
语音与文本情感识别中愤怒与开心误判分析
2018-11-22 12:02:52胡婷婷沈凌洁冯亚琴
计算机技术与发展 2018年11期
胡婷婷,沈凌洁,冯亚琴,王 蔚
(南京师范大学 教育科学学院机器学习与认知实验室,江苏 南京 210097)
1 概 述
情感在人类认知与交流过程中具有重大作用。情感识别是人工智能领域的重要研究方向。语音是情感识别的一项重要通道,然而,在使用语音通道信息进行情感识别时,容易出现一些情感难以区分的情况,尤其是愤怒与开心之间难以区分的问题[1]。在使用文本通道信息进行情感识别时,有不同效果。因此,研究不同通道信息中包含的情感识别能力具有重要研究意义。
语音情感识别已经取得了一定的研究成果,但是在语音情感识别中一直存在愤怒与开心之间难以区分的问题。M Grimm和K Kroschel基于德语VAM数据集,采用单通道的声学特征进行情感识别,使用KNN(K-nearest-neighbors classification)方式对四类情感进行识别,在说话人无关实验中发现,愤怒与开心之间容易误判,中性和悲伤容易误判,愤怒识别准确率最高,开心识别率最低[2]。在基于多分类器集成的语音情感识别研究中,使用Berlin情感语言数据库中的语音数据,提取声学特征进行情感识别,愤怒和开心之间容易误判,悲伤识别准确率最高,开心识别准确率最低[3]。在基于决策树的多特征语音情感识别中,采用多种语音特征进行情感识别,对愤怒与开心容易误判,且对愤怒与害怕也易误判[4]。基于神经网络的语音情感识别研究发现,愤怒和悲伤是四种语音情感中最容易识别的两种表达方式,愤怒与开心之间容易误判[5]。在使用二次特征选择及核融合的语音情感识别中,对于愤怒与开心容易误判[6]。基于遗传小波神经网络的语音情感识别中,愤怒与开心也容易产生误判[7]。分析发现,愤怒与开心误判的问题在语音情感识别中广泛存在。
文本通道包含不同情感识别信息。ZJ Chuang采用中文戏剧节目中的男女对话,将对话语音转录为文本,通过单通道的文本信息提取特征进行情感识别,愤怒识别准确率最高,开心次之,悲伤识别率最低[8]。之后ZJ Chuang采用了声学与文本两个通道的特征进行情感识别,采用SVM模型训练,文本通道情感识别中,愤怒识别准确率最高,悲伤识别准确率最低[9]。在基于语音信号与文本信息的双模态情感识别研究中[10],文本通道对四类情感识别准确率大致相当,但生气与高兴相对偏高。分析发现,文本通道信息对于情感识别也具有重要影响。
