
规则半自动学习的概率软逻辑推理模型
2018-12-14 05:31赵旭剑杨春明
计算机应用 2018年11期
张 嘉,张 晖,赵旭剑,杨春明,李 波,3
(1.西南科技大学 计算机科学与技术学院,四川 绵阳 621010; 2.西南科技大学 理学院,四川 绵阳 621010;3.中国科学技术大学 计算机科学与技术学院,合肥 230027)(*通信作者电子邮箱zhanghui@swust.edu.cn)
0 引言
2013年,美国马里兰大学的Kimmig等[1]提出了概率软逻辑模型(Probabilistic Soft Logic, PSL)。与马尔可夫逻辑网(Markov Logic Network, MLN)及其他统计关系学习方法类似,PSL也使用加权的一阶逻辑规则对问题中的依赖性进行建模。但是和MLN不同的是,PSL表示的逻辑关系是用概率的形式在区间[0,1]中使用软真值,而不是用布尔值0或1来代表域中的原子,这使得PSL的推理成为连续的优化问题[2]。此外,作为一种基于声明式规则的概率模型,PSL在解决新的领域问题时,可灵活添加有益的先验领域知识作为规则输入,并且其声明式规则对于机器和人都是可以理解的,模型构建后更易于人为处理。
然而,PSL面临的一个巨大挑战是所需的声明式规则完全由人工生成,这种规则构建方式往往非常昂贵,而且人工获取的知识由于每个人对事物认知的偏差以及问题本身的多变性,这些知识难免会包含不正确的信息,这些不正确的信息可能会增大推理模型的不确定性。
本文引入规则自动提取的方法,提出一种规则半自动学习的概率软逻辑推理模型(C5.0-Probabilistic Soft Logic, C-PSL),它将数据驱动和知识驱动的方法相结合,利用C5.0算法从数据中提取规则,再将这些规则转化为适应概率软逻辑模型的形式,同时辅以决策树等算法将无法使用的人为常识或知识作为概率软逻辑模型的输入进行建模。通过在两个真实数据上评估本文提出的模型,结果表明,所提模型比没有规则学习的PSL和C5.0算法能获得更高的精度。
本文的主要工作为:1)提出了一种PSL规则自动挖掘方法,它可以大幅减少人工工作,同时提高了规则建立的科学性;2)通过手工定义规则来优化模型,让模型具有处理关系数据的能力,而这种能力是决策树和大多数其他机器学习算法所不具备的。
1 建立规则半自动学习的概率软逻辑模型
1.1 概率软逻辑相关研究
近几年,概率软逻辑(PSL)已经被广泛应用于情感分类、实体识别、知识图谱构建、链路预测和图像处理等诸多问题[1]上。
