
基于相似消息的流行度预测方法
2018-12-20 06:18:22高金华沈华伟程学旗
中文信息学报 2018年11期
高金华,沈华伟,程学旗,刘 悦
(1. 中国科学院 计算技术研究所 网络数据科学与技术重点实验室,北京 100190;2. 中国科学院大学,北京 100049)
0 引言
随着互联网技术的不断发展,社交网络已经成为人们日常生活中不可或缺的一部分。社交网络的出现,极大地方便了消息的产生和传播。在社交网络上,用户可以自由地发布消息,也可以选择自己感兴趣的用户进行关注,进而获取自己感兴趣的内容。然而,用户有限的时间和关注度使得消息在传播过程中获取的流行度的分布是不均匀的[1-2]。这种分布不均匀的现象,吸引了研究者的广泛关注,并最终引出流行度预测问题。流行度预测问题在很多实际应用中都有着重要意义,包括服务商站点资源优化、热点资源发现、社交网络市场营销等。
传统的流行度预测方法可以分为两类: 基于点过程的方法[3-5]和基于特征的方法[6-8]。基于点过程的方法采用随机过程来刻画待预测消息在观测窗口内的流行度到达过程,通过对流行度变化速率的建模和估计,来预测该消息后续的流行度变化。这类方法能够较好地刻画流行度的到达过程,但是由于没有显式地利用其他历史消息的信息,这类方法的预测能力非常有限。基于特征的方法通常将流行度预测问题形式化为回归或分类问题,人工地定义和抽取大量的特征,并以历史消息为训练样本,训练得到特征和流行度之间的变换函数,进而对测试集中的消息进行预测。这类方法采用了有监督的学习框架,因此有较好的预测能力。但是,基于特征的方法对所有的消息都采用同一个预测模型,忽略了消息本身的特异性。实际上,消息在社交网络上的传播存在不同的传播模式[9],对应的预测函数也应不尽相同。因此,我们需要一个更细粒度的流行度预测方法。
本文提出了一种基于相似消息的流行度预测方法。对于待预测的消息,我们根据它在观测窗口内的流行度增长过程,从历史消息中寻找出与之相似的部分消息,再基于相似消息来对该消息后续的流行度变化进行预测。在定义消息之间的相似度时,我们将消息传播中包含的传播模式作为隐变量,利用LDA模型[10]学习得到消息在不同传播模式上的分布来作为消息的表达,进而使用余弦距离来度量消息之间的相似度。我们的方法既充分利用了历史信息,同时也考虑了消息本身传播过程的特异性。在数据集上的实验结果表明,我们的方法在流行度预测任务上要明显优于前两类方法。
1 相关工作
已有的流行度预测方法大体可以分为两类: 基于特征的方法和基于点过程的方法。
基于特征的方法通常将流行度预测问题形式化为回归或分类问题,人工地定义和抽取大量特征,使用有监督的框架来学习特征到流行度之间的变换函数。Szabo等[11]研究了Digg上的新闻数据和Youtube上的视频数据,发现这些内容早期的流行度和后期流行度之间存在着很强的对数线性相关,并将消息的早期累积流行度为特征,提出了SH(Szabo-Huberman)模型来预测消息的流行度。Pinto等[12]在SH模型的基础上,将观测窗口内的累积流行度拆分为等长时间间隔内的流行度增长序列,利用多元回归模型来预测流行度。这类工作中,也有研究者专注于分析和发现对流行度预测有指示作用的特征。Suh等[13]研究了Twitter平台上消息的转发情况,并抽取了一系列的特征来预测消息的最终转发数。实验结果表明,消息中包含的URL和hashtag标签信息,对消息转发数的预测有很重要的指示作用。消息发布者的元信息,包括粉丝数和关注数等,也与最终的预测结果存在很强的关联关系。Bao等[14]研究了新浪微博上消息转发形成的转发树数据,提取了消息转发树的深度和连接密度两个特征,有效提高了回归模型的预测精度。