
从高频词等级相关角度探析《红楼梦》作者
2018-12-20 06:18:42马创新陈小荷
中文信息学报 2018年11期
马创新,陈小荷
(1. 江苏师范大学 语言科学与艺术学院,江苏 徐州 221009;2. 南京师范大学 文学院,江苏 南京 210097)
0 引言
古今中外存在着很多作者存疑的文献,具体情况包括: 有些文献本来就没有作者署名;有些文献署的是作者笔名,而世人无法确定该笔名在现实世界中的所指人物对象;有些文献有具体可查的署名作者,但世人对该文献作者的真实性产生怀疑或有争议。比如,俄裔作家索尔仁尼对于《静静的顿河》是否为肖洛霍夫所写表示公开质疑,他认为《静静的顿河》这样的鸿篇巨著,不是当时只有20多岁的年轻人——肖洛霍夫所能写出的,还有人怀疑肖洛霍夫抄袭了已故作家克鲁乌可夫的作品[1]。狄更斯和马克·吐温对于《罗密欧和朱丽叶》是否为莎士比亚所写也表示过怀疑,因为他们觉得莎士比亚的出身为英国平民,而《罗密欧和朱丽叶》描写的是意大利上流社会的生活[2]。中国古典小说《红楼梦》的作者也有悬疑,有些学者认为《红楼梦》全书120回为同一人所作,而有些学者认为前80回与后40回并非同一人所作[3]。
对于如何确定存疑文献的真实作者,我们认为可以从高频词的等级相关度方面来分析这个问题。相对于中低频词型来说,文献中出现的高频词中,连词、介词和副词占有更大的比例。如果把写文章比作盖房子的话,名词、动词、形容词等实词就相当于砖瓦等建筑材料,连词、介词和副词等虚词就相当于水泥、黄沙等黏合材料。同一作者在写作两部题材不同的作品时,两部作品中所使用的名词重合度会比较低,但所用的连词、介词和副词等虚词重合度会较高[4-5]。我们所提出的方法是基于这样的考虑: 两部文献语言风格的差异不仅体现在词型的重合度上,还更细微地体现在高频词的等级相关度上。如果两部作品是同一作者所写,那么它们的相关系数就会比较高;如果两部作品是不同作者所写,那么它们的相关系数就会比较低。
1 相关研究
1984年,挪威奥斯陆大学的一个统计学家领导一个小组统计三组文献中的词语特征,三组文献分别是肖洛霍夫的确认作品、存疑作品《静静的顿河》、克鲁乌可夫的作品。他们先是统计不同词汇量与总词汇量的比值,三组分别是65.5%、64.6%、58.9%;再选择最常见20个俄语单词,统计它们出现的频率,分别是22.8%、23.3%、26.2%;然后统计出现多于一次的词语所占百分比,分别是80.9%、81.9%、76.9%。上述三种统计结果都显示,肖洛霍夫比克鲁乌可夫更有可能是《静静的顿河》的真正作者[6]。
在《红楼梦》作者信息的研究方面,最早使用统计方法展开研究的是瑞典汉学家高本汉。高本汉(1952年)选取了32种语法、词汇现象,统计它们在《红楼梦》等五部作品中的出现频率。高本汉根据统计结果,认为《红楼梦》全书120回为同一人所作[7]。1980年,在美国威斯康星大学举行的《红楼梦》研讨会上,陈炳藻发表论文“从词汇上的统计论《红楼梦》的作者问题”,他把《红楼梦》分为三组,分别是1~40回、41~80回、81~120回,另外还配上了《儿女英雄传》。他按一定比例从各组中抽选特定词类,再统计各组词语之间的相关系数,计算出《红楼梦》前80回和后40回的词汇相关度为78.57%,而《红楼梦》与《儿女英雄传》的词汇相关度仅为32.14%。由此认为《红楼梦》前80回和后40回为一人所作[8]。
