
基于随机森林的倾斜影像匹配点云分类研究
2018-11-22 07:17:46赵利霞王宏涛郭增长管建军
测绘工程 2018年12期
赵利霞,王宏涛,郭增长,管建军
(1.河南理工大学 测绘与国土信息工程学院,河南 焦作 454000;2.河南测绘职业学院,河南 郑州 450005)
目前,倾斜摄影测量建模方法主要是通过多视影像密集匹配生成高密度彩色点云,进而通过构建不规则三角网的方式生成特定场景的三维模型,该模型能够真实的反映地形地貌,且具有逼真的三维效果。然而,该方法得到的仅仅是一个单一的表面模型,不能反映场景内各种目标的语义信息,难以构建真三维GIS系统[1]。因此,如何从影像匹配点云中自动识别出各种地物目标并进行自动化的三维建模,已经成为倾斜摄影测量的研究热点。
点云分类是倾斜摄影测量影像数据处理和模型重建中关键的一步,其主要包括特征提取和分类两个过程,其中,特征提取是最为重要的技术环节,决定分类效果的好坏。目前点云分类研究主要集中在对LiDAR点云的处理方面,多数方法是从LiDAR点云中提取出几何特征、多回波特征、强度特征以及波形特征等多种不同特征进行点云分类,这些特征在用于特定场景地物分类时取得了相对不错的分类结果。然而,在城区复杂环境下,仅仅依靠点云中提取的几何特征进行地物分类仍然存在较大的困难。因此,一些学者开始研究将点云中提取的几何特征与影像中提取的光谱特征进行融合来提高分类精度[2-3],然而这不但增加了数据来源的需求,并且需要将这两种数据源进行精确配准。相比之下,倾斜影像匹配点云具有精确的几何信息和丰富的光谱信息,不存在配准问题,有利于提高点云分类的精度和效率。针对提取的各种特征,国内外众多学者主要采用机器学习的方法进行点云分类研究,主要包括人工神经网络(Artificial Neural Networks,ANNs)[4]、支持向量机(Support Vector Machine,SVM)[5,6]、AdaBoost[7]以及随机森林(Random Forest,RF)[8]等。这些方法大都通过计算尽可能多的特征以得到更好的分类结果,但是当提取大量特征时,会存在一些冗余特征,冗余特征不仅增加计算负担、浪费内存空间,还会降低分类精度。因此,从高维数据中提取和选择有用的特征信息是正确分类的关键。
