
山东胶东金矿综合信息矿产预测
2018-12-04 09:11:20王海芹刘继梅王秀凤
上海国土资源 2018年4期
王海芹,陈 莉,刘继梅,王秀凤
(1. 山东省地质科学研究院,山东·济南 250013;2. 国土资源部金矿成矿过程与资源利用重点实验室,山东·济南 250013;3. 山东省金属矿产成矿地质过程与资源利用重点实验室,山东·济南 250013)
随着我国经济的飞速发展,矿产资源的勘查与开发形势也发生了翻天覆地的变化,找矿难度日益加大,找矿对象已从露头矿、浅部矿和易识别矿转变为隐伏矿、深部矿及难识别矿。随着找矿难度加大,应用新理论新技术新方法提高成矿预测水平和找矿效果,最大限度地减少地勘投入风险,实现找矿工作重大突破。
综合信息成矿系列预测是王世称等提出来的基于综合信息分析的一种预测方法[1-5]。理论基础是指应用能够反映矿床形成、分布规律和控矿因素的地质、地球物理、地球化学、遥感地质等一系列方法所获得的有关信息对矿产资源体所作的预测工作。其核心是通过合理地进行地质、物探、化探、遥感等综合信息解译,揭示成矿规律,用间接成矿信息代替直接成矿信息,指导找矿工作。
本次研究通过综合信息解译和编制矿产预测图,提取控矿信息,从具体控矿条件出发,建立实用的找矿模型去预测找矿靶区;强调以地质体为单元,定性研究与定量分析相结合,通过直接成矿信息与间接找矿信息相关联和合理转换,达到矿产预测的目的。综合信息矿产预测以找矿模型为基础,以计算机技术为工具,以各种数学模型为手段,充分开发各类矿产地质资料蕴含的成矿信息,有利于实现矿产资源立体化预测,提高矿产预测的科学性。综合信息矿产预测侧重于定位预测,因此能够提供普查勘探靶区,便于及时开展靶区查证工作。
1 地质背景
研究区位于沂沭断裂带以东,胶东半岛中北部地区。按照板块构造的划分,该区大地构造区划属华北板块(Ⅰ级)之胶辽隆起区(Ⅱ级)和秦祁昆造山系之秦岭—大别—苏鲁造山带(Ⅱ级)二个Ⅱ级大地构造单元的结合部位。而研究区主要位于胶辽隆起区(Ⅱ级)之胶北断隆(Ⅲ级)和胶莱拗陷(Ⅲ级)二个Ⅲ级构造单元中,尤其是胶北断隆内(图1)。受区域地质构造环境的制约,区内沉积建造、构造运动、岩浆—火山活动和各种矿产的形成均受其控制。
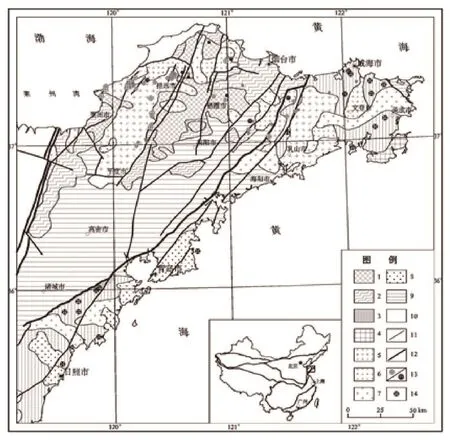
图1 胶东地区大地构造位置Fig.1 The tectonic location in Jiaodong area
胶北断隆区以前寒武纪结晶基底为主,基底有中太古代唐家庄岩群、晚太古代胶东岩群、古元古代荆山群、粉子山群和中元古代芝罘群,新元古代蓬莱群;在中生代断陷盆地内有白垩纪莱阳群、青山群和王氏群分布;在龙口断陷盆地中有古近纪五图群碎屑岩系及含煤岩系,但未在地表出露;在山前平原区和沿海地区有第四系展布。
区内岩浆侵入活动强烈而频繁,所形成的侵入岩区内基岩面积的50%以上。总体呈近东西或北东向展布的岩基、岩株、岩瘤状产出,具规模性的多群居聚集形成复式岩体。岩石类型齐全,从超基性-酸性者均有,尤以中酸性、酸性者规模大、分布广。形成时代自中太古代至新生代均有见及,其中以中生代燕山期侵入岩最发育,栖霞TTG岩系、玲珑花岗岩和郭家岭花岗岩与金矿息息相关。区内断裂构造十分发育,以NE-NNE向为最,北东向次之,另外尚有北西及近东西向断裂,前二者系金控矿(容矿)构造,它们均表现出多期性、继承性和力学性质的不同和转换等特点。