刘钧杰在《红楼梦》前80回中选取40回,和后40回进行比较,对六项语言材料在前部和后部的出现进行统计比较,结论是前、后的语言风格存在明显差异[9]。陈大康选取27个词、46个字,考察它们在《红楼梦》前后出版的情况,并且分析89 758个句子的句长分布及平均句长,认为《红楼梦》前80回和后40回并非一人所作[10]。
李贤平从《红楼梦》中抽取了47个虚字,统计其在各回中的使用频率,用统计学方法探索各回写作风格的接近程度,并用聚类方法对120回进行分析,认为《红楼梦》各个部分是由不同的作者在不同的时期撰写的[11]。
徐秉铮等从词的相关性和上下文的相关性、字符数的统计、字符串的统计等三方面判断《红楼梦》前80回与后40回的语言风格有明显的不同[12]。张运良等将《红楼梦》120回平均分成1~40回、41~80回、81~120回等三个集合,然后以句类为特征向量,采用K近邻算法作为分类算法构建分类器,实验发现集合1和集合2句类风格相近,集合3句类风格和前两个集合差距较大[13]。施建军使用支持向量机技术,以44个文言虚字频率为特征向量,对《红楼梦》120回进行分类研究,结果发现,前80回与后40回在写作风格上存在明显差别[14]。
2 基于高频词等级相关度的方法
2.1 理论依据
布拉德福提出了频次—等级排序法,这种方法在社会科学领域中被广泛应用[15],例如,把某部文献中的词型按照其出现频次递减排列,就会呈现出布拉德福分布。布拉德福分布的特点显示: 我们考察的具体对象的大多数集中于少数主体来源。例如,人们写文章时总是倾向于选择自己常用的词语。Zipf发现了词型的出现频率与等级序号之间的关系,任何一篇文章中词型的频次和频次等级的乘积总为一个常数[16]。
人们在表达一个观点或者描述一个事物时,会有多个同类词语可供选择,有的词语会被经常用到,而有的词语不常被使用。这种选择上的频度不均现象致使被选词语的特征信息变得越来越突出,这又会反过来作为再次被选的影响因素。如果把个体在表达一个观点或者描述一个事物时选用某词语看作这个词语的一次成功,那么这种成功的累积必然会产生新的成功,这就使得个体在语言运用方面会形成思维定势。文献之间的语言风格差异不仅体现在使用的高频词上,还更加细微地体现在高频词的使用频率等级上[17]。
2.2 计算方法
为了能够给鉴定作者存疑的文献提供更多的参考信息,我们提出了一种“基于高频词等级相关度的方法”,测量各份语料之间在词型等级方面的相关度,推断“存疑文献”的作者信息。这种算法分为三个步骤:
(1) 首先,对于各份语料,词型均按照出现频次(即词型的词例数)递减顺序排列;
(2) 然后,对于已经排序的词型按照“频序法”确定等级,把出现频次最高的词型等级定为1,次高的词型等级定为2,……依次类推,频次相等的词型为一个等级,以其在语料中词频序值为等级[18]。
(3) 接下来,计算各份语料之间高频词等级的相关度。相关度的计算方法采用“斯皮尔曼等级相关”,如式(1)所示。
