
基于数据挖掘的小微商铺信用风险分析
2018-11-21 01:52:50董小刚
长春工业大学学报 2018年5期
程 晖, 董小刚
(长春工业大学 数学与统计学院, 吉林 长春 130012)
0 引 言
近年来,互联网金融业发展迅猛。由于传统银行服务小微企业的收益与成本不大匹配,同时传统银行的业务办理速度较慢,以互联网为媒介的P2P信贷经营模式得到快速发展[1]。2005年,英国尤努斯教授首次提出网络信贷服务平台概念[2]。P2P信贷的产生,虽然给中小企业和个人带来了福音,实现了金融资源的优化配置,但是其自身也存在着巨大的风险和问题,由于监管上的空白,P2P网贷各种携款潜逃、非法集资、高利贷等恶性事件时有发生。
P2P信贷平台存在巨大风险,信用风险研究角度也较为广泛。马运全[3]分别就网络借贷中逆向选择、道德风险和运作中存在的问题展开研究。艾金娣[4]分别就存在的制度风险和信用风险展开研究并提出相关防范措施。何晓玲[5]和付英军[6]认为主要是由于我国法律在这一块的空白带来的立法不完善和监管缺失的政策性风险,以及我国个人信用评价体系不健全带来的信息不对称下的信用风险和网络信贷平台自身建设的风险。虽然上述研究从不同角度分析了影响P2P网络信贷平台存在的风险因素,但是并没有更加细致地找出相关因素。文中使用R语言进行了全流程数据挖掘,选取的指标较为全面,并且使用了多种数据挖掘方法进行信用风险分析,可以普及到校园数据及各种大数据中;同时,文中旨在从借款人个人信用风险的角度去分析,为减少P2P网络信贷平台风险和完善我国P2P网络借贷行业治理提供有效建议。
1 数据来源及变量说明
近年来,信用风险的研究越来越多。姚凤阁[7]利用网络借贷平台中的借款人信息数据,选取了借款人信用等级、投标成功次数、投标流标次数、借款总额、利率、期限、每月还款、用户年龄、性别等9个指标,对P2P网络借贷平台借款人信用风险的影响进行分析,得出投标成功次数是影响借款人信用风险的最大因素且呈正相关,和借款人的借款期限、性别、年龄与借款人信用风险之间不存在相关关系的结论。方匡南[8]选取商业银行客户信用卡信贷数据中的家庭人口数、性别、年龄、婚姻、学历、职业、个人月收入、信用卡使用频率、客户是否为违约客户、信用卡张数、户籍所在地、所在地都市化程度、个人月开销占家庭月收入比例、月刷卡金额和家庭月收入共15个方面的信息来对P2P网络借贷平台借款人信用风险的影响进行分析。冯广庆[9]针对大学生群体选取了申请人的性别、年级、在校表现情况以及家庭状况来分析对大学生信用风险的影响,得出在大学生群体中女性比男性违约风险更高的结论。葛军[10]在信用卡信用风险研究中选取了申请人的性别、学历、年龄、婚姻、月收入、家庭人数、保险、职称、单位性质等9个指标变量,得出学历越高信用度越高和已婚者的违约概率比未婚者的违约概率低等结论。荣丽平[11]根据P2P网络借贷的特点,选取借款人年龄、性别、文化程度、工作年限、婚姻状况、月收入范围、是否购车、房产状况以及借款成功次数和逾期笔数等指标来对借款人的信用等级进行预测。