2 预测技术
地、物、化、遥、矿化等多源地学信息是进行综合信息成矿预测的基础。成矿预测的途径是变地质问题为数学问题。这种研究的思路就是把地质标志或地质现象都视为地质变量,寻求地质变量之间的内在关系,并用一定的数学公式描述变量之间的关系。地质变量是指某地质标志或地质现象随着空间位置变化而取不同数值的信息,也称为统计变量。地质变量的研究包括变量的选择、提取、转换和赋值以及优化筛选等方面。
2.1 地质变量的选择
矿产预测中,地质变量的提取是正确使用变量的关键,是变量提取、转换和赋值的基础。在研究区成矿规律、控矿条件、找矿模型研究的基础上,选择单元成矿的因素,针对各个预测单元提取不同时期变质地层、沉积地层;不同方向的断裂构造、构造发育程度;不同时期岩浆岩岩性;重力场强度、类型;磁场强度、类型;地球化学单元素异常、地球化学元素组合异常;矿化类型;重砂异常等自变量,通过影响成矿的各类信息来提取预测单元的变量。本次研究选择原始变量分类,见表1。

表1 原始变量分类Table 1 Original variable classification
(1)地层变量的选择
研究区内地层变量的选择主要根据区内与金矿形成密切相关的地层:地层出露相对零星。新太古代胶东岩群呈残留体和包体零星分布于玲珑花岗岩体中,新太古代胶东岩群被认为是胶东金矿的原始矿源层、新太古代片麻岩套构成胶东地区前寒武纪变质基底岩系、古元古代荆山群、粉子山群。共选择地层变量2个,一是古元古代粉子山群,二是古元古代荆山群。
(2)侵入岩变量的选择
研究区内岩浆侵入活动剧烈而频繁,岩石类型尤以中酸性、酸性者规模大、分布广,与区域成矿具有极为密切的关系。其中以中生代燕山期侵入岩最发育,玲珑花岗岩、郭家岭花岗岩与金矿息息相关,共选择侵入岩变量10个,见表2。
(3)断裂构造变量的选择
研究区内北北东—北东向断裂构造是预测区尤为突出的一组线性构造,是主要的导矿、容矿、控矿断裂构造。该区几乎所有的金矿(点)床都产于北北东—北东向断裂中,分布于主要断裂成矿带和之间的区域。著名的三山岛、焦家、新城、马塘、寺庄、玲珑、台上、大尹格庄、夏甸等众多的金矿床均置身于该断裂系统之内,共选择变量8个(表2)。

表2 胶东地区侵入岩与构造变量Table 2 The variables of intrusive rocks and tectonic in Jiaodong area
(4)地球物理变量选择
通过对区域地球物理场的分析,将地球物理场分为不同的场区形态,不同的场区不仅预示着不同的地质体(可能是隐伏岩体),同时也是区域地球物理现象的综合体现,因此地球物理变量对找矿的意义不容轻视。共选择地球物理变量12个(见表3)。
(5)地球化学场变量选择
化探异常和化探组合异常也是区域矿化的重要指标,因此根据区域地球化学研究选择单元素地球化学异常4个,金异常与其他单元素异常的套合好与不套合等共2个(见表3)。
