
上海写字楼租金预测探究
2018-12-20 08:10:16李贞良曹布阳
软件 2018年11期
李贞良,曹布阳
上海写字楼租金预测探究
李贞良,曹布阳
(同济大学 软件学院,上海 201804)
本课题研究的问题核心点是如何有效地利用写字楼内部及周边环境的时空数据来对写字楼的整体规划进行评估,由于规划的优劣在一定的程度上能在租金高低上反映出来,我们将着重于通过对写字楼的租金预测,对写字楼及周边地块规划进行评价和建议。文章从数据获取、数据处理、影响因素分析、建模分析多个方面进行介绍。本文也探讨把此方法推广到对于一般商业地块的分析中去的可能性。
商业地产;预测;机器学习;数控数据
0 引言
人近些年来,随着经济的高速增长和第三产业的蓬勃发展,商业写字楼已经成为了国民经济发展的重要力量和主要空间形式。写字楼对企业来说,与企业共生共荣,实力企业入驻高端写字楼,好的写字楼也能帮助企业发展[1]。对于城市经济来说,写字楼承接了城市的经济发展面貌。正如国贸商务区之于北京,天河商务区之于广州,陆家嘴之于上海[2-3]。在一定程度上,写字楼可以视为城市经济地位的风向标。这些写字楼代表着城市的鲜明形象,同时也逐渐成为城市经济发展的一个重要载体,蕴藏着巨大的经济能量,创造着丰富的物质财富,见证着城市的日益繁荣发展。
随着新写字楼的规划和建设,投资回报率会摆到议事日程上。自然地,开发商和管理人员会十分关心几个问题:一旦写字楼开发之后,出租率和空置率大概是多少?采取什么样的设施配备,可以让租金提高?或者采用何种方案,才能使得整体经济效益最大化?
因此设想,如果能够在规划期内,根据建筑指标和以及周边时空数据提前预估写字楼楼房的大致出租情况包括可能的租金,那么会在在很大程度上为决策者和规划者提供坚实的决策依据,不仅能提升经济利益和社会效应,同时还能帮助开发商和管理者及时调整写字楼的规划战略和决策[4-5]。受此启发,本文结合上海及其他地区众多写字楼盘数据,基于其本身及周边时空数据提出了对写字楼规划评估和租金预测的相关研究。
在房屋售价和租金的预测方面,回归预测的场景十分适合与当下热门的机器学习相结合,而机器学习算法经过若干年的演化和改良,已经分化出了较多实际的应用场景[6]。在这些场景中,众多算法在回归和预测方面也有着效果出众的实际运用,如较为常用且成熟决策树,随机森林,支持向量机等等[7-9]。这些算法对于不同的数据量、数据特征、具体场景都会有不同的预测表现,因此需要根据自身的情况来对算法对比和调整。例如比较知名的“波士顿房价预测”案例[10],利用了UCI公开的波士顿房价数据集进行建模预测,该数据集于1978年开始统计,共506个数据点,涵盖了麻省波士顿地区不同的郊区房屋14种特征的信息。案例将房价数据分析与机器学习相结合,建立了一个简单的基于房屋配置的房价预测模型,并利用该模型对一些新配置房屋进行了具有参考价值的定价评估。
作为在写字楼租金预测方面的实际应用,除了理论基础,还需要进行数据收集与清洗、影响因子分析和选择、算法选择与调参优化等一系列的工作,探索出一条科学可行的方案路线。
本文通过“研究方法”、“计算实验”、“结果分析”等章节来介绍这一方案路线。在“研究方法”这一章节中,步骤分为了“数据收集清洗”、“数据相关性分析”和“建模分析”;在研究方法确立后,“计算实验”章节介绍了实验相关过程和数据;最终在“结果分析”章节中对实验结果进行了归纳和总结。