倾斜影像匹配点云不需要进行点云与影像之间的精确配准,其同时包含几何信息和光谱信息,将这两种信息进行融合将有助于提高分类精度。随机森林分类算法是一种高性能的分类算法,具有人工干预少、分类精度高、运算速度快等优点,可以快速处理高维数据,并且能够估计分类过程中特征的重要性。因此,本文基于随机森林算法进行倾斜影像匹配点云的分类研究,以期将倾斜影像匹配点云中提取的几何和光谱特征进行有机融合,并在减少冗余特征的基础上,有效提高倾斜影像匹配点云的分类精度和效率。
1 随机森林分类算法
随机森林是一种由大量决策树作为弱分类器的集成分类器,其基本单元是决策树。单个决策树进行分类的主要过程是从根节点开始,测试该节点上所有属性特征,然后选择一个最优特征进行节点分裂,直至决策树的叶节点,此叶节点上的类分布即为该决策树得出的分类结果。随机森林采用Bagging集成思想,随机有放回选取不同的训练子集并构建对应的决策树,然后根据所有决策树的分类结果进行投票以确定最终的分类。Leo Breiman结合 Bagging集成思想和随机子空间方法[9]实现随机森林的两大随机特性,即随机生成独立同分布的训练子集和随机选取分类特征,这两种随机性使得随机森林算法具有较好的泛化性能,可以快速处理上千维的数据集,并且不会产生过拟合现象。
随机森林算法的基本思想可作如下描述:①从原始训练集中随机有放回抽取Ntree个与原始训练集容量相同的样本集作为bootstrap[10]训练集,每次抽样均有接近37%的原始训练集样本未出现在新的训练集中,这些数据被称为袋外数据(out of bag,OOB);②根据bootstrap训练集建立Ntree个决策树并组成随机森林模型。每棵决策树的生长过程主要是从全部特征中随机抽取Mtry个特征,然后选择一个最具有分类能力的特征作为内部节点进行分裂,依次向下,直至决策树的叶节点;③集合所有决策树的分类结果,采用简单多数投票法确定最终分类结果。该算法基本流程如图1所示。
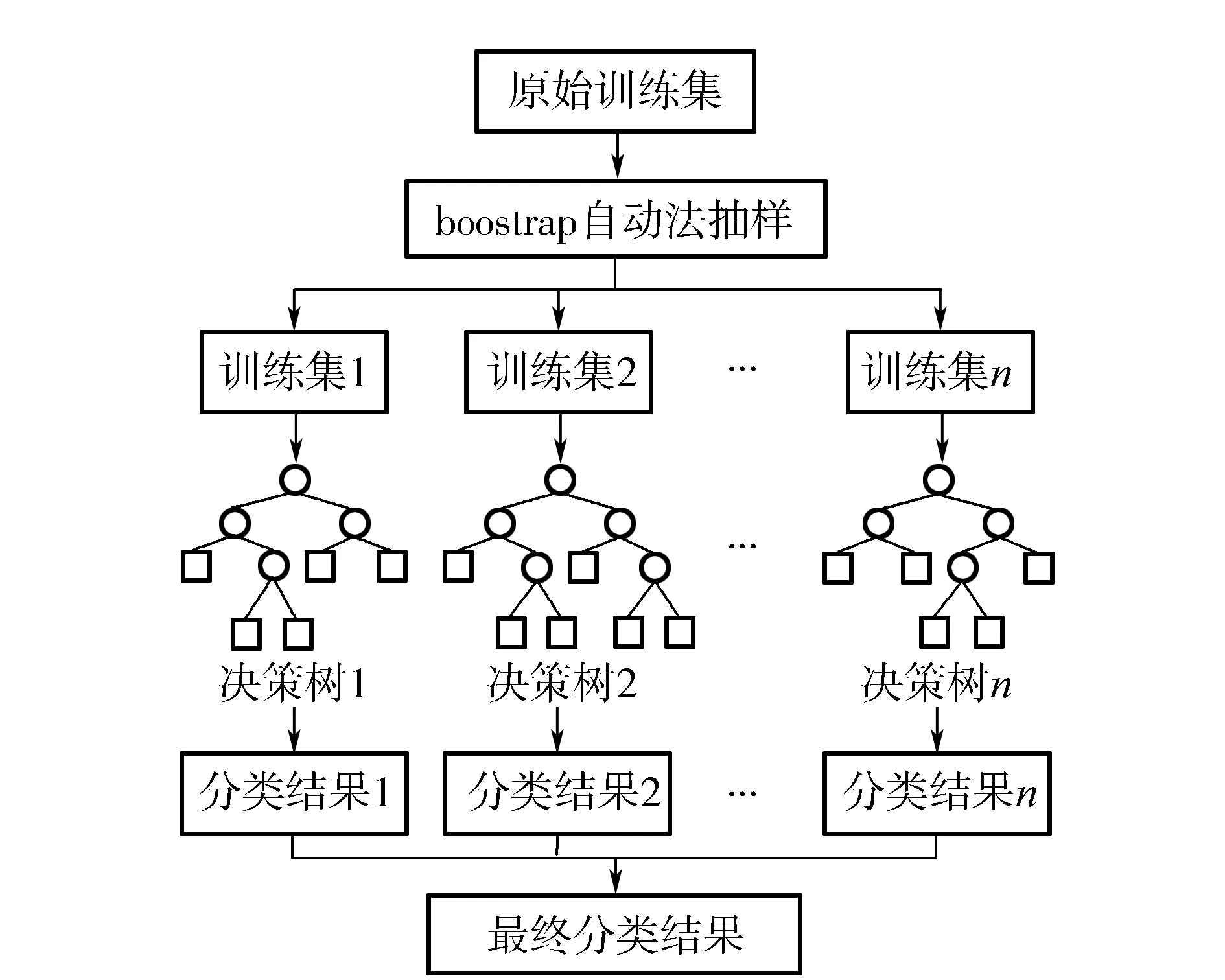
图1 随机森林算法基本流程
相比于其它分类算法,随机森林可以对分类中提取特征的重要性进行评估,该过程采用变量重要性评分(Variable Importance Measure, VIM)策略实现,该策略在高维组数据生物标志物的变量筛选中有广泛应用[11]。变量重要性评分主要有两种计算方法,分别是根据Gini指数计算和基于OOB误差率的置换法计算。由于置换法具有更好的非偏倚性能,因此多采用置换法进行变量筛选[12-13],该方法的基本原理是随机置换袋外数据变量值,然后通过计算置换前后的OOB误差率间的差异来衡量变量的重要性。对于某一变量Xj而言,采用置换法计算该变量重要性(VIMj(OOB))的算式为
