
基于条件随机场的方志古籍别名自动抽取模型构建
2018-12-20 06:08:46李娜
中文信息学报 2018年11期
李 娜
(南京林业大学 人文社会科学学院,江苏 南京 210037)
0 引言
命名实体识别(named entity recognition, NER)作为一种常用的文本挖掘技术,用于识别文本中为人们感兴趣的专有词和特定的数量词。它包含具体和抽象的实体。例如,人名、地名、机构名、时间、数量等[1],在信息检索和抽取、机器翻译和问答系统等自然语言处理上,有着广泛的应用。
近年来,随着数字人文的快速发展,中文古籍的数字化和深度挖掘需求越来越迫切。在自然语言处理中,命名实体识别的研究语料以现代汉语为主[2-3],藏语[4]、哈萨克语[5]、蒙古语[6]、维吾尔语[7]、越南语[8]等其他语言也有涉及,识别对象有地名[9]、人名[10]、疾病名[11]、机构名[12]、时间[13]等信息单元。古籍文献在繁简字、标点符号、句式表达等多个方面与现代文献差异明显,智能化识别难度更大,研究成果较少。石民等对《左传》进行了词汇处理和考察分析,采用条件随机场模型,进行自动分词、词性标注、分词标注一体化的对比试验[14];肖磊、汪青青分析了《左传》地名和人名结构的特点,基于CRF模型,分别实现了地名和人名的自动识别[15-16];马创新通过模型构建和结构分析,实现了《十三经注疏》中引文文献的识别和分析[17];钱智勇等基于隐马尔科夫模型,进行了楚辞的自动分词标注实验,并根据实验情况设计了一个分词标注辅助软件[18];黄水清等基于先秦语料库,分别使用条件随机场和最大熵模型对地名进行了识别研究,结果表明条件随机场的识别效果优于最大熵模型[19];王铮将条件随机场模型应用到《三国演义》的地名识别中,识别结果的准确率为99.16%[20];朱锁玲以《方志物产》广东、福建、台湾三省资料为语料,通过整理文中地名出现的规则,构建规则库与文本内容进行匹配,实现了地名的识别,精确率为63.38%,召回率为82.89%[21];衡中青以《方志物产》广东分卷为例,通过基于规则的方法,分别识别了文中的引书[22]和别名[23]。其中,引书识别的召回率和精确率分别为84.95%和72.88%,别名的召回率为88.60%、精确率为71.60%;Bol及其研究团队以220余部地方志为语料,基于语言模型和条件随机场,挖掘文本中的人名、字号、官职、地名等传记信息,并将结果与中国历代人物传记数据库(China Biographical Database, CBDB)进行对比和补充[24]。上述研究表明,基于条件随机场模型的中文命名实体识别正在不断深入,但中文古籍的命名实体研究多集中在文学作品等较为规范的古籍本文中。而在方志古籍的整理、挖掘利用研究方面,尚处于探索阶段,成果分散且精准度有待提高。
