
视觉假体中动态图像识别研究
2018-12-04 02:14耿秀琳蒋广琪
计算机工程与应用 2018年23期
赵 瑛,耿秀琳,李 琦,蒋广琪,谷 宇,2
1.内蒙古科技大学 信息工程学院,内蒙古 包头 014010
2.上海大学 计算机工程与科学学院,上海 200444
1 引言
可提供超过70%的外界信息的视觉是人类感官系统中最为重要的感觉之一,也是人类认知和了解真实世界的最主要途径,一旦失去视觉,人将无法对外界信息进行感知[1],并对其学习、生产、生活等各类社会和个人活动带来很大的影响[2]。
世界卫生组织2011年8月的统计数据显示,全球共有2.85亿人受到视力损伤问题的困扰[3]。82%的盲症病人年龄在50岁以上,此类人群患盲症的主要原因是白内障和老年性黄斑变性(Age-related Macular Degeneration,AMD)。白内障基本可以治愈,但AMD尚未取得有效治疗手段,这成为老年人致盲的主要原因之一[4]。除此之外,视网膜色素变性(Retinitis Pigmentosa,RP)也是导致视觉受损的主要原因,该病在人群中的发病率约l/3 500~1/7 500,其中约1/3~1/2的病例具有遗传背景[5]。由RP和AMD致盲的原因是视网膜外侧的光感受细胞凋亡而失去感光能力,而视网膜视觉假体能够绕过感光细胞层直接作用于视网膜内侧的神经节细胞,产生人工视觉,从而为这类人群提供了恢复视觉的可能[6-7]。
视网膜视觉假体可帮助由于疾病或外伤导致失明或低视的人们通过绕开视觉通路中的受损部分产生视觉感知[8-9]。它是一种新兴电子装置,可将外部采集图像经计算机处理、编码后,通过无线发射模块传输给植入人眼的接收模块和微电流刺激器,通过对视觉通路中的视网膜、视神经或视皮层等部位进行电刺激,使盲人获得相应的图像信息。受到电极数量的限制,现阶段的视觉假体并不能将外部采集到的全部的图像信息提供给假体植入者,所以,如何将有限数量电极采集到的部分图像信息提供给假体佩戴者,帮其形成可理解的视觉感受,依然是亟待解决的问题[10]。
虽然在视觉假体的研发上,已有美国的Second Sight公司的Argus II视网膜上假体和德国Retina Implant AG公司的Alpha-IMS视网膜下假体先后通过美国和欧洲授权,获准投入市场销售[11-15],但多数研究工作是先通过仿真假体视觉的方式开始,再过渡到临床实验。国际上多个研究小组已在文字阅读、物体以及环境识别等方面运用心理物理学及图像处理方法进行大量的仿真假体视觉的研究。澳大利亚仿生视觉联盟评估了影响视觉知觉阈值的因素,以及如何优化刺激参数以达到植入脉络膜视网膜假体患者的最低阈值[16]。美国Cha[17]等人针对皮层视觉假体开展了对正常人在低像素化下完成拉丁语系文字阅读和手眼协调任务的研究,并且发现由每个像素点占据1.7°视野的625个(25×25)像素点组成的仿真光幻视阵列可帮助假体佩戴者达到20/30的视觉敏锐度[18]。Humayun小组研究的视网膜上假体电极数量从16个增加到60个,并正在为制造250个乃至超过1 000个刺激电极而努力[19]。南加州大学的Humayun[20]和约翰霍普金斯大学的Dagnelie[21]等人还开展了阅读和面部识别的仿真假体视觉研究,证明了光幻视以正方形阵列呈现100至1 024个均匀点时句子的阅读速度为每秒75到100字,并且接近完美的面部识别是可能的。同时Dagnelie[22]还采用虚拟现实的方法完成图像识别的研究,结果表明视网膜植入60个电极可能为盲人提供独立的寻路能力,但是独立完成寻路任务还需要大量的实践和监督。国内北京大学和上海交通大学等单位联合的C-Sight研究团队针对动物实验采用刺入式金属微丝电极阵列刺激视神经并验证了其有效性[23]。已有的研究虽然取得许多突破性的进展,但克服植入电极阵列数量有限、电极尺寸、功耗、散热、生物相容性等诸多问题,并最有效的配置电极的位置和数量仍然是研究的核心[24]。通过正常视力的被试者参与仿真假体视觉实验来评估所给电极阵列的潜在益处可为临床研究及康复训练提供有效的评估参数。
本文使用一系列图像处理策略将动态视频处理成低分辨率的动态视觉信息,同时借助简化的Itti算法提取特征点,并与空间、时间信息相结合算法进行视频复杂度分析来分类有效信息,通过实验,比较不同分辨率下识别时间和识别准确率的变化情况,确定低分辨率动态图像识别过程的规律以及其所需要的最小信息及可优化参数,达到理解认知过程的目的。
2 材料与方法
2.1 被试的选取
二十名志愿者招募自内蒙古科技大学研究生院,均具有正常或矫正视力(十名女性,十名男性,年龄在20至30岁),且母语为汉语。所有受试者在实验前均被告知实验的过程和目的,并签署知情同意书。
2.2 实验所需设备和环境
实验平台包括一台个人电脑(联想 30AGA29BCN Tower台式电脑,Windows8.1,64位操作系统,英特尔Xeon(至强)E3-1241 v3@3.50 GHz四核处理器,联想SHARKBAY主板8 GB内存和Nvidia Quadro K620的显卡),摄像头(罗技c920),tobii眼动仪,ErgoLab,SPSS,C,C++,绘声绘影,oCam以及宏乐录音等软件。实验在一间干净且没有噪音的实验室中进行,实验前确保被试者没有其他干扰,保持放松。实验通过ErgoLab控制实验过程,期间通过tobii眼动仪监测眼动数据,并借助摄像头,oCam以及宏乐录音记录实验过程和识别时间以及识别准确率,实验结果进行单因素方差分析,最小显著差数法(Least Significant Difference,LSD法)等相关分析。
2.3 构建实验素材库
本研究中选取24个动态视频,其中包括8个动物视频,8个实物视频以及8个人物视频。视频是其绘画过程。其中,动物视频包括飞禽,走兽,海洋动物等等;实物视频包括蔬菜,水果,植物,交通工具和军用器材;人物视频包括男人,女人,男孩,女孩,老人等。这些种类在实验之前将会提前告知被试,便于识别。每个视频由900帧画面组成且控制时长为30 s,对每一帧的图像计算局部最大差值,并在灰度化和二值化处理之后使用sobel算子进行边缘提取,然后匹配分辨率分别为24×24(f24),32×32(f32),48×48(f48),64×64(f64)和128×128(f128)五种不同的光幻视模版,对视频进行像素化转换,处理流程如图1所示。图2是f64分辨率下的动态视频示例。

