
交替传译课堂测试流利板块得分的影响变量对比
2018-12-10 07:16:24刘雨凤
四川文理学院学报 2018年6期
刘雨凤
(四川大学 外国语学院,四川 成都 61000)
内容完整度、表达流利度、语言质量是评估学生口译表现的重要指标。其中,流利度难把捏,主观性强,历来是学者们的重点研究对象。在评价口译表现时,对流利度的考量有时远超对语言质量的考量。比如,Altman认为学生译员和职业口译员的最大区别是流利度的区别;[1]26Pio认为“流利度”和“意义传达”平分秋色。[2]69二语习得的专家们把流利度分为语速、停顿和自我修正,如Chehr Azad, Farrokhi & Zohrabi等。[3]随后口译研究也延用了该类别的区分。然而,尽管许多研究者预测:语速、停顿和自我修正等变量都能影响口译学生流利度的得分,如Riccardic、Mead、Tissi、Han,[4-7]且已有研究者通过实证研究表明停顿与口译流利度板块的得分显著相关如Cecot、Mead、Pradas Macías、Tohyama & Matsubara、Tissi,[6-11]然而目前还未有实证研究表明自我修正对学生口译考试的流利度得分有着和停顿同等程度的影响。
据此,本研究采取定量和定性结合的办法,收集某高校翻译专业大四学生《交替传译》课上的考试音频,对音频材料进行转写、分析,借助SPSS软件得出相关系数,探讨自我修正是否与停顿相同,与口译流利度得分之间存在显著相关性。最后,通过调查问卷,验证并解释SPSS得出的定量数据。本研究的一大优势是,两种变量的相关数据均在同一真实的环境中收集,具有很强的可比性并减少了相关误差。
一、相关研究回顾
事实上,如前所述对流利度的研究并非先发于口译领域,而是心理学领域,如Oleron & Nanpon及二语习得领域, 如Lennon、Kormos & Denes、Lautamus、Nerbonne & Wiersma、张文忠。[12-16]20世纪50年代伊始,口译研究才得以萌发,但关于流利度的探索一直贯穿口译研究的发展,从早期的Goldman-Eisler、Gerver、Kirchhoff到21世纪的Yagi、Cecot、Pio、Mead、Pradas Macías、Bakti、Yin、Han。[17-22]笔者对这些研究进行了大致的梳理,按照相关变量、口译模式、口译语种及方向、研究环境、受试进行分类。其中,自我修正包括开口错误、替换、重组;停顿包括有声停顿和无声停顿。
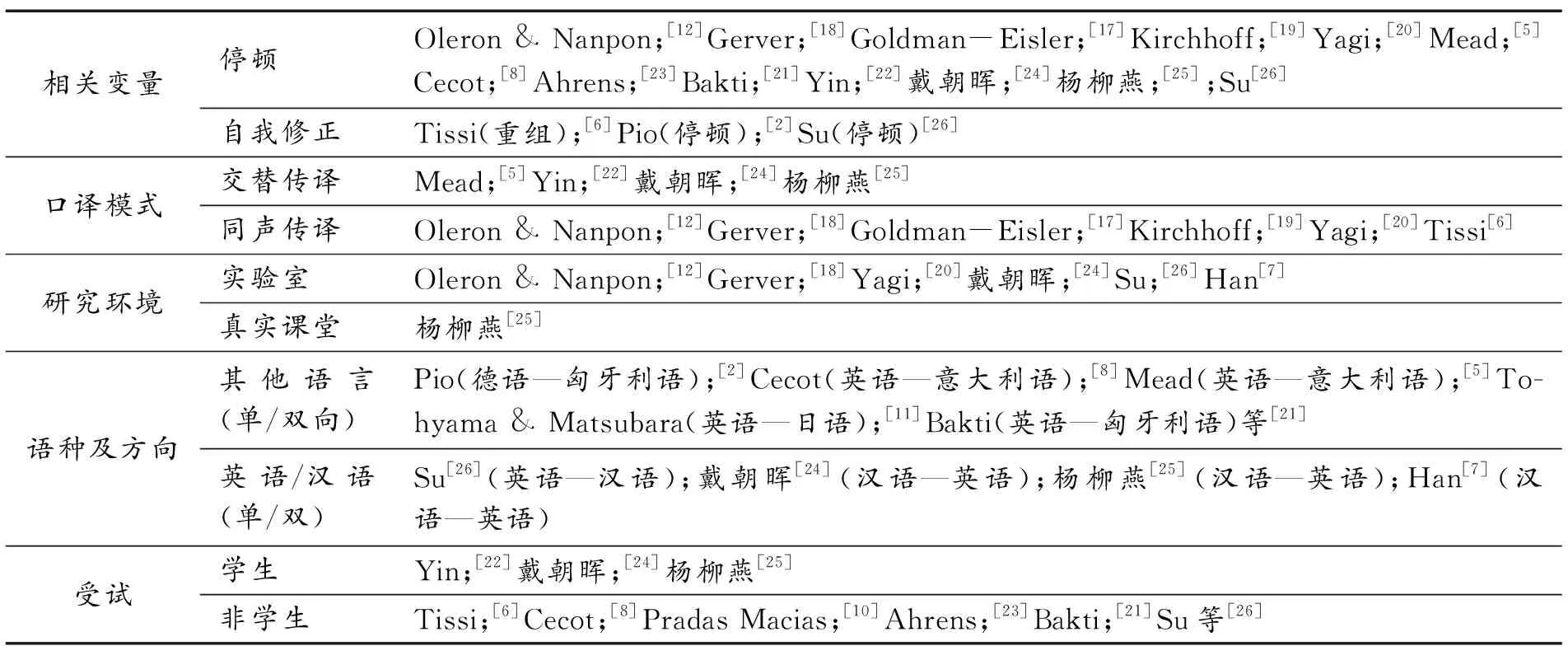
表1 相关文献分类