Tomkins等[3]基于时序数据手工定义了多种属性,将PSL应用于家用电器的能源消耗分解上,获得了不错的效果,为降低能耗和资源浪费找到了可行的入手点,该方法能轻易合并各种信息,但其准确性需要大量的手工整合知识作为支撑,这使得该方法很难移植到其他问题上; Huang等[4]将PSL用于建立社会信任模型,通过定义大量规则对社会影响的传播建模,验证了人们在生活问题上比起相信同事更相信家人,在工作问题上更相信同事给出的职业建议的直觉,该方法使用无监督和聚类方法进行建模,然而其模型并非都是PSL规则输入; 在图像修复问题中,LINQS团队基于Poon等[5]的工作,使用PSL对图像进行像素级的修复,表现出比和积网络(Sum-Product Network, SPN)更快的速度,然而在他们建立的模型中,PSL规则数量多达数万条,需要耗费难以估量的人工成本; Fakhraei等[6]通过药物相似性特征使用PSL构建模型,预测药物之间的相互作用,然而方法中基于经验所构建的规则的实用性很难被验证; Pujara[7]通过知识图中的关系特征使用PSL构建了实体识别的通用模型,然而对于大规模数据来说关系特征主导的规则很难被全面定义。
由以上描述可以看出,PSL具有强大的适应性,其研究和应用已经横跨多个领域,然而到目前为止,PSL的相关工作几乎都是基于人工去定义每条规则,其工作量将随着问题的复杂性增大而变得不可估计。本文方法试图解决上述问题,和上述方法一样,本文依然使用PSL作为建模基础,以保留推理的灵活性和稳定性;不同的是,本文的大部分规则由C5.0算法学习生成,以减少人工工作量。
1.2 概率软逻辑
1.2.1 PSL语法
PSL中的规则组成如下:
P1(X,Y)∧P2(Y,Z) >>P2(X,Z):weight
(1)
其中:P1和P2被称为谓词,用于定义随机变量X、Y和Z之间的关系;weight表示权重,代表每条规则在推理中的重要程度[2]。例如,在本文中,Semester(ID,SE2)表示要判断的数据为编号为ID的学生在SE2这一学期的成绩,GoodScore(ID,SE1) 表示该学生在SE1这一学期成绩合格,那么,根据Semester和GoodScore两个谓词的组合可以将该学生在SE2这一学期成绩合格的概率表示出来。
1.2.2 PSL理论基础
PSL中闭原子概率取值为[0,1]内连续的软真值,表示为I(a),逻辑规则r成立的概率记为I(r),通常使用卢卡西维兹(Lukasiewicz)逻辑来计算I(r),Lukasiewicz逻辑可以表达为式(2)~(4):
I(l1∧l2)=max{I(l1)+I(l2)-1,0}
(2)
I(l1∨l2)=min{I(l1)+I(l2),1}
(3)
I(l2)=1-I(l1)
(4)
PSL中一条规则r可以被描述为rbody→rhead,当I(rbody) ≤I(rhead),即I(r)=1时,这条规则被满足;否则,通过计算距离满意度d(r)的方式来衡量逻辑规则被满足的程度,d(r)计算方式如式(5):
d(r)=max{0,I(rbody)-I(rhead)}
(5)
例如,有一个集合I= {friends(a,b)→1, like_eat(a,c)→ 0.9, like_eat(b,c)→0.3},可以计算出逻辑规则friends(a,b)∧like_eat(a,c)→like_eat(b,c)的距离满意度:
I(friends(a,b)∧like_eat(a,c))=
max{0, 1+0.9-1} = 0.9
d(r)=max{0,0.9-0.3} = 0.6
使用d(r),PSL定义了概率分布对所有闭原子的解释概率值:
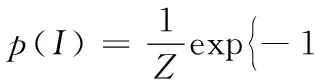
(6)
式(6)中:Z是归一化常数,λr是规则r的权重,R表示所有规则的集合,p为损失函数,PSL将寻求具有最小满意距离d(r)的解释,并尽可能地使其满足所有规则。
1.3 规则半自动学习的PSL模型
在机器学习中,规则学习(rule learning)是从训练数据中学习出一组能用于对未知结果数据进行推理判定的规则。得到的规则通常可写成“如果-那么”的形式。
在众多能进行规则学习的算法中,决策树算法提取的规则具有易于理解、能直观解释等特性,而其中又以C5.0算法为最优[4],因此本文使用决策树C5.0建模规则挖掘模块。除规则挖掘模块之外,规则半自动学习的概率软逻辑模型还包含规则优化、手工规则定义等模块,模型构建结构如图1所示,模型通过C5.0算法对输入的训练数据进行规则提取,学习得到的规则在规则优化模块进行优化和格式转换,PSL将学习得到的规则和手工规则整合组成最终的推理模型。接下来,将详细介绍如下几个模块的构建方式:
规则提取 运用C5.0算法,通过训练数据进行规则学习;
规则优化 讨论规则优化策略,改善模型质量;
人工规则 手动方法生成规则,辅助优化模型;
推理模型 权重学习与推理。
1.3.1 规则提取
C5.0算法是C4.5算法的改进版本,处理数据时可采用Boosting方式获得更高的准确率,C5.0算法在面对输入字段较多和数据遗漏情况时非常稳健,运行中占用的内存资源也较少。
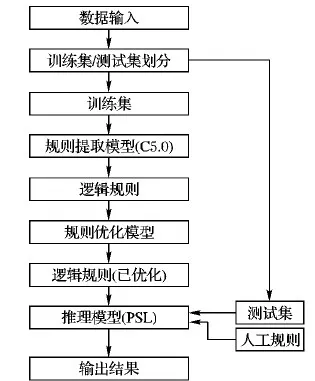
图1 规则半自动学习的概率软逻辑推理模型
1.3.2 规则优化
1) Boosting选择。
使用Boosting在多数情况可使C5.0算法分类效果更加优异,然而,Boosting所带来的一个弊端是模型产生的规则数量过于庞大,基于本文所使用数据,对使用Boosting和不使用Boosting的情况进行了实验讨论,结果将在第2章展示。
2) 同类规则合并。
通过规则挖掘模块提取出的众多规则中,有很大一部分规则具有由相同属性组成的结构,如表1所示,三条规则都包含Librarynum、Classroom、Semester、Booknum四个属性。
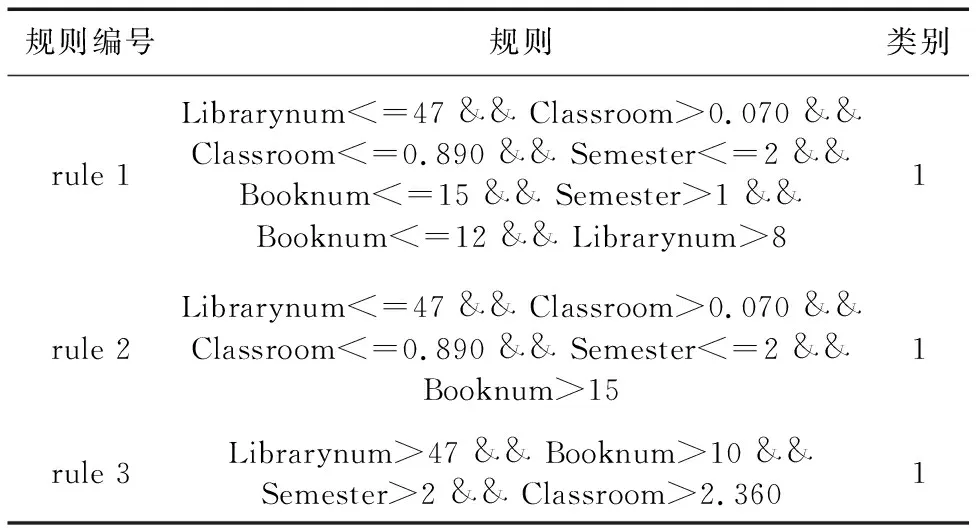
表1 学习得到的规则中同属性规则示例
在PSL模型中,运算量会随着规则数的增多而变大,对于这一类同属性规则,本文可以将其定义为PSL的ExternalFunction函数,并和谓词进行组合,从而转化为一条PSL规则作为模型输入:
Librarynum(ID,SE,LI)∧Classroom(ID,SE,CL)∧
Semester(ID,SE) ∧ Booknum(ID,SE,BO) ∧
Lunction(LI,CL,SE,BO) ⟹ GoodScore(ID,SE)
1.3.3 手动规则
人类认知的知识对于事物的判断起着至关重要的作用,机器学习算法在很大程度上依然无法完整模拟人类的推理和决策过程。本节将阐述根据人类知识手动建立规则的过程,所有的举例规则均已用在实验中。
1) 关联规则。
对于大多数机器学习算法,通过数据之间的关联关系进行推理是很难实施的,而对于PSL来说却容易得多。
①直接关联。
问题举例1 已知A同学在1、2、3三个学期的大量属性,推断A同学在2、3学期的成绩状况。
通过1.3.1节得到的规则模型可以根据学生属性推断A学生的成绩状况,但是推断结果彼此无关,一般的,我们认为:如果已经推断出A同学在第1或2学期成绩合格,那么有很大可能A同学在第三学期成绩也合格。但是可惜的是,此时规则学习模型得到的规则无法推断到这一步,所以需要人为引入这条规则:
Semester(ID,SE1) ∧Semester(ID,SE2) ∧
资源优化 我国高校以院系为单位,一个学院一般设置几个不同专业,因此,学院就需要建设几个相应的专业实验室。与基础实验室相比,专业实验室定位更为精准,课程安排严格按照理论课的进度,但是这也局限了专业实验室的使用率,资源不能被充分利用,在学院内部较难实现资源共享。专业实验室因其特殊性,一方面需要很多仪器满足实验教学;另一方面面向学生较少,仪器利用率并不高,甚至导致一些仪器被闲置,造成资源浪费[7]。另外,不同专业实验室中不可避免会有设备重复的情况,尤其是一些大型贵重仪器,重复性高也是一种资源浪费。鼓励专业实验室开放,即是避免资源浪费,以进一步提升资源共享。
GoodScore(ID,SE1) ⟹ GoodScore(ID,SE2)
其中:ID表示学生编号,SE1、SE2表示学期,GoodScore(ID,SE1)表示学生在SE1这一学期成绩合格,GoodScore(ID,SE2)即为该学生成绩合格的概率输出。
②隐性关联。
问题举例2 已知A同学成绩优异,某学期A同学的图书馆借书类型为(G G G G H H I I O O O TP TP TP TP),B同学在图书馆的借书类型为(H I I I I O O TM TN TP TP TP),能否一定程度上推断本学期B同学的成绩合格情况。
通过观察发现A、B两同学看书的类型有很大程度上的相似性,通常人们认为两个人的看书(接受的知识)类型一致可能会导致成绩水平也趋于一致,因此可以把两个学生看书类型的相似度作为成绩关联的隐性属性。本文通过计算余弦相似度来评判两学生看书类型的相似度。
两同学看书类型的词频向量为:
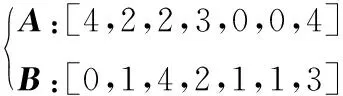
A、B向量夹角的余弦可以表示为:
(7)
得到A、B的余弦值cosθ= 0.707 106 781 186 547 6即为两同学看书类型的相似度。表示为PSL规则为:
Booktype(ID1,SE,BOTY1)∧Booktype(ID2,SE,BOTY2)∧
Similarity(BOTY1,BOTY2)∧GoodScore(ID1,SE) ∧
(ID1-ID2)) ⟹ GoodScore(ID2,SE)
其中:Similarity(BOTY1,BOTY2)为余弦相似度计算函数,(ID1-ID2)表示两个学生不是同一个人。类似的,还可以对学生数据中其他属性进行相似度计算。
2) 简单知识规则。
在已有规则基础上,本文还可以再增加一些简单的常识。如:
课余学习时间越长,学生成绩可能越好:
STUDYTIME(S,St) ∧ STUDYTIMEJUDGE(St) ⟹
GoodScore(S)
谈恋爱可能会影响学习:
ROMANTIC(S,Ro) ∧ ROMANTICJUDGE(Ro) ⟹
家庭关系越好越可能学习好:
FAMREL(S,Fa) ∧ FAMRELJUDGE(Fa) ⟹
GoodScore(S)
缺课次数越多越可能成绩差:
ABSENCES(S,Ab) ∧ ABSENCESJUDGE(Ab) ⟹
经常上网可能影响学习:
INTERNET(S,In) ∧ INTERNETJUDGE(In) ⟹
GoodScore(S)
这类规则对推理结果没有决定性影响,但却能让推理结果的表达形式变得更加符合常理,例如:在不添加这些规则的情况下,推断某同学S成绩合格的概率可能为GoodScore(S)=0,这很难理解,在添加规则后GoodScore(S)=0.235,虽然该同学依然被分到成绩不合格类,但却拥有了一个成绩合格的概率,这更符合人类正常的思维方式。
1.3.4 规则优化
1) 推理。
PSL模型提供了最大概率推理(Most Probable Explanation,MPE)[2]和边际概率推理两种方法,前者是通过数据推断逻辑规则包含原子的最可能概率值,后者是计算原子的概率取值区间。本文采用MPE推理机制。由于概率取值采用[0,1]内的连续值,使得MPE推理转化成求最优解的凸优化过程。
2) 权重学习。
对于学习得到的规则,根据每条规则的置信度分配其在PSL内构建时的权重,如有X、Y、Z三条规则,它们的置信度分别为0.7、0.8、1.0,在将它们转化成PSL规则时,可以将其置信度同时扩大多倍作为其权重。然而对于手工定义的规则,则需要进行权重学习。
在PSL模型权重学习时本文使用最大似然估计法[3],应用梯度函数进行权重估计:
(8)
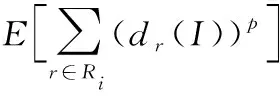
2 实验与分析
2.1 实验数据