(1)

2 基于随机森林的倾斜影像匹配点云分类
本文提出的点云分类方法主要分为3个步骤:①数据预处理:对原始点云进行滤波得到地面点和非地面点云;②特征提取:提取影像匹配点云的几何特征和光谱特征;③随机森林分类:采用变量重要性评分策略进行特征选择,确定一组最优特征子集,并采用随机森林算法将非地面点云分为建筑物、树木和低矮植被3类。文中所提方法的主要技术流程如图2所示。
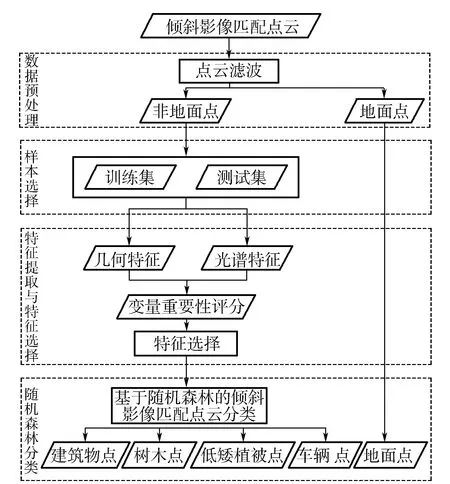
图2 倾斜影像匹配点云自动分类技术流程
2.1 数据预处理
首先利用开源软件CloudCompare对高密度的倾斜影像匹配点云进行降采样,以提高后续数据处理效率,根据实验需要,将采样间隔设为0.3 m来抽稀点云。然后,利用内嵌于CloudCompare软件中的布料模拟滤波算法[14]将原始点云分为地面点和非地面点。该算法的基本思想是通过模拟具有一定硬度的布料覆盖于倒置点云的物理过程,得到一个近似的地表形状,进而计算所有点云到此近似地表的距离,最终将点云分类为地面点和非地面点。
2.2 特征提取
针对倾斜影像匹配点云的特性,提取以下两个方面特征用于点云分类:
1)几何特征,主要包括高程值、归一化高度、高度标准差、协方差矩阵特征值、法向量、曲率、粗糙度以及点密度等。①高程值(H)反映该点真实的高程信息;②归一化高度(NH)是指每个非地面点与其最邻近的地面点的高度差值;③局部邻域内高度标准差(VH)可以反映点云的垂直分布;④基于协方差矩阵的3个特征值(λ0,λ1,λ2)可以用于区分平面、边缘和线等特征;⑤法向量的3个分量nx,ny,nz以及曲率(curvature)可以反映点云的外形和平面特征;⑥粗糙度(roughness)是指该点领域内所有点到局部拟合平面距离的平均值;⑦点密度(n)是指该点邻域内所有点的个数。
2)光谱特征,主要包括Lab颜色特征、可见光波段差异植被指数(visible-band difference vegetation index,VDVI)以及归一化绿蓝差异指数(normalized green-blue difference index,NGBDI)[15]。①Lab颜色是由亮度(L)和有关色彩的a,b3个要素组成,将a,b两个要素作为光谱特征可以在一定程度上消除光照不均的影响;②植被指数VDVI和NGBDI在仅有可见光波段的无人机影像植被信息提取中具有较好的适用性,能够很好地区分植被与非植被,具体算式为
(2)