图1 图像处理流程示意图

图2 f64分辨率下鹰的动态视频示例
2.4 空间与时间信息测量
关于视频复杂度的分析,本研究采用空间信息(Space Information,SI)和时间信息(Time Information,TI)相结合的分析方法[25]。二者并不是一种信息熵测量法,也与通信理论中定义的信息无关。空间信息(SI)是一种通常用于表示图形空间细节数量的测量法。空间上越复杂的场景,SI值越高。空间感知信息SI在时间n(Fn)的各个视频帧(亮度平面)首先用Sobel滤波器Sobel(F n)进行滤波,然后计算各个经Sobel滤波器滤出后的帧中像素的标准差(stdspace)。视频片段中各个帧重复该操作,产生场景空间信息的时间序列,然后选择时间序列中的最大值(maxtime)来表示场景的空间信息内容。该过程可以用方程式的形式来表示:
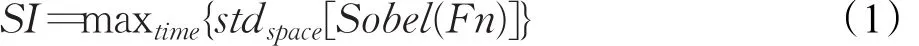
时间信息(TI)通常用于表示视频片段时间变化次数的测量法。运动程度较高的序列通常会有更高的TI值。时间信息测量法TI是用所有i和 j空间上的标准差(stdspace)的最大时间值(maxtime)来计算。

