
集成用户信任度和品牌认可度的商品推荐方法
2018-11-22 09:37韩晓龙付陈平王嵘冰徐红艳
计算机应用 2018年10期
冯 勇,韩晓龙,付陈平,王嵘冰,徐红艳
(辽宁大学 信息学院,沈阳 110036)(*通信作者电子邮箱wrb@lnu.edu.cn)
0 引言
随着互联网技术的高速发展与广泛应用,电子商务已成为人们日常生活中不可或缺的商品交易模式。在影响商品销售的诸多因素中,信任关系和品牌概念起到至关重要的作用。信任是构建用户间伙伴关系的基石,口碑营销、病毒营销等新型营销模式就是基于信任关系的销售。品牌是商品的标志,企业通过关系营销、数据库营销、整合营销等营销手段提升用户对品牌的认可度,进而增强用户黏度,促进商品销售。这两个关键因素的融合可以使用户在种类繁多的电子商务环境中迅速找到合适的商品,提高用户的购买效率。为此,本文从用户信任和品牌认可两个方面着手,对传统个性化推荐方法进行改进,实现电子商务精准营销。
近年来,众多学者通过研究用户信任关系与个性化商品推荐的关联,或是通过分析用户评分信息来提高推荐的准确率,但却忽视了商品自身最主要的品牌因素对推荐准确率的影响。李良等[1]将信任融合到协同过滤推荐方法中,提出将用户评分信任和偏好信任结合,但该方法在计算信任时忽略了用户间的交互关系。王海艳等[2]通过建立可信联盟的方法来提高推荐服务的精确度,考虑了信任计算中的直接信任和间接信任;但并没有充分考虑信任的非对称性,结果偏离现实信任关系。在用户评分上,Liu等[3]将用户评分相似性和用户评论进行综合考虑,这种思想在一定程度上提高了推荐的准确率,却增加了算法时间复杂度。McAuley等[4]利用hidden factors as topics将评分和评论信息相结合构建特征向量,但这并不能同时对商品和用户两个角度进行充分考虑。FPCA(Fixed Point Continuation with Approximate SVD)算法[5]和LmaFit算法[6]等通过补全用户评分矩阵来提高推荐算法的准确度;但这些算法大多聚焦于用户的评分信息,而忽视了用户的评论、购买足迹等因素,这些因素能够更细致地描述用户的轮廓,对用户的消费决策产生重要影响。
本文在改进推荐算法中用户信任度计算方式的同时,引入了品牌认可度因素,将品牌认可度与用户信任度融合,提出一种集成用户信任度和品牌认可度的商品推荐方法(Commodity Recommendation Method Integrating User Trust and Brand recognition, TBCRMI)。该方法由品牌认可度、用户活跃度和用户信任度三个核心计算环节构成,其中:品牌认可度充分考虑了用户购买商品时的品牌选择行为;用户活跃度分析了用户的评价行为,突出活跃用户;用户信任度结合了现实世界中信任的双向关系,定义了新的信任度计算方式。
1 TBCRMI方法
1.1 方法架构
为提升个性化商品推荐的成功率,促进电子商务的开展,本文结合商品营销中的核心要素:信任关系和品牌理念,给出一种集成用户信任度和品牌认可度的个性化商品推荐方法,其架构如图1所示。架构图的核心环节包括:品牌认可度计算、用户活跃度计算和用户信任度计算。
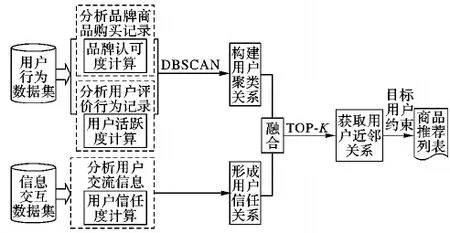
图1 TBCRMI 方法架构Fig.1 Architecture of TBCRMI
1.2 核心算法
设用户集合U={u1,u2,…,un},品牌集合B={b1,b2,…,bm},根据用户行为数据集和信息交互数据集,先分析用户的商品购买记录和评价行为记录,计算得到用户品牌认可度和活跃度,然后按品牌构建用户向量。设存在bj∈B,ui∈U,用户向量表示为:
ui(Bcoi, j,Uaci, j)
其中:Bcoi, j表示用户ui对品牌bj的认可度;Uaci, j表示用户ui在品牌bj上的活跃度。
在形成用户信任关系环节,采用DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法对用户进行聚类,用户间的距离计算使用欧氏距离。聚类算法如下。
输入U为包含n个用户的数据集;ε为半径参数;MinPts为邻域密度阈值。
输出 基于密度的用户的集合C。
标记U中所有的用户为unvisited;
do
{随机选择一个unvisited对象ui;
标记ui为visited;
ifui的ε-邻域至少有MinPts个对象
{创建新簇C,并把ui添到C;
令N为uiε-邻域中对象集合;


把它添加到N;
输出C;}
Else标记ui为噪声}
whileU中没有标记为unvisited的对象
根据聚类结果,得到关于品牌bi的用户关系矩阵URbi:
其中:数据元素dij是用户i和用户j间的距离。
在用户信任度计算环节,根据用户间信息交流数据,计算得到用户信任关系矩阵T如下:
其中:数据元素Trij为用户ui对用户uj的信任度。
在面向目标用户选取近邻关系环节,将用户聚类矩阵与用户信任矩阵融合。设用户ui为目标用户,在矩阵URbi中第i行表示用户ui相对其他用户的距离;同样在矩阵T中第i行表示用户ui对其他用户的信任度。合并得到推荐用户列表URn表示如下:
最后采用Top-K方法选取目标用户的K个最近邻,再依据目标用户约束生成商品推荐列表。为了确定α和β的合理取值,本文针对不同的α、β取值进行多次实验并计算相应的准确率P和召回率R。α、β的测试用例与计算结果如表1所示。从表1中可以看出当α=0.5,β=0.5时推荐效果最佳。
1.3 算法时间复杂度分析
本文算法的时间复杂度主要取决于以下两个过程:1)分析用户行为数据与用户交互数据过程中遍历所有记录的时间;2)对用户进行聚类时使用的DBSCAN算法的时间复杂度。由于分析用户品牌商品的购买记录、用户评价行为记录和用户交流信息的过程是并行执行的,所以遍历n个用户的n条记录所产生的时间复杂度为O(n2);而采用DBSCAN算法对用户聚类时的基本时间复杂度是O(n×找出ε-邻域中的用户所需要的时间),n是用户的个数,在最坏情况下其时间复杂度是O(n2)。综合以上分析,本文的时间复杂度为O(n2)。
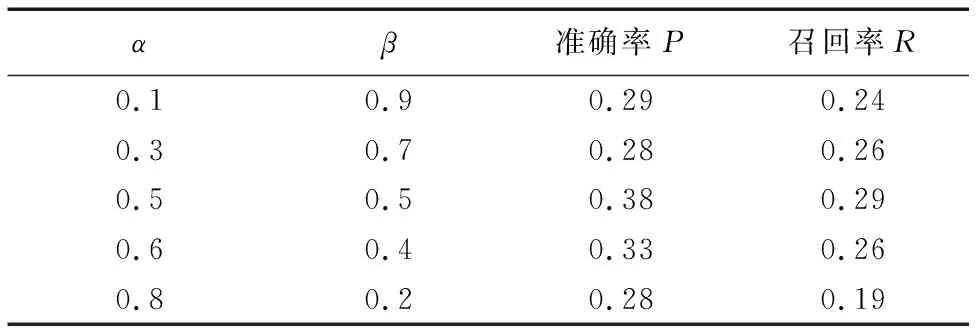
表1 测试用例及结果Tab. 1 Test cases and results
2 TBCRMI方法核心环节
本文所提出的集成用户信任度和品牌认可度的个性化商品推荐方法包含三个核心环节:品牌认可度计算、用户活跃度计算和用户信任度计算。
2.1 品牌认可度
Halim[11]的研究发现,一个能给消费者带来深刻印象的品牌总能赢得消费者特别的注意力,超值的品牌更可能赢得消费者的认可。在现实生活中,如果用户在体验过某个品牌的商品后对其并不满意,那么再向该用户推荐这个品牌的其他商品时,用户接受的可能性很小。因此,在个性化商品推荐中融合品牌认可度因素,可以提升推荐的准确性。
定义1 品牌认可度。是指相对一种品牌,用户对其熟悉度和忠诚度的表达。假如在同类商品中用户对某品牌的商品购买的次数明显高于该品牌下所有用户的平均购买次数,且高于用户自身对同类商品的平均购买次数,那就说明该用户对此品牌商品比较偏爱,有较高的认可度。
