
一种新型的分布式弱栅栏构建与移动算法*
2018-12-10 12:13:02秦宁宁
传感技术学报 2018年11期
秦宁宁,许 健,金 磊
(江南大学轻工过程先进控制教育部重点实验室,江苏 无锡 214122)
不同于在整个网络的截面处建立链状覆盖带的栅栏覆盖,弱栅栏是一种分区不连续的链状结构。由于初始传感器节点分布的随机性,需要部分传感器节点移动至合适位置,以构建栅栏。如何在节点的移动距离与栅栏质量上,取得性能的折中平衡,是栅栏覆盖中的一个关键问题。
在栅栏覆盖的研究中,如何在保证闭合性的同时,最大限度地减少传感器节点的总移动距离,研究人员提出了很多具有参考价值的方案。文献[1]针对存在多个复杂约束的复合事件栅栏覆盖优化问题,提出了一种基于有效策略集的乘子法[1]ASMP(Active Set Multiplier Policy),该算法可以有效的计算闭合性,但是算法较为复杂且适用场景较少。基于经典概率感知模型,文献[2]通过数据融合技术构造虚拟节点以增加节点的覆盖范围,虽然提高了栅栏的闭合性,但算法复杂度偏高。为了降低复杂度,毛科技等人采取分块的模式,设计了应用于每个分区中,且以传感器节点偏移角为核心变量的蚁群算法[3],实现了分区下的K-栅栏覆盖。作为弱栅栏研究的前身,该分区栅栏模式延长了栅栏的存在时间,保证了闭合性,但是被调度的节点移动距离较大,实时性较差。针对实时性问题,CBarrier(Centralized Barrier Algorithm)算法[4]提出:将栅栏约定为直线,以节点到直线栅栏上可能位置间的距离作为变量,构造距离表达式。利用偏导来近似求解距离最小的位置,但算法对节点初始分布要求较高,普适性差。为扩展CBbarrier的应用范围,班东松等人提出了CBGB(Constructing Baseline Grid Barrier)[5]算法,所得栅栏的闭合性优异,但节点移动距离的仍然较长,通信开销的改善也不明显。
为了在随机部署的传感器网络中,寻找网络闭合性和节点平均移动距离之间的最优关系,论文结合最优二分匹配中的库恩匹配[6]KM(Kuhn Munkras),设计了一种分布式弱栅栏算法。通过将栅栏模型转化为槽位相连的模式,将传感器节点到槽位圆心坐标之间的距离设置为匹配权重,构造出备选栅栏表达式,并给出KSDE(Kuhn Select-box Distribute Exponential-smoothing)算法,解决了节点及其对应槽位点之间的最优选择和匹配问题,实现了以有效的短距离节点平均移动,取得迅速的高质量栅栏闭合性。
1 问题陈述
1.1 网络模型
在给定的被监测的矩形区域I=B×L内,设存在N个随机分布的同构传感器节点S={Sg|Sg=(xg,yg),g=1,2,3,…,N}和一个目标Target,试图以最小被感知到的代价,穿越区域Sg。不考虑传感器节点收发信息的能量损耗,所有节点皆为布尔感知模型,在感知半径r内,传感器节点都可以无差别的感知到事件发生[7]。
1.2 闭合性
闭合性是弱栅栏覆盖的一项重要性能指标,主要考察网络对直线穿越目标Target的感知能力。对几个闭合性相关基本概念的表述,约定如下:
定义1(穿越) Target从区域I的某一边进入,以直线的移动轨迹,抵达该边的对边。