(1)
其中,Di表示每一对数据相应的两个等级之差,n表示样本数。
斯皮尔曼等级相关适用于研究数据是具有等级性质的成对数据,并且变量之间呈线性关系[19-20]。但是,两份语料中出现的词型数据并不是成对的,所以采用这种计算方法所得到的相关系数是一个近似值。我们用ARs来表示“以语料A中特定数量词型为样本”与语料B中全部词型比较所得到的相关系数,对于在语料A中出现而语料B中没有出现的词型,不放在计算范围内。同样,以BRs来表示“以语料B中特定数量词型为样本”与语料A中全部词型比较所得到的相关系数,对于在语料B中出现而语料A中没有出现的词型,也不在计算范围内。通常选取在语料中出现频次排在前100、200、300位的高频词作为样本。语料A与B的相关度用ABRs来表示,ABRs等于ARs与BRs的均值,即: ABRs=(ARs+BRs)/2。也就是说,语料A与B的相关度就等于: “以语料A中特定数量词型为样本”与语料B的全部词型比较所得到的相关系数,加上“以语料B中特定数量词型为样本”与语料A的全部词型比较所得到的相关系数,两个系数之和再除以2所得到的商。
2.3 实验与分析
为了验证此方法的效果,我们选取《孟子》《荀子》这两部先秦文献作为实验语料,对这两部文献做人工分词处理。这两部文献都是儒家经典,在主题内容上有着很大的相关性。学术界对于这两部文献的作者,也无异议。把《孟子》语料均分为两部分,两部分语料用“《孟子》一”和“《孟子》二”表示;把《荀子》语料均分为四部分,四部分语料用“《荀子》一”、“《荀子》二”、“《荀子》三”和“《荀子》四”表示。采用“频序法”确定词型等级,选取频次排在前100位的词型作为样本,分别测量这七份语料两两之间的相关度,形成如表1所示的相似度矩阵。
将表1、表2和表3中的数据分别划分为三个区,第一区位于表格左上角,是《孟子》两份语料之间的相关度数据,在表中都以黑色字体显示;第二区位于表格右下角,是《荀子》四份语料相互之间的相关度数据,在表中都以黑色斜体字显示;第三区位于右上角和左下角,是《孟子》两份语料与《荀子》四份语料之间的相关度数据,都以常规字体显示。

表1 使用“基于高频词等级相关度的方法”得到的相关度矩阵(%)
为了评估“基于高频词等级相关度方法”的有效性,我们使用另外两种常用的分析文献相似度的方法与之相比较[21]。一种是“基于词型共现率的方法”。其计算方法如式(2)所示。
语料A与语料B的相关度=(A与B的共现词型数)/(A与B的词型数)
(2)
式(2)中,“A与B的词型数”并不等于“A的词型数+B的词型数”,因为语料A与语料B中有一些共现词型,这些共现词型既出现在语料A中,又出现在语料B中,不能重复计算,所以“A与B的词型数”等于“A的词型数+B的词型数-A与B的共现词型数”。
另一种是“基于词例共现率的方法”。其计算方法如式(3)所示。
语料A与语料B的相关度=(A与B的共现词型的词例数) /(A与B的词例数)
(3)
式(3)中,“A与B的词例数”等于“A的词例数+B的词例数”。
表2是使用“基于词型共现率的方法”所得到的七份语料相互之间的相关度矩阵,表3是使用“基于词例共现率的方法”所得到的相关度矩阵。