(3)
式中,R,G,B分别表示从真彩色数字航空影像上提取的红绿蓝3个通道的灰度值。
2.3 随机森林分类
在随机森林分类过程中,需要输入训练数据和测试数据,训练数据主要用于构建随机森林分类模型,然后利用分类模型对测试数据进行分类。首先,将实验区主要地物类型分为建筑物、树木和低矮植被,采用手工分类的方法从各类别点云中选取约10%的样本作为训练数据,其余作为测试数据,并记录对应的类别标签。其次,采用变量重要性评分策略进行特征选择,并采用逆向特征消除方法[16],反复构建随机森林模型,以减少冗余特征,选出一组最优特征子集。最后,基于最优特征子集,采用随机森林算法将点云分为建筑物、树木和低矮植被。
3 实验结果与分析
本文实验区的倾斜影像数据由红鹏无人机倾斜摄影测量系统AC1100获取,试验区域为河南理工大学测绘学院周边区域。飞行平均航高为100 m,相机CCD大小为5 456像素×3 632像素,其对应地面影像分辨率为0.02 m。采用ContextCapture Center软件将获取的倾斜影像进行处理,所生成的倾斜影像密集匹配点云如图3(a)所示。经过滤波处理后的非地面点如图3(b)所示。
3.1 参数优选
在随机森林分类过程中,有两个重要参数需要设置:特征数(Mtry)和决策树数量(Ntree)。针对本文实验数据,将Mtry取2,4,8,Ntree取100,200,300,…,1 000。在上述参数设置下,以OOB误差率和最终分类精度为评价标准,进行两个参数的优化选择。图4表示不同参数设置对分类精度的影响。
从图4(a)可以看出,随着Ntree不断增加,OOB误差率呈现下降趋势,且当Mtry=4时OOB误差率足够低且稳定;从图4(b)、(c)可以看出,当Mtry=4时,随着Ntree不断增加,总体精度和Kappa系数不断增大。当Ntree=400时总体精度和Kappa系数达到较高水平,分别是95.88%和0.919 2,但随着Ntree继续增加,分类精度增长缓慢,并且当Ntree过大,会造成构建随机森林的时间过长。综合考虑,本文最终选取Mtry=4、Ntree=400作为随机森林的最优参数。

图3 试验区倾斜影像匹配点云
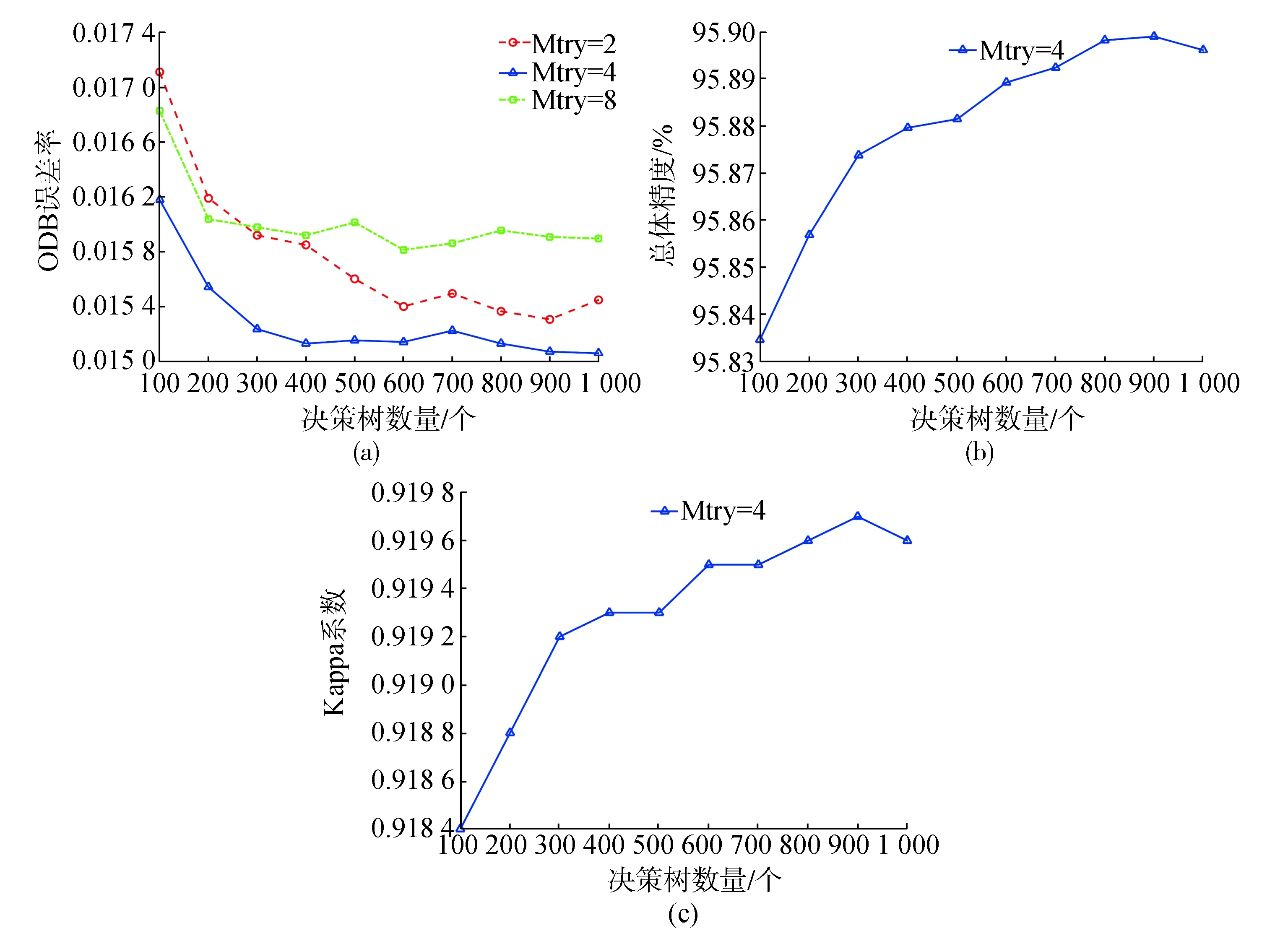
图4 不同参数设置下的分类精度
3.2 特征选择
本文首先采用变量重要性评分策略进行特征的重要性评估。图5(a)为全局变量重要性评分,表示在整个分类过程中每个特征的VIM值;图5(b)为各类别变量重要性评分,表示在不同地物类别分类过程中每个特征的VIM值;VIM值越大表示该特征在分类中作用越大,即贡献量越大。