本文使用真实数据集对模型进行评估。
1)UCI机器学习库所提供的两所葡萄牙学校的中学生数据集(http://archive.ics.uci.edu/ml/datasets/Student+Performance)。
葡萄牙中学生数据集 该数据集包含葡萄牙两所中学的1 064条学生数据,数据通过学校提供和问卷收集,属性包括学生成绩、社会家庭情况和学校表现等相关特征,两个文件分别提供数学(mat)和葡萄牙语(por)成绩。其中:属性G1、G2和G3分别是学生三次考试成绩的分数,具有很强的相关性,这是因为学生学习是一个持续积累的过程,不会在短时间内突然变好或变坏。而该数据集的其他属性并没有区分是学生哪一个学期产生的,因此本文认为是学生长期的表现,所以为了模型推理的科学性,数据预处理过程中,本文对学生的三次成绩求平均值作为目标属性,再将分数大于10分(总分20分)的学生标记为成绩合格。
2)中国某高校学生的日常数据集(http://www.dcjingsai.com/common/cmpt/学生成绩排名预测_竞赛信息.html)。
中国高校学生数据集 该数据集包含中国某高校的某个学院学生的60多万条活动记录,其中包含这些学生在三个学期的图书馆进出记录、一卡通消费记录、图书馆借阅记录,以及学生在每个学期成绩的相对排名。数据目录如下:
成绩信息包含学期、学号,以及相对排名。
借书信息包含学期、学号、书号、日期。
图书门禁信息包含学期、学号、日期、时间。
消费信息包含学期、学号、地点、日期、时间、金额。
该数据集标识的学生成绩只有学生相对排名,在数据预处理时,我们将成绩排名在前200名(共538人)的学生标记为成绩合格。
2.2 准备工作
2.2.1 评价指标
本文将对C5.0算法、手工定义规则的PSL,以及本文提出的C-PSL进行10次随机实验,随机选择80%的数据作为训练数据,剩下20%作为测试数据,方法的准确度通过式(9)、(10)、(11)和(12)所示的精确率(Precision)、正确率(Accuracy)、召回率(Recall)和F1值来度量。
(9)
(10)
(11)
(12)
其中:TP表示判断出成绩合格的学生数量,FN表示成绩合格的被判断为不合格的学生数量,FP表示成绩不合格被判断为合格的学生数量;Precision即正确判断的数量占识别出成绩达标学生总数的比例,Accuracy为正确判断的数量占总数的比例,Recall为正确判断的数量占应识别出成绩达标学生总量的比例,F1为准确率和召回率的调和平均数。

表2 混淆矩阵
2.2.2 Boosting选择