为了解决语音信息容易将愤怒与开心误判的问题,文中将文本通道信息加入情感识别中,以求能改善误判情况。通过采用IEMOCAP与SAVEE数据集中的语音数据提取声学特征,使用CNN(convolutional neural network)与SVM(support vector machine)分类器分别训练情感识别模型,对中性、愤怒、开心、悲伤四类情感进行识别,验证声学特征对于愤怒与开心的误判情况,并对声学特征对于其他情感的识别情况进行分析。然后,使用两个数据集中的文本数据提取文本特征,训练分类器,分析文本特征对于愤怒与开心的误判情况,并对其他情感识别情况进行分析。对两通道信息对情感识别的不同影响进行分析。最后,使用两通道融合特征训练分类模型,通过分析愤怒与开心误判的情况,判断文本通道特征是否具有弥补此问题的作用。并对两通道信息包含的对情感识别不同能力进行比较。
2 方 法
2.1 特征提取与选择
声学特征是语音情感识别中最常用的一类特征,包括音高、音强等韵律特征,频谱特征以及声音质量特征。声学特征采用开源软件openSMILE进行帧水平的低层次基础声学特征的提取,应用全局统计函数得到全局特征[11],参考了Interspeech 2010年泛语言学挑战赛(Paralinguistic Challenge)中广泛使用的特征提取配置文件。包含38个低层次声学特征,如音高、梅尔倒谱系数等,在这些低层特征上应用如最大值、最小值、均值、均方差等21个全局统计函数。如表1所示,得到共1 582维声学特征[12]。
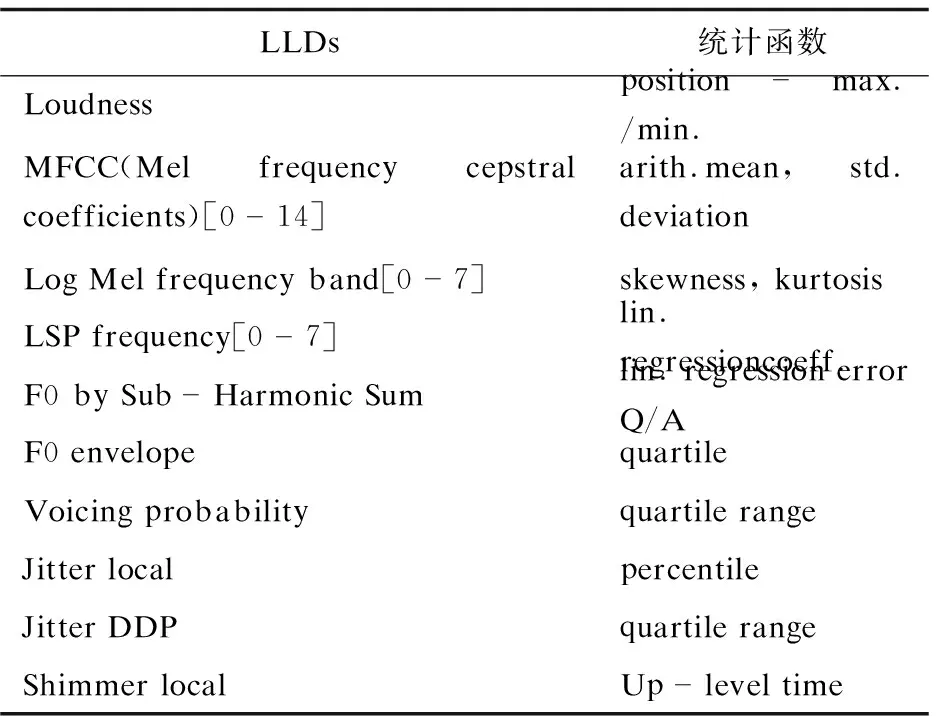
表1 低层次声学特征(LLDs)及统计函数
文本特征常用的有基于情感词典稀疏特征,基于机器学习n-gram特征以及深度学习的词向量等文本特征。文中采用基于情感词典的文本特征,采用词袋方式对样本进行处理[13],对四种情感分别进行词频统计后,提取出四百个情感词,去除重复词,得到955个词作为词典,以每个词在每个样本中出现与否作为该样本特征,出现为1,不出现为0。在IEMOCAP数据集中得到共955维文本特征。在SAVEE数据集中,提取159维文本特征。
2.2 分类器