本文以命名实体识别技术中的条件随机场模型为基础,对摘抄自地方志的《方志物产》语料库中物产别名进行自动识别实验,拓展语料的研究方法,延伸方法的应用范围,具有一定的创新价值和探索意义,为深入开发和利用方志资料提供实体数据。
1 研究语料
方志,又称地方志,为我国古籍文献之大宗,是按照一定体例记载了特定时空下,自然和社会各个方面历史与现状的综合性著述,被誉为“一方之全史”,是我国乃至世界的一座重要文化遗产宝库,为后世提供了取之不竭的史料资源[25]。
中国自古就有参考利用地方文献的实践。20世纪50年代,我国著名农史学家、农史学科创始人之一万国鼎先生,组织数十人先后前往全国40多个大中型城市、100多个文史单位,历时数年从数千部地方志中手工整理摘抄了其中的物产部分,编纂成农业专题资料《方志物产》[26]。作为目前世界上唯一一套明清方志农业专题资料,《方志物产》具有独特的史料价值: 一是唯一性,自摘抄以来,经历半个多世纪的变迁,尤其是“文革”时期的冲击,部分原始文献已经散佚;二是广泛性,横向地域范围广,涵盖了建国初期全国所有的省份;三是持续性,纵向时间跨度大,从宋熙宁九年(1076年)至民国三十八年(1949年),记载了长达近900年间的物产情况;四是丰富性,全文共431卷、3 000余万字,涉及动植物的品种资源和种植饲养方法等农业生产的各个方面,尤其以动植物的品种资源和种植、饲养、利用技术为主;五是多样性,行文风格和本文结构呈现出多样性,是古籍文献中比较有特色和代表性的语料[27]。
《方志物产》中蕴含着丰富的信息资源,物产别名就是其中之一。物产别名是相对于物产正名而言的,是由于物产特性、古籍记载、时代变迁、地域差异、民俗文化、人口流动、文化交流等多种历史原因,造成的同物异名现象[28]。考察物产的名称及其变化是植物史、动物史、货物史研究的重要任务,梳理《方志物产》所载物产的别名,有利于开展物产的起源和传播、生物学特征和用途、记载方式变迁、地方性知识等内容的研究,从而更加全面地认识和分析物产。
物产别名梳理是物产研究的重要组成部分,但往往是在研究某一物产时专门查找该物产的别名信息,鲜有专门整理物产别名的研究。本文以《方志物产》山西分卷为语料,在格式化处理的前提下,对物产别名进行全文人工标注。基于命名实体识别技术中的条件随机场理论,构建物产别名的自动识别模型,实现物产别名的自动抽取,探索方志古籍内容挖掘的新途径,为物产研究提供资料支撑。