从上述分类图表中可以看出,前人的研究主要关注同声传译中的停顿变量,且研究方法多为语言实验;有关汉语的口译研究也多是英译汉或者汉译英的单向研究;受试多为职业译员,而非学生译员。据此,本研究关注对象为学生译员,考虑他们在英汉、汉英交替传译中的表现,探究自我修正与他们的口译得分之间是否存在显著关联性。本研究中自我修正变量包括三个小变量:每分钟错误开口数量(the number of false start per min,即NFS(pm))、每分钟替换数量(the number of replacement per min,即NRepl (pm))、每分钟重组数量(the number of reformulation per min,即NRefo (pm))。停顿变量包括四个小变量:每分钟有声停顿数量(the number of filled pause per min,即NFP (pm))、每分钟无声停顿数量(the number of unfilled pause per min,即NUP (pm))、有声停顿平均时长( mean length of filled pause ,即MLFP)、无声停顿平均时长(mean length of unfilled pause,即MLUP)。最后包括流利度得分(Fluency of delivery ratings,即FluDel ratings)变量。
口译研究中中自我修正的研究相对较少,相关定义也较单一,对该术语进行定义的口译领域研究者主要包括Tissi,[6]Pio,[2]Han。[7]尽管像Fox Tree等二语习得领域的研究者也曾研究过自我修正,[27]但这里不进行赘述。错误开口被“定义为说话者在没有完成一句完整的表达前又开始了一个新的句子,Tissi[6]被Pio定义为:“口译员在翻译一句话的最开始打断自己,然后又重组语言”。[2]77替换和重组被Tissi合并为“结构重组(restructuring)”,[6]114包括:1)“更正说话者的说话内容,包括一个短语、词语甚至一个词语的部分”;2)“说话者决定用另一种语言结构表达他原本想要表达的意思”,分别对应替换和重组。韩潮也对替换和重组作了区分,[7]认为重组没有改变译者想要表达的含义,而替换相反。这些定义均适用于本研究,以下为例子(均取自于本研究中的真实素材):

表2 英汉交替传译中自我修正统计样本

表3 汉英交替传译中自我修正统计样本
(注:鉴于研究目的,“重复”不在考虑范围内,且错误开口的数量=替换数量+重组数量。)
关于停顿的分类略有不同。其中,语言学领域中,关于停顿的定义最充分、研究最丰富。
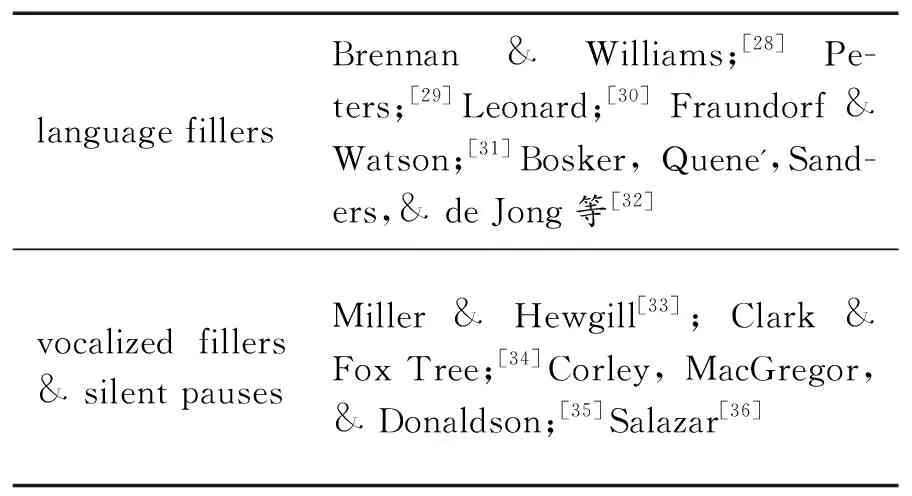
