
智能语音查询系统助力企业经营决策
2018-12-27 00:45:20张邵洁
石油商技 2018年6期
张邵洁
中国石化润滑油有限公司
本文在阐述语言识别和自然语言理解(NLU)技术发展趋势和应用场景的基础上,提出了中国石化润滑油公司智能语音查询系统的解决方案,为企业各级经营管理人员、一线销售服务人员提供更加智能、及时、准确的决策辅助信息。通过调用讯飞开放平台的接口程序进行语音识别,配置开源的自然语言处理配置服务实现语句意图和属性的抽取,正确地在移动端识别了用户对销售指标的查询意图,并返回正确结果;在系统查询准确率测试中,正确率达90.7%。
目前,以智能天线、软件无线技术等为关键技术的第四代移动通讯系统已经全面建立,手机、电脑、电视、Pad、LED等移动设备也得到了大规模普及,人类已经进入了信息互通、信息共享的多屏时代。同时,企业运营管理的方式也积极向多元化发展,企业高层和基层员工需要借助信息技术的能力,突破时间和空间的限制,随时随地地查看企业运营状况。在此背景下,移动互联网以及相应的移动商业智能分析(BI)就成为了企业进行实时分析、决策和业务管控的有力工具。
然而,现有的移动终端设备键盘通常较小,导致文字输入不便,同时也无法处理步行、驾车等特定场景下的人机交互。由于这些交互方式的局限性,因此人们在与机器的信息交流中,需要一种更加方便、自然的方式,即使用人类的自然语言来代替传统的以键盘、鼠标等为工具的人机交互方式。
语音识别技术,也被称为自动语音识别(Automatic Speech Recognition 简称ASR),是以语音为研究对象,通过语音信号处理和模式识别让计算机自动识别人类口述语言。中文语音识别的原理是通过数据训练得到声学模型和语音模型,利用语音输入和信号预处理得到音频信号,并利用特征提取技术得到音频信号的技术特征,将特征输入到声学模型和语音模型,最后得到正确的识别文字。这其中,关键的技术是特征提取以及声学模型和语音模型的建立。在技术上实现特征提取和模型建立主要有2种方法:传统的隐马尔可夫模型(HMM)[1]和端到端的深度神经网络(DNN)[2]。目前,语音识别技术主要是通过DNN实现的,特定场景下最高可以达到97%的识别率。在国内,2011年科大讯飞首次将 DNN 技术运用到语音云平台,并提供给开发者使用,并在讯飞语音输入法和讯飞口讯等产品中得到应用。百度成立了 IDL(深度学习研究院),专门研究深度学习算法,目前已有多项深度学习技术在百度产品上线,在语音识别、OCR识别(光学字符识别)、人脸识别、图像搜索等应用上取得了突出效果。此外,国内其他公司如搜狗、云知声等纷纷开始在深度学习技术的基础上开放了语音识别功能[3]。
构建一个语音交互系统,首先要对用户的语音进行正确识别,即解决“让机器知道你在说什么”的问题,接下来,需要进一步让机器去理解这段语音并做出特定的反应,这就需要自然语言理解技术的应用。自然语言理解(Natural Language Understanding,简称NLU)是人工智能的分支学科,主要研究用计算机模拟人的语言交际过程,使计算机能理解和运用人类社会的自然语言如汉语、英语等,实现人机之间的自然语言通信,以代替人的部分脑力劳动,包括查询资料、解答问题、摘录文献、汇编资料以及一切有关自然语言信息的加工处理[4]。