文中收集了文献[2]中附录的小微商铺信贷数据,通过剔除原始数据缺失值以及重复的样本数据信息,得到借款人的16个指标信息,对得到的数据通过数据挖掘技术进行分析,主要通过逻辑回归的方式进行分析,并且通过其他数据挖掘技术,如决策树、神经网络、随机森林、梯度提升等方式进行对比分析。这16个指标包括:是否为不良贷款、资产收益率、贷款原因/用途、信用记录中拖欠交易次数、店铺资产负债率比率、申请人学历、店铺经营时间、店铺年营业额、申请人信用记录、是否为本地户籍、申请人年龄、店铺月租金、申请人信用等级、店铺面积、雇员人数、所属行业。为了更好地度量P2P网络借贷平台的信用风险,文中用一个二值变量Y(BAD)来表示因变量,即若为不良贷款,则Y用1表示;若非不良贷款,则Y用0表示。具体见表1。
2 Logistic模型介绍
在分析分类变量时,常常采用对数线性模型的方法,文中用的是对数线性模型中的Logistic模型。Logistic模型[12]的优点在于它对自变量分布的假设条件没有限制,自变量可以是连续变量或离散变量;Logistic模型中的因变量是一个二分类变量。
事件发生的概率为
p(yi=1|xi)=p[(α+βxi+εi)>C]=
p[εi>(-α-βxi+C)]
当C=0时,有
p(yi=1|xi)=p[εi≤(α+βxi)]=
这个函数即为Logistic函数。
若将事件发生的概率p(yi=1|xi)记为pi,则pi表示第i个观测发生的概率,所以Logistic回归模型为
则事件不发生的概率为
所以,事件发生概率与不发生概率之比为
两边同时取对数即可将原先的非线性函数转换成一个线性函数,即
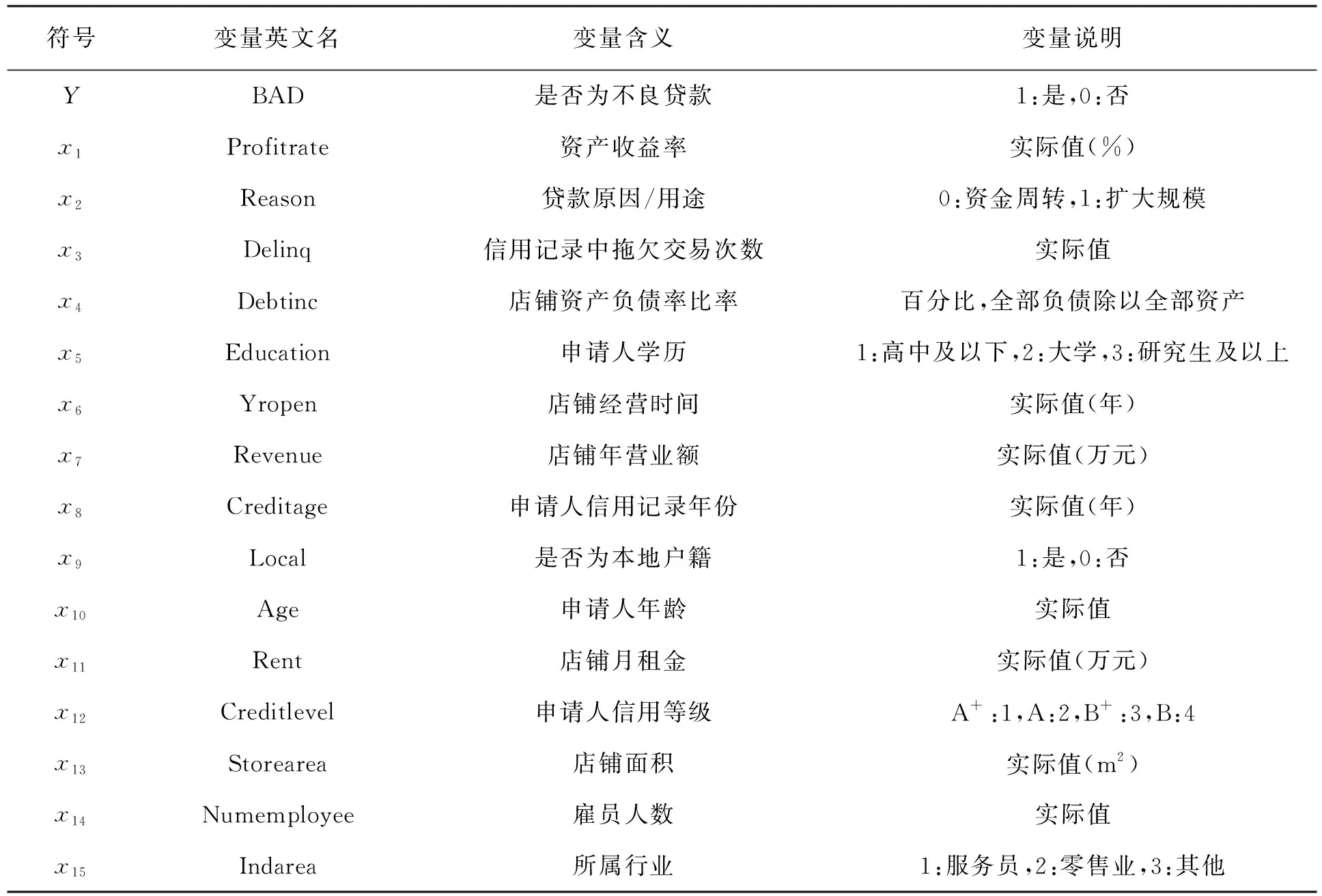
表1 信用风险度量指标量化处理
在线性回归中,常采用最小二乘法和极大似然估计法估计未知总体参数,由于Logistic回归模型是一种非线性模型,最常采用的模型估计方法是极大似然估计法。
评价Logistic模型是否有效,通常是从两个方面来看,一方面是查看模型的拟合优度,即AIC准则和SBC准则,通常情况下,AIC和SBC取值越小,模型拟合得越好;另一方面是检查模型的预测准确性。
3 实证分析
通过数据分区的方式把原始数据分成训练集和验证集,比例为70%和30%,通过训练数据集训练模型,验证集来验证模型的效果。Logistic回归模型是文中使用的重要模型之一,Logistic回归模型[12-13]虽然对自变量分布的假设条件要求没那么高,但它对共线性却非常敏感,当自变量之间存在高度的自相关时,会导致估计的标准误差膨胀,故将应用Logistic回归模型时需对是否存在共线性进行检验。文中采用的是方差膨胀因子(VIF)作为是否存在多重共线性的判断标准,检验结果见表2。

