
基于云模型的企业质量绩效评价
2018-12-20 07:20:58贺金凤徐松杰
统计与决策 2018年22期
贺金凤,王 林,徐松杰
(1.郑州大学 管理工程学院,郑州 450001;2.河南工程学院 管理工程学院,郑州 451191)
0 引言
企业绩效测量有多个维度,如财务与非财务方法,定性与定量分析等。由于单纯的财务绩效测量难以全面反映组织的整体绩效,近几年,许多组织采用全面质量管理方法来评估企业的综合绩效,质量绩效评估也应运而生。作为一种系统管理工具,质量绩效评估识可以帮助企业识别优势和弱项,通过持续改进,促进企业综合绩效的提升。目前广泛应用的质量绩效评估工具是质量奖模型,但质量奖标准仅给出一系列多层次、多准则的描述性条款以及相应的评价等级分类和对应等级的描述性定义[1],没有给出具体的指标测评和综合评价方法。在实际应用中,专家评分和评分的算术平均值通常被用作指标的度量和合成。由于自然语言本身具有一定的模糊性和随机性,加之单一的数字评分缺乏稳健性,不能很好地处理评价过程中的不确定性,因此评价结果常常存在较大的偏差[2]。云模型是实现定性概念定量化的一种有效方法[3],它可以处理定性概念与定量表达之间的不确定性转换。因此,本文将云模型应用于质量绩效评估,用以处理信息评估的模糊性和不确定性,提高质量绩效评价结果的有效性。
1 云模型
设X={x},X是一个用数值表示的定量论域,T是X上的定性概念,若定量值x∈X是定性概念T的一次随机实现,x对T的确定度 μT(x)∈[0 ,1]是一个具有稳定倾向的随机数[4]:
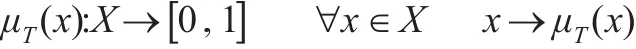
则x在论域X上的分布称为云。云模型通过期望Ex、熵En、超熵 He三个数字特征来表征一个概念T(Ex,En,He)。期望值Ex是 X所代表的概念在论域中的中心值,即最能代表某个定性概念的值。
熵En是定性概念不确定性的度量,由概念的模糊性和随机性共同决定,反映论域中可以被该概念所接受的云滴的取值范围。
超熵He是熵的不确定性的度量,是熵的熵。对于在一定范围内可以被普遍接受的概念,超熵较小;对于难以达成共识的概念,超熵较大。
2 基于云模型的质量绩效评价
2.1 质量绩效评估指标体系