目前,常用的命名实体识别方法主要有基于规则的方法和基于统计的方法。对比而言,基于规则的方法实现简单、速度快,但主观性较大,对规则库的完善程度要求高,适合小规模语料;基于统计的方法实现代价低,数据依赖性小,且具有较好的移植性,适用于较大规模语料。《方志物产》时间长、范围广、数量大、类型多,基于统计的方法较为适用。隐马尔可夫模型、最大熵模型和条件随机场模型是基于统计的方法中比较常用的模型。其中,条件随机场模型是Lafferty[29]等在最大熵模型和隐马尔可夫模型的基础上提出来的,解决了隐马尔可夫模型严格的独立性假设限制和最大熵模型标注偏差问题。通过灵活结合上下文的多项特征,在分词、词性标注、命名实体识别等自然语言处理方面有着较好的应用。
2 研究语料的预处理
本文以《方志物产》山西分卷为例,探讨条件随机场模型在方志古籍内容挖掘中的应用情况。有“三晋”之称的山西,位于黄河之滨,处于中原大地,是中华民族的发祥地之一。它有着长达3 000余年的文字记载史,农业发达、物产丰富,被誉为“华夏文明摇篮”和“中国古代文化博物馆”。因此,山西能够反映出中原地区、黄河流域甚至更广范围的情况,具有一定的代表性。
《方志物产》山西分卷共13卷,43万字,记载了明成化二十一年(1485年)至民国二十九年(1940年)间山西境内51 545条物产信息。物产信息包含志书名称、记载时间、物产名称、物产备注、物产分类等多项内容。本文主要考察物产名称和物产备注两项信息,其目的是通过计算机对人工标注信息的学习,基于条件随机场的构建物产别名自动识别模型。
2.1 别名的人工标注
受文字变迁和记载方志的影响,方志文献中物产信息不尽完备。首先,物产备注信息存在缺失现象,即有的物产有备注信息,有的物产没有备注信息,如图1所示。而本文研究的目的是从物产的备注信息中抽取别名信息,故没有备注信息的物产记录对本研究无意义。51 545条物产信息中,有备注信息的物产共有9 085条,约占总物产量的17.54%;其次,物产名称存在不完整现象。山西分卷中记载的51 545条物产,部分物产名称中除汉字以外,还包含“?、+、(、)、□”等其他符号,表示该处为“缺字”或者“造字”等。例如,“□鵝、天□□、(班+鳥)、□□、??”等。此类物产共计有273条,约占总物产数量的0.53%。为了保证数据的原始性和完整性,我们仍然将其保留,并尝试通过数据关联的方式,补全缺失的物产名称。

图1 随机选取的10条物产信息样例
在对物产的备注信息进行标注时,用“Alias”表示别名。“A”代表标注之处为别名,用“【”、“】”表示别名的左右边界,完整的标志结构为“【A别名】”。例如,“螽斯蝗类也长而色青长角长股翼鸣者也亦有斑黑者其股似瑇瑁五月中以两翅相切作声声闻数十步者是也俗名【A蚂蚱】以其形似马而鸣声咋咋然也”,最终计算机识别出的螽斯的别名为蚂蚱。标注完成后,9 085条物产信息中含有别名信息的有2 522条,这就是本研究的最终语料。