定义2(点闭合性) Target以给定位置点为起点,穿越区域I,被区域内节点感知到的概率为该起点的闭合性。
定义3(网络闭合性) Target从给定边的任意位置点出发,穿越区域I,被区域内节点感知到的概率平均值。
考虑到边的连续性在仿真计算中实现困难,因此在后续的研究中,选取出发边上具有代表性的若干位置点作为闭合性的计算样本,近似的替代考察整个网络的闭合性[8]。
1.3 栅栏覆盖的分类
栅栏覆盖是将传感器节点根据要求排列成链状的结构[9]。当Target穿越区域I时,其轨迹和栅栏接触时候,由传感器节点及其感应区域组成的栅栏可以完成对Target的感知。栅栏覆盖可以分为强栅栏覆盖和弱栅栏覆盖两类。
强栅栏覆盖是由传感器节点组成,横跨整个网络区域的链状覆盖带。入侵的Target无论以何种轨迹试图穿越区域I,都将被强栅栏感知。强栅栏覆盖的特点就在于,存在至少一条栅栏完全横跨整个区域I。如图1(a)给出了以AB边为起点边,CD边为抵达边的强栅栏覆盖。其AB边上点的闭合性及其网络闭合性均为1。弱栅栏覆盖是由多条覆盖带组成的集合,弱栅栏覆盖的特点在于:仅对于某些位置点,如图1(b)中点PB1,闭合性为1,而网络中由于存在穿越网络而能够不被栅栏感知的起点,因此整个网络的闭合性可能小于1,如采用路线Path的点PB2。
相比于弱栅栏,强栅栏覆盖虽然具有高闭合性,但是形成条件相对苛刻,需要调度网络中节点参与移动的数目和距离更多,调度的复杂性也更高[10]。另一方面,鉴于许多应用多集中在对热点区域内覆盖性能的考量,故对网络中栅栏覆盖性能的闭合性要求,可以基于需求适当降低,因此,采用节点移动数量和平均距离更少的弱栅栏,成为了相对合理的选择[11]。
2 库恩匹配(KM)
KM是图论学中解决匹配问题的一种常用的有效算法。该算法的本质,就是对两个集合:集合M1={M11,M12,…,M1i,…,M1m}以及集合M2={M21,M22,…,M2j,…,M2m},i,j∈[1,m],各取一个元素构成一条边,通过定义匹配约束和边权值,不断寻找增广路,以获取具有最大权值的元素匹配方式,从而完成上述两个等尺度集合之间的元素匹配。
2.1 基本概念
在描述算法过程之前,需要预先约定几个必需的图论概念如下。
定义4(匹配) 为M1和M2中满足匹配要求的两个元素建立联系的过程称为匹配。
定义5(未匹配边) 由分别源自集合M1和M2中具有一一映射关系的两个元素M1i和M2j组成,若M1i和M2j构成的边满足匹配约束条件,但是尚未进行匹配,则该边称为未匹配边。
定义6(匹配边) 对未匹配边进行匹配操作后,该边被称为匹配边。KM算法中得到匹配边的方法是对需要进行匹配的未匹配边取反。给定一个一维数组Match记录匹配边两边元素的信息,如M1i和M2j构成一组匹配边,则Match(j)=i。
定义7(完美匹配) 若M1和M2中所有元素之间,恰好可以成对的构成匹配边,那么所有这样的匹配边组成的集合就称为完美匹配。特别的,对于匹配边边权总和最大的完美匹配,被称为最优匹配。
定义8(交错路) 是一条在M1和M2之间构造的路径C-path,且该路径满足匹配边和未匹配边交替出现的特点。