国家标准GB/T 19580由一系列描述性条款组成,共包括七大“类”标准,这些“类”标准又进一步拓展为若干的评分“项”及针对评分项的说明性内容,并按照“方法-展开-学习-整合”或“水平-趋势-比较-重要性”的要求进一步展开说明,如此层层分解构成了多层次、多准则的组织绩效评价体系。因此,本文以GB/T 19580为基础,以其中的七大“类”为顶层属性,以标准中的评分“项”为2层属性,以针对评分项的说明性内容为3层属性,以此类推,构建如下页表1所示的质量绩效评估指标体系。
2.2 质量绩效评语集云模型
根据GB/T19580附录C,无论是“过程”评价还是“结果”评价,专家都按照过程条款和结果条款中的评价要素对其成熟度进行打分。成熟度水平分为6个区间,即0%~5%,10%~25%,30%~45%,50%~65%,70%~85%和90%~100%。显然,六个水平之间存在五个评分间隙,并且在相邻区间之间缺乏过渡,评分不能完全涵盖评价的范围。因此本文用云模型来表示专家评语,定义六个评价等级分别为{较差,差,一般,好,较好,非常好}。
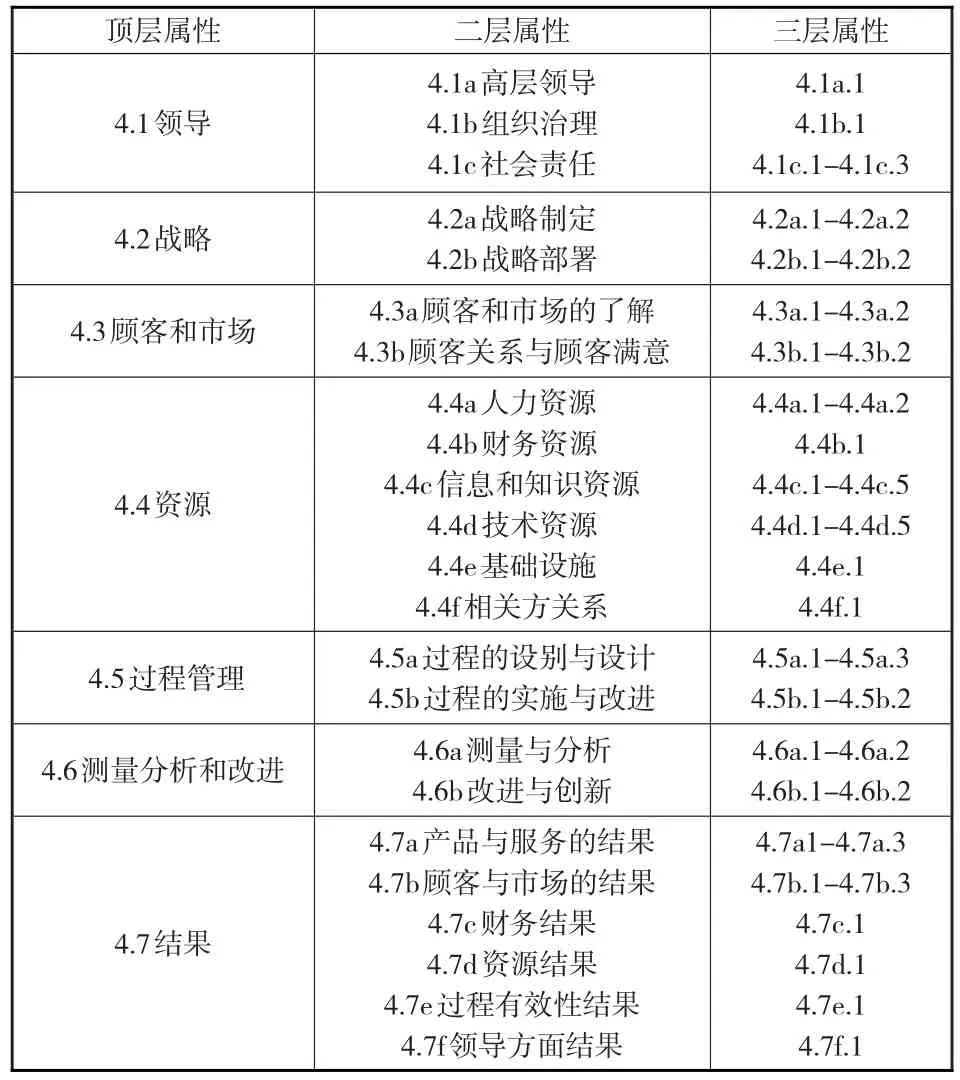
表1 基于卓越绩效评价准则的质量绩效评估体系
假设专家i的评语具有双边约束[Dinf,Dsup],且对应于[0,1]中的某个区间值,可以计算该评语云的数字特征[5]:

其中,Exi和Eni是专家i评语云模型的期望值和熵。He反映熵的离散程度,体现隶属度的不确定性,代表期望的随机性[6]。He越大期望的随机性越大,期望代表的定性概念越难以确定。超熵作为反映云滴凝聚度的值,可通过经验或实验取得,表示不确定性概念时往往取比较小的熵,当3He<En时可以更好地表达定性概念的特征[7]。本文根据云的雾化性质和专家知识确定超熵为0.005。表2根据专家知识给出了六个评价等级的数值分布及对应的定性语言描述。
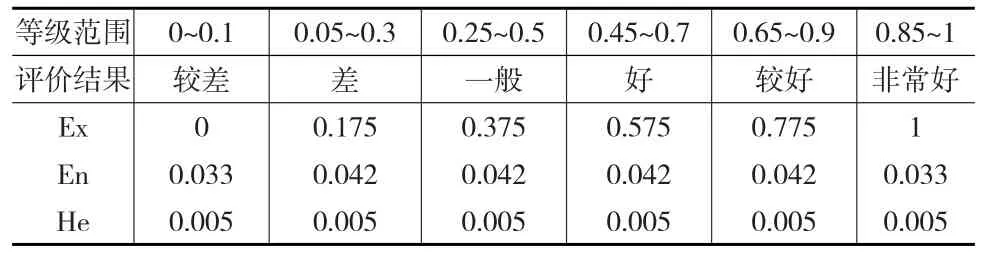
表2 评价等级及定性语言描述
评语云模型如图1所示,从左至右的评价等级依次为:较差,差,一般,好,较好,非常好。
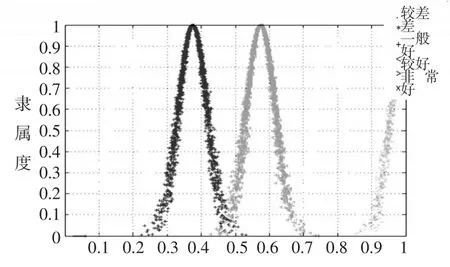
图1 评价等级及隶属度
2.3 专家评价的合成