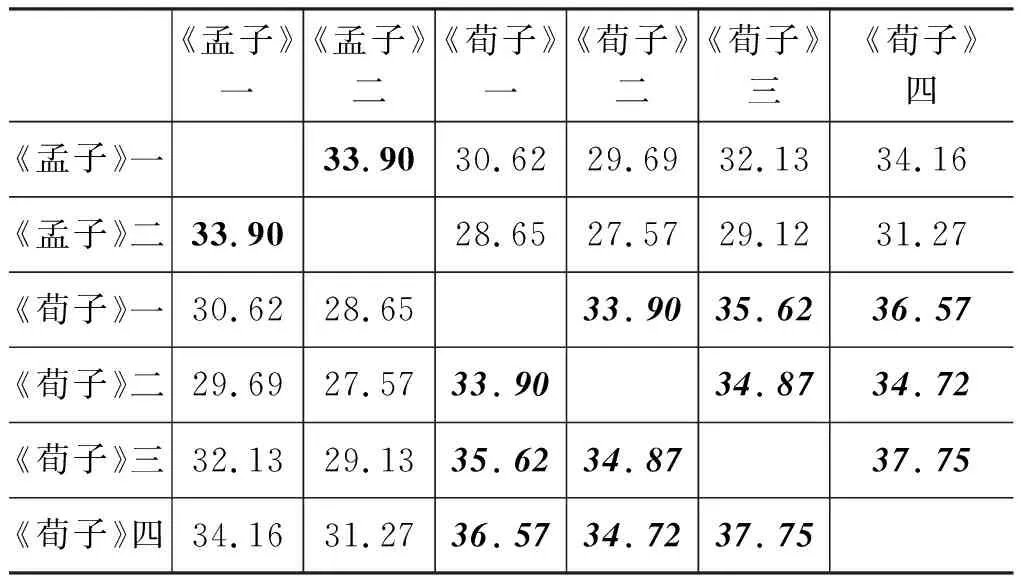
表2 使用“基于词型共现率的方法”得到的相关度矩阵(%)

表3 使用“基于词例共现率的方法”得到的相关度矩阵(%)
为了能够直观地观察到使用这三种方法所得到的数据在“量”上的特征,我们使用Excel 2016把表1、表2、表3中的数据转化为柱形图,如图1所示。观察图1能够发现:
(1) 使用“基于高频词等级相关度的方法”所得到的数据三个区之间的区别明显,左上角第一区数据的柱形高度显著高于第三区,右下角第二区的柱形高度也显著高于第三区;
(2) 使用“基于词型共现率的方法”和“基于词例共现率的方法”所得到数据三个区之间也有区别,但不如使用“基于高频词等级相关度的方法”所得到数据区别度大,左上角第一区数据的柱形高度显著高于第三区,右下角第二区的柱形高度与第三区右上角柱形高度相关差不大,区分度较小。

图1 三种方法的数据柱形图
为了分析使用三种方法分别得到的数据的集中与离散情况,我们计算了每种方法所得到数据的各个区的标准差,把计算结果汇总起来,形成表4。通过分析表4,我们发现: (1)使用“基于高频词等级相关度的方法”所得到的数据三个区的标准差分别为0、3.97%、3.59%,均略大于使用另外两种方法所得到数据标准差,这说明使用“基于高频词等级相关度的方法”所得到的数据波动性略大; (2)使用“基于词型共现率的方法”与“基于词例共现率的方法”所得到的标准差数值都很小,这两种方法所得到的标准差数值差异也很小。
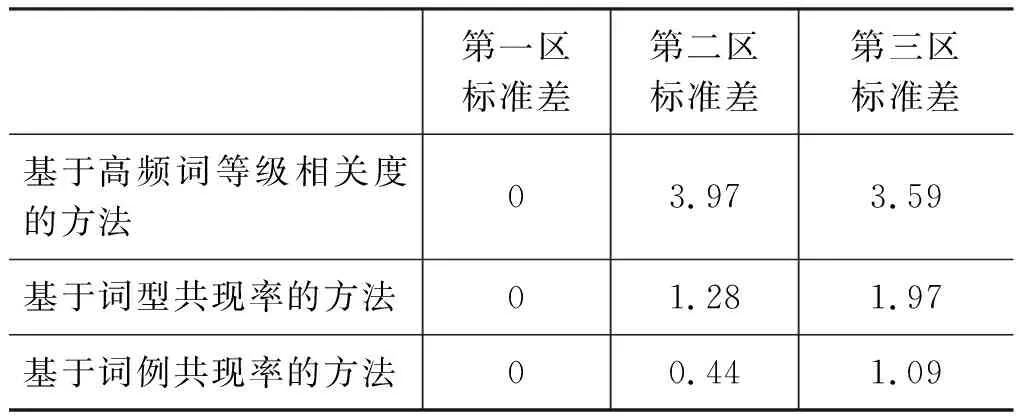
表4 三种方法的标准差对比(%)
接下来,计算每种方法所得到数据的各个区的均值,并且计算了各区之间的均值之差,把计算结果汇总起来,形成表5。通过分析表5,我们发现: (1)使用“基于高频词等级相关度的方法”所得到的数据三个区的均值分别为90.84%、83.77%、77.15%,介于使用另外两种方法所得到的均值之间; (2)使用“基于词型共现率的方法”和“基于词例共现率的方法”所得到的数据三个区之间的均值差异比较小; (3)使用“基于高频词等级相关度的方法”所得到的数据三个区之间的均值差异比较大,第一、三区均值之差为13.69%,第二、三区均值之差为6.62%,显著高于使用另外两种方法所得到的相应数据。

表5 三种方法的均值对比(%)
分析上述数据,能够得出以下结论: (1)“基于高频词等级相关度的方法”所生成的数据,在“第一、三区均值之差”和“第二、三区均值之差”方面均显著高于另两种方法所生成的数据,证明这种方法区分语言风格的能力最强。(2)“基于词型共现率的方法”和“基于词例共现率的方法”所产生的数据波动较小,而“基于高频词等级相关度的方法”所产生的数据波动略大,离散度略高。
3 探析《红楼梦》的作者信息