定义9(增广路) 若C-path的起点元素和终点元素均未包含在匹配边上,则该路径被称为增广路,记作R-path。在R-path中,匹配边的数量被记为nR-path,显然nR-path=n~R-path-1。其中~R-path表示对R-path取反,即匹配边和未匹配边的匹配属性互换。
定义10(顶标) 在集合M1和M2中,为每个元素定义一个特征参数作为顶标,分别记作LM1(i)和LM2(j),其中i,j∈[1,m],表示两个集合中的各个元素。顶标通常被用在算法中,作为匹配的约束变量。
3.2 匹配约束
定义11(边权) 定义组成边的两个元素M1i和M2j之间彼此的倾向程度为边权,记作u(i,j)。所有的边权组成的集合记作u={u[i,j]|i,j∈[1,m]}。
定义12(匹配约束) 两个集合中的元素间能进行匹配的条件。在KM中,M1和M2之间匹配约束为满足条件LM1(i)+LM2(j)=u(i,j)。
规则1(顶标修改法则) 寻找R-path过程中,若经过M1和M2中的元素序号集合分别为T1和T2,令:
slack=min{LM1(i)+LM2(j)-u(i,j),i∈T1,j∉T2}
(1)
则顶标修改法则为:
(2)
3.3 KM匹配
KM算法实质是按照顺序遍历M1中的每个元素,在匹配法则的约束下,为算法结束前的每一个元素,寻找一条R-path。通过判断~R-path是否为完美匹配,以此作为算法结束标识。对于给定具有m个元素集合M1,M2及边权u,可将KM匹配过程描述如下:
Algorithm1KM(M1,M2,u,m)
Line 1 初始化:LM1(i)=max{u(i,•)|i∈[1,m]},LM2=O1×m,R-path=∅,Match=Om×1
Line 2 foro=1:m
Line 3 (R-path,T1,T2)=Search_R-path(M1(o),R-path)
Line 4 if(R-path==∅)
Line 5 计算slack,更新T1和T2对应序号处LM1与LM2的取值,即LM1(T1)和LM2(T2)
Line 6 goto Line 3
Line 7 else if(n~R-path==m-1)
Line 8 break
Line 9 else
Line 10R-path=~R-path
Line 11 continue
Line 12 end
Line 13 end
Line 14 end
Line 15R-path=~R-path
Line 16 基于~R-path,确定Match

Line 18 return Match,u_all
由于R-path的未匹配边比匹配边的数量多1,对R-path取反可以使得匹配边数量增加1条。因此,满足n~R-path=m-1的R-path取反,即为最优匹配。u_all表示输出参与匹配的边权值总和。篇幅原因寻找增广路径函数Search_R-path的搜索过程不做描述,详细过程可参阅文献[7-8]。
3 KSDE算法
3.1 基本思路
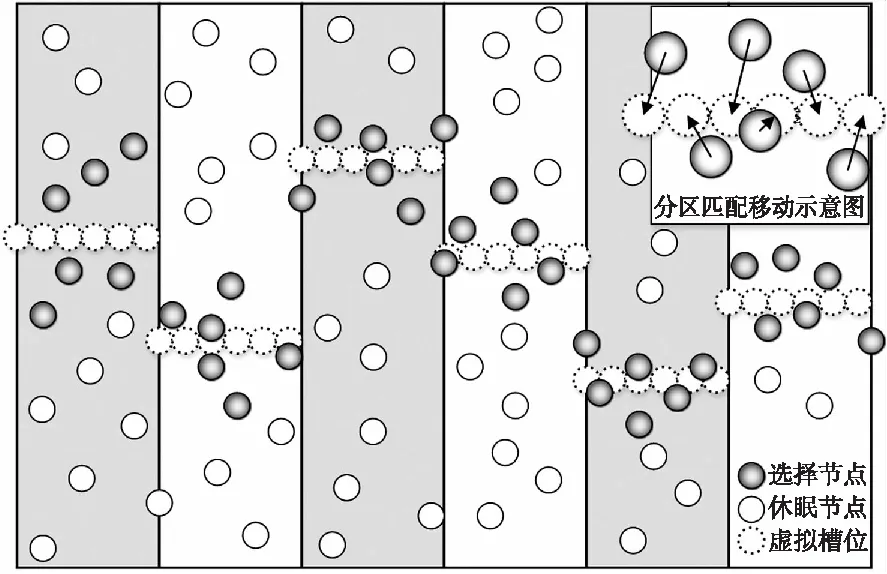