目前,许多国外顶级技术品牌已经开始为用户提供基于NLU技术的个性化语音搜索服务,包括Google的Google NOW、苹果的Siri、微软的Cortana、亚马逊的Alexa和三星的Bixby。同时,国内也有一些公司开始拥有自主语音语义相关技术并提供服务,如出门问问、云知声、思必驰、百度度秘和腾讯小鲸等产品,主要应用领域包括嵌入式系统、硬件产品、本地化生活服务、连续对话机器人、智能家居及车载市场等方面。此外,科大讯飞的“讯飞语音云”包括语音合成、语音识别和搜索、语音听写等技术,其主要业务是面向企业用户的服务,将自己的人工智能服务授权给其他企业应用。阿里巴巴、百度、腾讯、京东等互联网公司也纷纷推出了包含语音识别、自然语言理解等功能在内的人工智能开放服务。
润滑油业务作为中国石化直接面向市场和消费者的业务之一,市场竞争一直非常激烈。中国石化润滑油有限公司(以下简称润滑油公司)奉行“以客户为中心”的经营理念,积极探索互联网时代的润滑油业务专业化发展道路。为满足内部客户、外部客户的需求,努力提供更周到更细致的服务体验,润滑油公司积极尝试借助互联网、大数据、机器学习等先进的信息技术,实现人机交互、智能查询,为各级管理及销售人员快速提供数据决策支持,从而提升企业运营效率和客户满意度,拓展产品价值空间,大力提升市场竞争力。
2012年起,润滑油公司启动了企业数据仓库系统的配套建设。至今为止,润滑油公司数据仓库系统已经满足了机关层面的全口径统计以及其12个销售代表处、5家销售分公司和34家地市经营部的日常销售统计和客户统计的管理和分析需要。2014年7月1日,润滑油公司ERP(企业资源计划)大集中系统完成了实施[5],满足了有限公司的运作要求。BW(商务信息仓库)系统同步进行了配套建设,实现了业务统计的连续性。2015年后,BW建设主要内容重点放在了效益分析工作上,通过建立较为精准的产品、客户、销售经理利润贡献分析模型,实现了各项营销费用与产品及客户的合理匹配和分摊[6]。随着当前信息技术的发展,润滑油公司一线业务人员及中高层领导对销售、财务等数据的推送及时性和查询快捷性提出了更高的要求。
润滑油公司信息化应用水平在全国石化单位中处于领先地位,对于BI(商务智能)分析工具的使用率非常高,同时也在积极进行敏捷BI、移动BI等新技术的尝试和应用。2016年起,润滑油移动端数据分析系统开始建设,利用手机等移动设备展示常用的BW报表和重要指标数据,并开发了数据主动推送机制、自定义查询条件等功能,满足业务人员及中高层领导对销售、财务等数据的快速获取。据统计,“中国石化润滑油有限公司移动数据分析”使用查询次数突破50 000次/a[7]。
为了支持润滑油公司一线业务决策,真正做到“人人分析”和“实时分析”,本文将在润滑油公司多年积累的商务智能和移动数据分析建设经验的基础上,结合ASR与NLU技术,构建智能语音查询系统,以满足各层次用户快速准确地查询信息的需求。
系统功能
智能语音查询系统的主要设计思路是基于现有润滑油移动端数据分析平台,添加语音查询的功能。现有的报表往往逻辑简单、信息单一,业务人员需要通过交互式的反复查询才能最终获取想要的所有结果。而通过语音查询,可以让业务人员便捷的按照不同维度组合展现数据,并进行交互式查询。
根据需求分析,确定了智能语音查询系统的具体查询功能,部分查询内容见表1。