1 数据收集
本研究为数据驱动型的,故需要一定数量的相关数据支撑我们的研究。在前期的数据准备阶段,所收集的数据主要分为两类:写字楼租金信息和写字楼配套属性数据。
由于租金信息的波动性和不确定性,受市场变化影响较大,因此需要找到一个数据更新及时、数据量充足,同时准确度较高的数据来源。在多方面对比之后,决定从目前比较主流的一些写字楼出租网站上获取数据。由于当下租赁网站的发展迅速,企业商户和个人越来越重视线上的租赁渠道,相比线下租赁,线上网站十分便捷且信息公开。同时,对于我们的研究课题而言,租赁网站有如下几个优点:
(1)数据更新及时,可以拿到实时变动下最新的写字楼出租信息;
(2)写字楼覆盖较广,在设定了上海市范围之后几乎所有有出租信息的写字楼都能获取到相应 数据;
(3)由于直接的供需关系,价格相对贴近真实的成交租金,数据较为可信。
另外,对于一些大型的租赁网站来说,网站上还展示了写字楼的一些配套属性数据,如建筑等级,建成时间,物业费,地理位置等等。通过对该类网站上的数据进行获取之后即可同时获取租金信息和一些写字楼基本的数据,能够较为高效地扩充所需数据和属性。
在对租赁网站的选择上做了进一步的调研和分析之后,在众多主流网站中,我们选择了安居客(https://sh.xzl.anjuke.com/loupan/)的写字楼楼盘数据作为参考,通过所开发的爬虫工具,可以获得有关的写字楼出租的信息,例如某一写字楼的网页展示数据如图1。
从上面所列出的众多属性中,我们可以获取到诸如建筑等级、电梯数量、物业费、车位数等对租金大小可能产生影响的属性信息,以帮助我们进行模型分析。
同时,针对最重要的租金信息,在调研之后发现,如果使用单一出租广告的租价或是部分信息平均值来进行代表的话,很容易因为信息发布人的随意标价或是为了吸引客户过低标价的行为导致数据不准确,因此需要找到一个具有充足数据且做了平均租金处理的数据来源,消除个别特异租金造成的误差和影响。比较幸运的是,有另外一个网站:好租网(https://www.haozu.com/sh/zuxiezilou/)基于每个写字楼所有目前的出租信息提供了平均租金,结合此网站所提供的信息,我们可以获得更为精准的写字楼的租金数据。其统计方式如图2。
数据获取:本课题所有数据获取方式均为到相关网站进行自动化的数据爬取,限于篇幅,同时爬取过程也不是本研究课题的重点,故省略数据抓取的详细步骤。
除了基础属性,地理位置作为一项十分重要的空间属性,能够在很大程度上决定写字楼的租金高低[11]。但是关于一个写字楼的地理位置和区位情况较难量化,因此我们采取了对于写字楼周边的不同种类POI(Point of Interest)数量及类型进行加权计算,近似代替一个写字楼的地理位置热度。例如,根据写字楼周边一定范围内的地铁、酒店、停车场、商场和医院等POI数量加权后得到一个地理位置特征值,作为空间属性的量化指标。
对于写字楼周边的POI数据可以通过百度地图POI接口批量检索后获得。
有了基础属性,空间位置属性,平均租金之后可以通过写字楼名称将写字楼所有信息关联起来:写字楼名称-平均租金(好租网)-基础属性(安居客)-空间位置/POI数量(百度地图POI)。
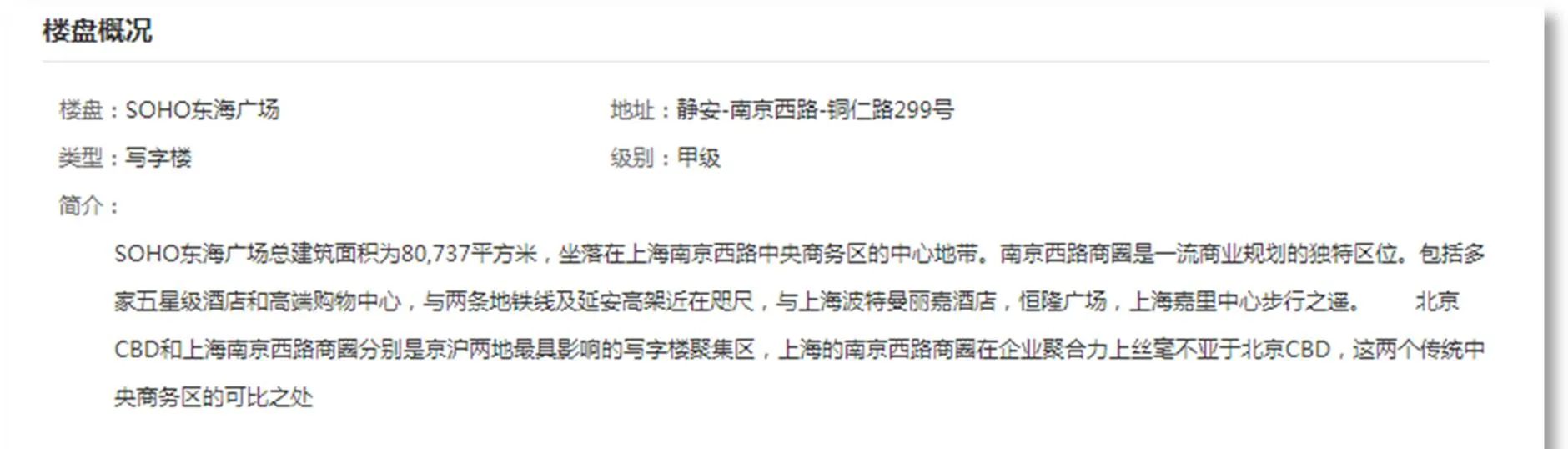

图2 好租网写字楼租金情况网页展示