表4 语言学领域中关于停顿的研究分类
可见,语言学领域中,停顿主要为fillers和silence,又称vocalized fillers和silent pauses。口译领域中称为filled pause和unfilled pause或者silence(Maclay & Osgood )。[37]本研究沿用口译领域的术语名称,称其为有声停顿(filled pause)和无声停顿(unfilled pause)。有声停顿定义为英文中的“uh” “um” “en” “e” (Miller & Hewgill;[33]Clark & Fox Tree[34]),以及中文中的“嗯”、“呃”等出现在句子中无语言意义的发声。而关于无声停顿,语言学领域并未详细介绍其长度标准,口译领域中主要的长度标准为大于等于0.2秒、0.25秒和0.3秒。本研究以0.25秒为标准,任何大于等于0.25秒的“无声区”即为一个停顿。
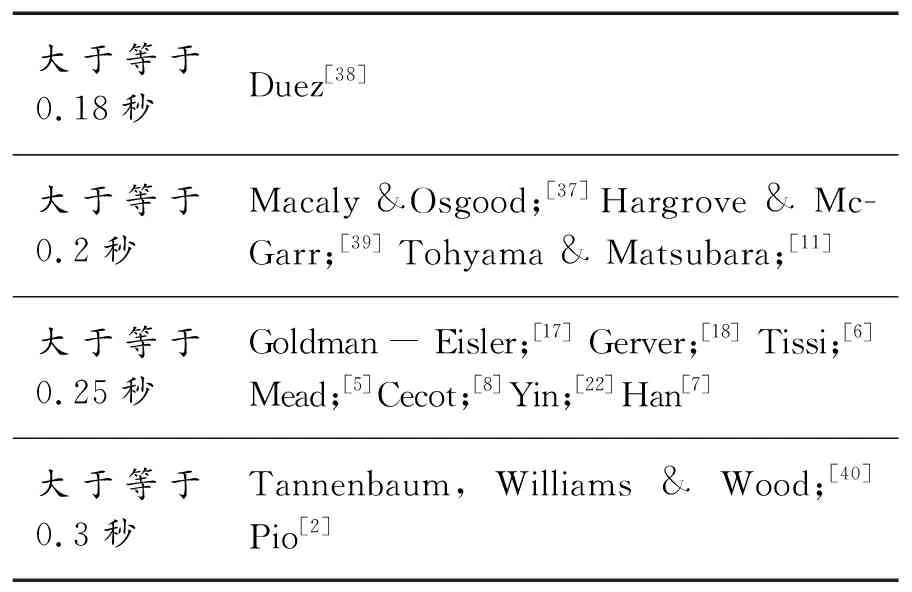
表5 口译领域中关于无声停顿长度的标准表
归纳起来,NFS (pm)=错误开口数量/口译时长(秒)*60;NRepl (pm)=替换数量/口译时长(秒)*60;NRefo (pm)=重组数量/口译时长(秒)*60;NFP (pm)=有声停顿数量/口译时长(秒)*60;NUP (pm)=无声停顿数量/口译时长(秒)*60;MLFP=有声停顿总时长(秒)/有声停顿的数量;无声停顿平均时长(MLUP)=无声停顿总时长(秒)/无声停顿的数量。FluDel ratings=流利板块评分人员评分总和/评分人员数量。
二、研究问题
本文探讨的是自我修正、停顿与口译流利板块得分之间的关系,力图用实证研究说明自我修正在口译评分中的地位,回答“口译评分中,自我修正是否与停顿享有同等影响力”这一问题。据此,本文有以下六个具体研究问题:
问题一:英汉交替传译中NFS (pm)、NRepl (pm)、NRefo (pm)与FluDel ratings是否存在显著相关关系?
问题二:英汉交替传译中NFP (pm)、NUP (pm)、MLFP、MLUP与FluDel ratings是否与前人研究得出的结果相同,与FluDel ratings呈显著负相关?
问题三: 上述两种关系是否存在不同,为什么?
问题四:汉英交替传译中NFS (pm)、NRepl (pm)、NRefo (pm)与FluDel ratings是否存在显著相关关系?
问题五:汉英交替传译中NFP (pm)、NUP (pm)、MLFP、MLUP与FluDel ratings存在显著相关关系吗?
问题六:上述两种关系是否存在不同,为什么?