为了兼顾网络闭合性与节点平均移动成本的双重增益,论文设计了一种分布式弱栅栏覆盖算法KSDE。KSDE将整个区域分成n_part个长度为select_length=B/n_part子区域I(k),k∈[1,n_part]。在每个子区域I(k)内选择部分传感器节点移动,构造一条栅栏,剩下的节点进入休眠状态。最经济的节点排列方式显然为节点之间相距2r。为便于算法设计,将节点移动后的位置模拟成圆形槽位,槽位圆心坐标集为Slot,槽位半径rs=r,则形成栅栏所需要的槽位数量为n_slot=floor(select_length/2r),其中floor为向上取整函数。算法将利用KM匹配,为每个子区域I(k)内的节点,找出一种移动到槽位距离和最小的节点选择策略,及其与槽位匹配的方法。算法采用分布式设计,各个子区域互不影响,并行寻找属于自己的匹配策略,构建自己区域内部的栅栏。
3.2 选择框的设计
将给定区域I划分成若干个子区域,可以将全局搜索栅栏位置的工作,转化成多段栅栏子段构建的过程。对于每个子区域I(k)而言,设置一个从底部向上,宽度为select_width,且以d为步长的选择框select_box(k,t),其中t={t|select_box(k,t)⊂I,t∈Z+}为步数标识,若select_box(k,t)内包含Nsec个节点的子集Ssec={Ssec_i|1≤i≤Nsec}。分区选择框步进过程如图2所示。
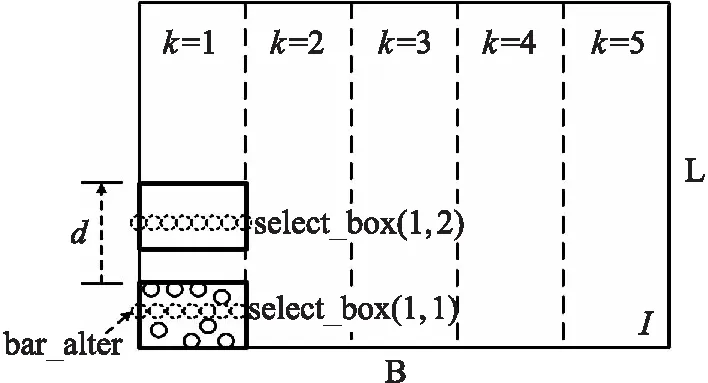
图2 I的分区和选择框步进示意图(n_part=5)
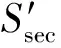
3.3 bar_alter位置的选择
在给定的select_box(k,t)中,bar_alter的纵轴位置,直接决定着所形成栅栏的位置,关系着节点移动的距离,在不引起混淆的情况下,论文以bar_alter同时表征备选栅栏的纵坐标位置。因此bar_alter的确定应能对节点分布具有自适应性能,应尽量避免个别孤立节点对bar_alter位置确定的偏离影响。如图3所示,S1~S7可以通过较少的移动,形成一条栅栏bar_alter。如果采用节点纵轴平均法计算备选栅栏,孤立节点S8,S9,S10会导致bar_alter向上偏移成为bar_alter′,为构建栅栏bar_alter′引发的节点移动距离和,明显较构建bar_alter有所增加。因此,需要首先对孤立节点的存在情况进行判断。
3.3.1 孤立节点的判定
由图3可知,孤立节点的存在直接影响bar_alter选择的合理性。
图3 节点不均匀分布下对备选栅栏的影响
孤立节点的定义及条件如下:
定义13(孤立节点) 在给定select_box(k,t)内,与节点纵坐标均值的距离大于选择框宽度的一半的节点Ssec_h(xsec_h,ysec_h)。其判断条件为:∃Ssec_h(xsec_h,ysec_h)∈select_box(k,t)且满足式(2)成立:
(3)
3.3.2 bar_alter的确定
根据内部节点分布情况,对于不存在孤立节点的select_box(k,t),其bar_alter的位置可以采用节点坐标均值法进行确定。而对于存在孤立节点的select_box(k,t),其bar_alter的位置计算可描述如下:
首先,采用加权平均法进行宏观定位。将select_box(k,t)分成p块,统计每个块中节点的个数Ve及节点纵坐标和Yee∈[1,p],通过加权平均得到bar_alter的模糊位置。