浮动云适用于将多个相互独立的语言值综合为一个更广义的语言值[8]。针对同一个指标进行评价时,不同的专家有不同的评价值,且各个专家的评价值相互独立。本文采用云理论中生成浮动云的方法进行专家意见的集合,生成各个决策者对某一指标的综合评价值[9]。假设有n个指标,每个指标有P个专家的评价,专家的评价值根据云发生器转化为云模型,每个指标都有p个云模型,考虑专家的权重w,指标的专家综合评价云模型可以通过以下公式计算:
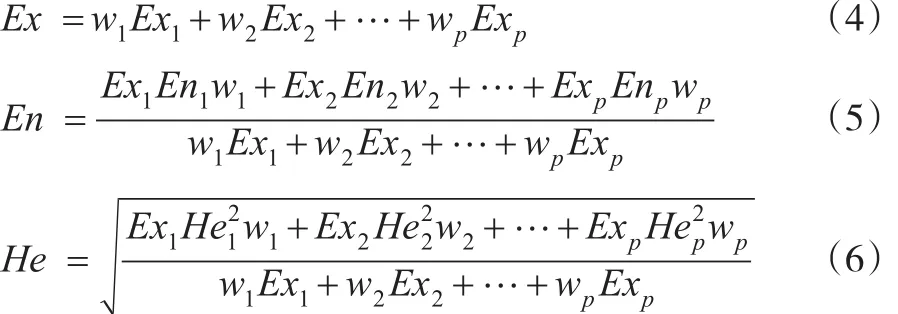
2.4 质量绩效指标的合成
综合云适用于将多个相互关联的语言值综合为一个更为广义的语言值,用来实现语言项从低层次概念到高层次概念的跃迁[10,11]。因此,本文应用综合云进行多指标的合成。根据式(4)至式(6)可以得到各个分指标的云模型,考虑指标的权重ν,这里m为指标个数,质量绩效评价的综合云模型计算为:

2.5 质量绩效水平评估
通过计算质量绩效综合评价云模型与评语集云模型的相似度,最终确定质量绩效结果的评价等级,评估企业的质量绩效水平。这里相似度δ的计算公式为[12]:
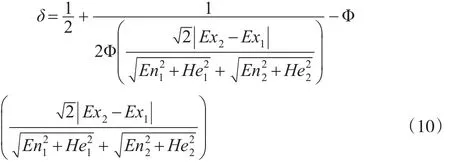
3 实证分析
某烫印材料制造企业为了测评自身的质量绩效水平,识别企业的优势与需改进的项目,选择10位专家组成测评小组,分别对表1质量绩效评估体系中各个指标项的实际水平进行评价。本文以专家对“战略部署”评分项的评估为例来说明上文的方法,并与企业在申报省长质量奖时的专家打分结果进行对比分析。
3.1 基于云模型的质量绩效水平计算
根据公司的自评报告,4.2b(战略部署)评分项可以进一步分解为如图2所示的指标体系。表3给出了“战略部署”评分项的专家评价结果。
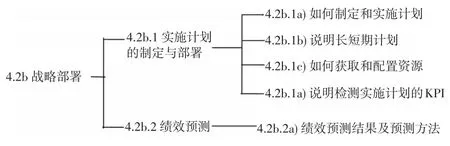
图2 战略部署指标
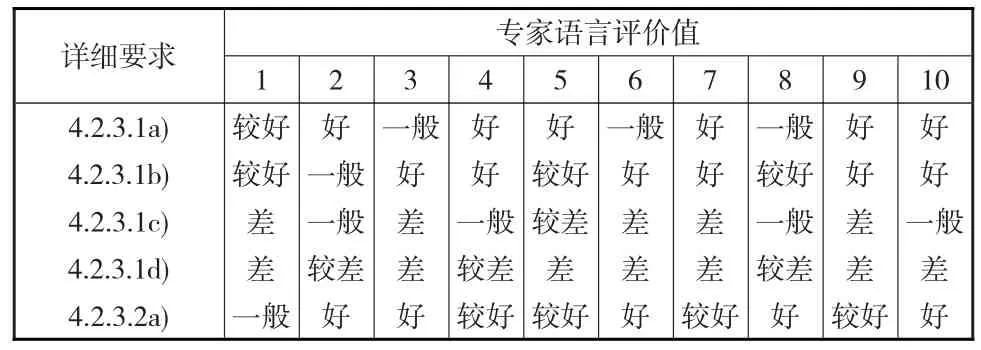
表3 专家对指标的语言评价表
假 定 指 标 4.2b 为 X1,4.2b.1 为 X11、4.2b.2 为 X12,4.2b.1a)至 4.2b.1d)及 4.2b.2a)分别为(X111,X112,X113,X114)、X121。根据专家对指标的语言评价结果,对照表1的评语集云模型,对专家的语言评价利用云模型进行转化,专家评价云模型如表4所示。
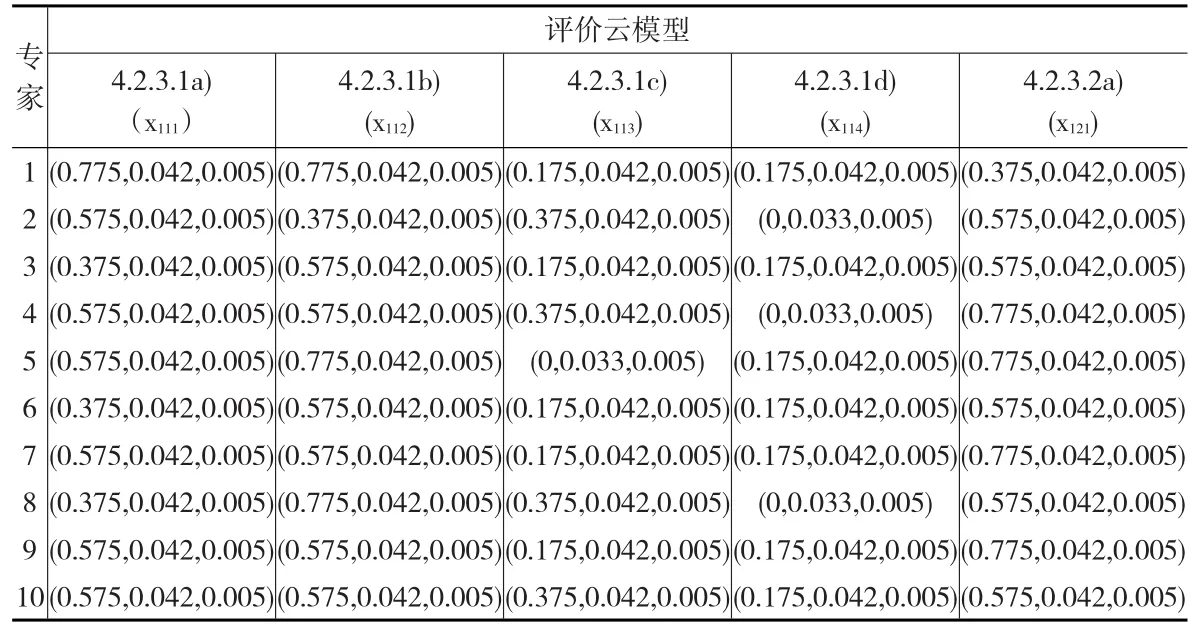
表4 专家评价云模型