三、研究设计
本研究的受试是某高校《交替传译》课上的26名大四学生,包括23名女生和3名男生,平均年龄21岁,母语为汉语,英语为第二语言。26名学生至少有一年的口译课经验,其中15名同学已有CATTI三级口译资格证书。
评分人员包含两名口译教师、四名助教(已有CATTI二级口译资格证书,从该校MTI口译专业毕业的研究生,目前已从事口译员工作一年零六个月),其中两名男性,四名女性。汉语为母语,英语为第二语言。两名口译教师平均年龄35岁,四名助教平均年龄26岁。他们互相熟络,有利于开展讨论。他们将对每一位同学的口译表现根据评分表进行评分,最终评分结果取平均值。
《交替传译》课第一周,任课教师向全班学生说明考试要求,并借用韩潮的口译评分表,[7]向学生解释将会按照该评分表对每位同学的口译表现打分。评分表主要包含三个模块:内容完整性(completeness of contents)、表达流利度(fluency of delivery)和目标语质量(target language quality),本研究不考虑内容完整性和目标语质量,只考虑表达流利度,其评分细则如下(Han[7]):

表6 流利板块评分细则
在评分前,口译老师对评分人员进行一次培训。同时,每位评分人员获得一张评分表,口译老师详细解释评分表,其它评分人员提出问题进行讨论,统一标准。每位评分人员先独立完成评分,最后一起讨论。评分过程尽量保证标准统一,减少误差。评分人员分别对内容完整性、表达流利度和目标语质量进行打分,每位同学的最终口译得分取三部分得分的平均值。但鉴于研究目的,此处只取表达流利度得分的平均值作为每位同学的流利度得分。
本次口译测试的英文材料含250词,即430个音节,主题为日益增长的中国贸易;中文材料含400词,主题为中国的旅游业。中英文材料均由口译老师提前录制。两段材料之间间隔15分钟,以供考生休息。每段材料分为两到三个小节进行播放。考试采用New Class系统,同时录入原声道和学生声道。
首先,运用Cool Edit Pro 2.0对音频进行编辑。去掉原声道,只留下译语声道,同时去掉小节之间的空白。第二步,对音频进行转写。转写要求精确,口译中出现的一切情况都需记录,包括呼吸声、有意咳嗽和未完成的音节。第三步,利用Cool Edit Pro 2.0计算音频总时长(秒)、找出所有无声停顿和有声停顿,要求记录停顿开始时间和持续时长(秒),将其总数和每个停顿的长度(秒)统计在Microsoft Excel中。第四步,对转写材料进行错误开口、替换、重组的统计。将所有的数据统计到表格中后,用公式算出NFS (pm),NRepl (pm), NRefo (pm), NFP (pm), NUP (pm), MLFP, MLFP。根据6名评分人员的打分表算出每位同学表达流利度部分的平均分作为FluDel ratings。最后,核查转写材料和数据。
笔者在得出NFS (pm), NRepl (pm), NRefo (pm), NFP (pm), NUP (pm), MLFP, MLFP的数值后做了如下工作:1)算出平均值(mean)和标准差(standard deviation);2)运用IBM SPSS Statistics 21算出变量之间的相关系数;3)通过相关系数分析参数之间的两两关联性;4)对比自我修正、停顿与评分之间的相关程度;5)解释差异的原因和意义。本研究主要参看皮尔森相关系数数值,进行分析。显著水平ρ值小于0.05说明相关性显著,小于0.01说明相关性异常显著。相关系数r小于0,说明两者呈正相关;小于0,呈负相关;等于0,不相关。