其中,Mn(i ,j)表示帧中相同位置上各像素之间的差异,但属于两个随后的帧,就是说:

其中,Fn(i ,j)是时间上第n帧第i行和第 j列处的像素[25]。
本研究中通过对不同分辨率下的动物,实物,人物三种类型的视频进行SI和TI分析,如图3所示。

图3 视频复杂度分析
图3 (a)对八个动物视频的SI取其均值得到SI_AVG,TI取其均值得到TI_AVG;同理,对图3(b)和图3(c)中八个实物以及八个人物视频的SI、TI取均值分别得到实物和人物视频的SI_AVG和TI_AVG。由图可知,分辨率从f24到f128,动物视频的空间信息从93.14 s上升到240.19 s,时间信息从1.83 s上升到5.01 s;实物视频的空间信息从127.56 s上升到297.79 s,时间信息从2.20 s上升到7.12 s;人物视频的空间信息从141.11 s上升到323.58 s,时间信息从4.92 s上升到13.22 s。在同一分辨率中,动物、实物以及人物的视频复杂度依次呈上升趋势。随着分辨率的增加,动物、实物以及人物视频的空间信息和时间信息增多,视频复杂度升高。
2.5 实验步骤
本研究的实验中,安排被试者在连续的五天内依次识别f24、f32、f48、f64和f128分辨率下的各24个视频,并对不同分辨率的呈现次序进行随机排序,以减少或避免学习效应的发生。识别过程中,针对动物视频要求识别具体动物的种类,实物视频要求识别实物的类别以及具体实物的类型,人物视频要求识别男女老少,以及具体到每个人物不同的特征,每个视频识别时间限制在三十秒内,若三十秒内未能识别即算识别准确率为零,若三十秒内只能识别出大致类型,即按不同视频的识别程度进行区分,例如:眼镜男孩,识别出是男性,准确率为33%,识别出是男性且年纪小,准确率为66%,识别出是男性,年纪小,戴眼镜,准确率为100%。统计分析识别时间,识别准确率,视频复杂度信息,提取特征信息。
3 结果
3.1 识别时间分析
图4显示了动态视频识别时间随着分辨率变化的情况,其中不同分辨率之间不显著的情况用“NS”表明。如图4(a)显示了八种动物视频在五种分辨率(f24,f32,f48,f64,f128)识别时间。在五个分辨率下的8种动物视频的识别时间进行单因素方差分析,并选择LSD方法进行各分辨率识别时间的多重比较。由图4(a)可见,动物视频的识别时间在不同分辨率上存在显著的差异性(F=7.190,P<0.05)并且其方差具有齐性,分辨率从f24到f32,p=0.042,差异显著;分辨率从f32到f48,p=0.012,差异显著;分辨率从f48到f64,p=0.033,差异显著;分辨率从f64到f128,p=0.039,差异显著。对每个动物视频的识别结果分别做LSD检验可知,分辨率从f24到f128,各视频识别时间的变化依次是——孔雀从22 s减少到7.54 s,鹰从30 s减少到9.54 s,鱼从13.55 s减少到4.39 s,其中f32和f48,f48和f64,f64和f128的识别时间具有显著性差异;乌龟从16.08 s减少到5.84 s,鸭子从8.52 s减少到 3.77 s,象从 19.03 s减少到 5.49 s,猪从25.45 s减少到7.66 s;兔子从16.05 s减少到5.64 s,五个分辨率之间均差异显著。