从图5(a)可以看出,对整个分类模型贡献最大的特征依次是VDVI,H,NH,这说明这些特征对于点云分类具有非常重要的意义,其中,VDVI可以很好地识别树木和低矮植被, 而H,NH能够区分高程不同的地物类别;roughness,λ1,ny这3个特征的贡献量最小,表明这些特征在整个分类过程中作用相对较小。从图5(b)看出,对于建筑物和树木而言,VIM值最大的是H,VDVI,NH,但对低矮植被来说,却是H,VH,NH,出现这种差异的原因有两个方面:一是VH能够更好地识别表面平缓的低矮植被;二是VDVI虽然对植被有很好的分类能力,但是难以将具有类似植被特征的树木和低矮植被区分开。此外,值得注意的是,VDVI和a的VIM值较高,这说明两种光谱特征在三维彩色倾斜影像匹配点云中有很好的分类效果。
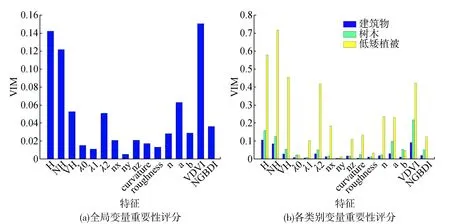
图5 变量重要性评分
在上述特征重要性评估的基础上,选择VDVI,H,NH和a作为后续主要分类特征,不参与特征冗余性分析,其余特征按照全局变量重要性评分进行重要性排序,然后采用逆向特征消除法依次减少冗余特征,并根据最终分类精度确定一组最优特征子集。特征选择的实验结果如图6所示,图中横轴从左至右为按照重要性由弱到强依次减少的特征,纵轴为分类精度。
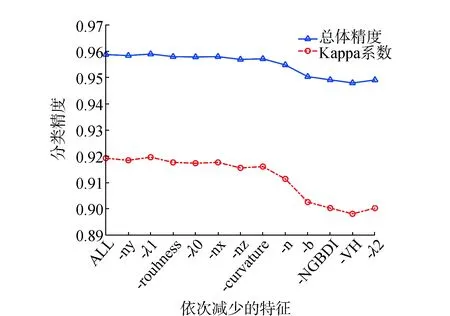
图6 特征选择对分类精度的影响
从图6可以看出,依次去除ny,λ1,roughness,λ0,nx,nz,curvature等7个特征时,总体精度和Kappa系数虽然呈现缓慢下降趋势,但总体维持在相对较高的水平,表明这些特征对于本文试验数据分类而言属于冗余信息,去掉这些冗余特征对分类精度影响不大。但从效率上讲,去掉冗余特征之后分类计算的时间从145 s减少到112 s,分类效率明显。综上所述,确定最优特征子集为{VDVI,H,NH,a,λ2,VH,NGBDI,b,n}。
3.3 分类结果及精度评定
本文按照上述方法,采用随机森林算法将非地面点分为建筑物、树木和低矮植被3类,该实验的分类结果如图7所示。
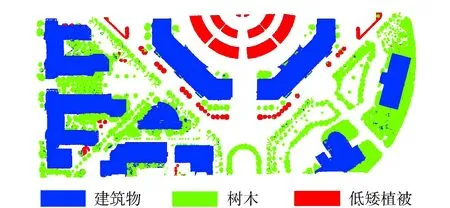
图7 实验区分类结果
从图7可以看出,本文提出的影像匹配点云分类方法具有较好的分类效果,能够正确地区分点云中建筑物、树木和低矮植被;但图中也存在少数错分现象,主要是建筑物立面上隆起部分和门顶凸起部分被错分成树木,树冠和低矮植被的平缓部分被错分成建筑物。