支持向量机与卷积神经网络分类器在情感识别中应用广泛并取得了良好效果[14-15]。为了验证声学特征对愤怒与开心识别结果产生的影响,消除分类器对识别结果可能会产生的影响,文中实验分别采用SVM和CNN建立情感识别模型。对于支持向量机,使用Linear SVC,损失函数使用“squared_hinge”,损失函数的惩罚项使用“L2”正则化函数,停止标准为0.000 1,误差项的惩罚因子C设为1。卷积神经网络模型使用两个卷积层加上一个全连接层,经过softmax激活层后得到四类预测结果。使用“Adam”优化器,损失函数使用交叉熵。每十个样本计算一次梯度下降,更新一次权重。对于模型中具体参数设置,第一层使用一维的卷积层,卷积核数目采用32个,第二层卷积层采用64个卷积核,卷积核的窗长度为10,卷积步长为1,补零策略采用“same”,保留边界处的卷积结果。激活函数使用“ReLu”,为防止过拟合,在训练过程中每次更新参数时按0.2的概率随机断开输入神经元。池化层采用最大值池化方式,池化窗口大小设为2,下采样因子设为2,补零策略采用“same”,保留边界处的卷积结果。对所有训练样本循环20轮。
2.3 混淆矩阵
混淆矩阵是人工智能中重要的可视化工具。文中采用混淆矩阵方式分析愤怒与开心以及其他各类情感之间的误判情况[16]。对四类情感进行分析,横向每行表示真实结果,纵向每列表示预测结果。每一行四类值的和为一,表示所有样本数标准化后的值。从左上到右下的对角线上的值为预测正确的值,其余为误分值。混淆矩阵能详细表示出四类情感之间的误判情况,从而分析语音与文本两通道特征对于愤怒与开心的误判情况的差别。
3 实 验
3.1 数据集
采用由美国南加州大学SAIL实验室收集的IEMOCAP多模态数据集,以及Philip Jackson和Sanaul Haq等收集制作的SAVEE数据集作为实验数据。为了排除单个数据集可能对结果产生的影响,采用两个数据集验证研究结论。之前的情感识别研究中,研究者们尽量避免在不同数据集上比较多通道特征的识别表现,由于不同数据集录制方式不同,环境不同,说话人不同,表达语言不同等因素,会得到不一致的结论。因此,试图去比较不同数据集的情感识别结果,从而发现一般性的结论是一项具有挑战性的工作。本研究做出尝试,使用两个数据集的数据进行情感识别,分析情感识别中的普遍现象。
IEMOCAP(interactive emotional dyadic motion capture database)公用英文数据集由五男五女在录音室进行录制,数据集包含语音数据与文本数据,以及运动姿势数据。每个句子对应一个标签,每个样本情感在离散方式上标注为愤怒、悲伤、开心、厌恶、恐惧、惊讶、沮丧、激动、中性等九类情感。在维度上,在效价度(valence)、激活度(activation)、优势度(dominance)三个维度上进行标注[17]。由于激动和开心在之前研究中,在情感聚类识别时表现相似,区分不明显,因此将其处理为一类情感,合并为开心[18]。最终本研究参考一种常用情感识别方式,选取中性、愤怒、开心、悲伤四类情感,共5 531个样本。
