
基于公共空间嵌入的端到端深度零样本学习
2018-11-22 12:02:48秦牧轩荆晓远
计算机技术与发展 2018年11期
秦牧轩,荆晓远,吴 飞
(南京邮电大学 自动化学院,江苏 南京 210003)
0 引 言
在图像识别技术中[1-3],零样本学习(ZSL)[4]是一种特殊的问题,在训练集中某几类样本标签缺失或者样本不存在,但是依然能够在测试任务中识别出这些样本的类别。一种全部类别共同映射的中间层特征子空间[5]技术,在零样本学习中被大量使用,通过建立一种训练类别信息与测试类别信息的连接空间,将原本使用类别信息分类能力转化到该中间层,摆脱了必须使用类别信息分类的限制。一般中间层特征空间有两种:属性(attribute)特征空间[6-7]和文本(text)特征空间[8-9]。
属性是人为定义的特征,如“形状”“纹理”“是否含有某个属性”等可以描述类别的语义特性,可以利用属性信息学习到新的类别,如Lampert等[6]提出的直接属性预测模型(direct attribute prediction,DAP)。
但是属性的分类效果取决于属性的选择好坏,同时会消耗人力物力。利用自然语言处理技术(NLP)使用文本特征作为中间层表示,是零样本学习中另一种解决模型。文本数据容易获得,且其语义相关性可以推测出未出现的类别,利用多模态[10]技术学习将图像从视觉模态映射到文本模态,来推测未知图像。Socher等[8]利用一个2层的神经网络训练一个映射函数,映射图像特征与其对应的词向量距离最近。Frome等[9]则直接连接卷积神经网络的最顶层和skip-gram语言模型的输出层,并将上述映射关系称之为嵌入(embedding)。
直接将图像特征嵌入到语义特征会由于维度降低导致枢纽度问题[11]。文献[12-13]利用一种联合嵌入模型(structured joint embedding,SJE),将图像特征和语义特征嵌入公共特征空间,使得公共特征空间中的各模态特征内积和最大,取得了良好的效果。但这些方法只是单纯地使用了CNN的图像特征,在分类时仍需要人工参与特征提取,并不是一种端到端的深度学习方法。文献[14]在深度的基础上应用一种特征融合技术,但是由于只使用词向量而效果不佳。
基于此,文中结合端到端的深度学习模型与基于公共空间的嵌入模型,提出了一种新的零样本图像分类方法,即基于公共空间嵌入的端到端深度零样本学习,可以同时利用属性特征和文本特征,并通过实验验证该方法的有效性。
1 基于卷积神经网络的图像特征学习(CNN)
CNN通过逐层对图像卷积获得低维的特征,并学习这些卷积的参数。输入图像训练集X={x1,x2,…,xi,…,xc1},经过CNN后,得到图像特征。输入227*227的三通道图像,经过5个卷积层和3个全连接层,输出n维特征向量,n为样本类别数量,每一个参数对应一个类别。神经网络的卷积层数据见表1。

表1 神经网络的卷积层数据
经过两个全连接层fc6和fc7之后,在fc8层应用softmax损失函数进行分类,同样在fc6和fc7层之后会有激活函数和drop函数。fc8层使用softmax损失函数分类:
(1)
(2)