用户的品牌认可度由式(1)计算得到:
(1)

2.2 用户活跃度
高活跃度用户对品牌商品的评论存在正、负两面,正面评论可以增加品牌的影响力进而吸引更多用户,而负面评论却可以促进企业或商城对商品的持续改进。相对于普通用户,高活跃度用户浏览推荐商品的次数频繁,在浏览过程中发现自己感兴趣商品的概率随之提高,从而提升了商品购买概率。
定义2 用户活跃度。是指根据用户对推荐列表中商品浏览次数和商品体验评价情况而反映出的用户在社会网络中的活跃程度。
用户活跃度采用式(2)计算得到:
(2)
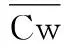
使用式(2)可以对用户在社交网络中的综合活跃度进行计算。当针对单一品牌商品进行推荐时,也可使用式(2)针对用户对某一品牌商品的浏览量、评论次数和字数等,计算用户在单一品牌上的用户活跃度。
2.3 用户信任度
在日常生活,尤其是电子商务中,信任表现出越来越重要的作用,是开展商品交易、交换的基础,成为电子商务网络中用户与用户间沟通的桥梁。推荐系统中融入信任关系,在一定程度上解决了数据稀疏问题,提高了推荐的准确性。
定义3 用户信任度。是指电商网络中用户之间通过直接、间接联系表现出相对信任的程度,具有不对称性、双向性、传递性等特点。现实生活中,信任是人与人之间的一种相互关系,是双向且不对称的,所以用图论来描述社交网络中用户的信任关系恰到好处,因此在社交网络中,用户关系可用有向带权图G(U,E,X)表示。其中:U是网络中的节点集合,表示所有的用户;E是网络中节点之间的有向边,表示用户间的交流关系,箭头指向消息的接收方;X是节点间连线的权值,表示用户之间单向信息交流的数量[12]。用户间信息交流如图2所示。

图2 用户间信息交流示意图Fig.2 Schematic diagram of information exchange among users
因为用户间的信息交流是双向且不对称的,所以在计算信任度时不仅考虑信任的双向性,同时还要体现信任的不对称性。以图2中D节点为例,在计算D节点相对于其他节点的信任度时,要以D为中心向外扩散,选择由D向外指的权值(D→H→I)。扩散范围依据六度分离理论确定,对于因社交网络不能覆盖或缺少关键中间联系人而造成的超出六度分离理论的用户予以保留,但并不作为关系节点参与计算[12]。
用户间信任度由式(3)计算:
(3)
其中:D是根节点;U表示与D有信任关系的其他节点;i表示由根节点D到目标节点n条路径的第i条;j表示该条路径中由根节点D到目标节点的m层中的第j层(层表示由根节点向外,所有直接联系的节点为第一层,隔一个节点间接联系的为第二层,以此类推);X(Sj-1,Sj)表示节点Sj-1与节点Sj之间的权值;Xj_total表示第j层与根节点D相关联的节点的权值之和,图2中用户间节点的权值是信任度计算公式的核心参数。
3 实验与分析
为了验证信任关系和品牌概念融合的方法对推荐算法的影响,本文选择基于用户的协同过滤算法(UserCF)[1]、融合用户信任的协同过滤推荐算法 (SPTUserCF)[1]、合并用户信任的协同过滤算法 (MTUserCF)[17]作为对比算法,采用准确率、召回率和F1值等指标与TBCRMI方法进行对比分析。
3.1 实验环境配置
本文实验用到的环境配置如下:操作系统Linux Ubuntu 14.04,CPU i5-4590 3.30 GHz,内存8 GB或以上,可用硬盘空间50 GB以上,给虚拟机分配24 GB空间。算法采用Java 语言编写。