2 522条语料共标注出别名3 458次。去重后,共得到891个物产名称和1 485个别名。平均每个物产名称约有1.67个别名,物产至少有一个别名。如“百足虫”的别名为“钱龙”等,最多有42个别名,如物产“稷”。平均每个别名出现约2.33次,最少出现1次,如“羊胡草”等853个别名,最多出现46次,如“小米”和“诸葛菜”。
2.2 标注集确定
在手工标注的基础上,识别构建模型所需要的标注。计算别名的加权长度,可以明确标注集长度。生成标注集如式(1)所示。
(1)
其中,Lik为当i≤k时,别名平均加权后的长度,Ni为语料库中长度为i的别名出现的次数。k和j分别代表语料库中别名长度的最大值和最小值,N为语料库中别名出现的总次数。通过计算和实验测试,本文确定在别名的自动识别中,使用四词位的标注集,具体表示为P={B,M,E,S}。其中,B为别名的初始词,M为中间词,E为结束词,S为别名标记以外的词。经过手工标记的语句“樗鷄 一名【A紅娘子】俗呼【A瞎眼婆婆】”,标注集的结果,如表1所示。

表1 标注集样例
标注集生成后,对别名的边界词进行统计分析。假设,我们把一条语料的构成序列表示成“SLn,…,SLi,…,SL1,【R,R1,…,Rn】,SR1,…,SRj,…,SRn”。其中,【R,R1,…,Rn】表示标注集,SLi表示标注集的左边界,SRj表示标注集的右边界。那么,SL1和SR1就是标注集的左右一元边界词,SL2SL1和SR1SR2为标注集的左右二元边界词,SL3SL2SL1和SR1SR2SR3为标注集的左右三元边界词。在判定线性序中的别名时,主要使用了左右一元边界词特征。别名的左右一元边界词的分布状况运用式(2)获取。
(2)
其中,pc(ω)为ω在语料中作为一元边界词出现的概率,fβ(ω)为ω在一元边界词位置上出现的次数,∑ωfβ(ω)为ω在语料库中出现的总次数。
2.3 别名的内外部特征分析
《方志物产》山西分卷的语料经过人工标注后,编写计算机程序,提取物产的别名和别名的左右一元边界词。在词频和词长统计的基础上,对物产别名的长度和左右一元边界词等内外部特征进行分析。
经过标注,共提取出人工标注的别名3 458次。去除重复后,总计有1 485个不同的别名,每个别名出现的平均次数约为3次。别名的长度主要有五种,即长度为1、2、3、4、5,数字表示一个别名由几个汉字组成。从词频统计结果看,长度为2的别名最多,有2 001个,约占总别名的57.87%;长度为5的别名最少,只有9个,仅占总别名的0.26%。别名的长度主要集中在1、2、3上,共有3 353个,约占总别名的96.96%,涵盖了绝大多数的别名。
