
一种基于数据重构和富特征的神经网络机器阅读理解模型
2018-12-20 06:18:28尹伊淳
中文信息学报 2018年11期
尹伊淳,张 铭
(北京大学 信息科学技术学院,北京 100871)
0 引言
“2018机器阅读理解技术竞赛”旨在让机器根据问题和搜索引擎返回的相应证据文档,抽取或生成合理的答案文本,推动搜索引擎场景下智能问答技术的发展。具体而言,竞赛要求构建机器阅读理解系统,自动对给定问题q及搜索引擎返回来的候选文档集合D={d1,d2,…,dn},其中n=5,输出对应的答案文本a。评测基于人工标注问题答案,采用ROUGE-L和BLEU4作为评价指标,其中ROUGE-L是主阅读评价指标。
本文将机器理解问题建模成文本抽取问题,认为答案文本a来自候选文档中某个连续的文本片段,基于问题和数据的特点构造神经网络模型。为了充分利用人工标注答案信息,本文首先对数据进行重构,使同一个问题的多个候选文档具有各自不同的答案文本;接着提出了基于语义富特征的神经交互网络,得到问题感知的文档表征;最后采用基于不同词向量的模型集成方法,进一步提升模型效果。在测试集上,本文提出的模型得到ROUGE-L60.99和 BLUE-4 55.93的结果,在所有105支参赛队伍中排名第2位。
1 数据重构
给定的数据集基于真实标注答案集(一个问题往往含有多个答案),在文档中寻找相对应的匹配文本段,进行伪答案的标注。这种简单的标注方法在答案覆盖度上存在以下不足: (1)以段落为单位标注和预测,忽略了候选文档其他段落的信息; (2)所有5篇候选文档中只把匹配度最高的一条真实标注答案作为基准信息,忽略了其他真实标注答案的信息。
为了缓解原始标注对真实答案信息利用不足的问题,本文对给定数据集进行了重构。具体来说,本文从文档级出发,基于每个真实标注答案对文档进行匹配。每个文档选择匹配分数最大的作为伪答案片段。这样真实的标注答案信息会出现在多个候选文档中,其分别匹配不同的真实答案。本文基于F1的词匹配指标,对提供的训练集进行重构,同时过滤掉匹配分数小于0.65的答案片段。为了提高数据重构的速度,使用多进程并行处理方式。
2 模型