数据录入需要进行数据的清洗。过程大致如下:
(1)将字符类型的字段量化后转为数值类型,如建筑等级:甲乙丙级,将其对应为数值的3、2、1。
(2)出现属性值为空(爬取时网站上缺少该属性)的情况时,如果该属性为空的样本数占总体样本超过15%,则在所有样本中删除该属性,该属性不加入模型分析;如果超过5%,则去除缺少该属性的样本;如比例在5%及以下,缺失该属性的样本对整体影响不大,则将缺失该属性的样本中该属性值置位0。
(3)对数值异常进行处理,如租金超过50元/m²×天,等于0元/m²×天的样本,都当做异常直接去除整条样本。尽可能排除噪音点和异常点对模型的干扰。
2 相关性分析
在数据收集阶段,我们收集到很多写字楼相关属性,这些属性是主观判断下认为的写字楼租金的影响因素。但是在这些属性中,也有影响力的高低之分。因此我们应该在最终的预测模型中进行不同属性权重的分配。
上文中说到,使用写字楼周边不同POI数据进行总和计算,以此来近似代替写字楼的周边区位、便利性、以及通勤优势等。但是不同类别的POI其实对于写字楼租金的影响也是不同的,从直观上我们可以做出猜测,对于办公写字楼来说,对周边的公园和医院等数量不是十分敏感;同时写字楼周边的商店数量对其租金的影响,远远没有写字楼短距离内的地铁站和地铁线路数量对租金的影响大。因此,对于写字楼的区位优势我们不能简单用POI加和代表,而是需要对不同POI设置权重,建立模型进行计算。
要计算每种POI的权重,就需要分析每种POI和租金信息之间的相关性。
在数据收集过程中,我们获取了写字楼周边的以下几类POI数量:酒店数量(hotel)、医院数量(hospital),商场数量(mall),公园数量(park),商店数量(store)以及地铁站以及站内所含线路之数量(underground)。
根据每种POI数量和其对应的写字楼平均租金,作出可视化的数据分布图。

图3 写字楼周边各POI数量与租金的相关性分析
根据经验可以得出,写字楼周边POI数量应该和写字楼租金成一定线性关系,例如周边便利店、商场越多,代表地区越繁华,写字楼租金就越高;而周边通勤的地铁线路数量越多,代表交通越便利,则租金也会越高。而根据图像显示,也可以看出POI数量和租金成一定的正比关系。因此作出相关性的假设:每类POI数量和租金保持大致的线性关系,即:POI数量增多时,相应的租金也会有所增加。
因此,要找到这个线性关系(根据经验判断),我们将对对数据点进行线性回归。线性回归方式采用最小二乘法,即假设拟合直线形如:
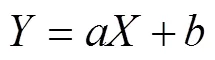
其中,X代表每类poi的数量,Y代表租金。a,b为该拟合直线的系数。
最终拟合结果如图4。
我们最终的目标是找到该类POI与租金的相关性强弱。从上图中我们可以分析得知,如果一个POI和租金十分相关的话,那么点分布应该更靠近拟合的直线(图中红线);相反的,如果POI与租金相关性较弱或是没有直接相关性,那么点分布应该更加离散。
评估数据点到直线的离散程度可以使用每个点到拟合直线的距离平均值来评估,这个距离平均值即是回归分析常用的评价指标:均方误差MSE(Mean Squared Error)。

图4 线性关系下各POI数量与租金的拟合直线
通过计算,得到各个属性数据点到回归直线的均方误差MSE如下:
表1 各属性MSE表