其中,aj为第i个样本被分为j类的概率;1{y(i)=j}表示当表达式成立时值为1,否则为0。
首先建立单视觉的Fake-task模型,fc8层特征只作用于预学习,在多模态嵌入时使用的是fc7层的特征,相较于fc8层,fc7层特征能更好地表达图像层级的特征。
2 基于融合层的语义特征学习(Att、W2V)
由于使用的公共空间不依赖单一模态的特点,可以同时使用属性特征和文本特征或者融合训练该模型。如图1所示,应用一个多模态融合层,其函数定义如下:
(3)
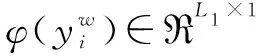
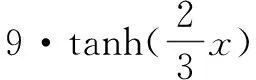
(4)
不同于属性特征,文本特征需要使用skip-gram模型训练得到。应用维基百科上面570万文本(约54亿单词)来训练一个三层全连接的神经网络,输入文本训练集Y={y1,y2,…,yc1,…,yc2},并得到文本特征,注意到文本训练集种类数量远远大于图像训练集种类数量,即c2≫c1。y定义如下:
(5)
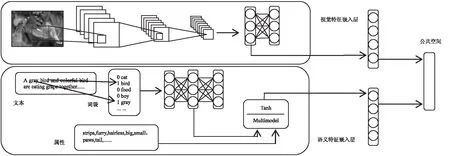
图1 视觉模态和语义模态公共空间嵌入模型
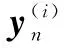
输入层经过隐层到达第三层,第三层实际上是一个Softmax分类器。同样文本模块也是一个Fake-task,目的是得到隐层的参数作为词向量。通过比较100维到2 000维的隐层权重分类效果,发现将隐层的大小设置为512维最为合适。
3 视觉-语义联合学习部分
联合学习将原有模型上的图像特征和文本特征投影到公共空间并建立一种类别对应关系。去除上文所述的图像和文本模块的分类层,替换一个全连接层映射隐层的特征到公共空间,形成一个新的损失层,损失函数为:
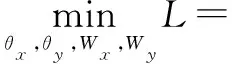
s.t.
(6)
H(x)=sigmoid(WxF)
H(y)=sigmoid(WyG)
F=f(X;θx)
G=g(Y;θy)
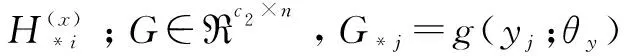
(7)
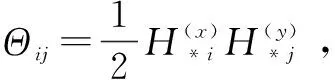
在联合训练阶段,应用随机梯度下降算法(SGD)交替迭代训练嵌入参数:
(1)固定θy和Wy,优化θx和Wx。
应用一种微调深度学习的技术(fine-tuning)对θx调优,θx前5层的参数固定不变,降低fc6和fc7的学习率10倍。在嵌入层,梯度计算如下:
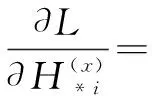
(8)
(2)固定θx,θy和Wx,优化Wy。
同样应用SGD算法优化文本嵌入层参数Wy。由于需要词向量的语义相关性,所以只训练Wy,梯度计算如下:
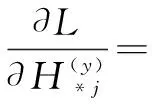
(9)
4 实 验