接着,基于节点与模糊位置的垂直距离,取距其最近的n_slot个传感器节点递减重排,采用指数平滑法对模糊位置进行精确调整,得到bar_alter的精确位置。
综上,bar_alter位置的自适应确定算法可描述为:
Algorithm2Bar_Alter(select_box(k,t),Ssec,p,a)
Line 2 基于定义13,搜索Ssec_h
Line 3 if(Ssec_h≠∅)
Line 4 基于select_box(k,t)和p,统计Ve和Ye
Line 7 for(e=1:n_slot)
Line 9 end
Line 10 end
Line 11 return bar_alter

3.5 算法流程
Algorithm3KSDE
Line 1 参数初始化I,S,select_width,n_part,n_slot,a,d,p,r
Line 2u_part=∞n_part×1,Match=O1×n_slot,MATCH=On_part×n_slot,u_best=0,pass=0
Line 3 fork=1:n_part
Line 4t=1
Line 5 选择框初始化select_box(k,t)
Line 6 while(select_box(k,t)⊂I)
Line 7 基于select_box(k,t),建立子集Ssec
Line 8 bar_alter=Bar_Alter(select_box(k,t),Ssec,p,a)
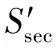
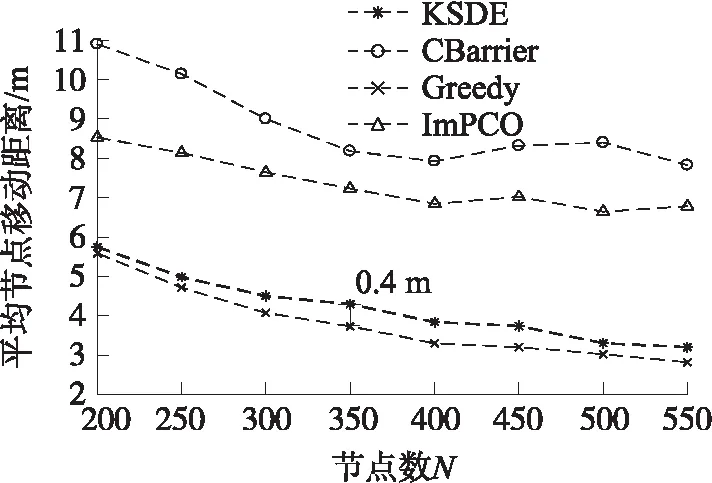
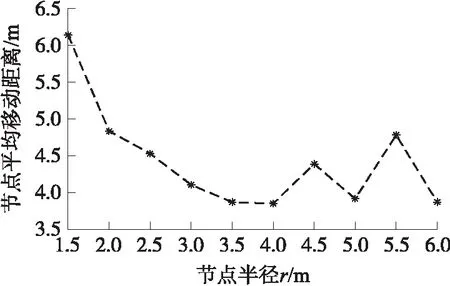
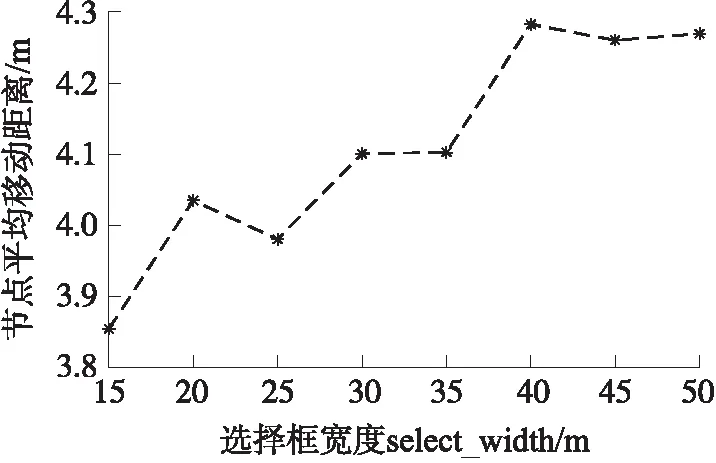
Line 11 if(|pass| Line 12 MATCH(k)=Match Line 13u_part(k)=|pass| Line 14 end Line 15 select_box(k,t)向上步进d,t++ Line 16 end Line 18u_best_average=u_best/(n_part·n_slot) Line 19 end Line 20 output u_best_average,MATCH 多维数组MATCH用来存放各分区最终采用的匹配对应关系。u_part用来存储各个分区节点最小移动距离和。u_best_average为参与算法的节点的平均移动距离。根据MATCH选择节点进行移动,将剩下的节点置于休眠状态,实现以少量节点完成弱栅栏覆盖,得到匹配效果展示如图4所示。 图4 KSDE匹配效果图 论文采用了MATLAB R2016b平台进行仿真实验。区域设置为I=B×L,其中B=300 m,L=100 m。传感器节点集S随机分布在区域I内,且为连通网络。其他参数在实验中不做特殊说明时,默认设置如下:N=400,n_part=6,select_width=30 m,a=0.5,p=4,d=3 m,r=3 m。 为了验证算法的性能,将论文提出的KSDE,文献[2]提出的ImPCO,文献[3]提出的CBarrier算法和基于遍历原理的贪婪算法(Greedy)进行平均距离及闭合性的对比。