假设每位专家的评价重要程度相同,由式(4)至式(6),利用浮动云对10位专家对某一指标的评价云模型进行合成,生成每个指标的评价云模型,指标云模型计算结果如表5所示。
在质量奖评审中,处在同一层次的属性被认为具有相同的重要性,即同一层次指标权重相同且满足假定4.2b.1a)至4.2b.1d)的权重分别为(0.25,0.25,0.25,0.25)。利用式(7)至式(9)对表5中各指标云模型进行合成,可得二层指标X11的评价云模型为(0.3775,0.168,0.0158),X12的评价云模型为(0.635,0.042,0.0158),进而得到“战略部署”类指标X1的综合评价云模型为(0.429,0.21,0.005)。

表5 各指标云模型
3.2 基于云模型的质量绩效评价与诊断
3.2.1 基于云模型的质量绩效结果分析
由式(10)计算综合评价云模型与评语集云模型的相似度,从表6可以看出,与综合评价云模型相似度最大是“一般”级评语云模型。图3中黑色用“#”表示的云模型代表“战略部署”评分项X1的综合评价结果,综合评价云模型的期望为0.429。
该企业在申报省长质量奖时,专家通过企业自评材料及现场评审,对“战略部署”类指标X1成熟度的最终评分为45%,即0.45;而本文计算的综合评价云模型的期望为0.429,与质量奖评审专家打分结果基本一致,证明了本文结果的有效性。

表6 评语云与综合云的相似度
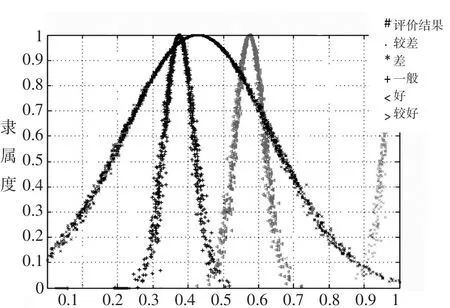
图3 质量绩效评估结果
3.2.2 基于云模型的质量绩效诊断分析
根据表5及图3,得出评分项X1(战略部署)的综合评价云模型的期望为0.429,综合评价的云模型的熵为0.21,可以看出评价结果较为分散,说明企业在某些分项指标上评分较低,存在不足之处。对“战略部署”的二层指标进行分析发现,X11(实施计划的制定与部署)的期望为0.3775,X12(绩效预测)的期望为0.635,分别属于“一般”与“好”的水平,由此可以识别出二层指标的弱项为X11(实施计划的制定与部署)。