图4 动态视频识别时间
图4 (b)显示了八种实物视频在五种分辨率的识别时间。五个分辨率下的八种实物视频识别时间进行单因素方差分析,并做LSD检验。实物视频的识别时间在不同分辨率上存在显著的差异性(F=7.824,p<0.05)。实物视频总体上对五个分辨率识别时间的方差具有齐性,分辨率从f24到f32,p=0.018,差异显著;分辨率从f32到f48,p=0.034,差异显著;分辨率从f48到f64,p=0.044,差异显著;分辨率从f64到f128,p=0.048,差异显著。对每个实物视频的识别结果分别做LSD检验可知:分辨率从f24到f128,各视频识别时间的变化依次是——菠萝从27.54 s减少到8.44 s,房子从7.5 s减少到2.92 s,其中f32和f48,f48和f64,f64和f128的识别时间具有显著性差异;大炮从27.79 s减少到11.21 s,其中f24和f32,f32和f48,f64和f128的识别时间具有显著性差异;吊车从28.79 s减少到6.81 s,其中f24和f32,f32和f48的识别时间有显著性差异;吉普车从21.77 s减少到6.06 s,茄子从22.11 s减少到3.29 s,五个分辨率之间均差异显著;蘑菇从18.49 s减少到5.40 s,其中f48和f64识别时间有显著性差异;花从9.19 s减少到3.26 s,其中f24和f32,f48和f64,f64和f128的识别时间有显著性差异。
图4(c)显示了八种人物视频在五种分辨率的识别时间。五个分辨率下的八种人物视频进行单因素方差分析并做LSD检验。人物视频的识别时间在不同分辨率上存在显著的差异性(F=10.190,p<0.01)。从人物视频总体上对五个分辨率的识别时间分析可得,分辨率从f24到f32,p=0.011,差异显著;分辨率从f32到f48,p=0.008,差异显著;分辨率从f48到f64,p=0.019,差异显著;分辨率从f64到f128,p=0.004,差异显著。对每个人物视频的识别结果分别做LSD检验可知,分辨率从f24到f128,各视频识别时间的变化依次是——老人从19.35 s减少到3.93 s,男孩从26.84 s减少到11.9 s,其中f24和f32,f32和f48,f64和f128的识别时间有显著性差异;女孩从27.81 s减少到7.23 s,小胖孩从25.05 s减少到9.83 s,其中f32和f48,f48和f64,f64和f128的识别时间有显著性差异;男人从29.1 s减少到7.84 s,眼镜男孩从28.01 s减少到19.22 s,其中f48和f64的识别时间有显著性差异;舞女从21.04 s减少到3.95 s,五个分辨率之间均差异显著;女人从27.1 s减少到7.52 s,其中f24和f32,f48和f64,f64和f128的识别时间有显著性差异。
3.2 识别准确率分析

图5 动态视频识别准确率
图5 展示了动态视频识别准确率随分辨变化的情况,其中“*”表示不同分辨之间情况显著,而“NS”则表示不同分辨之间情况不显著。由图5可知,随着分辨率的增加,同一种类视频的识别时间减少,识别准确率逐渐升高,除了特殊难识别的情况(大炮,男人,小胖孩和女人),在f128分辨率下,识别准确率已经达到百分之百。对八种视频的五个分辨率的识别结果进行单因素方差分析可知,动物视频的识别准确率在不同分辨率上存在显著差异性(F=5.033,p<0.01);实物视频的识别准确率在不同分辨率上存在显著差异(F=7.510,p<0.01);人物视频的识别准确率在不同分辨率上存在显著差异(F=32.701,p<0.01)。同时,动物视频中乌龟、鸭子、鱼和兔子,实物视频中吉普车、花和房子特征显著,在f24分辨率下识别准确率就已经达到100%,随着分辨率的增加,识别时间减少;实物视频中的大炮,人物视频中的男人,小胖孩和女人特征不明显,在f128分辨率下识别准确率仍达不到100%,但随着分辨率的增加,识别时间仍减少,只有女人的视频在分辨率f32到f48时,识别时间增加了1.36 s,在这里识别不准确是由于视频本身的原因以及被试者的认知所造成的,分辨率的增加有利于识别效率的提高。
3.3 特征点的提取
被试者对识别物的识别主要受图像显著性区域的影响。显著性检测主要用来检测图像中能引起人类视觉感知的最重要部分。其中,基于显著性点的显著性检测算法用来检测人类最感兴趣的点;基于显著性对象的检测用来检测最能引起人类视觉感知的前景对象[26]。本文主要采用一种简化的Itti算法来提取动物、实物以及人物的主要特征信息。
Itti算法[27]是一种模拟生物视觉注意机制的选择性注意模型,该算法采用跨尺度中心-周边算子模型提取显著性区域,最终所得与人眼视觉感知效果一致。其基本结构图如图6所示[27]。