其主要查询场景是:选择一种或多种维度下指标的组合,将查询语音输入智能查询系统,返回相应的产品销售量,如“查询重庆高汽包装油的销量”、“我想知道工业油在茂名直销的买了多少?”等。其中,由于销售代表处和单位2个维度有重合的指标,如“天津”等,系统默认的查询维度为“单位”,但如果在语音中指出“销售代表处”,如询问“销售代表处天津的船用油销量是多少”,则在系统中查询该维度下的销售量并返回。
技术架构
总体架构
智能语音查询系统主要包括“语音识别”和“自然语言处理”两大主要功能。“语音识别”旨在让计算机能够“听懂”人类的语音,将语音中包含的文字信息“提取”出来,“自然语言处理”旨在让计算机能够“理解”人类的文字,将包含在自然语言中意图、语义等信息“提取”出来。两者相辅相成,满足各层次用户数据挖掘需求。
系统通过自开发ASR接口集成外部ASR系统实现语音识别,同时,通过自开发NLU模块实现自然语言处理。应用程序可通过接口服务发送语音或文本信息并获取语义解析后的结果;此外,系统及相应的模型还将在收集数据样本信息的过程中不断自我更新,实现意图和实体识别的迭代优化以及查询准确性的逐步提升。其总体架构见图1。
语言输入、语音的正确识别、语意和意图的抽取、查询SQL语句的拼接以及数据展示是智能语音查询系统的主要处理内容,如图2所示。
语言输入开发
语音输入服务主要基于中石化移动应用平台实现,APP框架界面基于React-Native开发。主要技术要点及实现流程如下:界面根据移动终端(IOS、Android)类型通过中石化移动应用统一封装的JS桥,调用底层录音组件。启动录音组件进行语音录入,待语音录入结束后,将语音转为Base64位格式进行本地存储,再调用Java语音识别服务平台接口将语音文件转换为文字。具体语言识别接口开发过程见下一小节。
语音识别开发
语音识别接口开发
经过一段时间的语音识别开放平台技术选型比较,我们选择了业内一致推荐和广泛使用的讯飞开放平台作为语音识别的接口选择。讯飞开放拥有领先的语音识别技术,核心技术达到国际领先水平,语音识别准确率已经超过98%,在业界遥遥领先,同时,其系统的语音输入速度、识别结果响应时间、系统运行效率也能够满足目前的需求。

表1 智能语音系统查询内容
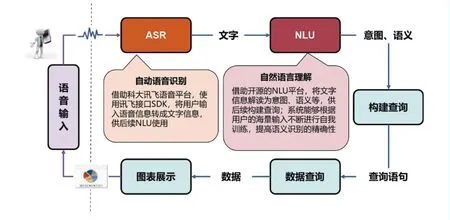
图1 智能语音查询系统功能架构
利用JAVA通过http 请求/响应模式,调用讯飞开放平台提供的免费开源SDK,实现了语音转换文字的功能。其主要的开发过程包括解压下载JAR包,复制assets文件夹到项目中、在Manifests文件中添加权限、初始化SDK、封装语音识别实体等内容。最后调用initSpeech方法,在TextView中得到正确的识别结果。
语音纠错程序开发
在完成接口开发后,收集相关的语音查询样本,批量运行语音识别程序对样本进行文字识别。基于测试结果发现,行业专有词语音识别率只有34.79%,直接造成后续NLU无法正确抓取关键词,并输出正确的语义。经过分析,这种情况发生的原因是某些专有名词不在讯飞平台的语料库内所导致。如“金工液”被识别为“金工业”,“工业油”被识别为“工业游”等情况,除此之外,类似“北京”、“上海”等专有地理名词均能被正确识别。