表2 多重共线性检验
所有变量的逻辑回归结果见表3。

表3 所有变量的逻辑回归结果
从检验结果可以看出,方差膨胀值(VIF)的平方根均小于2,说明这15个自变量间不存在多重共线性问题。所以,可利用统计软件R将这15个自变量进行Logistic回归建模。从输出结果来看,有2 816条样本参与了建模。本次拟合出来的Logistic回归模型为:
0.200 7x6-0.042 3x7-0.000 6x8+0.130 6x9-0.019x10-1.179 5x11+
0.637 3x12+0.010 9x13+0.105 2x14+0.095 9x15
从参数的显著性检验结果可以得到,在这15个指标变量中只有x1,x3,x4,x6,x11,x12,x13为显著非零,由于不显著变量较多,这里通过AIC准则进行变量选择,部分输出结果见表4。
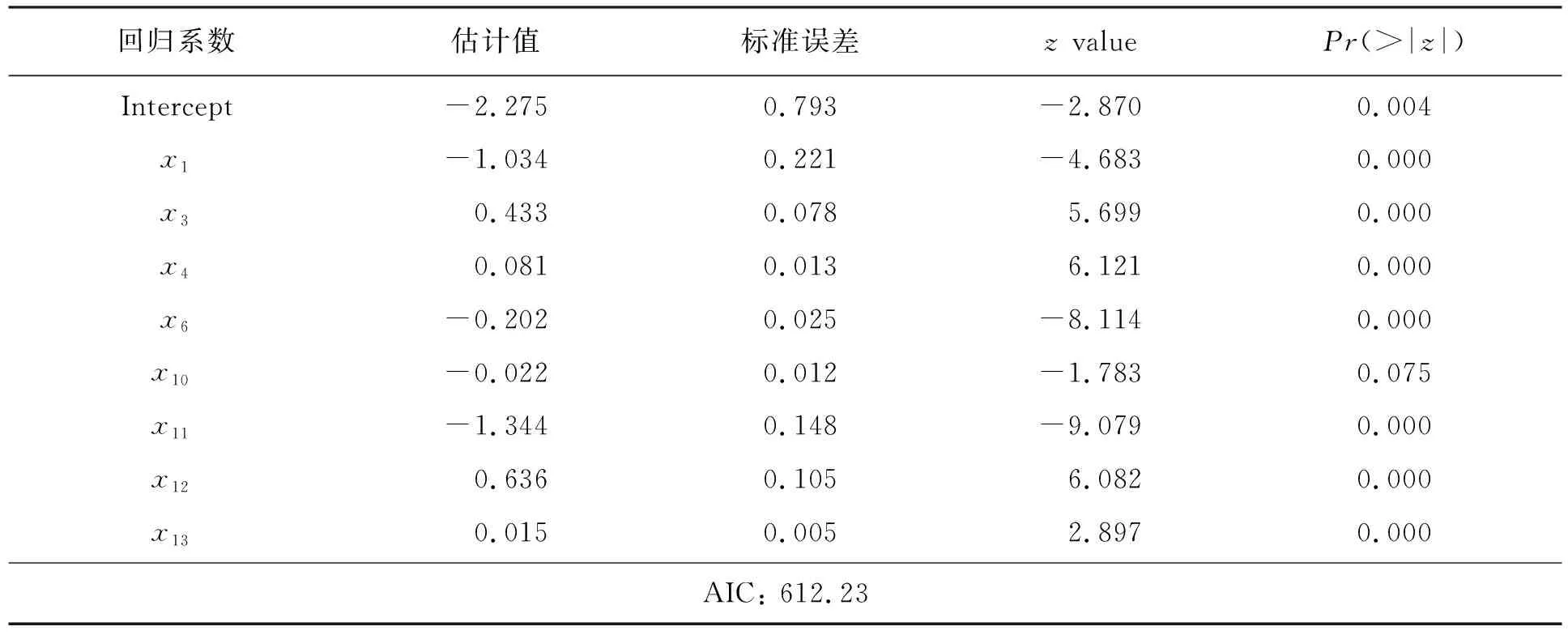
表4 向后消除法回归汇总
剔除X10后的逻辑回归结果见表5。