以《红楼梦》作为实验语料,使用哈工大社会计算与信息检索研究中心研发的“语言技术平台”对语料作分词处理,把《红楼梦》的120回分为12份语料,每份语料包含10回,这样第一份语料就包含第1至第10回,第二份语料包含第11回至第20回,……,依次类推,简写为: 一(第1~10回)、二(第11~20回)、三(第21~30回)、四(第31~40回)、五(第41~50回)、六(第51~60回)、七(第61~70回)、八(第71~80回)、九(第81~90回)、十(第91~100回)、十一(第101~110回)、十二(第111~120回)[22]。
使用“基于高频词等级相关度的方法”计算这12份语料相互之间的相关度,均取出现频次排在前100位的词型作为样本语料。把相关数据汇总起来,形成表6所示的相关度矩阵。为了便于发现前80回与后40回之间的区别,把表6中的数据也划分为三个区,第一区位于表格左上角,是前八份语料相互之间的相关度数据,在表中都以黑色字体显示;第二区位于表格右下角,是后四份语料相互之间的相关度数据,在表中都以黑色斜体字显示;第三区位于右上角和左下角,是前8份语料与后4份语料两部分语料之间的相关度数据,都以常规字体显示。

表6 使用“基于高频词等级相关度的方法”得到的相关度矩阵(%)
计算出使用这种方法所得到数据的各个区均值,并且计算出各区之间的均值之差,把结果汇总起来,形成表7。通过分析表7,我们发现: 使用“基于高频词等级相关度的方法”所得到的数据三个区的均值分别为68.51%、73.69%、50.74%,三个区之间的均值差异比较大,第一、三区均值之差为17.77%,第二、三区均值之差为22.95%,差异明显。

表7 各区均值及区间均值之差(%)
分析上述数据,能够得到以下结论: (1)《红楼梦》的前8份语料相互之间的相关度要高,后四份语料相互之间的相关度也高,即语言风格相似度大; (2)前8份语料与后4份语料之间的相关度要低,即语言风格差异度大。
4 结语
我们把《红楼梦》的120回均分为12份语料,每10回作为一份语料,然后使用“基于高频词等级相关度的方法”,计算这12份语料两两之间的相关度,得到结论: “《红楼梦》的前8份语料两两之间相关度高,后4份语料两两之间相关度也高,而前8份语料与后4份语料这两部分语料之间相关度低。”也就是说,前80回之间语言风格相似度高,后40回之间的语言风格相似度也高,而前80回与后40回的语言风格差异很大。由此推断《红楼梦》前80回应是同一人所写,后40回应是另一人所写。
猜你喜欢
小康(2022年7期)2022-03-10 11:15:54
小康(2022年7期)2022-03-10 11:15:54
小康(2021年7期)2021-03-15 05:29:03
小康(2021年7期)2021-03-15 05:29:03
海外华文教育(2016年1期)2017-01-20 08:21:58
高中生学习·高三版(2016年1期)2016-05-30 05:45:06
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:20
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01 02:54:01
数学年刊A辑(中文版)(2014年4期)2014-10-30 01:50:38