此外,Cheng等[15]将流行度预测问题形式化为阶段性的增长预测问题。他们指出,在以往的流行度分类预测问题中,由于流行度本身的分布是幂律的,导致各个类别样本数极度不均匀,从而影响最终的预测效果。因此,他们提出了“kto2k”问题: 给定当前流行度为k的消息,预测它们最终的流行度能否增长到2k。基于样本集中流行度的分布,他们证明了提出的“kto2k”问题是一个均衡的二分类问题,并抽取了内容特征、用户特征、网络结构特征以及时序特征来进行预测。实验结果表明,随着k的增长,分类预测的准确率也在不断提高。
基于点过程的方法通常只利用待预测消息自身的信息,通过对待预测消息在观测窗口内流行度到达过程的建模,来预测消息后续流行度的变化。这类方法将流行度的增长过程形式化为一个计数过程(counting process)[16],并将强度函数(intensity function)的刻画作为模型的核心。强度函数l(t)刻画了给定历史信息Ht下,在时间窗口[t,t+dt)内有新事件发生的概率,如式(1)所示。
P{event in [t,t+dt) |Ht}=l(t)dt
(1)
基于这一框架,Shen等[3]提出了基于自增强泊松过程(Reinforced Poisson Process, RPP)的RPP模型。在建模消息的强度函数时,考虑了消息本身的吸引力、时间衰减机制和富者愈富机制。Gao等[4]将RPP模型应用到新浪微博中,并对几种机制的作用形式进行了修正。Bao等[5]采用了自激励Hawkes过程(Self-exciting Hawkes process)来建模强度函数,刻画了消息传播过程中转发用户带来的激励作用。Zhao等[17]在自激励过程的基础上,进一步引入了用户的影响力信息。他们将用户的粉丝数加入到强度函数的建模中,进一步提升了模型的预测效果。这类方法由于没有利用其他历史消息的信息,预测能力比较有限。
此外,Mishra等[18]提出了将上述两类方法融合的方法。他们先利用自激励过程来建模消息在观测窗口内的流行度增长过程,再将学习得到的参数与人工抽取的其他特征合并,利用回归模型来预测消息的最终流行度。近年来,深度学习的方法在流行度预测领域也取得了不错的的进展。Li等[19]提出了端到端的DeepCas模型。他们在监督学习框架下,先利用深度学习模型将消息在观测窗口内的转发情况表示为向量,再利用神经网络模型学习消息的流行度增长与转发向量间的转换函数。Cao等[20]在自激励过程的启发下,提出了DeepHawkes模型。他们利用深度学习模型,刻画了传播过程中的用户影响力、用户激励以及时间衰减效应等影响因子,在数据集上取得了很好的预测效果。
2 模型
2.1 问题形式化

2.2 整体预测框架
不同于传统的基于特征的方法和基于点过程的方法,我们提出了一种基于相似消息的流行度预测方法。我们首先对所有消息在观测窗口的传播数据进行表示学习,得到他们的表示。对于待预测的每一条消息j,我们根据他们的表示,从历史消息中找到与之最相似的前K条消息,利用这K条消息在窗口[T0,T]内的数据,来预测消息j在预测窗口[T0,T]内的流行度。我们提出的方法,既充分利用了历史消息的传播数据,同时又避免了对所有的消息使用统一的预测模型,充分考虑了消息传播过程的特异性。在我们的模型中,如何对消息的传播数据进行表示,进而找到与之相似的历史消息,是至关重要的部分。
2.3 消息传播数据的表示