Greedy遍历精度设置如下:选择框宽度以 1 m 为间距遍历4 m~50 m,选择框垂直步进步长细化到0.01 m,以近似模拟遍历所在子区域的所有情况。鉴于实验数据的随机性,为保证实验比较的公平性,所有实验数据均采用20次独立实验的均值[12]。 对于传感器网络而言,节点移动的距离直接关系着网络的能耗,对网络寿命的影响至关重要。本实验通过节点数量的改变调控网络规模,考察在KSDE,CBarrier,ImPCO,和Greedy 4种算法中,网络规模对节点平均移动距离的影响,以此间接评估算法在不同规模的网络中能量消耗的有效性。实验设定网络节点的规模数为N∈[200,550],并以50作为节点数目的增长间距进行实验。 从图5给出的实验数据可以看出:随着节点数N的增加,4种算法的平均移动距离均呈现出下降的整体趋势,即网络以节点投入数目的增加可以换取节点平均移动距离的减小,从而降低单个节点的平均移动能耗。论文提出的KSDE与已有的CBarrier及ImPCO相比,具有更小的平均移动距离(小于6 m),能以小于0.4 m的距差,较为稳定的逼近理想情况的Greedy算法。 图5 节点数目对平均移动距离的影响 节点数目的投入可以赢得平均移动距离的减小,从而实现闭合性能的同时控制能耗,但对于大规模网络(N≥350)而言,4种算法的节点平均移动距离的减小增益逐渐减弱,甚至在CBarrier算法中出现负增长,当N≥400时ImPCO节点的平均移动距离逐渐稳定,说明此时对于应用ImPCO算法的网络此时已经逐渐饱和,因此应注意网络规模与移动节点能耗之间的平衡利用。 网络闭合性的表现,直接决定着算法所构建的栅栏的有效性。在给定的默认网络场景中,本实验将通过调节网络分区目数n_part∈[3,10],评估基于不同数目的分区划分下,包括KSDE,CBarrier,ImPCO 和Greedy在内4种算法所形成的弱栅栏,能提供的网络闭合性能。 实验以网络底边作为起点边,顶边为终点边。选择起点边的两个端点及其中间点,分别作为测试起点,每个测试起点均引出一条射线作为闭合测试使用,并以1°为旋转单位,扫描整个终点边,测试射线被各子区域栅栏感知到的比率,就是该测试起点的闭合性,所有测试起点闭合性的均值为网络闭合性。 分区数目在3种算法中,对网络闭合性的影响情况,如图6所示。基于实验数据可见,随着分区数目n_part的增加,4种算法的网络闭合性都表现出整体下降的趋势。在n_part较小时,4种算法的网络闭合性随n_part的增大逐渐降低;进一步,随着n_part 的持续的增长,弱栅栏断续现象趋于明显,会在一定程度上削弱网络的闭合性,在图中的体现为:当n_part>6时,各算法闭合性的下降趋势均出现不稳定波动。由此可知,当分区数较少时,某条栅栏的位置会对整体闭合性产生非常大的影响,经过后续扩充样本试验,既增加实验次数后,分区数较小时网络覆盖率的曲线波动幅度明显降低。就网络闭合性曲线的整体趋势而言,KSDE以稳定高于80%的闭合性能,在4种算法中的表现最佳,且随着分区数的增加闭合性平滑递减,稳定性较好;CBarrier,ImPCO及Greedy的闭合性能相对不稳定,随着n_part的增加,3个算法的闭合性能交替加速下降。 