针对这种情况,开发了语音纠错程序,首先将识别后的文本转换为汉语拼音形式,同时建立易错读音和文字指标的对照表,再利用字符串的相似性判断,将相近似的拼音结果转换为查询结果。如“查询武汉的金工液”在讯飞识别端会识别为“查询武汉的金工业”,由于“金工液”和“金工业”的拼音为“jingongye”,因此通过纠错程序可将“查询武汉的金工业”转换为正确的文本,即“查询武汉的金工液”。经过100个语音样本的纠错测试,通过纠错程序可将语音识别正确率由35%提升到85%。语音识别纠错程序如图3所示。
NLU服务搭建
面向数据库的语言搜索系统,通常需要精确地理解文本语义并将之转化为计算机可以理解处理的形式化表示,进而转化为精确的SQL查询语言。目前NLU方法主要分为两类,一类是基于目前快速发展的深度学习技术,如embedding嵌入式学习算法[8],RNN、LSTM等递归型深度学习神经网络[9],通过学习得到问句和语料库、知识库之间的映射关系。另一类是基于符号逻辑的NLU方法,利于符号化文法对自然语言问句进行分析并转化为结构化。这种分析方法依赖于问句的语句规范性,当面对一些口语化、不规范的短文本时,很难得到精确的分析结果[10]。
意图分类与属性抽取
NLU的处理过程是将一段文字输入,转换为一种结构化的语义表示,在其实施方法上会分成2个步骤:用户意图的判定和属性的结构化抽取。一个意图和属性抽取实例见图4。
在图4中,针对“我要查询6月份重庆高汽包装油的销量”这一段短文本信息。第一个步骤是要理解用户的意图,即销量查询;第二个步骤为属性抽取,即把地区、品种、时间等关键的信息处理出来,从而得到一个比较完整的结构化语义表示。
在处理意图理解时,通常的方法是将其抽象为一个分类问题,并利用CNN神经网络、SVM分类器等典型的机器学习方法进行分类。除此之外,处理意图之前还需要对文本进行分词以及对词进行向量化表示,目前一般采取开源的jieba、SnowNLP、THULAC、NLPIR 等工具进行中文分词[11],并采用word embedding或基于知识的语义表示法进行向量化处理[12]。
在处理属性抽取时,业界一般会将其转换为序列标注问题,如阿里巴巴的iDST NLU团队采用了双向LSTM加CRF解码器的方式[13]。为配合较多的匹配结果,很多机构采取了大数据分析的方法,收集诸如 probase、Web文 本、Bing查询日志和DBpedia多种数据资源的300多TB数据以及上亿数量级的google查询日志等数据,从数据中挖掘大量的属性[14]。
服务配置
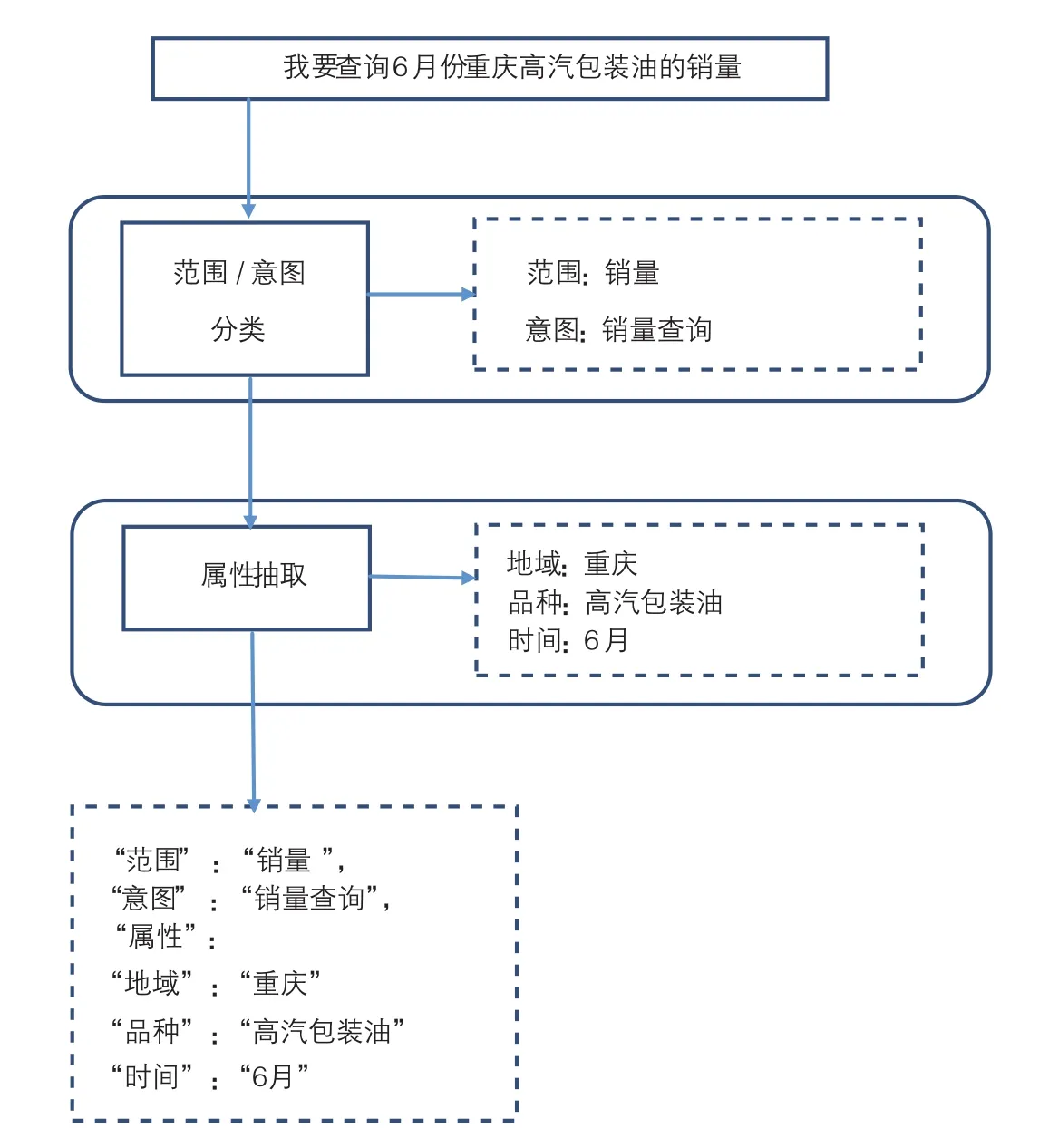
图4 意图和属性抽取实例
在润滑油公司智能语音系统的搭建中,NLU功能是最核心也是最重要的部分。经过技术选型和方案比较,选取了开源的RASA NLU开发框架作为系统的NLU功能模块核心。RASA NLU是Github上一个开发团队做的一个开源项目,优势就是只提供框架流程,可自定义自己的NLU功能,可本地化部署,和google micro的闭源框架相比,不需要依赖互联网。BMW、UBS等企业都在用RASA框架开发自己的产品。NLU服务搭建流程见图5。
数据查询与前端展示