由表3和表4可以看出,在多次随机实验中,使用Boosting所产生规则的数量远远超过未使用Boosting的情况,推理的平均正确率在葡萄牙中学生数据上只相差2.67%,中国高校学生数据上使用Boosting推理正确率反而降低,其原因在于,本文模型构建C5.0模块的主要目的是通过C5.0算法从训练数据进行Boosting迭代提取规则,而算法准确率的测试过程由验证模块单独完成,这对于后续和PSL模型的比较会更加公平,由于该模型规则挖掘模块中C5.0算法不能通过测试数据得到的推理结果进行迭代优化而导致其在中国高校学生数据上使用Boosting时推理准确率反而降低。另一方面,对于本文研究,要将大量规则全部写入PSL将耗费更多的人工工作量和计算机资源,这违背了我们的研究初衷。因此,为了平衡规则数量,本文规则提取模块只在葡萄牙中学生数据上使用Boosting。
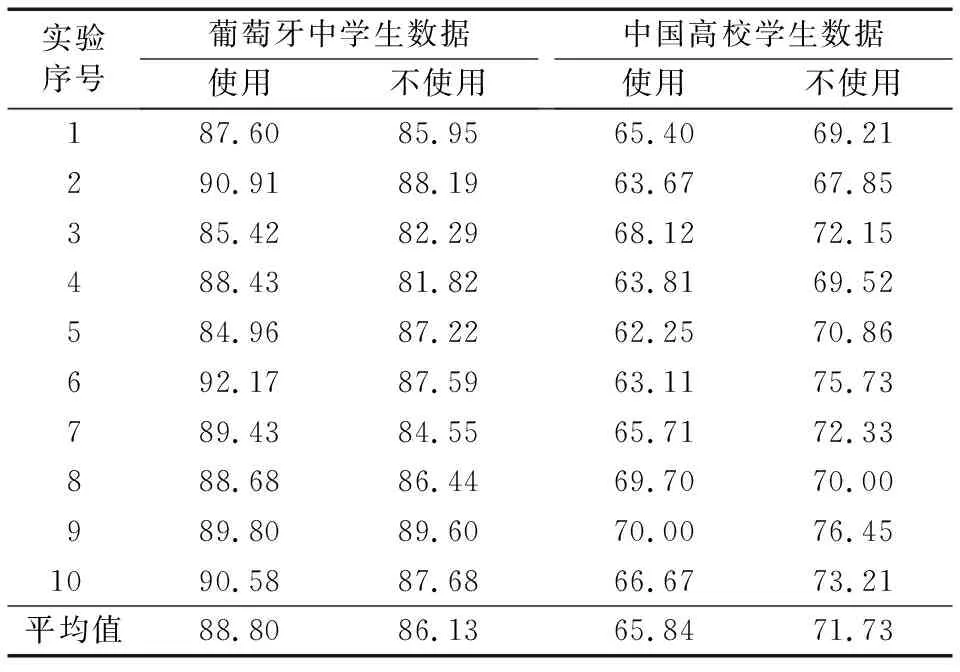
表3 是否使用Boosting的推理效果对比
表4是否使用Boosting时产生的规则数对比
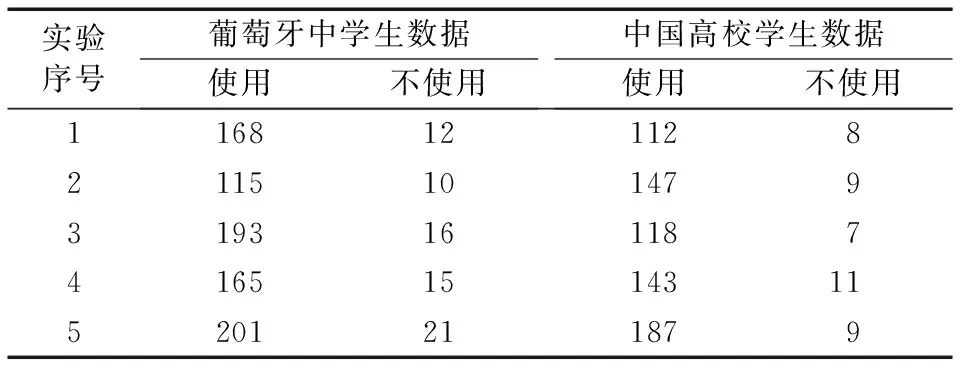
Tab. 4 Comparison of number of rules generatedwhen using and not using Boosting
2.3 实验结果
本文在两个数据集上对三种方法进行实验,根据模型对学生成绩达标情况的推断能力进行性能评估。实验配置如下。
C5.0 在葡萄牙中学生数据集上使用Boosting,中国高校学生数据集上不使用Boosting,两种情况都使用交叉验证,修建纯度70,子分支最少记录数7。
PSL 完全手工定义规则,仅有的参数为每条规则的权重,并且每条规则的权重由训练数据训练得到。
C-PSL C5.0学习的规则+手工定义规则。
表5和表6分别是C5.0、C-PSL和PSL在两组数据集上测试的F1值和Accuracy值对比,葡萄牙中学生数据集不包含学期属性,因此关于学期成绩的前后关联规则没能在该数据集上被手动构建,结果表明,在葡萄牙中学生数据上C-PSL的推理性能优于C5.0和PSL;对于中国高校学生数据集,规则全部被构建,可以看出,C-PSL推理的正确率和F1值依然优于C5.0,而表6中之所以C-PSL和PSL的推理正确率相当,是因为此时C-PSL和PSL的规则有很大一部分是人为定义,而这部分重合的规则起到了显著作用,这同时也说明了C-PSL是延续了PSL的优秀推理能力;从两组数据实验得到的F1值和Accuracy值的对比表明,C-PSL在学生成绩预测问题上可行且推理性能较优。
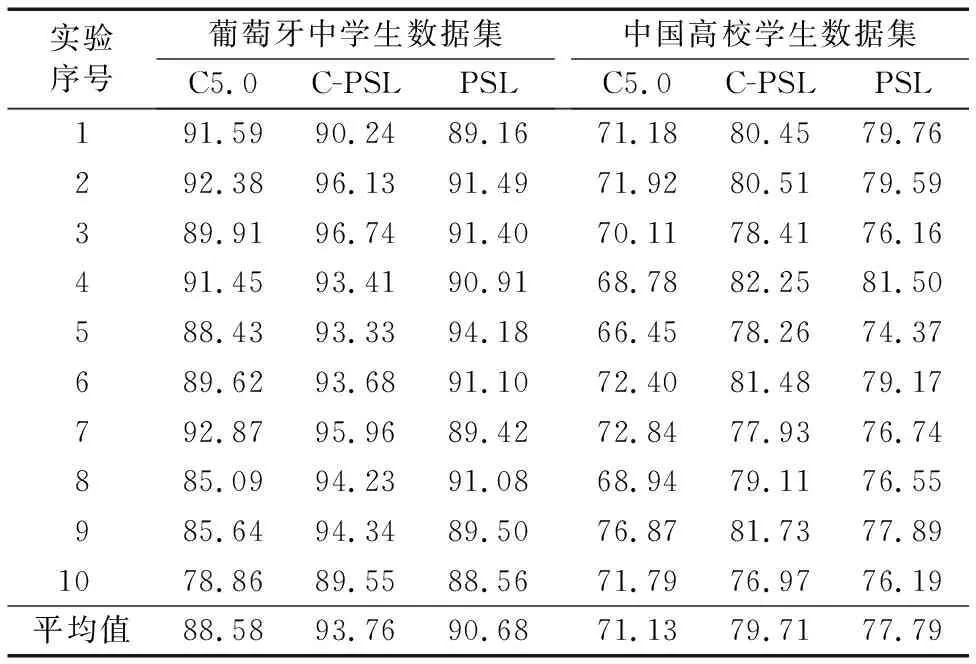
表5 三种方法在两个数据集中的F1值对比 %
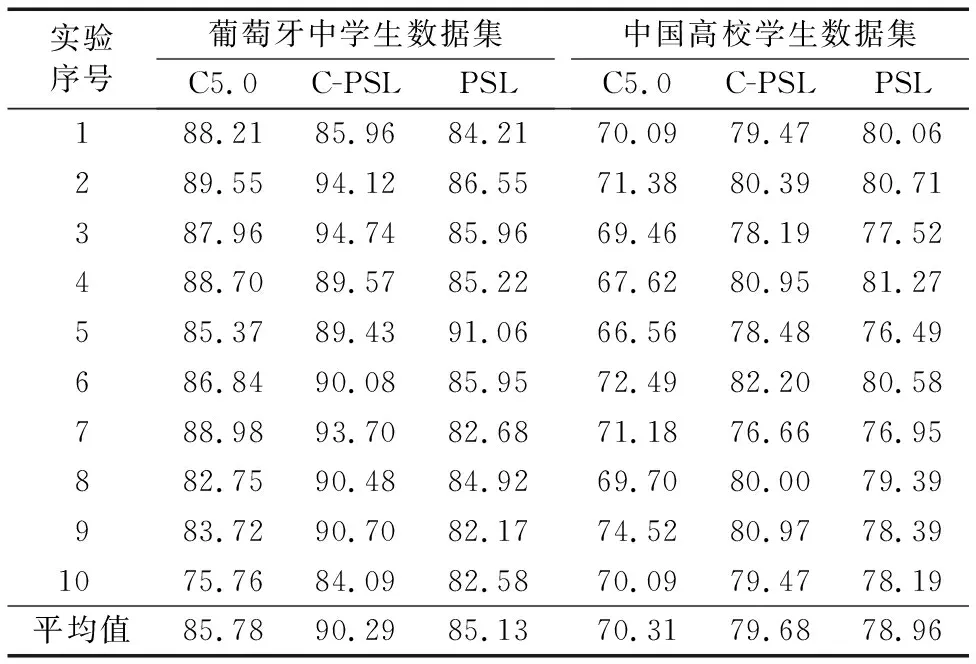
表6 三种方法在在两个数据集中的正确率对比 %
2.4 补充实验
为了进一步验证本文模型的性能,本文将C-PSL和支持向量机 (Support Vector Machines, SVM)[8]、逻辑回归(Logistic Regression, LR)[9]、贝叶斯网络(Bayesian Network, BN)[10]、K-最近邻(K-Nearest Neighbors,KNN)[11]等算法进行10次随机对比实验,结果如图2所示。