左右一元边界词分析有助于精确定位词的边界。别名的左右一元边界词及其出现的概率统计结果(按照出现次序由多到少排序各取前十)如表2所示。
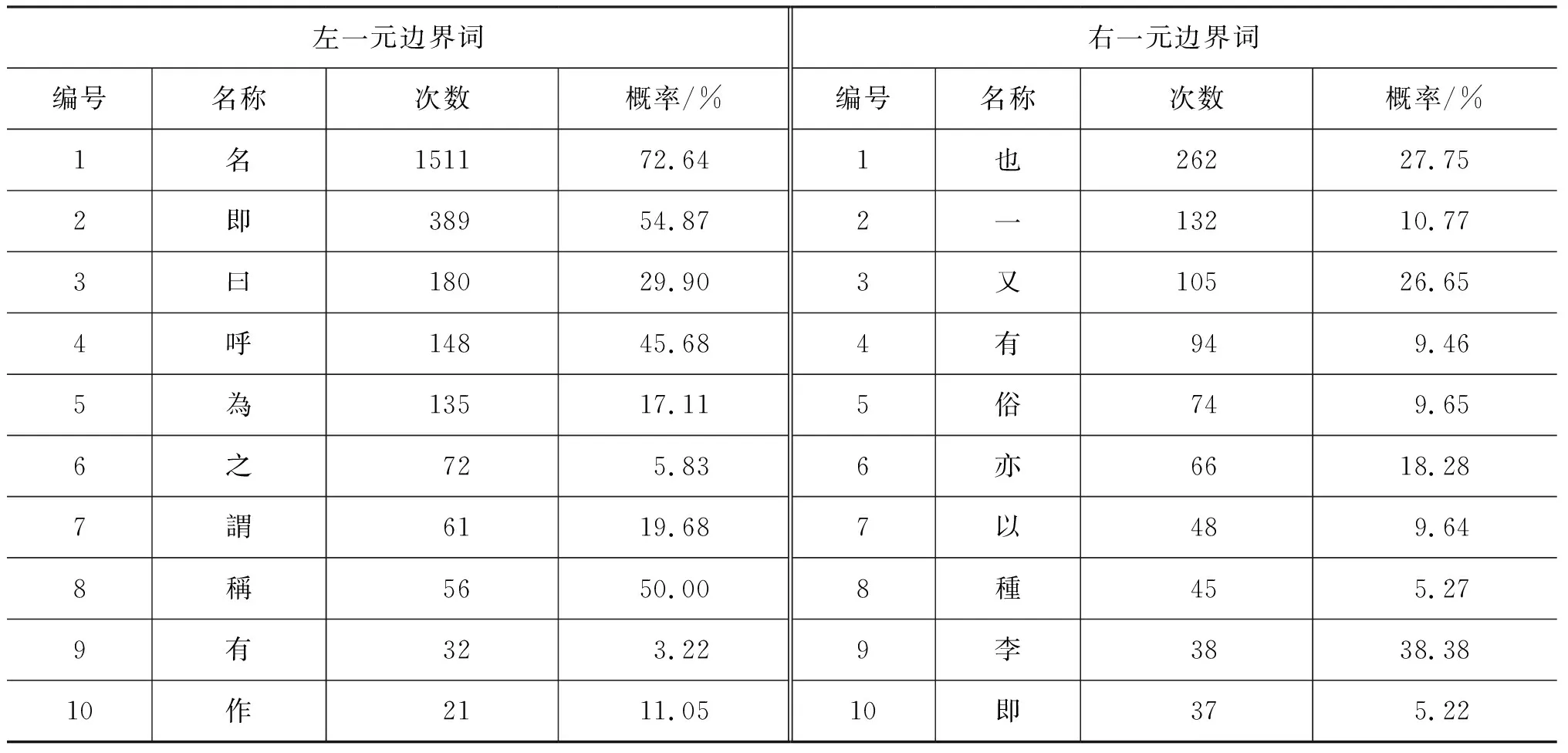
表2 别名的左、右一元边界词信息统计结果(前十)
结果显示,物产别名的左一元边界词高度集中。频次最高的10个左一元边界词占所有一元边界词的比例高达91.73%。其中,“名”的频次和出现次数均为最高,如“大力子 一名牛旁子又名鼠粘子”等;物产别名的右一元边界词较为分散,频次最高的10个右一元边界词占所有右一元边界词的比例为44.02%。其中,“也”的出现次数最多,如“鳳仙 即海納也”等。而“李”的频次最高,如“長松草 亦名【A仙茅】李時珍曰長松生古松下根色如薺苨長五六寸味甘微苦類人葠清香可愛”等。
3 基于CRF的识别模型构建与测评
3.1 模型构建
条件随机场(Conditional Random Fields,CRF)是一种判别式的无向概率图模型,用于在给定需要标记的观察序列的条件下,预测标签序列的概率分布。
本研究在构建条件随机场模型时,假设变量x是方志物产语料库中经过人工标注的别名实体,变量y是别名实体中每一个分布序列。一串变量y对一串变量x,将多个变量x作为一个整体,用于确定y和y之间的转移概率,即当变量x取值为x时,变量y取值为y的概率。计算如式(3)所示。
(3)
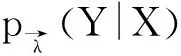
在构建CRF模型时,语料中的上下文特征都应该被加进特征函数中去,以提高模型的性能。本研究的模型中需要加入上文所分析的别名的内外部特征,例如,出现频次、长度、边界词等。
1. 别名长度。如上文统计,最常见的别名长度为2,如“鳳仙 俗名【A海納】”。大多数的别名长度都在1至3的范围之内,长度为1的如“榖 即【A粟】為秋橡之主東北一帶村莊半居岡阜地瘠苦寒種麥者僅十之一惟河西及南鄉澤鹵之地多種”,长度为3的如“榖精草 即【A文星草】可餧馬令肥”。别名长度用阿拉伯数字表示,作为一个特征加入模型中。
2. 一元边界词。命名实体的识别其实就是确定命名实体的左右边界的过程。一旦左右边界确定了,那么命名实体就顺理成章地被识别出来了。因此,别名的左右一元边界词作为一个非常重要的特征,成为模型的一部分。在前文的统计中,“名、即、曰、呼、為、之、謂、稱、有、作”是别名的左一元边界词的前十名,“也、一、又、有、俗、亦、以、種、李、即”是别名右一元边界词的前十名。在处理训练语料的时候,标注出左右一元边界词,左一元边界词标注为L,右一元边界词标注为R,非一元边界词则标注为N,并作为特征加入到模型之中。例如,语料“花紅 即【A奈】也俗名【A紅果】即謂【A文官果】也”,标注左右一元边界词的结果,如表3所示。