本文实验处理的两个数据集:Amazon Food(642 MB)和Unlocked Mobile phone(141 MB),由于数据量很大,为提高数据处理速度和实验运行速度,实验平台采用Hadoop2.6.0完全分布式集群,共添加3个节点。
算法中的半径参数ε根据用户距离计算得出[19],本文为0.695,邻域密度阈值MinPts取值为3[19]。
3.2 实验数据集与评价指标
为验证本文方法的有效性,将TBCRMI与其他推荐算法进行对比,实验所用数据集为Amazon Food(简称数据集1)和Unlocked Mobile phone(简称数据集2)。两个数据集均是下载于聚数力网站的公共数据集:Amazon Food是食品评论数据集,包括用户、评论内容、评论食品、食品评分等9项共计50多万条数据;Unlocked Mobile phone是无锁手机评论数据集,包括用户、无锁移动手机的价格、用户评分、评论等8项共计40多万条数据。具体使用的数据信息见表2,这两个数据集的下载地址均为: http://www.dataju.cn/Dataju/web/dataDescriptionAndDataset。

表2 数据集信息表Tab. 2 Dataset information
本文所给的改进方法主要目的是提高推荐质量,所以在指标选择上选取了准确率、召回率以及F1值等常用的推荐算法评价指标来进行对比分析。
1)准确率P。推荐列表中用户喜欢的物品所占的比例,准确率计算如式(4)所示:
(4)
2)召回率R。测试集中有多少用户喜欢的物品出现在推荐列表中,召回率计算如式(5)所示:
(5)
其中:Lu表示通过训练集得出的推荐列表;Tu表示测试集上用户的实际行为列表。
3)F1值。是信息检索领域常用的一个评价标准,其计算公式为:
F1=2PR/(P+R)
(6)
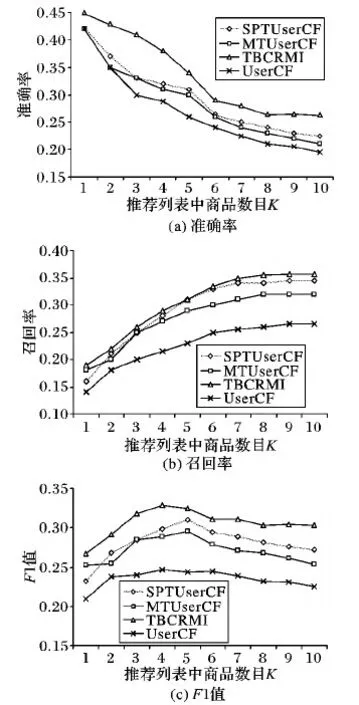
图3 Amazon Food数据集中不同K值的各指标对比Fig.3 Indexes comparison of different K on dataset Amazon Food
3.3 实验对比分析
在选择品牌效应进行推荐的情况下,推荐列表中商品的数目K会对推荐结果产生影响。将商品数目K作为变量,在两种数据集中对多种品牌综合推荐效果和单一品牌推荐效果进行多角度验证。
3.3.1 多种品牌综合推荐效果
在Top-K的推荐方法中,随着商品推荐数目的不同会产生不同的推荐效果。将商品推荐数目K作为自变量,分析不同的推荐算法在相同的数据集下产生的推荐效率。
针对多种不同品牌商品向用户进行综合推荐时,TBCRMI方法和其他算法在准确率、召回率和F1值的对比结果如图3所示。
图3显示的是在Amazon Food数据集下,针对不同数目的推荐商品所对应的准确率、召回率和F1。从图3的实验结果对比可以看出:TBCRMI拥有最高的推荐准确率,并且明显高于其他方法。此外还可以看出随着推荐商品数目的增加准确率会降低,在K值从1增加到10的过程中:SPTUserCF准确率下降46.43%,MTUserCF准确率下降50%,UserCF准确率下降53.57%,TBCRMI准确率下降41.56%,可以看出本文方法在准确率保持方面取得较好效果。当K=4时,TBCRMI的推荐准确率比对比算法中效果最好的SPTUserCF还要提升18.75%;召回率方面随着推荐商品数目的增加而上升,K=4时,TBCRMI的召回率较SPTUserCF算法提升3.57%;在F1方面,K=4时,TBCRMI比SPTUserCF提升10.14%。