四、研究结果
本研究得出各变量个方向的描述性数据如表7、表8,相关性矩阵如表9、表10、表11、表12。表7和表8中的平均值和标准差均由Excel表算出。从表中可以看出,英汉交替传译中NFS(pm)、NRepl(pm)、NUP (pm)、NFP (pm)的标准差较大,说明学生关于这四种变量的个体差异相对较大;NRfor(pm)、MLUP、MLFP、FluDel ratings标准差数值较小,说明数据之间差异不大。汉英交替传译中情况类似,NFS(pm)、NRepl(pm)、NUP (pm)、NFP (pm)的标准差较大,说明学生关于这四种变量的个体差异相对较大;NRfor(pm)、MLUP、MLFP、FluDel ratings标准差数值较小,说明数据之间差异不大。其中,NUP (pm)、NFP (pm)标准差数值最大,且多出其它数值一半,因此这两个变量不如MLFP、MLUP平稳,验证了加入MLFP和MLUP的科学性。
表7 NFS(pm), NRepl(pm), NRefo(pm) , FluDel ratings的描述性数据
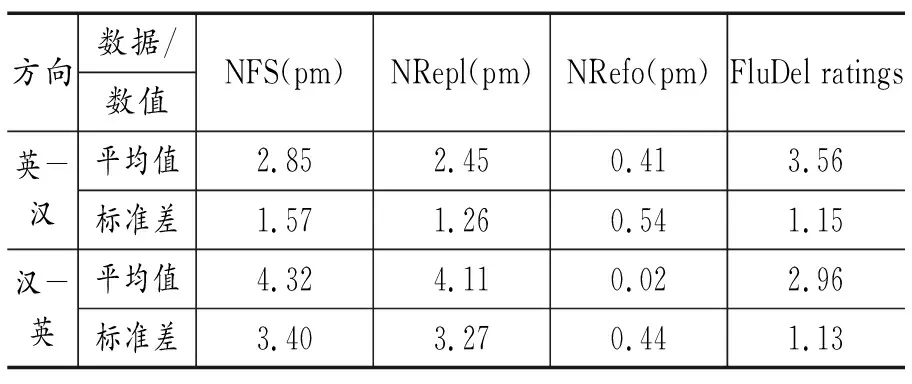
方向数据/数值NFS(pm)NRepl(pm)NRefo(pm)FluDel ratings英-汉平均值2.852.450.413.56标准差1.571.260.541.15汉-英平均值4.324.110.022.96标准差3.403.270.441.13
表8 NUP(pm),MLUP NFP(pm), MLFP, FluDel ratings描述性数据
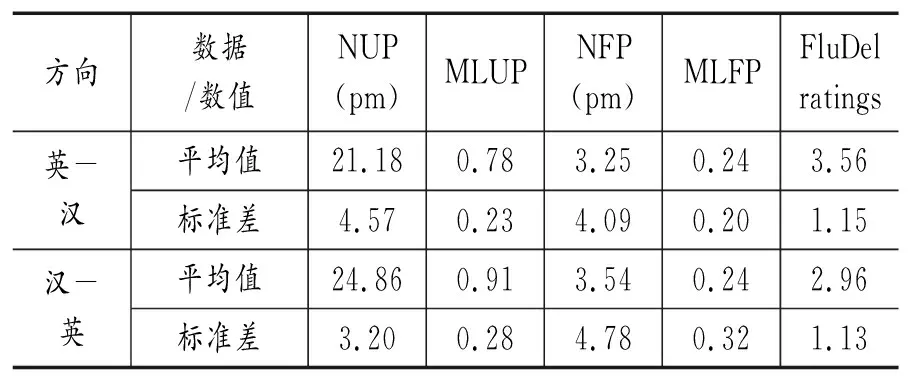
方向数据/数值NUP(pm)MLUPNFP(pm)MLFPFluDel ratings英-汉平均值21.180.783.250.243.56标准差4.570.234.090.201.15汉-英平均值24.860.913.540.242.96标准差3.200.284.780.321.13
表9 NFS(pm), NRepl(pm), NRfor(pm)和FluDel ratings相关矩阵(英-汉)
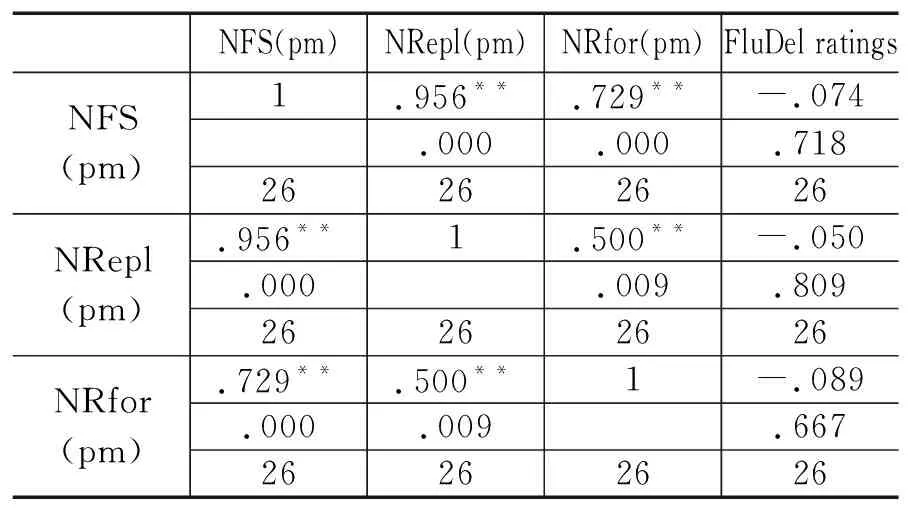
NFS(pm)NRepl(pm)NRfor(pm)FluDel ratingsNFS(pm)1.956**.729**-.074.000.000.71826262626NRepl(pm).956**1.500**-.050.000.009.80926262626NRfor(pm).729**.500**1-.089.000.009.66726262626
表10 NUP(pm), MLUP, NFP(pm), MLFP和FluDel ratings (英-汉)
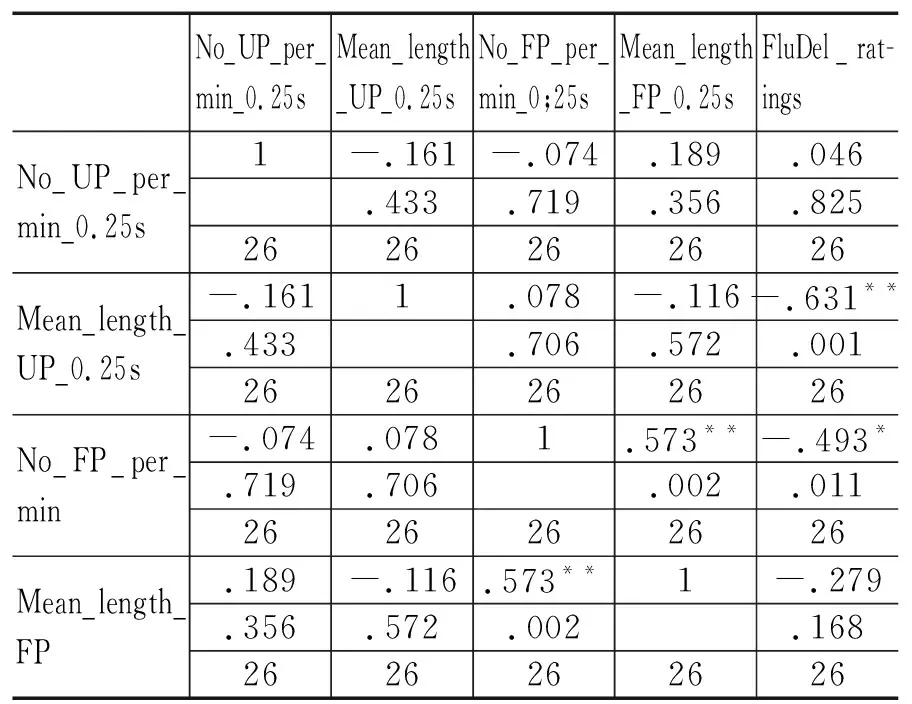