通过在AwA(animals with attributes)数据库和Cub鸟类数据库上的识别率波动图和平均识别率来比较文中方法与DeViSE、Ba et.al、SJE、LatEm和JLSE方法的识别性能。AwA包含30 745张50个不同动物的图片。CUB-200-2011(Caltech UCSD Bird)鸟类数据库包含了200种鸟类共11 788张图片,是目前应用广泛的细粒度分类参考之一。所有方法均采用基于余弦距离的最近邻分类器来做分类识别。
4.1 实验方法
在AwA数据库上,选择40个类别作为已知类,10个类别作为未知类;在CUB数据库上,参考文献[7]方法选取100个类别组成训练集,50个类别组成验证集,50个类别组成测试集。实验都采取随机挑选的方式运行30次。
对于AwA库,应用文献[6]提供的85维的属性特征,而CUB库上,应用文献[12]提供的312维度的属性特征。不同于固定的属性特征,文本特征使用skip-gram模型来训练所需的词向量,使用维基百科上的570万文本(约54亿单词)来训练AwA库和CUB库,特征维度为512。
4.2 实验结果与分析
表2给出了所有方法在AwA和CUB两个数据库上随机30次的识别率。图2给出了AwA库上使用词向量作为语义特征的识别率波动,图3比较了几种使用公共空间的方法。
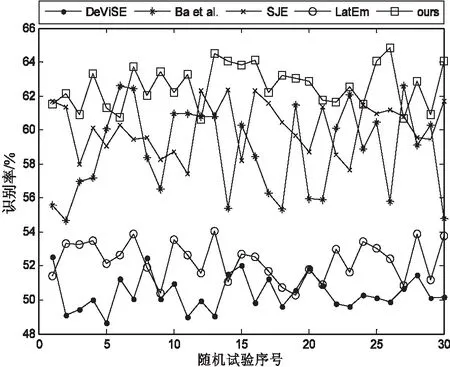
图2 AwA数据库上所有方法随机30次的识别率
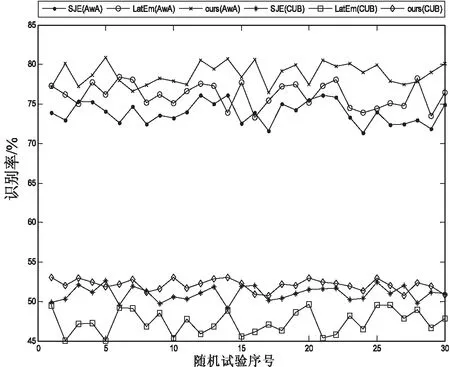
图3 使用公共空间的所有方法随机30次的识别率
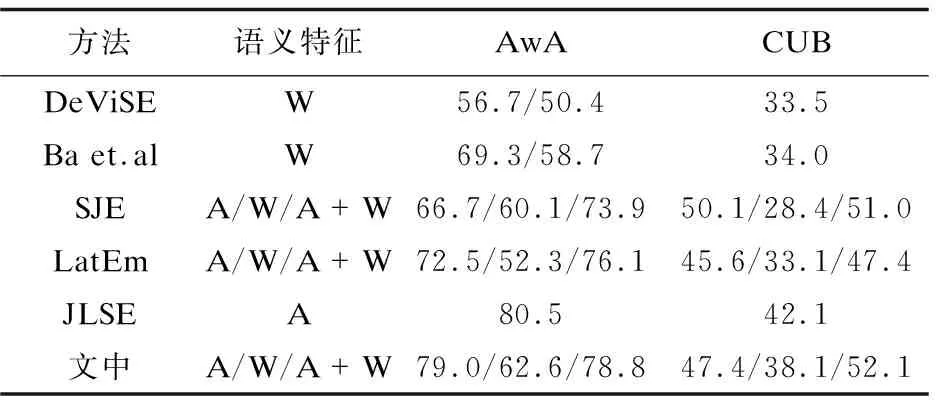
方法语义特征AwACUBDeViSEW56.7/50.433.5Ba et.alW69.3/58.734.0SJEA/W/A+W66.7/60.1/73.950.1/28.4/51.0LatEmA/W/A+W72.5/52.3/76.145.6/33.1/47.4JLSEA80.542.1文中A/W/A+W79.0/62.6/78.847.4/38.1/52.1
从表2可以看出,在AwA数据库上,文中方法无论是单独使用属性或词向量,还是同时使用混合特征,都比DeViSE、Ba et.al、SJE以及LatEm等四种方法的平均识别率提高了至少2.5%(62.6%-60.1%);在CUB数据库上,对比上述方法,文中方法虽然在单属性特征上略微输给了SJE,但是在混合特征上取得最好的效果(52.1%)。
5 结束语
建立了应用于零样本学习的端到端的深度学习模型,并使用了融合属性信息和文本信息的联合语义特征,提出了基于公共空间嵌入的端到端深度零样本学习。在AwA和CUB数据库上的实验结果表明,该方法有效地提高了识别率。
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
中国交通信息化(2016年2期)2016-06-06 07:28:02
现代语文(2016年21期)2016-05-25 13:13:44
新校长(2016年8期)2016-01-10 06:43:59
大连民族大学学报(2015年2期)2015-02-27 08:28:11
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