SAVEE(surrey audio-visual expressed emotion)数据集,收集用于自动情感识别,数据集由四个演员,分别表演七种不同的情感,在视听的多媒体录音室中收集,包含语音与视频以及对应的文本数据,共有480个英文句子。本研究选取四类情感,共包含300个样本。
3.2 基于声学特征的情感识别
分别使用在IEMOCAP与SAVEE数据集中提取的声学特征训练分类器模型,图1表示声学特征对情感识别的结果。通过分析可以发现,与之前研究[2-3,5]取得了类似的结论,对于愤怒与开心之间误判效果较明显;同时还发现,中性与开心,中性与悲伤通过声学通道也容易产生误判;中性与愤怒,愤怒与悲伤通过声音得到有效区分。
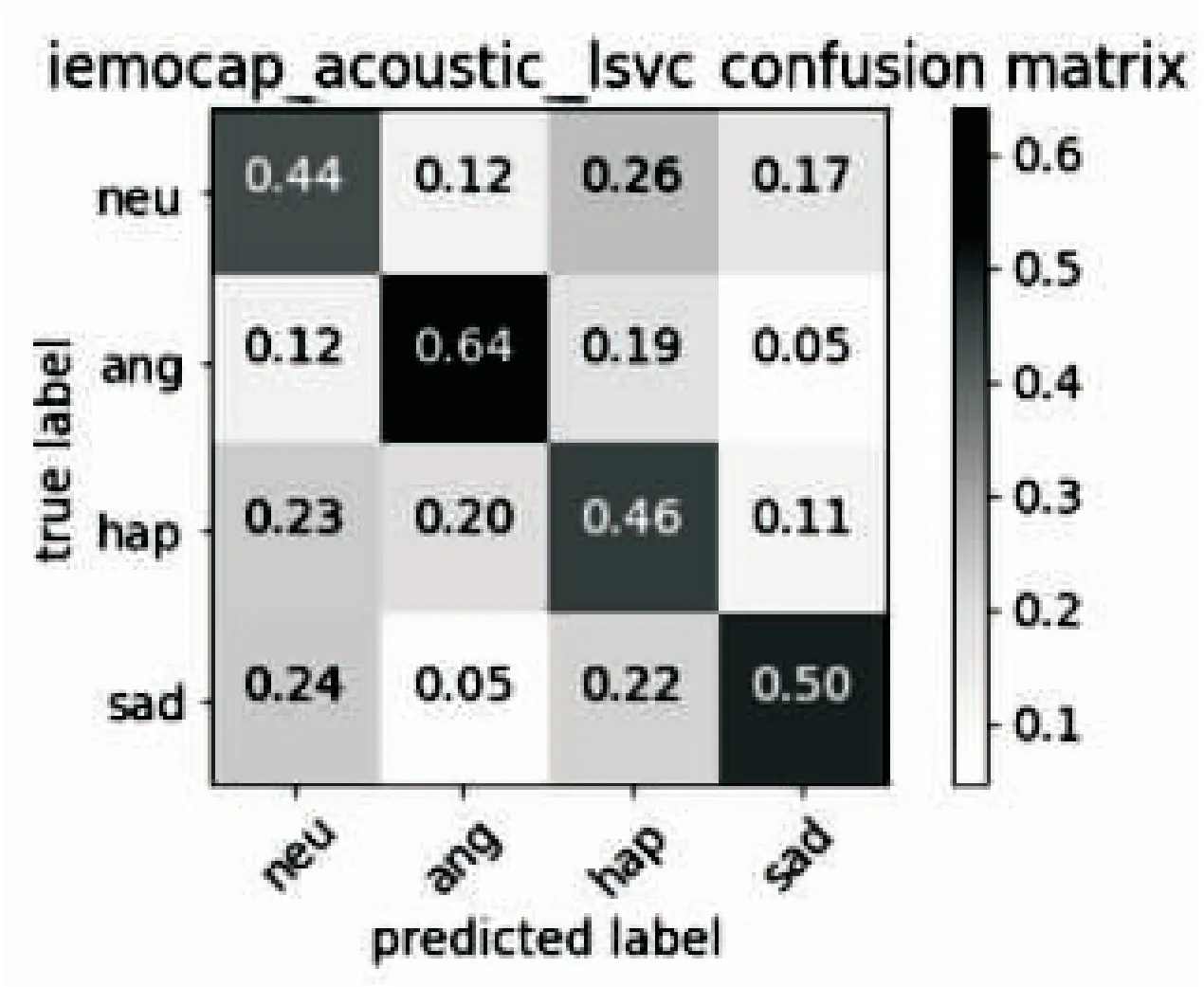
图1 声学特征情感识别混淆矩阵
3.3 基于文本特征的情感识别
分别使用IEMOCAP与SAVEE数据集中提取的文本特征训练分类器模型,图2表示文本特征对情感识别的结果。之前文本通道对情感识别的研究中[7-8],对于愤怒和开心识别准确率较高。而本研究中对愤怒识别率偏低,但是对于愤怒与开心具有良好的区分效果;同时发现文本通道特征容易将其余情感误判为中性情感;文本中的愤怒、开心、悲伤三类情感之间互相区分效果优于语音的区分效果。

图2 文本特征情感识别混淆矩阵
3.4 基于声学与文本融合特征的情感识别
通过分析发现,文本通道特征对于愤怒与开心区分良好,因此文中通过将文本特征与声学特征相融合,旨在改善愤怒与开心的误判情况。在IEMOCAP中,将声学特征与文本特征前期融合为2 537维特征,进行情感识别。在SAVEE数据集中,声学特征与文本特征融合为1 741维特征,由于样本数与特征数限制,虽然不明显但也取得了相似的结果。图3展示了IEMOCAP数据集的声学与文本融合特征,分别使用CNN与SVM分类器识别的结果。在图1中,在IEMOCAP数据集,单通道声学特征中使用CNN分类器,愤怒误判为开心的占总愤怒样本比例的0.18,开心误判为愤怒占总开心样本的0.14。在加入对愤怒与开心区分良好的文本通道特征后,如图3所示,愤怒误判为开心占愤怒样本的0.12,开心误判为愤怒的占开心样本的0.09。可见在声学通道特征中加入文本通道特征后,对于愤怒与开心的误判情况相比于单声学通道得到明显改善。