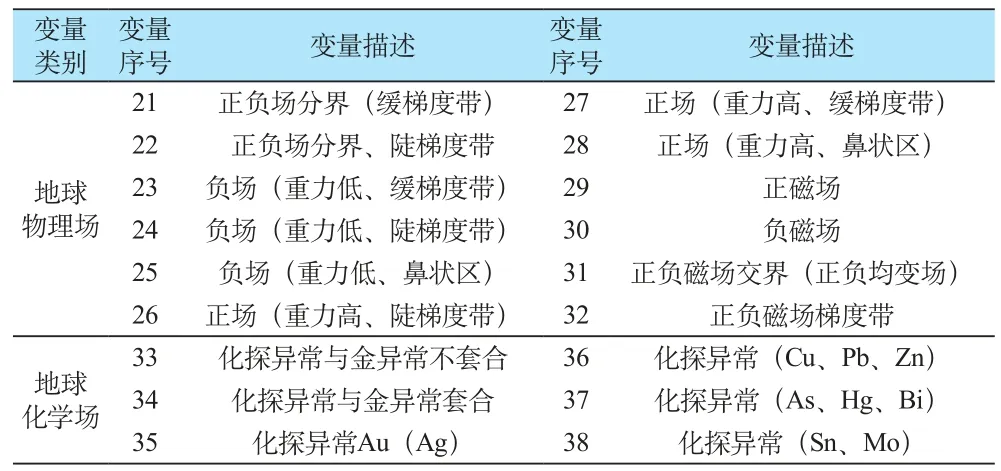
表3 胶东地区地球物理与地球化学变量Table 3 Geophysical and geochemical variables in Jiaodong area
(6)矿床变量选择
不同的元素矿化组合类型,可能会指示不同的成矿系列。成矿系列对某一成作用的存在是具有确定意义。统计预测单元内分布矿床(点)的存在,提取出已知预测区矿床(点)的矿化信息,共提取矿点变量4个,即39-大型金矿、40-中型金矿、41-小型金矿、42-金矿(化)点。
(7)重砂变量选择
区内金、铜、铅、黄铁矿异常分布均匀,吻合程度高,异常展布方向除受水系的发育控制外与地质、构造、矿产分布关系极为密切,推断异常形成于区内的金矿及局部矿化有关。所圈异常对寻找金矿及多金属矿产具有很好的找矿意义。研究成果共选出3变量,即43-重砂金异常、44-重砂异常(铜、铅)异常、45-重砂黄铁矿异常。
2.2 信息的提取与赋值
进行矿产预测工作,重要的一步是将地质模型(即由地质变量组成的数据型模)转化为计算机能够接受或者说数学统计方法认可的数学变量。这一过程就是将原始资料中所提取的变量,从文字性描述、数值型描述转换为统一数字模式。
(1)地层变量提取与赋值
研究区内成矿有关的地层主要包括:新太古代胶东岩群(呈残留体和包体零星分布于玲珑花岗岩体中)、新太古代胶东岩群(被认为是胶东金矿的原始矿源层)、新太古代片麻岩套(构成胶东地区前寒武纪变质基底岩系)、古元古代荆山群、粉子山群。其它地层与成矿也有一定的对应关系。该类变量都为二态变量。赋值方法是:一般地层变量如果在统计单元内出现则该变量在该单元上取值为1,反之取0。
(2)岩浆岩变量提取与赋值
其中以中生代燕山期侵入岩最发育,玲珑花岗岩、郭家岭花岗岩与金矿矿体的出现密切相关。岩浆岩体是区域成矿的动力基础、物质基础以及成矿活动的载体。其它不同时期不同岩性的岩浆岩体都表明了区域内具有成矿的潜力。赋值方法:存在某侵入岩体取值为1,不存在为0。
(3)构造变量提取与赋值
与断裂构造有关的变量共有8个。赋值方法是该地质特征在单元内出现与否来取值。存在某变量取值为1,不存在为0。
(4)地球物理类变量提取与赋值
该类变量有重力和航磁两种。与重力异常有关的变量有8个。与航磁等值线有关的变量有4个。赋值方法:存在某变量取值为1,不存在为0。
(5)地球化学类变量提取与赋值
该类变量共有6个。分别为化探异常Au(Ag)、化探异常(Cu、Pb、Zn)、化探异常(As、Hg、Bi)、化探异常(Sn、Mo)单元素异常变量存在与否、单元素与金异常的套合好与不套合,根据上述异常是否在单元内出现来赋值,存在为1,反之为0。
(6)矿床相关变量提取与赋值
矿床相关类变量,是指单元内出现的矿化类型,只考虑该种矿化在单元内存在与否即可。赋值方法:存在某矿床取值为1,不存在为0。
(7)重砂类相关变量提取与赋值
重砂类变量包括金、铜、铅、黄铁矿重砂异常。这一类变量只考虑单矿物重砂异常在单元内存在与否即可,存在为赋值为1,反之赋值为0。
3 综合成矿信息预测结果
矿产资源的定位预测,是对由矿床成矿模型和找矿预测模型所定义的成矿必要条件所限定的空间范围(预测单元)作进一步的成矿概率评价。