Tab.1 MSE attributes
根据MSE越大相关性越小的原则,得到MSE与相关性的反比关系。根据以上特点,我们可以定义一个描述某一写字楼区位优势和地理位置热度的量化指标,令其为f(x),则该量化指标计算方式如下:
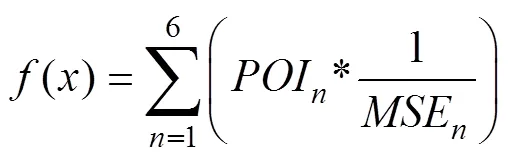
其中n表示上述6类POI中的第几类。
由上述表达式我们可以得到一个由多个POI共同影响的写字楼区位优势综合评价。有了这一量化指标,我们就可以将写字楼的区位优势作为一个租金的影响因子,投入模型进行分析。
3 建模分析
对其余属性影响权重的确定,本质上就是对于写字楼所有相关数据和其租金进行回归分析,建立输入(各项属性值)和输出(租金)之间的关系。对这样典型的回归问题来说需要选择一个合理的自学习回归模型,也就是在大量数据中通过训练自动调整参数的机器学习模型。
在模型选择上,采用了当下回归预测问题广泛采用,同时效果较好的“支持向量机”-SVM(Support Vector Machine)[12]。选择SVM有以下一些理由:
(1)在本问题中,收集到的写字楼属性较多,在高维的特征空间中SVM比其他回归算法表现 更好。
(2)SVM能够处理非线性特征的相互作用。
(3)因为本课题收集的写字楼数据均来自网络,可以预想有部分数据其实是不准确的,容易成为噪音点。该类噪音点因为属性较多也较复杂,不容易在数据清洗阶段识别出来去除,因此需要模型 有较好的抗噪音能力。而SVM相比其他回归模型有较强的鲁棒性,模型建立后的泛化能力也更好。
(4)由于SVM是借助二次规划来求解支持向量,而求解二次规划需要大量的存储和计算,因此SVM计算效率是较为低下的,在大量训练数据面前比较吃力。但是在该课题中,网站上上海写字楼数量有限,数据总量不大,样本数不超过1000个,因此带来的运算代价在可接受范围内。
4 计算实验
SVM能够解决分类和回归问题,在本课题中主要使用支持向量机回归SVR(Support Vector Regression),也就是找到一个回归平面,让一个集合中所有样本点到该平面的距离最近。
进行回归训练时,需要将数据分为训练集和测试集。在前文提到的数据收集处理阶段我们对入库的写字楼数据进行过清洗,包括对数据格式进行统一规范,对一些租金、属性值超出正常范围的数据进行去除。最终剩下有效数据量为890条。我们对有效数据进行训练集和测试集划分:95%数据作为训练集,5%数据作为测试集。
在训练数据中,每一个样本输入包含的属性有:
表2 样本属性表

Tab.2 Sample data attributes
在进行SVR训练时,需要调整参数达到最优效果,在根据数据特点和训练结果进行调整之后,得到一个回归模型。SVR具体参数设置如表3。
带入测试集数据之后,得到一组预测的写字楼租金。与测试集实际的租金对比效果如图5。
将每个预测租金点和实际租金点绘成折线图进行直观的效果对比,如图6。
为了验证SVR模型的有效性,以及针对本课题数据特点拥有的独特优越性,还用相同的训练集和测试集数据用其他模型进行了预测对比。例如在进行效果对比时使用了“决策树回归”来进行模型训练和预测。在决策树回归过程中经过数次尝试得到最佳参数设置:调整训练最大深度(max_depth),即建立树时从根节点到叶子节点的路径长度,将值设置为5。决策树回归模型的最终训练结果如图7。
表3 SVR参数设置表