本节介绍富特征的神经交互网络(图1),整个网络分为: (1)词富语义表征层,使用特征工程建模词向量表征; (2)序列语义编码层,使用句子序列信息对词进行语义编码; (3)问题与文档交互层,旨在得到有效的问题感知文档表征; (4)答案文本预测模块,在所有候选文档上抽取答案文本a; (5)模型集成模块。
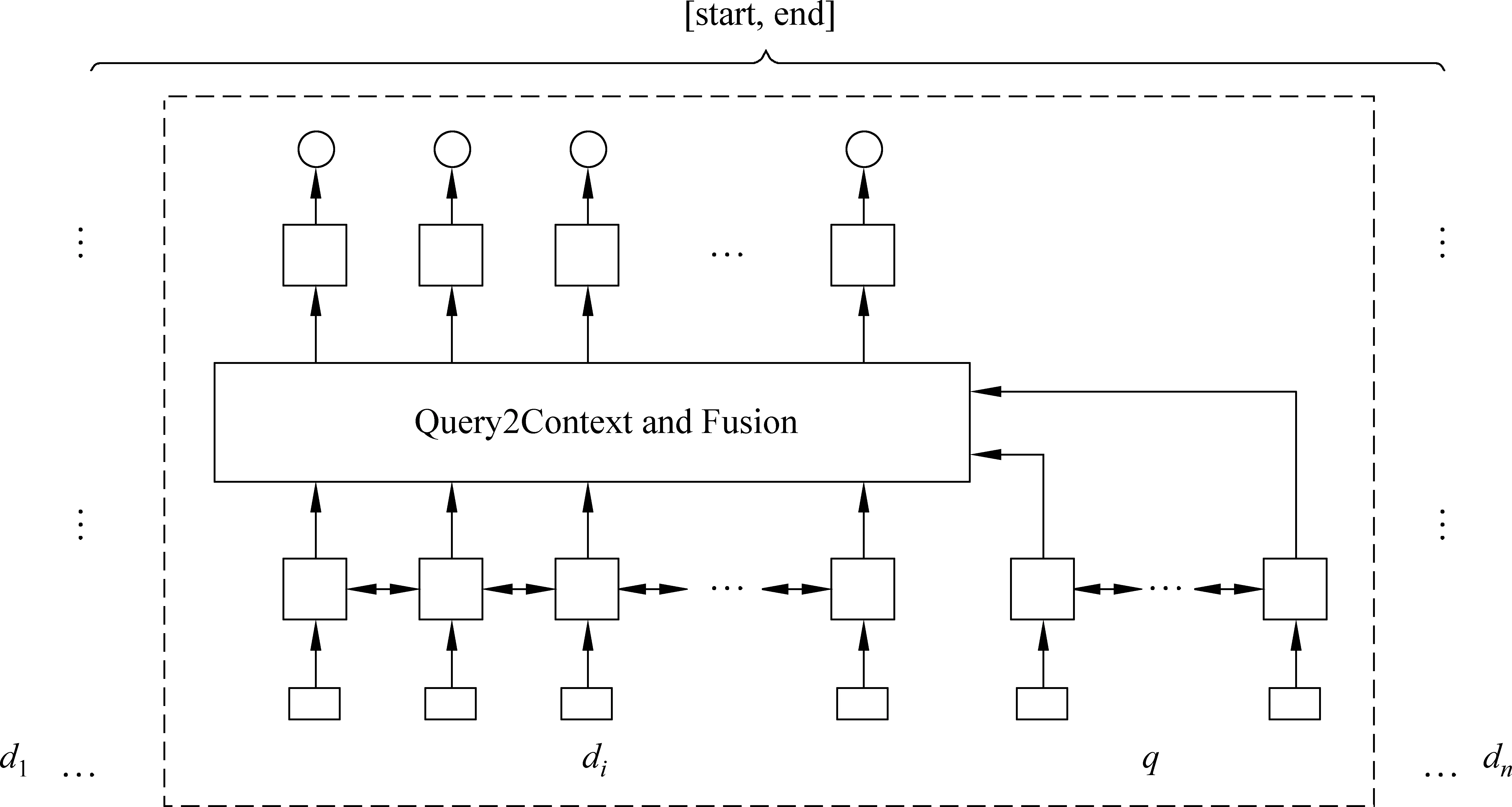
图1 模型框架图
2.1 词富语义表征
为了得到丰富的词语义表征,本文使用了以下8种特征。
词向量特征: 本文使用了从大规模122GB中文语料中使用Word2Vec预训练得到的64维词向量[注]https://pan.baidu.com/s/1o7MWrnc。
文档排序特征: 排名越靠前的文档越可能出现答案文本,因此本文使用了Mrank∈5×5待学习排序矩阵,每个位置上都对应一个5维的向量。
问题类别特征: 考虑到问题类别对答案文本抽取影响较大,这里使用了Mques∈6×5的待学习排序矩阵,分别对应“SEARCH_DESCRIPTION”“SEARCH_ENTITY”“SEARCH_YES_NO”“ZHIDAO_DESCRIPTION”“ZHIDAO_ENTITY”和“ZHIDAO_YES_NO”6种问题类型,每种问题类型使用5维向量表示。
词性特征: 本文同时使用了词性特征,统计全部语料,选取了30个不同词性作为特征,使用Mpos∈30×5进行表征。
精确匹配特征: 指示当前词是否同时存在于文档和问题中。
上下文匹配特征: 指示在此前词的上下文中窗口词精确匹配的比例,例如考虑当前词上下文中的4个词,如果其中3个是精确匹配的,那么匹配比例即为0.75。
是否由数字组成: 指示当前词是否由数字组成。
是否由字母组成: 指示此前词是否由字母组成。
本文对问题和文档中的词采用了不同的特征表征形式,其中问题词使用了词向量特征、问题类型特征和词性特征;文档词使用了词向量特征、词性特征、排序特征、精确匹配、上下文匹配和是否为数字、字母特征。
2.2 序列语义编码
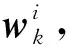
2.3 问题感知的文档表征
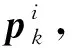
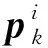
2.4 答案文本预测
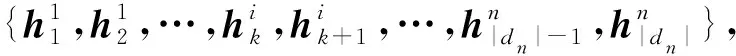
