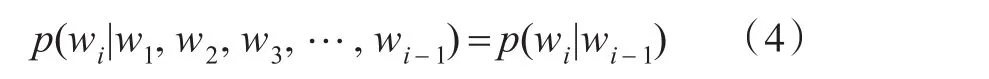
整个句子出现的概率:
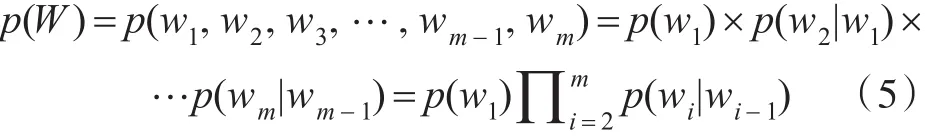
其中 p(w1)表示start后出现字 wi的概率。这些概率在原始模型中全等于1,以至在同音字识别中正确率是不高的。
本文首先对训练数据进行统计,构建一个为全0的矩阵C=(cij)(N+2)*(N+2),cij表示字i后面出现字j的概率,N+2表示有N个无重复的汉字和表示开始与结束的start与end;然后依次读取训练集,读取到字符X,就在矩阵的行中找到X的位置x,接着读取下一个字符Y,在矩阵的列中找到该字符的位置y,则cxy=cxy+1,表示字X后出现Y的次数;最后对矩阵中的数值进行计算。则字转移概率:p(wi|wi-1)=cwi-1wi。
2 实验部分
2.1 实验工具和数据
本文研究修改了HTK工具包,以得到支持声调和字转移概率的GMM-HMM语音识别模型。为验证声调信息和字转移概率对汉语语音识别的影响,分别进行了两组实验。实验一是对声韵母相同声调不同的近音字的识别;实验二是对声韵母和声调都相同的同音字的识别。
实验一所使用的语音数据集一为本研究收集的6个人对5组声韵母相同但声调不同的单个汉字的发音,共1 000条语音数据,其中每5个相同声韵结合体不同声调的孤立汉字为一组,每组有180个训练发音,20个测试发音。5组数据分别为:
1、ma1妈,ma2麻,ma3马,ma4骂,ma5吗;
2、ya1压,ya2牙,ya3雅,ya4讶,ya5呀;
3、mo1摸,mo2磨,mo3抹,mo4末,mo5魹;
4、zuo1作,zuo2昨,zuo3左,zuo4坐,zuo5咗;
5、qi1七,qi2奇,qi3起,qi4气,qi5啐。
这5组数据中,第1组和第2组有着相同的韵母,不同的声母,目的是验证声母对声调发音的影响;第1、3组数据有相同的声母和不同的韵母,目的是验证韵母对声调发音的影响。
实验二所使用的语音数据集二为本研究收集的10个人对10句连续字的发音,共110条,其中100条训练发音,10条测试发音。10组训练数据为:
1、慢man4慢man4喜xi3欢huan1你ni3;
2、我wo3在zai4雨yü3中zhong1漫man4步bu4;
3、我wo3在zai4洗xi3衣yi1服fu5;
4、再zai4见jian4;
5、我wo3在zai4做zuo4作zuo4业ye4;
6、我wo3在zai4做zuo4手shou3工gung1;7、作zuo4息xi1时shi2间jian1;
8、小xiao3荷he2才cai2露lu4尖jian1尖jian1角jiao3;
9、保bao3持chi2沉chen2默mo4;10、蓝lan2色se4墨mo4水shui3。
这10组数据中,第1组和第2组有相同发音的“慢”和“漫”,第2、3、4、5、6组有相同发音的“在”和“再”,第1、3组有相同发音的“喜”和“洗”,第5、6、7组有相同发音的“做”和“作”,第9、10组有相同发音的“默”和“墨”,这几组数据可以用来验证字转移概率对同音字识别的作用。
2.2 实验过程
第一步:统计实验数据中的汉字,编辑语法文件,实验一中的语法规则是多选一,然后通过HTK命令将语法文件转换成可供计算机识别的“词网文件”;实验二中的语法规则是多选多,然后建立两个“词网文件”,分别是HTK命令自动生成的无字转移概率的词网文件wnet1和添加了字转移概率的词网文件wnet2。
第二步:提取供训练的汉字语音文件的梅尔倒谱系数,转化成为特征矢量文件。
第三步:结合实验数据构建两个字典。字典一直接使用HTK命令生成,由汉字和音素组成,不含音调信息;字典二是在字典一的基础上添加声调信息,将声调与每个字的最后一个音素相结合,生成含有音调的字典。