预测单元(地质统计单元)的划分方法有两种,分别是网格单元法和地质体单元法。本次预测工作选用地质法。为了数学模型计算的准确性,把胶东地区分A、B、C三个分区:招远—莱州分区、西林—毕郭分区、威海—乳山分区,三个分区中共计135个单元(如图2)、45个取值变量。
通过统计评估每一个预测单元的成矿可能性大小,从中优选出成矿可能性较大的矿产资源体作为进一步找矿工作的靶区,并查明这些矿产资源体成矿可能性变大的主要控制因素。本研究选用特征分析法对预测变量进行优选。然后综合使用特征分析法、Q型聚类分析法、数量化理论和对应分析法对预测单元成矿概率进行评价,实现对单元的定位预测。
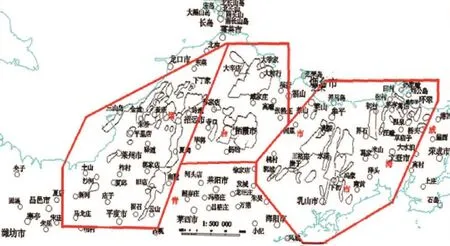
图2 胶东地区最小预测区分布Fig.2 Distribution of minimum predicted area in Jiaodong
3.1 特征分析法变量优选
对招远—莱州分区进行特征分析后,变量的权系数如表4,变量的权系数趋势见图3-a。从图中可以看出,招远—莱州分区变量权系数出现台阶状的变化趋势,如果以台阶值作为阀值作为优选变量的条件,根据不同的台阶阀值则可按要求优选出不同数目的变量以供使用。例如以权系数0.02为界划分变量,大于0.02变量为18个;如果以权系数0.005为界,将变量分为两群,大于0.005变量共有34个。为了保证后期有足够的变量,这里采用0.005阀值选出34个变量(表4)。
3.2 数学模型的建立
根据以上优先出的变量,结合有矿单元建立预测模型。本文以招远—莱州分区为例进行模型单元的建立。数学模型通过suffer软件对优化后的数据矩阵进行特征分析,得出有矿单元的单元联系度。

表4 招远—莱州分区初步优选变量标志权系数Table 4 Index weight coefficient of initial optimal selection variable in Zhaoyuan-Laizhou subarea
单元的联系度反映了成矿可能性的大小。因此根据已知单元的单元联系度分析可以建立单元成矿分级模型。将已知单元的成矿联系度按由大到小的排列,可以看出成矿联系度呈阶梯状排列,这就为分级模型的建立提供了较好的条件,这里将已知单元按联系度大小分为四级,分别是A、B、C、D,见图3-b。
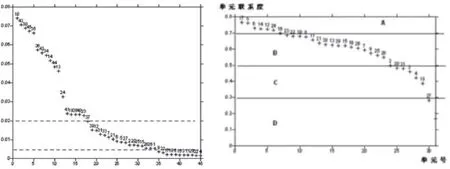
图3 招远—莱州分区模型单元特征分析变量权系数(a)与联系度变化(b)趋势图Fig.3 The trend chart of variable weight coefficient of feature analysis (a) and relation degree change (b) of model unit in Zhaoyuan-Laizhou subarea
A级单元:联系度大于0.7,为成矿概率大的单元;B级单元:联系度介于0.5~0.7之间,为成矿概率较大单元;C级单元:联系度介于0.3~0.5之间,为成矿概率一般单元;D级单元:联系度小于0.3,为成矿概率很小单元。