由图2可以看出,在葡萄牙中学生数据,SVM表现优秀,然而SVM的分类过程却很难人为理解,虽然C-PSL推理正确率次于SVM,但是由于C-PSL使用一阶逻辑规则表达推理,其过程的可读性是SVM无法比拟的;在中国高校学生数据上,C-PSL性能远超过其他算法,其原因在于,该数据中包含大量具有关联关系的数据,在使用C-PSL进行推理时加入了众多手工定义的关联规则,而这些关联关系,却几乎不能用SVM等算法进行构建,这正是C-PSL手工定义规则的优势所在。
2.5 C-PSL稳定性
本文所提出C-PSL模型基于PSL、C-PSL应该也应继承PSL的推理稳定性,下面的实验结果证实了这一点。表7显示了C5.0、C-PSL和PSL在两数据集(其中1为葡萄牙中学生数据,2为中国高校学生数据)上各10次实验的F1值和Accuracy值的标准差。
从10次实验的F1值和Accuracy值的标准差对比可以看出,本文所提模型(C-PSL)和PSL稳定性相当,这正是说明了C-PSL继承了PSL优秀的稳定性,并且C-PSL的稳定性优于C5.0算法。
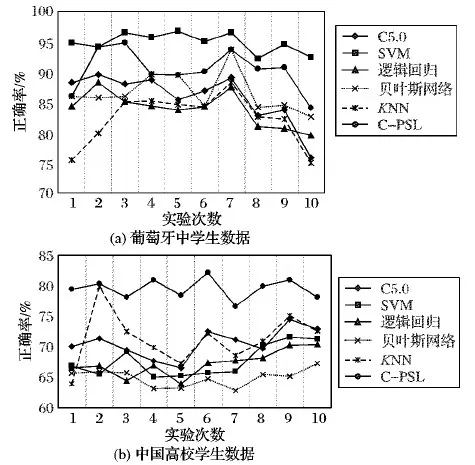
图2 六种算法在两个数据集中分类正确率对比
3 结语
本文提出了一种面向概率软逻辑的规则半自动学习方法(C-PSL), 该方法使用C5.0算法作为PSL的规则挖掘模型,同时辅以手工定义规则处理数据中的关联关系,让PSL成为一种由数据和知识共同驱动的推理模型。通过对两个属性差别很大的学生数据集的实验表明,在成绩预测问题上该方法比C5.0算法和PSL具有更高的推理准确度; 并且,和以往纯手工定义规则的方法相比,该方法能大幅降低手工成本; 此外,本文提出的模型,在两组数据上推理的稳定性也优于C5.0 算法。对于实际应用,该方法可以通过预测学生成绩的方式帮助学生及时发现生活学习习惯的不足,学校也可将其作为调整教学管理方案的参考因素。
下一步工作主要集中在两个方面:1)进一步探索规则优化策略,让模型得到更高质量的规则; 2)研究基于关联规则的自动挖掘方案。
猜你喜欢
法律方法(2022年2期)2022-10-20
中学生数理化·中考版(2022年6期)2022-06-05
中学生百科·大语文(2021年11期)2021-12-05
中学生数理化·中考版(2021年6期)2021-11-22
纺织科学研究(2021年7期)2021-08-14
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
37°女人(2017年11期)2017-11-14
山东青年(2016年1期)2016-02-28
当代修辞学(2014年3期)2014-01-21