时间序列(x1,x2,…,xN)通常被用来将消息的传播数据转化为定长的向量化表示,其中N表示划分的等长时间区间的个数,xi表示在第i个时间间隔内流行度的增长量。这种时间序列的表示方式能一定程度上反映消息的流行度变化趋势,但是这种表示方法的效果受时间区间粒度的影响,同一条消息在不同大小的时间区间下的表示差异较大。另外,它也不能刻画消息在传播模式上的区别。事实上,消息的传播过程中包含着不同的传播模式,如快速爆发的模式、均匀增长的模式、逐渐衰退的模式等。图1中展示了两条示例消息的传播过程。从图中可以看到,在时间序列表示下,以5个单位时间为一个时间区间,两条消息的表达都是(25,21),但是两条消息的传播过程并不相同。第一条消息经历了平稳增长和衰落的过程,可以预见后续的流行度增长量会比较小;而第二条消息在经历了第1个时间间隔内的快速增长和衰落后,在第2个时间间隔内又迎来了平稳增长的过程,后续的流行度应该会持续增加。因此,基于时间序列的表示方法,会忽略消息传播过程所包含的不同传播模式,难以真正捕获传播过程相似的消息用于预测。
进一步地观察图1我们可以发现: 消息在处于不同的传播模式时,转发到达的速率不同,形成的转发时间间隔的分布也不相同。当消息处于快速爆发的模式时,会产生大量的短时间间隔;而当消息处于衰退模式时,会产生较少但是持续时间长的转发时间间隔。因此,消息在传播过程中产生的时间间隔数据,可以帮助推断消息所处的传播模式。
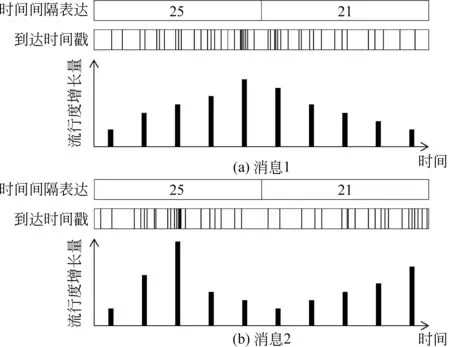
图1 两条示例消息的传播数据
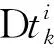
① 消息i根据自身传播模式的分布,采样一个传播模式P;
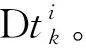
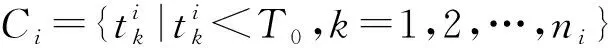
2.4 消息的流行度预测

我们模型的整体预测框架如图2所示。
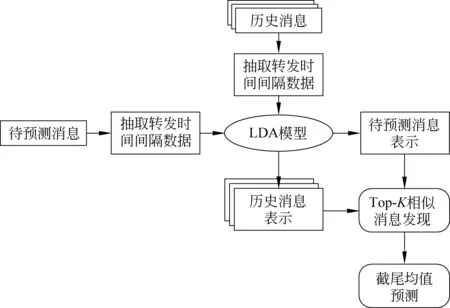
图2 模型的整体预测框架
3 实验
3.1 实验数据
我们抓取了微博上某一天的全部源发消息和它们发布后24小时内的转发数据来作为我们的实验数据。我们过滤了发布1h后累计转发数小于10的消息,最终用于实验的数据集包含了6.5万条源发消息和它们在发布后24h内的转发数据。我们将数据集平均分成5份,轮流选取其中1份为测试集,剩余4份为训练集来进行实验。所有展示的实验结果均为5个测试集的平均结果。
3.2 实验准备
3.2.1 对比模型
我们选取了以下三个模型来和我们的模型进行对比:
① RPP模型[3]: 采用了自增强泊松过程来刻画流行度的到达过程,考虑了消息自身的吸引力、时间衰减效应和富者愈富效应;
② Pinto模型[12]: 将消息在观测时间窗口内的转发数据表示为时间序列,利用多元线性回归模型来学习时间序列特征与流行度之间的变换函数;
③ SeqSim模型: 和我们提出的模型一样,SeqSim模型也是先从历史消息中寻找到和待预测消息相似的消息,再利用相似消息进行预测。不同于我们的模型,SeqSim模型直接使用时间序列来表示消息的传播数据。
3.2.2 评价指标
我们使用了平均绝对百分误差(Mean Absolute Percentage Error, MAPE)来度量不同模型的预测效果。模型在预测时间点t的MAPE值定义如式(2)所示。
(2)
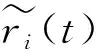
3.2.3 参数设置