第四步:构建音素和音素-声调两个列表。音素表只包含音素,而音素-声调表在音素表的基础上加入声调信息,在每个元音后加上声调,声母不变。
第五步:构建基于音素的隐马尔科夫模型HMM1和基于音素-声调的隐马尔科夫模型HMM2,HMM1和HMM2都被迭代训练了7次。
第六步:实验一和实验二分别使用了语音数据集一和语音数据集二,对比了无声调模型HMM1和有声调模型HMM2对近音字和同音字的识别效果。
2.3 实验结果
实验中正确率(Correct,α)定义如式(6),准确率(Accuracy,β)定义如式(7),其中N表示语音转译文件中的标签总数,D表示删除错误的数量,S表示替换错误的数量,I插入错误的数量[13]。
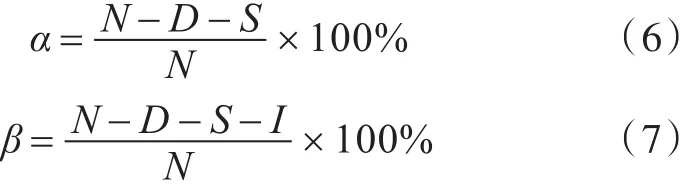
从实验一的结果(见表2)中可以看出,在识别孤立汉字时,声调模型对近音字识别结果的影响很大。无声调模型的识别结果均是词网中的第一个汉字,所以只有20%的正确性;而有声调模型基本可以有效的识别声韵母相同但声调不同的汉字,但是仍然有些错误。从图7中可以看出,一声比较容易被识别成二声,轻声容易被识别为四声,其原因是一声和二声均以平声结尾,轻声和四声均有些短促,所以容易被混淆。
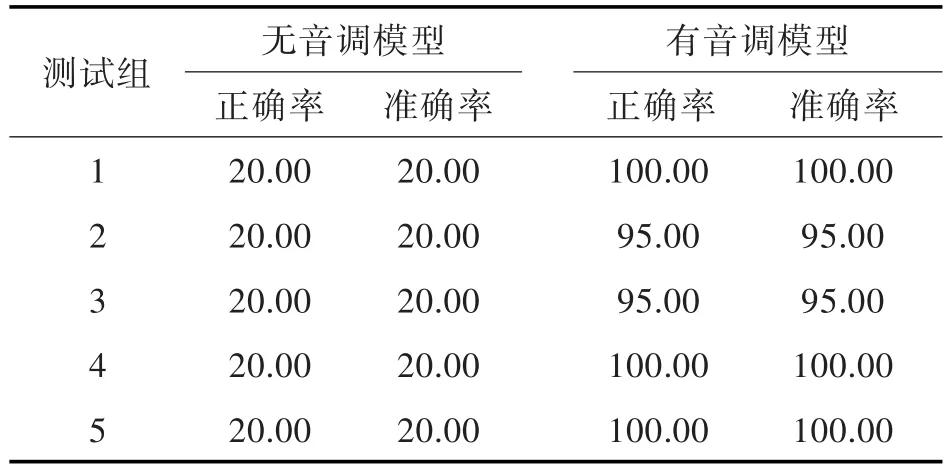
表2 孤立字识别的正确率和准确率比较Tab.2 Comparison of correct rate and accuracy of isolated word recognition %

图7 有音调模型识别结果错误对比Fig.7 Errors comparison of tonal model recognition
从实验二2次测试结果的正确率和准确率的比较结果(见表3)中可以看出,在连续汉语语音识别中,声调信息与字转移概率结合使用对同音字识别结果影响很大。在相同数据下,有字转移概率的识别正确率比没有字转移概率的正确率提升了20%左右,准确率也提升了30%左右。在没有字转移概率的识别中,系统会默认选择词网中第一个出现相同发音的字,在添加字转移概率后,系统会通过计算概率选择概率最大的字,因此正确率会提升。

表3 连续语音识别正确率和准确率比较Tab.3 Comparison of correct rate and accuracy of continuous speech recognition %
3 结 语
将汉语中的声调信息和字间转移概率引入基于GMM-HMM的语音识别系统,通过改造语音模型和语言模型,提高近音字和同音字的识别率。但仍然存在,比如轻声和四声的误判;连续语音中的三声容易出现插入错误等问题,预期解决这些问题能够进一步提高系统的识别率。
猜你喜欢
中学生英语·阅读与写作(2023年9期)2023-10-19 14:24:34
小学阅读指南·低年级版(2022年10期)2022-05-30 10:48:04
作文周刊·小学一年级版(2022年28期)2022-05-30 10:48:04
西藏科技(2022年3期)2022-04-22 09:17:20
小天使·一年级语数英综合(2020年9期)2020-12-16 02:57:03
北京教育·普教版(2020年9期)2020-10-09 11:15:09
校园英语·中旬(2019年11期)2019-11-26 10:01:06
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:16
作文周刊·小学一年级版(2019年28期)2019-09-07 03:42:03
小天使·一年级语数英综合(2019年6期)2019-06-27 06:36:15