Tab.3 Parameter settings for SVR

图7 决策树回归模型预测租金与真实租金进行柱形图对比
对应的折线图如下:

图8 决策树回归模型预测租金与真实租金进行折线图对比
同时计算SVR模型和决策树回归模型下,预测集和测试集租金之前的差距。我们依然使用均方误差:MSE来评估:
表3 SVR和决策树回归预测结果均方误差表

Tab.3 MSE for DecisionTree Regression and SVR
通过图形和MSE指标都可以看出,同样在调整参数之后SVR模型预测效果优于决策树回归。
5 结果分析
简单从结果上来分析的话可以看到,在一些租金值较为极端的情况下预测效果较为保守。在一些租金较高点或者较低点预测不够准确,分析如下:
(1)数据训练样本不够:目前在数据清洗之后上海写字楼有效数据还不足900条,对于成熟可靠的模型来说来远远不足。之后可尝试其他地区的写字楼楼盘,扩充训练集。
(2)数据本身质量不足:一些写字楼发布人可能对发布的写字楼租金随意标价。为了吸引浏览量刻意降低或者抬高标价,导致能够获取到的标价和真实成交价格有差距,最终模型训练效果不够好。同时,对于写字楼其他属性来说也有可能存在部分错误信息,影响了训练结果。课题数据来源过于依靠网络平台,包括写字楼各项数据,POI数据等都来自网站爬取或者网络查询,数据质量不可控。之后可以寻找更加正规或官方的渠道,尽量让各个样本的属性接近真实值。
(3)写字楼的现有属性利用不足:例如不同种类的POI数据,只是用来简单的进行加权和,对于本身POI价值来说挖掘不够。例如地铁站数目其实可以极大影响到写字楼租金价格,但是在计算时只是简化成一种普通的POI指标,作为POI加权和的一部分。同时,一些写字楼的入驻企业信息也有收集,但是因为量化较困难在此次课题中没有作为属性加入训练。
(4)影响租金的属性收集不全:例如对于写字楼的空间属性来说,简单使用一些POI指标进行加权和来代表其实是不准确的,并不能完美的反映一个写字楼地理位置热度信息。除了POI外,地理信息还包括了写字楼周边通勤,交通流量以及高峰拥堵程度等。同时,写字楼租金还会受整个产业园区的整体租金水平、绿化、物业等等因素影响,这些属性在本课题中都没能收集加以考虑。
但是总体上来说,模型对于不同样本之间的预测结果与真实值保持了一致的变化趋势。同时,预测结果在一定范围内是可靠的,可以作为写字楼开发商和出租方租金定价的范围参考。
6 总结
作为本课题来说,旨在尝试一种方便、快捷并且智能化的地产分析评估方式,用自动化爬取的数据获取方式代替传统的实地走访或是人工收集录入,同时在能力范围内尽可能地去扩充写字楼的维度信息,将这部分维度信息作为影响其租金定价的影响因子,最终通过机器学习等一系列智能化的建模分析方法来对影响因子与租金间的因果关系用模型进行了归纳和描述,最终达到了预测估计的效果和目的。在文章中我们尝试了一个数据来源公开且方便获取、预测结果有参考价值的写字楼租金学习、预测的技术方案。今后也可以在此基础上继续打磨,对上述不足之处作出改进,尝试对模型参数进行调优,并尝试更多的机器学习模型并作出结果对比,分析利弊,把写字楼预测模型做得更加健壮和并获得更为精确的结果,产生更大的实用价值。
[1] 葛大永. CBD写字楼城市经济价值探讨[J]. 科技信息, 2009(33): 674-675.