图4显示了在Unlocked Mobile phone数据集下,针对不同数目的商品进行推荐时的准确率、召回率和F1。从实验结果可以看出TBCRMI的推荐效果最好,在准确率下降趋势方面,SPTUserCF准确率下降46.62%,MTUserCF准确率下降39.94%,UserCF准确率下降40.81%,TBCRMI准确率下降30.36%,依然取得最好的效果。在此次实验中,MTUserCF是所选择的对比算法中效果最好的,但与本文提出的TBCRMI算法相比,在K=4时,TBCRMI的准确率比MTUserCF高29.86%,召回率比其高40.66%,F1值比其高36.45%。

图4 Unlocked Mobile phone数据集中不同K值的各指标对比Fig.4 Indexes comparison of different K on dataset Unlocked Mobile phone
3.3.2 单一品牌推荐效果
图5是在Amazon Food数据集下,针对用户进行单一品牌商品推荐时的推荐准确率。从图5可以看出:TBCRMI在准确率上取得了比较大的优势,当商品数目K=4时,三种品牌平均准确率分别较SPTUserCF、MTUserCF和UserCF提升了64.59%、69.9%和82.88%。

图5 Amazon Food数据集中单一品牌不同算法准确率对比Fig.5 Accuracy comparison of different algorithms to single brand on dataset Amazon Food
图6是在Unlocked Mobile phone数据集下,针对用户进行单一品牌商品推荐时的推荐准确率。从图6可以看出:TBCRMI在准确率上的优势依然很明显,当商品数目K=4时,三种品牌平均准确率分别较SPTUserCF、MTUserCF和UserCF提升了52.23%、46.83%和63.85%。
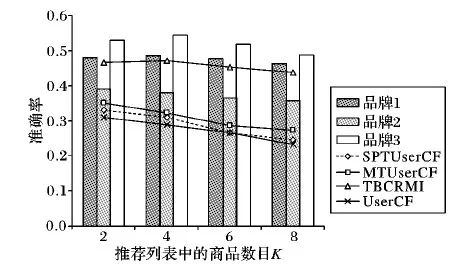
图6 Unlocked Mobile phone数据集中单一品牌不同算法准确率对比Fig.6 Accuracy comparison of different algorithms to single brand on dataset Unlocked Mobile phone
总体来看无论是多种品牌综合推荐还是单一品牌推荐,TBCRMI都取得了比较突出的推荐效果,尤其是在单一品牌商品推荐方面,准确率有了较为明显的提高。
4 结语
本文在个性化商品推荐方法中引入了影响商品销售的两个关键因素:用户信任度和品牌认可度,提出了一种集成用户信任度和品牌认可度的商品推荐方法。该方法通过分析用户历史行为得到用户品牌认可度和活跃度,并据此进行用户聚类,融入用户信任度得到近邻关系进行推荐。所给方法充分利用了商品销售中的品牌理念,并且通过对比实验验证了所给方法在商品推荐的准确率、召回率及F1值等多方面有所提升,尤其是在单一品牌商品推荐方面准确率提高明显,效果显著。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
环球时报(2018-01-23)2018-01-23
都市家教·上半月(2017年4期)2017-05-15
江苏教育·职业教育(2017年4期)2017-05-08
课程教育研究·学法教法研究(2017年1期)2017-03-21
教学研究(2016年2期)2016-05-14
汽车维护与修理(2015年5期)2015-02-28