其中,v、Wp、Wq是待学习的参数;qs是问题的表征,本文使用注意力机制得到式(6)、式(7)。
其中,u是待学习参数。为了训练模型,本文最小化金标准start和end位置的negativelogprobabilities。
在得到start和end的概率之后,本文基于两个概率的积,在全局文本上搜索答案文本,选择积最大者作为最终答案文本,其中设定文本的最大长度为max_a_len。
2.5 模型集成
本文假设不同语料学习得到embedding具有不同的语义知识,采用基于embedding的方法[1]进行模型集成。具体而言,本文使用了: (1)从大规模122GB中文语料中使用Word2Vec[2]预训练得到的64维词向量E1; (2)将训练数据集作为语料采用fasttext[3]预学习得到的128维词向量E2。模型集成采用两个64维向量学习得到的模型和两个128维词向量学习得到的模型,最终的起止位置的概率值采用4个模型结果的平均值。
3 实验
3.1 实验设置
实验采用了比赛提供的数据集(此数据集是之前DuReader[4]公开数据集的超集),总共30万个问题,其中训练数据27万;开发数据1万;测试数据2万。直接使用数据集提供分词结果。
本文的模型构建采用Tensorflow1.4.1、Python2.7.12,整体调优在开发集上进行,参数值设置见表1;模型采用Adam优化模型参数。实验运行的硬件条件为: TITAN12GB显存;内存为132GB。
得到结果文本之后,去掉了HTML符号标记的冗余部分,作为最终的预测文本。

表1 模型参数设置
3.2 实验结果
基于不同词向量的模型结果如表2所示,可以发现我们的模型显著高于baseline,模型集成对效果也有一定的提升。最终,我们的模型在测试集上的排名第2。
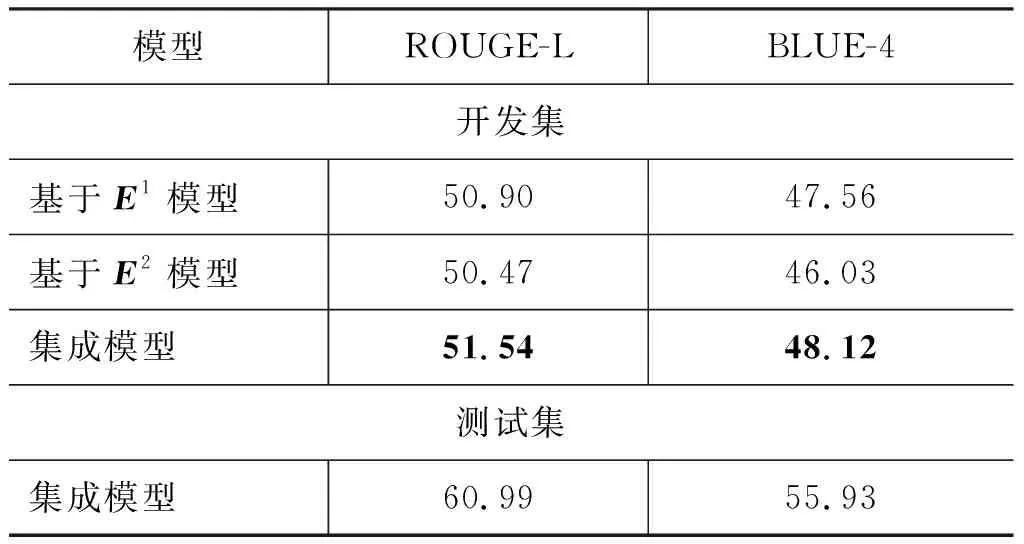
表2 模型结果
为了评价富特征和数据重构的有效性,我们在开发集上做了相应的对比实验: (1)有无富特征模块的效果对比; (2)是否进行数据重构处理的效果对比; (3)富特征模块和数据重构两者一起对模型效果的影响。整个实验结果如表3所示。从结果中可知,富特征模块和数据重构对整个模型贡献很大,分别在ROUGE-L指标上有5%和7%的提升,其中数据重构比富特征对结果提升更大;同时加入两个模块,模型得到了接近14%的提升,这说明了本文提出方法的有效性。