No_UP_per_min_0.25sMean_length_UP_0.25sNo_FP_per_min_0;25sMean_length_FP_0.25sFluDel_rat-ingsNo_UP_per_min_0.25s1-.161-.074.189.046.433.719.356.8252626262626Mean_length_UP_0.25s-.1611.078-.116-.631**.433.706.572.0012626262626No_FP_per_min-.074.0781.573**-.493*.719.706.002.0112626262626Mean_length_FP.189-.116.573**1-.279.356.572.002.1682626262626
(注:**p<0.01,*p<0.05)
表9和表10展示了英汉交替传译中自我修正与口译流利度评分、停顿与口译流利度评分的相关系数r和显著水平ρ。NFS(pm)和FluDel ratings之间的r (25) = -0.074, ρ > 0.05; NRepl(pm)和FluDel ratings之间的 r (25) = -0.050, ρ > 0.05,NRor(pm)和FluDel ratings之间的r (25) = -0.089, ρ > 0.05,说明两两之间尽管略微负相关,但是相关性并不显著。NUP(pm)和FluDel ratings之间的r (25) = 0.46, ρ > 0.05; MLUP和FluDel ratings之间的r (25) = -0.631, ρ =0.01;NFP(pm)和FluDel ratings r (25) = -0.493, ρ < 0.05且趋近0.01;MLFP和FleDel ratings之间的r (25) = -0.279, ρ > 0.05。这说明在英汉交替传译中自我修正并非与停顿一样,在口译得分中起着显著的负相关作用。相反,自我修正与口译得分之间并无任何显著相关关系,但数据再次印证无声停顿的长短以及有声停顿的个数对口译流利度的得分起着决定性的作用,无声停顿越长或有声停顿越多,得分就越低(Mead 2000; Cecot 2001; Pradas Macías 2006; Tohyama & Matsubara 2006, etc.)。
表11 NFS(pm), NRepl(pm), NRfor(pm)和FluDel ratings相关矩阵(汉-英)
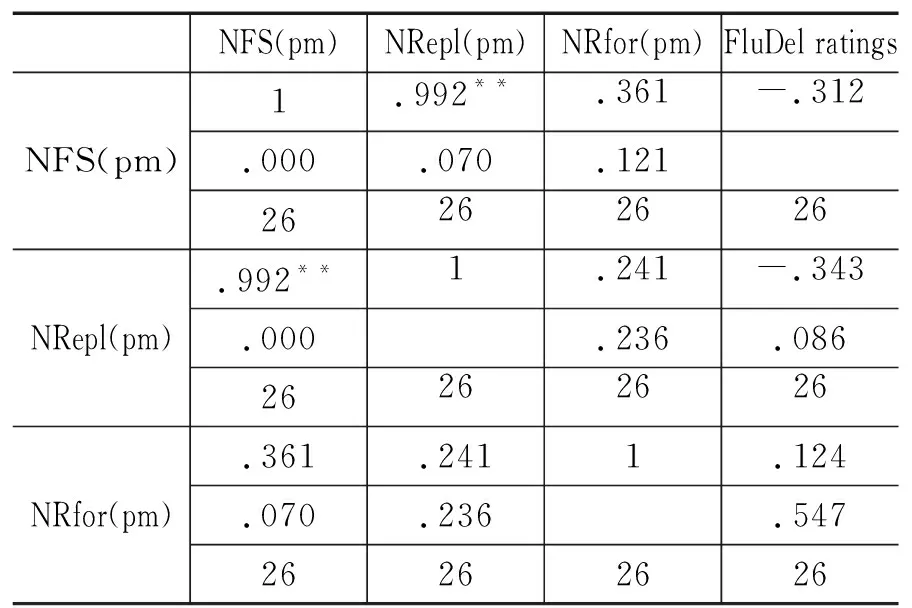
NFS(pm)NRepl(pm)NRfor(pm)FluDel ratingsNFS(pm)1.992**.361-.312.000.070.12126262626NRepl(pm).992**1.241-.343.000.236.08626262626NRfor(pm).361.2411.124.070.236.54726262626
表12 NUP(pm), MLUP, NFP(pm), MLFP and FluDel ratings相关矩阵(汉-英)
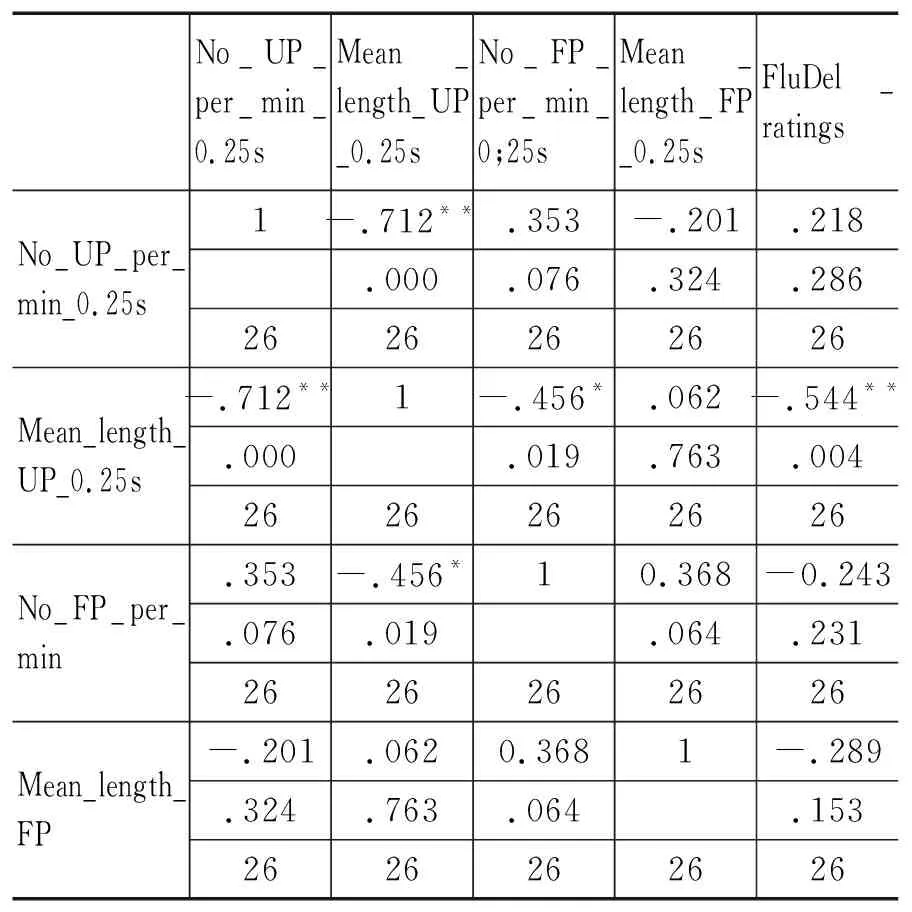