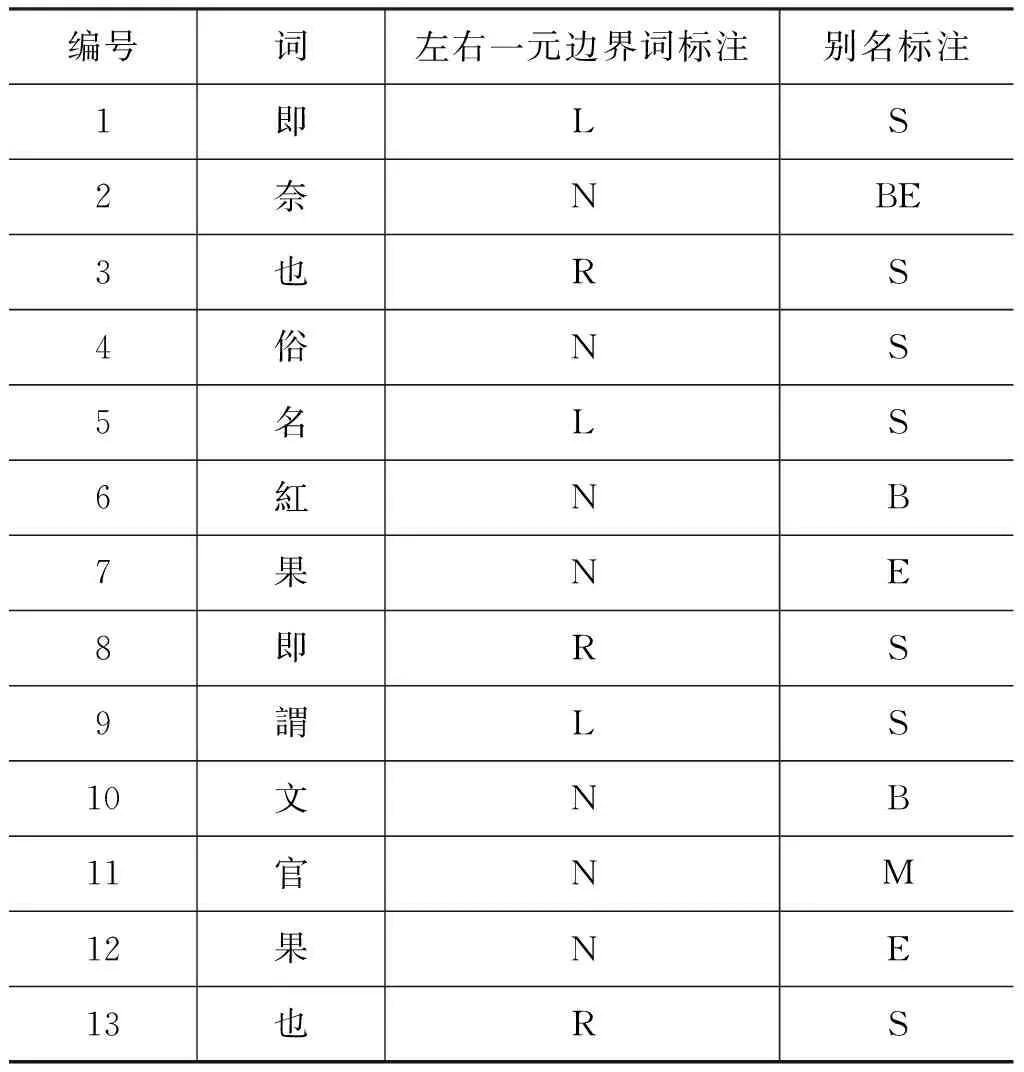
表3 左右一元边界词的标注样例
3.2 测评方法
命名实体识别的评价指标有三个: 精确率P、召回率R及调和平均数F。精确率是指识别结果中正确的命名实体所占的比例,召回率是指识别结果中正确的命名实体数量占语料中所有命名实体总量的比例,调和平均数是精确率和召回率的加权几何平均值。计算公式如式(4)~式(6)所示。
其中,识别正确的命名实体数量,是指模型识别的结果中是别名的个数;识别错误的命名实体数量,是指模型识别的结果中不是别名的个数;没有识别的命名实体数量,是指模型没有识别出的别名个数。
在利用精确率和召回率进行别名识别模型的性能评价时,单方面提高精确率,会导致召回率下降,反之亦然。本文采用精确率和召回率的加权几何平均数F作为别名识别模型的综合评价指标。
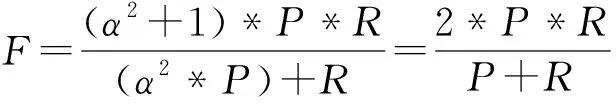
(6)
其中,α为P和R的相对权重。当α>1时,P的权重较R大,当α<1时,R的权重较P大,当α=1时,P与R具有相同的权重。
3.3 测评结果
《方志物产》山西分卷中物产的备注信息中有别名信息的共有2 522条。为了提高调和平均数的值,本文采用交叉验证的方式构建和测评识别模型。将2 522条语料分成10等份,进行10次实验。每次选取其中的9份作为训练语料,构建模型,将剩余的1份作为测试语料,对模型的性能进行测试和评价。针对识别结果计算P、R、F值,结果如表4所示。
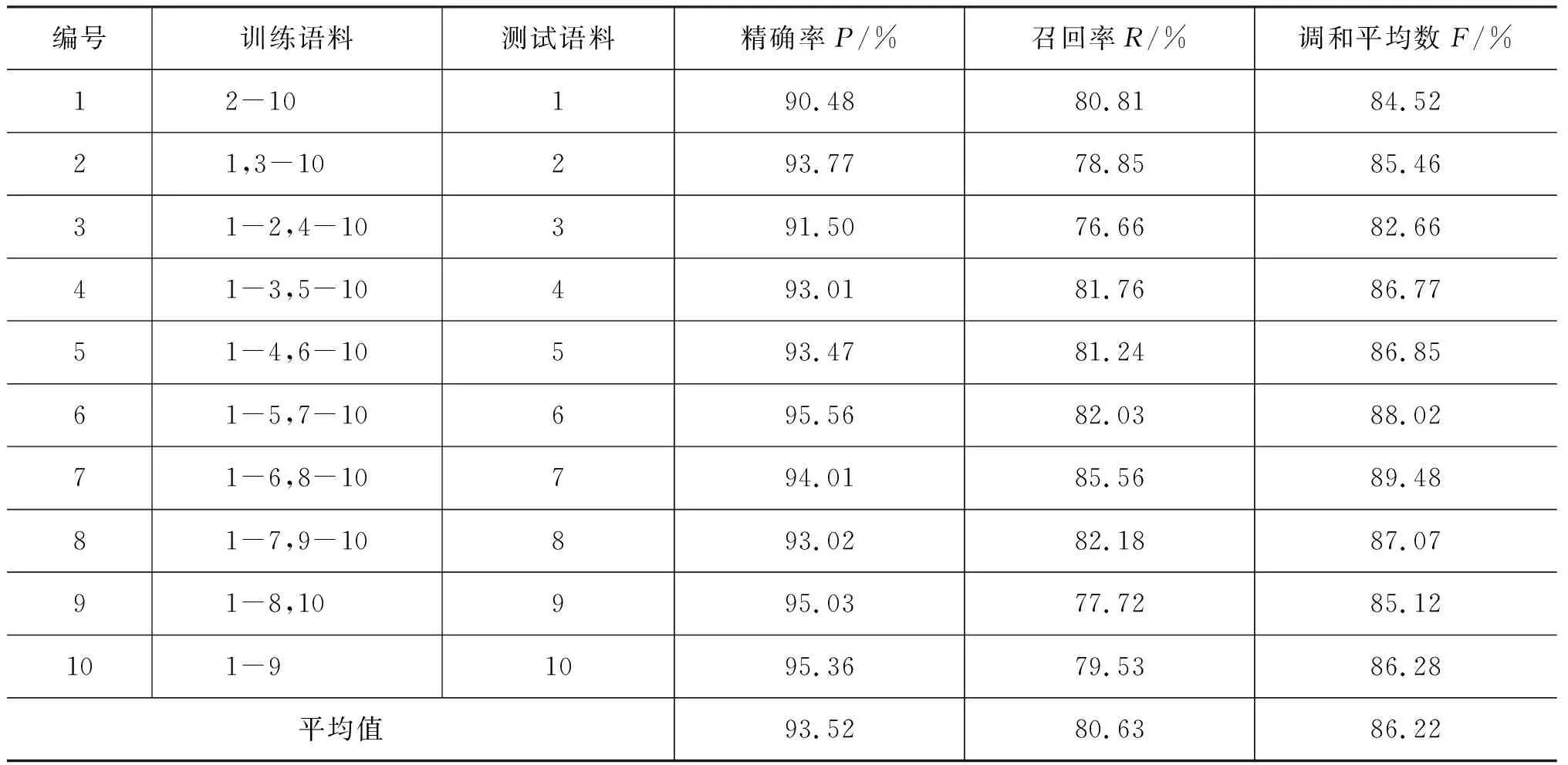
表4 物产别名自动识别模型的测试结果
整体而言,基于CRF的模型识别精确率最高,平均值达到了93.52%,而召回率相对较低,为80.63%。即模型的识别结果中别名正确率较高,但占全部应识别出的别名比例稍低。就单次测试结果而言,第7份测试的整体效果较好。该次测试的语料中,别名的内外部特征与识别模型的特征模板高度吻合。别名长度在1~3之间,符合别名长度的分布趋势;73.50%的左右一元边界词都是总体排名前十的字,有利于别名左右边界的精确定位。
3.4 结果分析
测试结果显示,条件随机场模型在《方志物产》山西分卷的物产别名识别中发挥了较好的作用,取得了良好的实验效果。不过还有一定的提升空间,主要是由于以下几个方面的原因。