除了上述定性分析之外,本文采用计算分类结果混淆矩阵的方法对分类结果进行定量分析,如表1所示。
从表1可知,该实验区倾斜影像匹配点云分类的总体精度为95.72%,Kappa系数为 0.916 1。建筑物和树木的分类精度较高,其制图精度和用户精度均在94%以上,而低矮植被的用户精度较低,这是由于低矮植被的点云数量明显小于其他类别的点云数量,这种类间不平衡数据[17]影响分类器对小类别的分类性能。另从算法效率上考虑,该方法对实验区约80万个点云数据进行分类仅花费了112 s的时间。由此可见,本文提出的基于随机森林的点云分类方法具有较高的分类精度和效率。

表1 混淆矩阵
注:总体精度:95.72%,Kappa系数:0.916 1
4 结 论
本文根据倾斜影像匹配点云的特性,提出一种基于随机森林的点云分类方法。所提方法首先从点云中提取多种几何与光谱特征构成多维特征向量;然后,采取变量重要性评分策略对分类中的特征进行重要性评估,以减少冗余特征,从而确定一组最优特征子集;最后,采用随机森林算法进行点云自动化分类,并取得了较好的分类效果。通过对实验结果的分析可以得到以下结论:1)融合倾斜影像匹配点云的几何特征和光谱特征能够有效提高点云分类精度;2)采取变量重要性评分策略进行特征选择,可以减少冗余特征,有利于提高分类精度和效率。目前,本文所提方法仅实现了对倾斜影像匹配点云中建筑物、树木和低矮植被的分类,未来研究将侧重于采用面向对象的分类方法实现对多种地物目标的自动识别。
猜你喜欢
河北地质(2022年2期)2022-08-22 06:24:04
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:26:02
中国生殖健康(2020年4期)2021-01-18 02:58:26
甘肃教育(2020年21期)2020-04-13 08:09:24
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
现代园艺(2017年23期)2018-01-18 06:58:12
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
唐山文学(2016年11期)2016-03-20 15:26:04
应用海洋学学报(2015年2期)2015-11-22 07:36:28