No_UP_per_min_0.25sMean_length_UP_0.25sNo_FP_per_min_0;25sMean_length_FP_0.25sFluDel_ratingsNo_UP_per_min_0.25s1-.712**.353-.201.218.000.076.324.2862626262626Mean_length_UP_0.25s-.712**1-.456*.062-.544**.000.019.763.0042626262626No_FP_per_min.353-.456*10.368-0.243.076.019.064.2312626262626Mean_length_FP-.201.0620.3681-.289.324.763.064.1532626262626
表11和12展示了汉英交替传译中自我修正与口译流利度评分、停顿与口译流利度评分的相关系数r和显著水平ρ。NFS(pm)和FluDel ratings之间的r (25) = -0.312, ρ > 0.05; NRepl(pm)和FluDel ratings之间的 r (25) = -0.343, ρ > 0.05,NRor(pm)和FluDel ratings之间的r (25) = 0.124, ρ > 0.05,说明自我修正与口译得分之间无显著相关关系。NUP(pm)和FluDel ratings之间的r (25) = 0.218, ρ > 0.05;MLUP和FluDel ratings之间的r (25) = -0.544, ρ < 0.05;NFP(pm)和FluDel ratings r (25) = -0.243, ρ > 0.05;MLFP和FleDel ratings之间的r (25) = -0.289, ρ > 0.05。这说明在英汉交替传译中,自我修正并非与停顿一样,在口译得分中起着显著的负相关作用。相反,自我修正与口译得分之间并无任何显著相关关系,但数据再次印证无声停顿的长短对口译流利度的得分起着决定性的作用,无声停顿越长,得分就越低。然而,汉英交替传译中,每分钟有声停顿的数量却与口译得分没有显著相关性,这与英汉交替传译有所不同。
五、SPSS数据补充
利用SPSS得出的数据表明,学生英汉汉英交替传译中的流利度得分与每分钟错误开口数量、每分钟替换数量、每分钟重组数量无显著相关性,这与部分研究者(Riccardic;[4]Mead;[5]Tissi;[6]Han等[41])的预测并不符合,也脱离口译课师生的一般看法,即自我修正和停顿一样,能对口译得分造成显著影响。同时,结果也再次证实英汉汉英交替传译中无声停顿的平均时长对口译得分有显著的负相关关系;尽管在英汉交替传译中每分钟有声停顿的数量与口译流利度得分呈显著负相关关系,但是在汉英交替传译中,两者无显著关系,这也与一般认知有所不同。因此,本研究决定再次向评分人员做问卷调查,收集相关数据,力图摸清缘由。
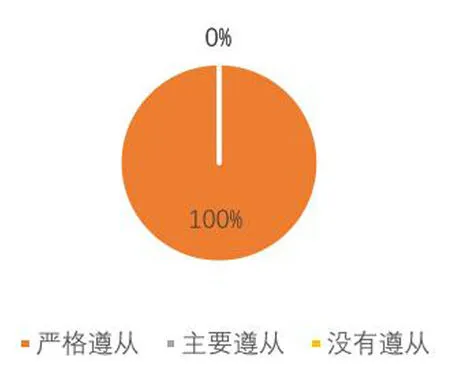
图1 评分人员评分过程中遵从评分表的程度
问卷共有8道题目,其中5道选择题,3道开放式问答题。做问卷时,所有评分人员均未获得SPSS得出的数据。问卷结果表明6名评分人员均严格遵从评分表细则对学生的口译表现进行打分(如图1)。图2和图3表明,6名评分人员均认为英汉汉英交替传译中每分钟错误开口数量,每分钟替换数量、每分钟重组数量、每分钟无声停顿数量、每分钟有声停顿数量、无声停顿平均时长、有声停顿平均时长均会影响学生的口译得分。而图4表明,2名评分人员认为前三种变量的影响程度更深,4名评分人员认为后四种变量的影响程度更甚,分别约占总人数的33.33%和66.7%。
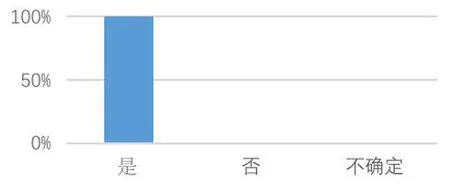