[2] 陈晓婷. 上海甲级写字楼市场浅析[J]. 才智, 2010(12): 31.
[3] 中华写字楼网. 2016年上海甲级写字楼市场年度报告[J/OL]. (2017-5-16) http: //news.officese.com/2017-5-1/153226. html.
[4] 章辉. 如何确定旅店的出租率?[J]. 商业经济文荟, 1985, (01): 55-56.
[5] 茹茜. 提高我国社区商业街出租率的对策[J]. 内江科技, 2011, 32(09): 142+85.
[6] Glaeser E L, Nathanson C G. An extrapolative model of house price dynamics[J]. Journal of Financial Economics, 2017.
[7] 张寅. 用于回归预测的高斯过程模型研究[D].河北工业大学, 2014.
[8] Chi Zhang, Haikun Wei, Xin Zhao, Tianhong Liu, Kanjian Zhang. A Gaussian process regression based hybrid approach for short-term wind speed prediction[J]. Energy Conversion and Management, 2016.
[9] 张伟, 熊伟丽, 徐保国. 基于实时学习的高斯过程回归多模型融合建模[J]. 信息与控制, 2015, 44(04): 487-492+498.
[10] Boston Home Prices Prediction and Evaluation[J/OL]. https: //www.ritchieng.com/machine-learning-project-boston-home-prices/
[11] 龚健雅, 李小龙, 吴华意. 实时GIS时空数据模型[J]. 测绘学报, 2014, 43(03): 226-232+275.
[12] Yueming QI. GA-SVR Prediction of Failure Depth of Coal Seam Floor Based on Small Sample Data[A]. CBEES. Proceedings of 2013 2nd International Conference on Geological and Environmental Sciences (ICGES 2013)[C]. CBEES: 2013: 7.
Research on Rent Prediction of Shanghai Office Building
LI Zhen-liang, CAO Bu-yang
(School of Software Engineering, Tongji University, Shanghai 210044, China)
The concept of the research is how to effectively use the office buildings’ time and spacial data to evaluate the construction plan of buildings. Since the quality of the construction plan can be approximately reflected in the rent price level, we can focus on evaluation and suggestion for construction plan of these office buildings through rent prediction. The article introduced the research steps of data acquisition, data processing, influencing factor analysis and modeling analysis. This article also explored the approach to apply these research steps and prediction model to the analysis of general commercial estates.
Commercial estate; Prediction; Machine learning; CNC data
TP181
A
10.3969/j.issn.1003-6970.2018.11.036
李贞良(1993-),男,研究生,主要研究方向:机器学习与大数据;曹布阳(1958-),男,教授,主要研究方向:机器学习与大数据。
李贞良,曹布阳. 上海写字楼租金预测探究[J]. 软件,2018,39(11):170-177
猜你喜欢
消费电子(2022年4期)2022-07-18 09:04:02
消费导刊(2021年9期)2021-07-12 15:09:55
作文周刊·小学一年级版(2021年40期)2021-01-04 17:07:21
房地产导刊(2020年5期)2020-06-24 06:14:10
经济管理文摘(2020年7期)2020-02-28 04:35:39
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:42
中国房地产·综合版(2019年12期)2019-01-06 06:37:11
小猕猴智力画刊(2016年6期)2016-05-14 21:40:48
华人时刊(2016年13期)2016-04-05 05:50:12
现代企业(2015年5期)2015-02-28 18:51:08