进一步分析构成X11的三层指标,可以发现,指标X111(如何制定和实施计划)、X112(说明长、短期计划)、X121(绩效预测结果及预测方法)的期望分别为0.535、0.615、0.635,都属于“好”的水平,表明该企业能够根据组织内外部环境的变化、通过与竞争者、标杆企业绩效的比较,适时调整战略目标及实施计划,缩小与标杆企业的差距;指标X113(如何获取和配置资源)、X114(说明检测实施计划的KPI)的期望分别为0.2375、0.1225,都属于“差”的水平,反映出了该组织的资源计划不能保证组织长、短期战略计划的实施,关键绩效系统没有涵盖相关方关键的战略部署,需进一步调整获取与配置资源的计划,完善关键绩效系统指标体系。通过上述分析,可以分层次诊断出企业在战略部署方面存在的主要问题,帮助企业识别需要改进的区域,促使企业的战略部署水平提升到更高的层次。
4 结论
GB/T19580标准以定性语言描述的形式给出,因此在质量绩效评估过程中,语言的主观性和不确定性处理是一个不可避免的问题。在企业绩效评估过程中,基于GB/T19580标准的质量绩效评估工具没有给出具体的指标测评和综合评价方法。因此,本文建立了基于GB/T19580标准的质量绩效评估指标体系,在此基础上,利用云模型中的浮动云和综合云进行质量绩效指标的测量与合成。通过计算云模型相似度更加精确地确定企业质量绩效的成熟度等级。本文建立的基于云模型的多层次多指标的质量绩效评价体系,每个分条款都有对应的评价云模型,不仅可以从整体上把握企业的绩效水平,也可以由分条款的云模型识别企业的强项与弱项,帮助企业进行诊断和绩效改进。同时,将质量绩效测评结果以图形和数据的形式呈现,使得计算过程更加的客观、准确、直观,从而为组织测量质量绩效水平并实现绩效的持续改进提供了有效工具。
猜你喜欢
计算机应用(2022年2期)2022-03-01 12:35:06
四川文学(2020年11期)2020-02-06 01:54:52
中国盐业(2018年20期)2019-01-14 01:18:44
新西部·中旬刊(2016年10期)2017-05-09 21:20:07
现代营销·学苑版(2016年10期)2016-12-12 13:39:54
中国市场(2016年30期)2016-07-18 05:17:28
宠物世界·猫迷(2016年3期)2016-04-23 19:54:06
少儿科学周刊·少年版(2015年3期)2015-07-07 21:10:04
散文百家(2014年11期)2014-08-21 07:16:36
语文教学与研究(2014年9期)2014-02-28 21:55:06