图2 自我修正是否影响口译得分
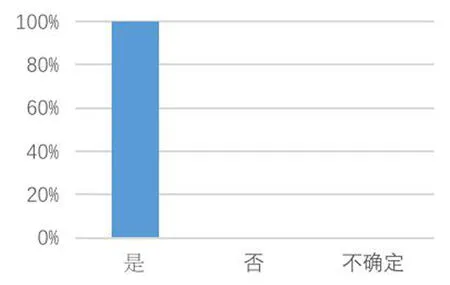
图3 停顿是否影响口译得分
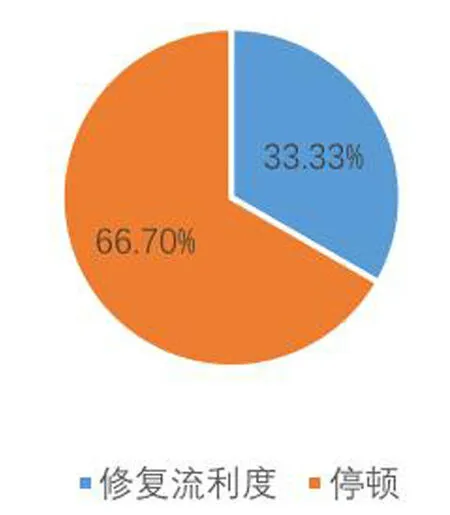
图4 自我修正和停顿谁的影响程度更大
在开放式问答题中的答案中,两名评分人员认为,自我修正对口译得分的影响更甚的原因是,学生译员不断改口将影响译语内容的整体理解,而确保评分人员对内容的理解是重中之重。但剩余四名评分人员表示,无声停顿造成多次译语空白将大大降低评分人员对学生译者的好感度,且无声停顿和有声停顿数量多便意味着错误开口、替换、重组的数量也多,因此停顿的影响程度更甚。
六、结 语
通过对比SPSS算出的各变量的相关系数,笔者发现自我修正并未如部分研究者预测一般,和停顿相同,对口译得分起着关键的反向作用。相反,无论是英汉还是汉英的交替传译中,自我修正与学生译员的口译得分之间并不存在显著相关关系。在确保实验设计、数据无误后,笔者再次利用问卷调查,对6名评分人员进行了调查。问卷结果表明,6名评分人员均表示自我修正和停顿都能对口译得分产生影响,且其中4名评分人员认为停顿的影响程度更甚于自我修正的影响程度,原因是无声停顿造成的大段空白最能拉低评分人员对学生译员的好感度,且停顿越多、越长,越可能导致错误开口、替换、重组的发生。而尽管自我修正一定程度上影响译文的整体流畅度,但在评分过程中并无显著相关性。据此,口译教师在评分过程中是否应该继续坚持该评分原则,还是应该做出调整,对自我修正引起一定重视,这是一个严峻的问题,因为课堂教师的打分会对学生的学习起反波作用。若是教师打分比实际培养目标更宽松,那么是否会一定程度影响学生的学习呢?这仍需进行更深层次的研究。此外,任课教师及其他助理教师尽管在问卷调查中的态度观点与SPSS实际得出的相关系数明显不同,这一定程度上说明单一的定性研究不尽可靠。未来的口译研究趋势一如韩潮所说,将是定性和定量结合。[42]
但本研究仍存在局限:1)只有26名被试者,数量不够大且性别分布并不平衡;2)所有被试者来自同一学校同一班级,不能代表全国不同高校学生的情况;3)尽管评分人员均宣称严格遵从评分表进行打分,但仍然可能存在较大的差异。上诉局限在实际操作过程中难以完全杜绝,尤其是口译相对笔译还需要进行大量的转写工作,耗时巨大。但假以时日,若能建成一个全面而大型的高校口译考试语料库,那么得出更具有概括性的结论将不再是“黄粱一梦”。
猜你喜欢
河南工业大学学报(社会科学版)(2022年1期)2022-03-31 12:54:42
外语教学理论与实践(2016年1期)2016-06-11 05:51:46
疯狂英语(双语世界)(2016年4期)2016-06-05 08:37:16
疯狂英语(双语世界)(2016年4期)2016-06-05 08:37:14
河北传媒研究(2015年1期)2015-07-12 10:45:19
山西大同大学学报(社会科学版)(2015年6期)2015-01-22 07:22:32
语言与翻译(2014年1期)2014-07-10 13:06:14
海外英语(2013年10期)2013-12-10 03:46:22
外语学刊(2011年4期)2011-01-22 05:34:26
学苑创造·B版(2009年6期)2009-08-13 09:47:48