数据查询的主要实现原理是:将NLU服务参数根据业务需求进行一一映射配置,即对象关系映射,把配置参数设置为数据源data source的模型结构配置,实现面向对象编程JAVA里不同类型系统的数据之间的转换。
在本系统中,首先配置业务需求与参数定义;接着在JAVA端调用NLU提供的restful API接口服务,得到用户意图以及相应的属性维度;再利用相应的对照映射关系表组成查询对象和查询条件;最后拼接生成SQL查询语句,得到查询结果。
前端界面取得Java返回的固定格式的查询结果数据后,针对界面交互以及实际业务逻辑进行数据的加工处理,结合用户体验习惯渲染到浏览器界面。在润滑油公司智能语音查询系统中查询“去年上海金工液销量”的结果显示界面见图6。
由图6可以看出,系统正确地显示了查询结果,并且显示了查询维度和查询意图,以及ASR、NLU、数据库查询各自花费的时间。
应用效果测试
为了深入了解智能语音查询系统的应用效果,我们选择了如下的测试场景对查询正确率进行测试:
测试人员:3人(2男,1女);
测试案例:每人50个测试语句,其中40个销量意图,10个其他意图。
智能语音查询系统查询正确率测试结果见表2。
由表2可见,平均查询正确率达到90.7%。通过分析发现,由于部分查询字段为石化专有名词,讯飞语言识别系统无法给出正确的识别结果,应用纠错程序也无法全部改正此类识别错误。此外,测试员的普通话发音清晰度、语速及其周边噪声也会对识别的正确程度产生影响。此外,测试过程中还发现,由于训练样本充足,NLU模型通过训练,得到了良好的性能。因此,本次测试中能够正确识别的语音,均能够通过NLU系统正确地解析意图和抽取属性,达到理想的查询结果。
系统未来扩展
所搭建的润滑油公司智能语音查询系统主要实现了如下功能:
◇系统化:搭建了语音查询智能系统雏形,实现了语音、语义结果的保存;
◇模块化:按功能模块化,以微服务的方式对外提供能力输出;
◇接口化:语音识别、语义识别以及系统的能力输出都包装成标准接口,方便应用调用。
在未来的工作中,将着重实现多意图、多属性下的智能查询,实现跨主题的语音查询,并能够满足业务用户的交互式查询需求。在硬件配置方面,目前的系统搭建在测试环境下,性能较低,正式环境硬件架构将主要采用Nginx+keepalive的HA负载均衡方案,在2台Server上部署语言识别、数据库查询和前端渲染服务,同时将NLU服务部署在带有GPU的服务器上,可提升响应速度,满足多用户访问、模型快速迭代的需求。

表2 智能语音查询系统查询正确率测试结果
结束语
本文所搭建的智能语音查询系统实现了在现有润滑油移动应用的基础上添加语音识别的功能,同时对系统的各个关键环节做了深度测试和验证。在未来的工作中,将以标准接口的方式提供语音查询服务,推广至集团内其他企业应用。
猜你喜欢
法律方法(2022年2期)2022-10-20 06:42:20
福建基础教育研究(2022年4期)2022-05-16 08:48:40
内燃机工程(2021年6期)2021-12-10 08:06:50
石油商技(2021年1期)2021-03-29 02:36:08
法律方法(2021年3期)2021-03-16 05:56:58
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
风能(2016年12期)2016-02-25 08:46:00