(1) 别名单独出现。别名前后没有明显的标识字符,且出现次数较少,不足以形成规律。例如,以下三条语料“滴溜 甘露子”、“醋注 长柄瓠”、“白鳝 鳗鲡”等,“滴溜、醋注、白鳝”为物产名称,“甘露子、长柄瓠、鳗鲡”分别是三种物产的别名,这三个别名在整个语料当中都只出现了一次,别名两侧又没有任何标识字符。因此,计算机模型无法将其识别出来。
(2) 别名与物产名相同。人工标注过程中,一旦发现物产备注信息中出现的别名与物产名称相同,就放弃对该名称的标注,认为它是物产名称在备注信息中重复出现。但计算机模型识别的时候,只要判断符合别名特征,就会被当作别名识别出来。例如,“半痴 俗名半翅檢徐天地集名半痴因其性也”,人工标注的时候只标注出“半翅”,而计算机模型识别的结果为“半翅”、“半痴”。
(3) 别名重复出现。在同一个物产的同一条备注信息中,某别名多次出现,人工标注仅标注一次,而计算机模型不会判断别名是否重复出现。例如,“鳲鳩 俗呼布穀身灰色翅尾俱有黑斑辳夫侯此鳥鳴乃布種其榖故名布穀”,人工只对“俗呼布穀”进行标注,结果为“布穀”,而计算机模型识别的结果为“布穀”、“布穀”。
(4) 别名与其它信息混淆。在物产的备注信息中,有品种、地名等其它类型的命名实体出现的规则与别名相似,在计算机模型分析判断之后,成为识别结果的一部分。例如,“赭石 生河東山中別錄曰出代郡者名代赭李時珍曰赭赤色也代即雁門也俗呼土朱鐵”,人工识别的结果为“代赭、土朱鐵”,而计算机模型识别的结果为“代赭、雁門、土朱鐵”。显而易见,“雁門”并非物产“赭石”的别名,而是地点“代”表示的地名。
(5) 别名的长度判断错误。物产的别名长度大多数为2~3个字,但也有一些较长的别名,在计算机模型进行判断时,识别的完整性较低。例如,“玄精石 出解州塩池本草曰乃鹹鹵至陰之精凝結而成故名又名太乙玄清石”,计算机模型只识别出“太乙”。
(6) 别名并列连续出现。即一个物产有数个别名,这些别名在备注信息中是并列连续出现的。别名之间没有任何标识字符,计算机模型无法准确判断别名个数,不能实现自动分词。例如,“黃精 葉似竹每葉傍生二黑子一名重樓又有莬竹雞格救窮鹿竹等名宋僧延一舊志云出西臺”,人工标注的结果为“重樓、莬竹、雞格、救窮、鹿竹”,而计算机模型仅仅识别出“重樓”,“莬竹、雞格、救窮、鹿竹”在计算机模型中被判定为无效字段。
3.5 结果应用
物产的别名,关系着物产的起源、分布范围和传播路径,蕴含着文化的交流与变迁状况,对于全面认识物产具有重要的价值和意义。
首先,本研究自动抽取出的物产别名可以直接为物产研究人员提供别名信息,只要明确物产名称,就可以快速而精确地展示出方志物产中记载的该物产的别名信息,图2即是物产“菠菜”的别名信息。