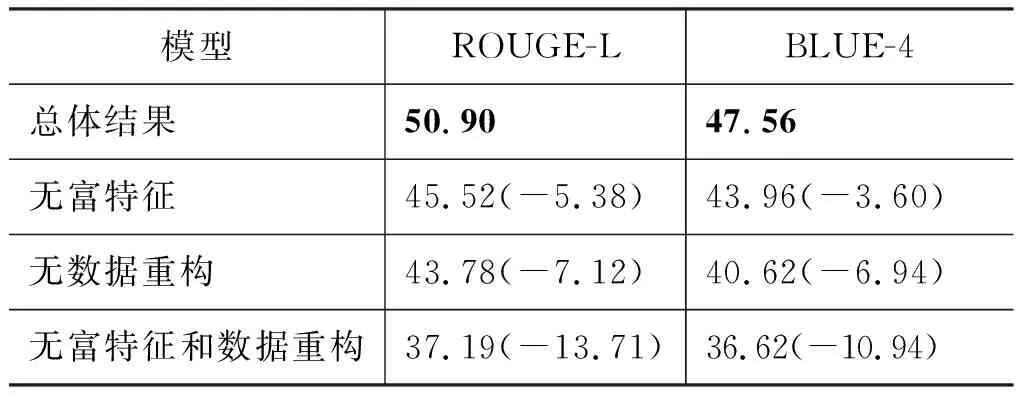
表3 模块对比
注: 实验结果基于开发集,所有模型使用E1;无富特征表示只是用词向量。
3.3 错例分析
从模型在开发集上的表现,可以总结出以下几种错误类型。
(1) 真实答案为非连续片段;例如ID=186572,问题是[“2017”, “有”, “什么”, “好看”, “的”, “小说”],答案由多个文本片段组成,每个答案之间包含大量的无关介绍文本。目前本文框架还无法解决此类问题,未来可以将其转化成序列标注问题或者生成问题。
(2) 真实答案不在文档中,例如,ID=181576。这种错误只能寄希望于补充更多的事实文本信息,进行答案补充处理。
(3) 文档标题信息融合不够导致的错误,例如,ID=181579;问题是["csgo", "读取", "游戏", "后", "提示", "已", "停止", "工作"],所提出模型给出的答案是定位在题目为“csgo一点开始就停止工作”的文档下。下一步本文将考虑如何将标题信息进行融入。
4 总结
本文面向机器阅读理解提出了一种简单且有效的神经交互网络。首先,为了充分使用标注的答案信息,本文对发布的数据进行了重构;在建模词表征的时候,使用了多种词语义特征;接着使用问题到答案的注意力操作以及双向GRU完成文档和问题信息的有效融合。在最终的测试集上,本文模型达到了现有的先进的效果,名列所有参赛队的第2名。
猜你喜欢
摄影世界(2022年1期)2022-01-21 10:50:14
中国新闻周刊(2021年26期)2021-07-27 04:02:12
知识经济·中国直销(2018年12期)2018-12-29 12:22:14
商周刊(2017年6期)2017-08-22 03:42:36
海外华文教育(2016年1期)2017-01-20 08:21:58
信息安全研究(2016年4期)2016-12-01 06:06:54
山东大学法律评论(2016年0期)2016-08-16 03:24:12
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