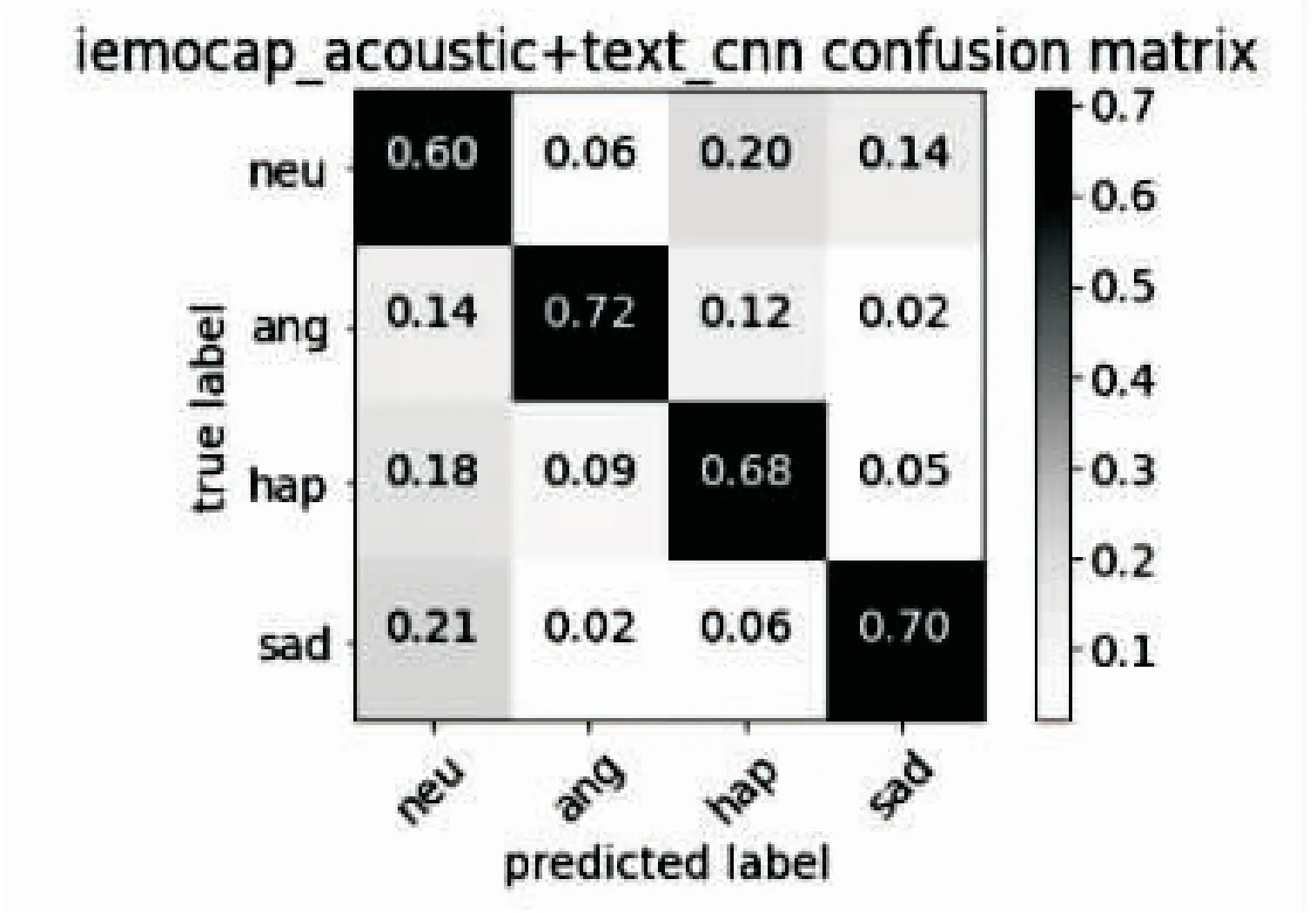
图3 声学加文本特征情感识别混淆矩阵
采用混淆矩阵方式,验证了语音对于愤怒与开心误判效果,通过加入文本特征,改善了愤怒与悲伤的误判效果。通过对识别结果的进一步分析,比较声学通道特征与文本通道特征在情感识别中的不同影响。
图4和图5分别展示了基于CNN和SVM分类器在两个数据集上的表现。

图4 声学特征情感识别

图5 文本特征情感识别
使用SVM建立的情感识别模型,对两个数据集中的两通道特征进行情感识别对比,可见CNN与SVM对于四类情感识别总体趋势类似。由图4可见,声学通道特征对愤怒与悲伤两种情感的识别准确率较高,对中性与开心识别准确率较低。由图5可见,文本通道特征对愤怒与悲伤两种情感的识别准确率较低,对中性与开心识别准确率较高。可见文本与声音中包含对情感识别具有不同作用的信息。
由图6可以看出,两通道特征融合后的特征模型相比于单通道声学模型与单通道文本模型,对于各情感分类效果均有所提升。可见声学特征与文本特征融合后没有互相干扰,且对于情感识别产生了互补作用。

图6 声学加文本特征CNN分类器情感识别
4 结束语
在语音情感识别中,愤怒与开心误判的情况普遍存在,文中加入文本信息以改善此情形。并对声音与文本中包含的情感识别能力进行比较。实验结果表明,愤怒与开心两类情感通过声学特征难以区分,容易出现误判。通过加入文本通道特征,有效改善了愤怒与开心的误判问题。同时通过分析发现,声学通道特征与文本通道特征对于情感识别有着不同影响。声学特征在情感识别时,对愤怒与悲伤的识别率较高,对中性与开心识别率较低;文本通道特征对于愤怒与悲伤的识别率较低,对中性与开心识别率较高,与声学特征呈现互补的情感识别效果;通过将两通道特征融合后,两通道信息互相影响,提高了各类情感的识别准确率。
猜你喜欢
家庭影院技术(2020年6期)2020-07-27 01:37:54
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
家庭影院技术(2019年1期)2019-01-21 02:25:04
家庭影院技术(2018年11期)2019-01-21 02:20:50
小说界(2018年5期)2018-11-26 12:43:42
家庭影院技术(2018年10期)2018-11-02 05:35:26
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