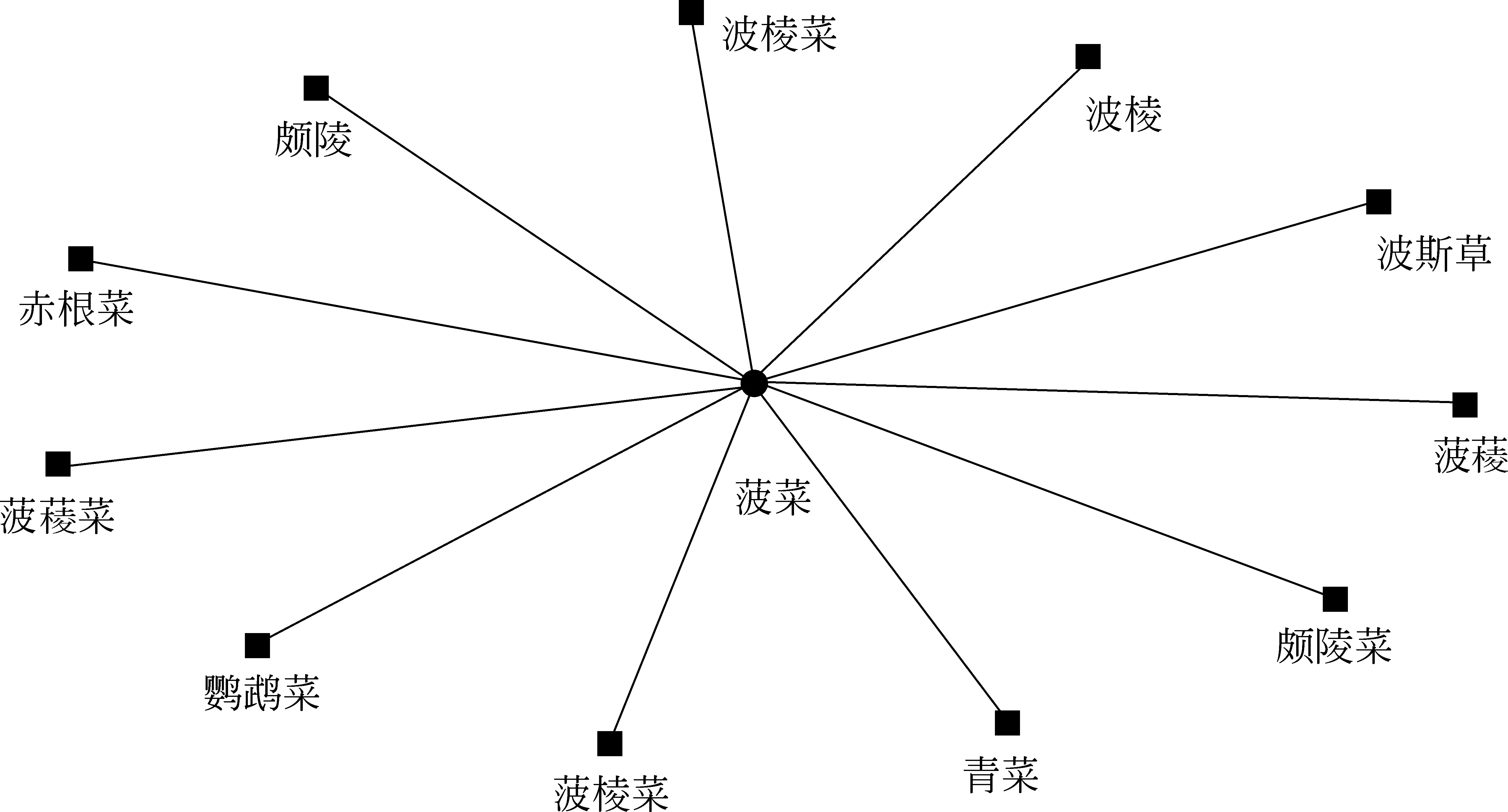
图2 物产“菠菜”的别名信息
其次,根据物产与别名之间的关系,可以清晰地梳理出不同物产之间具有相同别名的信息,有助于领域人员开辟不同物产之间的相关性研究,促进物产研究的体系化。图3是物产与别名信息中抽取出的一部分网络。结果显示,芍药与莱菔具有相同的别名虫媒花。
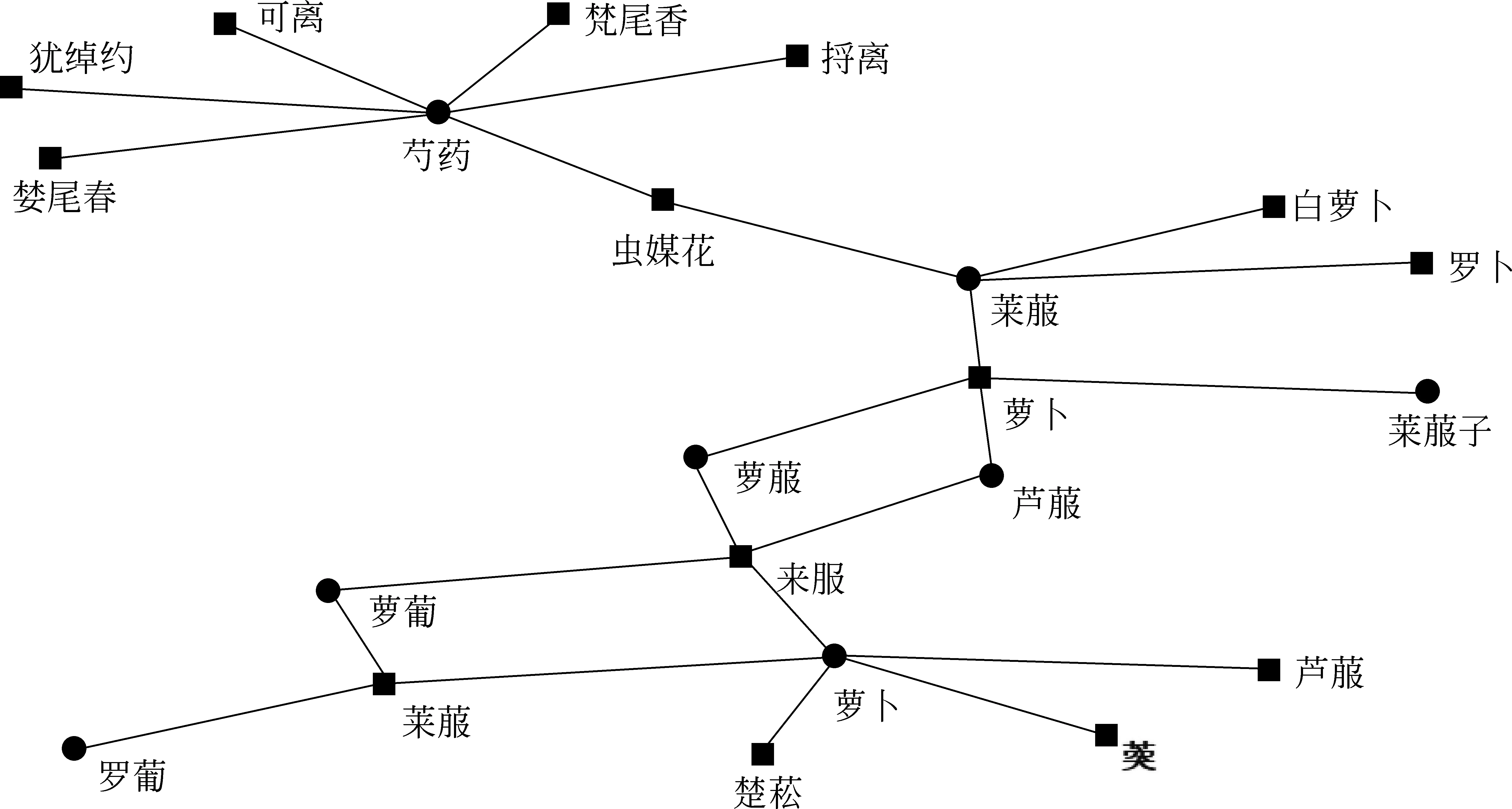
图3 物产—别名共用网络
4 结语
本文以《方志物产》山西分卷为例,在数据格式化处理和全文人工标注的基础上,通过特征分析,完成了基于条件随机场的别名自动识别模型构建。并通过十次交叉验证法,对模型的识别性能进行测试,取得了较好的实验结果,验证了条件随机场模型在方志古籍的内容挖掘中具有良好的可行性和应用前景。
在进一步的研究中,主要通过两个方面提升命名实体的识别效果。一是扩大语料规模。将研究语料从山西一个省扩展至华北地区多个省甚至全国范围,增加语料的多样性;二是完善特征模板,作为构建识别模型的基础。特征模板越完善,识别模型的性能越高。随着研究的逐步深入,智能识别效果会越来越精确。
内容抽取是古籍整理的中间环节,连接着数字化建设和知识发现结果。古籍中凝聚着古人的经验和智慧,挖掘其中蕴含的信息,可以更好地了解过去、认识现在、指导未来。数字图书馆和现代信息技术的发展为基于内容的古籍整理提供了坚实的资料基础和技术支持,推动了古籍文献服务社会的进程。但仍有待于进一步深入探索,充分挖掘古籍资料的价值。
猜你喜欢
公民与法治(2023年11期)2023-11-18 08:49:18
Plasma Science and Technology(2022年5期)2022-06-01 07:55:32
证券市场周刊(2021年44期)2021-05-30 10:48:04
书法赏评(2019年2期)2019-07-02 12:10:50
西藏研究(2017年1期)2017-06-05 09:26:11
海外华文教育(2016年1期)2017-01-20 08:21:58
乡村地理(2016年2期)2016-06-15 20:29:28
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
Transactions of Nanjing University of Aeronautics and Astronautics(2015年5期)2015-02-09 06:08:54
民族古籍研究(2014年0期)2014-10-27 08:24:34