图6 分区对网络闭合性的影响情况 节点半径的增加会扩大覆盖的范围,显然可以有效减少给定子区域内构建栅栏所需的节点总数,但同时地会影响参与匹配的节点选择。实验在默认场景中,通过改变节点半径r,分析探究节点感应能力的变化,对节点在平均移动距离的影响。 节点在r的不同取值时的平均移动距离情况如图7所示。 图7 节点半径对平均移动距离的影响 当r<4 m时,呈现出随着节点感应能力提高,节点平均移动减少的趋势,且减小的趋势逐渐变缓。随着节点感应范围的进一步增大,节点参与匹配的偶然性随之增大,r和平均移动距离的之间不再具有稳定的变化关系,而出现齿状曲线。可见,对于r的设定并非越大越优,鉴于实验数据的分析,在r∈[3 m,4 m]时,是比较合适的取值范围。 增加选择框宽度select_width,对算法效率而言,增大的框内区域可以更快确定分区内栅栏,减少算法运行时间;但从算法能效而言,增大的框内区域势必增加更多的冗余节点参与匹配,影响备选栅栏的位置,进而扩大节点平均移动距离。本实验在给定默认实验场景中,通过改变select_width,分析前者对节点平均移动距离的影响。 从图8中节点平均移动距离的变化情况可以看出,随着select_width的增加,节点平均移动距离呈现出近似阶梯状的上升趋势。根据KSDE关于栅栏的确定方式可知:距离栅栏越远的节点对栅栏的生成影响越小,因此当select_width增大到某个值时,新进入选择框的节点对节点匹配的影响将趋近于零。在图中的表现为节点平均移动距离上升趋势在select_width≥40后消失,此后的节点的平均移动距离不再受到select_width变化的影响并逐渐稳定在4.28 m左右。 图8 select_width对节点平均移动距离的影响 针对弱栅栏覆盖的覆盖率和移动距离相互制约的关系,论文提出了一种分布式的弱栅栏覆盖节点选择算法KSDE,力求以较小的移动损耗,选择合适的节点参与栅栏构建,赢得更高效的网络闭合性。同时进一步深入探究了传感器节点数量、分区数等参数对平均移动距离影响关系,实现了在传感网络中,构建弱栅栏覆盖所需要传感器节点的合理选择。在同构传感网络中,KSDE构建弱栅栏覆盖具有不错的表现,但在异构传感网络中,KSDE构建弱栅栏覆盖的性能还需要继续探究。
4 仿真实验
4.1 实验说明
4.2 对比分析-节点平均移动
4.3 对比分析-闭合性

4.4 性能分析-节点半径
4.5 性能分析-选择框宽度
5 总结
猜你喜欢
环球时报(2022-03-29)2022-03-29 17:14:11
数学小灵通(1-2年级)(2021年10期)2021-11-05 07:20:38
知识经济·中国直销(2018年7期)2018-07-27 02:49:52
数学小灵通(1-2年级)(2017年9期)2017-10-13 08:10:11
山东青年(2016年1期)2016-02-28 14:25:25
电测与仪表(2015年8期)2015-04-09 11:50:16
电测与仪表(2015年7期)2015-04-09 11:40:16
第二课堂(小学版)(2014年4期)2014-08-02 17:39:17
当代修辞学(2014年3期)2014-01-21 02:30:44
公务员文萃(2013年5期)2013-03-11 16:08:37