图6 Itti算法流程图
如图6所示,Itti的主要算法如下:
(1)特征的提取:首先用九层高斯金字塔来搭建输入图像。输入图像为第0层,使用5×5的高斯滤波器对输入图像进行滤波采样形成剩余的1~8层,其大小分别为输入图像的1/2到1/256。对金字塔每一层分别提取各特征,形成亮度、红色、绿色、蓝色、黄色以及方向特征金字塔。特征由下列公式表示:

其中r、g、b分别表示输入图像的红、绿、蓝三个分量。o(σ+θ)是Gabor函数在0,π/4,π/2,3π/4四个方向上滤波得到的Gabor金字塔。其中,σ∈[0,1,…,8],θ∈[0°,45°,90°,135°],这样将特征以九个金字塔的形式表示出来:1个亮度金字塔,4个色度金字塔(分别是红、蓝、绿、黄)以及4个方向金字塔(分别是0°,45°,90°,135°)。其中的色度特征对黑、白两色的响应为零,对各自对应的饱和单色有最大的响应。
(2)特征图的形成:Itti算法通过不同尺度间的特征取差来形成特征图。具体公式如下:

Itti算法模拟人类视觉感知视野的中心—周边算子的结构。中心视野对应于尺度c(c∈{2,3,4})和外周视野对应于尺度s(s=c+δ,δ∈{3,4})的特征像素点。由于分辨率不同的特征图尺度不同,需要在两幅图的大小相同的基础上点对点做差,并用Θ表示。通过c和s尺度对比来表示中心和外周的特征对比。其中式(9)是关于亮度对比的特征图计算公式。公式(10)和(11)是颜色特征图计算公式。其中式(10)是中心和周边区域的红/绿对比特征图计算公式;式(11)中心与周边区域的蓝/黄对比特征图计算公式。式(12)是方向特征图计算公式,是不同尺度在同一个方向的特征作差得到的。由于c和 s共有6种组合(2-5,2-6,3-6,3-7,4-7,4-8),所以最终会得到6个特征图和42个不同尺度的特征图(包括六个亮度,十二个颜色和二十四个方向特征图)。
(3)显著图生成:把每一个上述得到的特征图归一化,以消除和特征相关的幅度差别。为了消除干扰噪声突出显著部分,对每个特征图分别用二维高斯差函数进行卷积,并把卷积结果叠加回原特征图,使同种特征以侧抑制的方式在空间上竞争。卷积和迭代过程进行多次,这样可以让少数几个最显著的点均匀分布在整个特征图上,从而每个特征图上只保留少数的几个显著点,在叠加多个特征图时能把多种显著特征的点突现出来。接下来分别把每一类(亮度、色度、方向)归一化后的特征图逐点求和(采样到第4尺度),得到对应于每一类特征的显著图,综合所有特征的显著性,就得到对应于输入图像的显著图S[27]。计算过程如下:

Itti算法是第一个模拟人眼视觉感知的较为完整的视觉注意机制,得到的显著图突出了显著性区域但区域轮廓并不明显,基于上述原因,同时为了提高算法效率,本文采用一种简化的Itti模型,在颜色、方向以及亮度三组特征图中每组仅选最显著的一个特征图进行合并[28],并将模糊半径设置为0.02。以菠萝为例,特征点提取后原始像素化、Itti算法以及简化Itti算法所得到的结果如图7所示。

图7 特征点提取
表1中特征点的选取是按照人眼视觉感知的显著特征来选取的。图8以实物素材菠萝为例,显示了眼动仪监测的被试注视点的变化情况。其中f24-a1,f32-b1,f48-c1,f64-d1分别代表在f24,f32,f48和f64分辨率时注视点在菠萝圆筒状的果实;f24-a2,f32-b2,f48-c2,f64-d2分别代表在f24,f32,f48和f64分辨率时注视点在菠萝的茎;f24-a3,f32-b3,f48-c3,f64-d3分别代表在f24,f32,f48和f64分辨率时注视点在菠萝圆筒状的果实和茎上的叠加。图中没有画出f128的情形是因为在f128时,当完整画出菠萝圆筒状的果实时,被试已完成识别,并识别准确,所以没有注视点在茎上的情况出现。
识别特征点的人数统计如图9所示,当视频有两个特征点时,随着分辨率的增加,特征一被作为主要识别依据的人数逐渐增加,特征二被作为主要识别依据的人数逐渐减少;当视频有三个特征点时,随着分辨率的增加,特征一被作为主要识别依据的人数逐渐增加,特征二被作为主要识别依据的人数先增加后减少,特征三被作为主要识别依据的人数逐渐减少;当视频有四个特征点时,随着分辨率的增加,特征一被作为主要识别依据的人数逐渐增加,特征二被作为主要识别依据的人数先增加后减少,特征三和特征四被作为主要识别依据的人数逐渐减少。这表明,随着分辨率的增加,特征点被更清晰地表现出来,使得被试者的识别既快又准。

表1 不同素材的特征

图8 眼动仪监测到的被试者在观察菠萝时的注视点图
4 讨论及结论
4.1 不同分辨率下识别时间和识别准确率的比较

图9 识别特征点人数统计
本研究结果表明,动物、实物以及人物视频随着分辨率的增加,识别时间逐渐减少。分辨率的增加使视频的时间以及空间信息增多,视频复杂度升高,图像清晰明了容易识别。但孔雀在分辨率f24到f32时,识别时间增加了0.22 s,女人在分辨率f32到f48时,识别时间增加了1.36 s,这是由于分辨率增加后,信息量增加,有用信息增多的同时也产生干扰信息,使被试者需要更多的时间完成识别。同时,本研究发现在不同分辨率下的识别时间具有显著性差异。不同种类的视频随着分辨率的增加,识别准确率升高。同时在不同分辨率下的识别准确率差异显著。
4.2 特征点的选取
在特征点选取的结果中,部分特征点只有在f128分辨率中被识别,其余的分辨率下都没有被识别,所以在图中没有画出,这是因为f128分辨率下细节信息增多,特征明显,同样符合上述规律。
5 结束语
综上所述,随着动态视频在不同光幻视像素化模板下的视频复杂度的升高,SI和TI信息量增大,识别时间会逐渐减少,识别准确率不断升高。当视频像素化达到f64或f128时,少量特征信息即可完成识别。本研究结果可望为盲人在低分辨率情况下获得最佳视觉效果提供可行的指导方案,并可将其应用于后续的生理信息采集和分析中,开展对假体佩戴者完成识别任务的相关生理参数的进一步研究。
猜你喜欢
疯狂英语·新读写(2023年1期)2023-04-06
中学生数理化·中考版(2022年10期)2022-11-10
基层中医药(2022年1期)2022-07-22
数学物理学报(2019年3期)2019-07-23
家庭影院技术(2018年9期)2018-11-02
作文小学中年级(2018年10期)2018-10-29
电子制作(2018年1期)2018-04-04
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
湖南农业(2016年3期)2016-06-05