3.3 综合信息找矿
一般而言通过一种方法即可得到想要的结果,这一结果是否可靠需要多方检验。一种有效的检验方法就是多种方法同时使用,从不同角度、用不同理论去解释同一问题,如果仍能得到有效的结果,说明我们使用的手段是可以信服的,可以推而广之的。因此对研究区矿产的定位预测我们采用特征分析法,同时又辅以Q型聚类分析、数量化理论IV和对应分析法三种手段来对得出的结果加以修正。根据各种方法解决问题的思路、数学原理和作用等因素,对各种方法得到的结果进行综合评估,评估的基本原则是:在以特征分析所得结果为基础之上,对每种方法得出的结果都要充分信赖,通过加权得出综合评估结果(见表5)。

表5 胶东地区招远—莱州分区定位预测综合分析结果Table 5 Comprehensive analysis results of location prediction for Zhaoyuan-Laizhou subarea in Jiaodong area
根据预测结果,对当前和未来找矿工作具有明确的指导意义。对研究区中成矿的可能级别进行了综合表述。A级区:A级区所处位置的成矿条件优越,有大、中型金矿床多处,矿点、矿化点众多,有Au异常及其它矿化信息充分,具有明确的找矿价值。B级区:有中、小型金矿床多处,B级区所处位置成矿条件良好,矿化信息也相对充分,但部分手段评价结果有降低趋势,因此总体找矿价值低于A级区。C级区:有小型金矿床,C级区所处位置,成矿条件一般,没有显著的矿化信息,且多种手段评价结果一般,找矿前景不明确。D级区:D级区所处位置,成矿条件较差,没有已知矿化信息存在,多种手段评价结果都为负面,成矿级别最低。
4 结论
对胶东地区划分了三个成矿区中135个预测单元采用特征分析法,辅以Q型聚类分析、数量化理论和对应分析法三种手段进行定性预测,对定性预测的结果通过加权法进行综合评估验证,共圈出A级区31处,成矿条件优越,有大、中型金矿床多处,矿点、矿化点众多,有Au异常及其它矿化信息充分,具有明确的找矿价值;B级区55处,所处位置成矿条件良好,矿化信息也相对充分,但部分手段评价结果有降低趋势;C级区36处,找矿前景不明确;D级区13处,成矿条件较差,没有已知矿化信息存在。预测结果与新近掌握的实际资料、目前地质工作情况及我们的经验与认识是比较吻合的。
猜你喜欢
四川大学学报(自然科学版)(2023年1期)2023-04-29 00:44:03
建材发展导向(2022年24期)2022-12-22 07:44:36
榆林学院学报(2022年4期)2022-08-02 14:30:42
环境卫生工程(2021年4期)2021-10-13 06:52:26
少儿美术(2020年9期)2020-11-05 09:12:02
计算机与生活(2018年8期)2018-08-15 08:24:34
文史春秋(2016年6期)2016-12-01 05:43:06
中国市场(2016年12期)2016-05-17 05:10:42
理科考试研究·高中(2016年9期)2016-05-14 00:12:18
大众考古(2015年12期)2015-06-26 08:53:16