在我们的实验中,消息的观测窗口设置为1小时,预测窗口设置为24小时。在利用LDA模型学习消息的表示时,LDA的主题数为4时效果最好,因此实验部分的结果均为主题数为4时的结果。主题数对预测效果的影响将在实验分析章节中进行讨论。在选取最相似的历史消息时,我们将K设置为10,即为每条待预测消息找到与之最相似的10条历史消息来进行预测。对于Pinto模型和SeqSim模型,在生成时间序列时,我们选择的时间区间的长度为5min。在使用截尾均值进行预测时,截尾均值的参数e%设置为10%。
3.3 实验结果
我们以消息发布后1小时内的转发情况作为观测,来预测后续每隔1小时后消息的流行度情况,实验结果如图3所示。
从图3中可以看出,我们提出的模型的预测效果要明显优于其他3个模型。Pinto模型的表现效果最差,因为它用一个模型来预测所有的待预测消息,噪声影响很大。比较Pinto模型和SeqSim模型可以看出,利用相似微博来预测流行度,可以有效地区分出消息本身的特异性,从而显著地提升预测效果。对比SeqSim模型和我们提出的模型的结果可以看出,相比于时间序列的表示方法,我们提出的基于消息传播模式的表示方法,可以更好地刻画消息的传播过程,进而找到传播过程相似的历史消息来进行预测,得到更精确的预测效果。另外,综合对比两个基于相似消息的模型和其他两个模型,可以发现基于相似消息的模型在进行预测时,随着时间的增长,预测误差的增长更加平稳,预测性能更好。

图3 不同模型的流行度预测效果
3.4 实验分析
3.4.1 LDA模型中主题个数的影响
在利用LDA模型进行表示学习时,主题个数是一个非常重要的超参。我们对不同主题个数设定下的预测效果进行了实验,结果如图4所示,其中M表示主题个数,t表示预测时刻。

图4 不同主题数目下的预测效果
从图4可以看出,在不同的预测时间点上,主题个数为4的模型的预测效果都要明显地优于其他模型。因此,在对比实验中,我们将LDA模型的主题个数设置为4。
3.4.2 相似消息分析
我们在图5中展示了部分待预测消息以及模型,并找到与之相似的历史消息的传播数据。图中竖线标识的位置为观测窗口的大小,加号数据标识了待预测消息流行度的实际变化情况。从图中可以看到,我们找到的相似消息,在观测窗口内的传播过程和流行度大小与待预测消息非常相似;同时在预测时间窗口中,消息的流行度变化趋势也非常一致。这表明我们提出的基于传播模式的表示方法,可以有效地刻画消息的传播过程,从而找到那些变化趋势相近的历史消息来辅助预测。另外,从图中可以看出,找到的近似消息中存在离群点,这也说明了采用截尾平均值的必要性。
4 总结
针对现有的两类流行度预测方法的不足,本文中提出了一种基于相似消息的流行度预测方法。对于每一条待预测的消息,我们从历史消息中选取出传播相似度最高的K条消息来进行预测。在计算消息间的相似度时,我们利用了文档主题建模领域的LDA模型,来学习得到消息的表示。我们将消息转发过程中产生的时间间隔数据作为输入,将消息中包含的不同传播模式作为隐变量,利用LDA模型,学习得到消息在不同传播模式上的分布作为消息的表示。数据集上的实验结果表明,我们的方法能够有效地发现传播模式相近的消息,进而取得了更好的流行度预测效果。在本文的模型中,在学习消息的表示时,学到的消息并没有显式的时序特征。在接下来的工作中,我们会从这个方向展开,来研究消息的传播模式随时间的变化,以及其对流行度预测效果的影响。
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
通信产业报(2020年43期)2020-01-15 06:38:43
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
中国卫生(2014年12期)2014-11-12 13:12:26
中国卫生(2014年8期)2014-11-12 13:00:50