表5 剔除X10后的逻辑回归结果
对于逐步回归的结果分析发现,x10不显著,去除x10之后,模型的参数都显著,从而得到最终的模型,模型中包含了变量x1,x3,x4,x6,x11,x12,x13,所以最终的Logistic回归模型为:
0.438 4x3+0.082x4-
0.206 5x6-1.360 2x11+
0.648 7x12+0.014 9x13
从模型可以看出,对发生违约风险影响最大的是x11,其次是x1,再次是x12。通过上述参数估计可以计算出优比估计Odds,见表6。

表6 优比估计
由表6知:当x1提高一个单位时,不良贷款的发生比为原来的0.351倍;当信用记录中x3提高一个单位时,不良贷款的发生比为原来的1.550倍;当x4提高一个单位时,不良贷款的发生比为原来的1.085倍;当x6提高一个单位时,不良贷款的发生比为原来的0.813倍;当x11提高一个单位时,不良贷款的发生比是原来的0.257倍;当x12增加一个单位时,不良贷款的发生比将为原来的1.913倍(和表1信用等级B做比较);当x13提高一个单位时,不良贷款的发生比为原来的1.015倍。优比估计中点估计的值大于1,说明所选的自变量对事件的发生概率有正的作用。因此,x3,x4,x12,x13对事件的发生概率有正的作用,即拖欠交易次数越多,店铺资产负债比越高(影响很小),申请人信用等级越低,店铺面积越大(影响很小),发生不良贷款的可能性越高;x1,x6,x11有负的作用,即资产收益率越高,店铺经营时间越长,店铺月租金越贵,发生不良贷款的可能性将会降低。
预测精度见表7。

表7 预测精度
从表7可以看出,预测精度为0.97,预测效果很好。
将验证数据集代入上述模型进行验证,得到针对验证数据集的ROC曲线下面积AUC为0.974。验证集的ROC曲线如图1所示。

图1 验证集的ROC曲线
一般认为ROC曲线下面积达到0.75,该模型就具备了较好的预测能力。因此,从验证集上的ROC来看,模型拟合的预测效果非常好。
4 模型比较
除了使用逻辑回归进行建模,文中还采用决策树、随机森林、支持向量机等数据挖掘模型进行建模,通过对比模型的准确率、正例命中率、模型的可解释性及ROC曲线下的面积来进行模型选择。一般情况下,准确率、正例命中率和ROC曲线下面积介于0~1之间,取值越大越好,可解释性越强越好。因而综合各方面考虑,文中选取了逻辑回归作为最终的信用风险[14]模型。
模型比较见表8。

表8 模型比较
5 结 语
通过采集P2P网络信贷平台上的借款人信息,选取了2 816条借款人是否不良贷款、资产收益率、贷款原因/用途、信用记录中拖欠交易次数、店铺资产负债率比率、申请人学历、店铺经营时间、店铺年营业额、申请人信用记录、是否为本地户籍、申请人年龄、店铺月租金、申请人信用等级、店铺面积、雇员人数、所属行业等16个指标信息,利用R软件进行AIC回归选择模型,最终得知资产收益率(x1)、信用记录中拖欠交易次数(x3)、店铺资产负债比率(x4)、店铺经营时间(x6)、店铺月租金(x11)、申请人信用等级(x12)、店铺面积(x13)这7个指标变量显著非零,再利用这7个变量进行Logistic回归建模,并对该模型的预测准确性进行检验,最后得出该模型的预测准确性为0.97,并且模型验证集的ROC值远大于0.75,预测效果较好。
所以,在P2P网络信贷平台上,出借人可以着重考虑小微商铺借贷人的资产收益率(x1)、信用记录中拖欠交易次数(x3)、店铺资产负债比率(x4)、店铺经营时间(x6)、店铺月租金(x11)、申请人信用等级(x12)、店铺面积(x13)这7个指标。一般来说,信用等级越低,不良事件发生的概率就越高;拖欠交易次数越多,发生不良贷款的可能性越高;店铺资产负债比越高,发生不良贷款的可能性相对较高。此外,资产收益率越高,发生不良贷款的可能性越低;店铺经营时间越长,发生不良贷款的可能性越低;店铺月租金越贵,发生不良贷款的可能性越低。这是由于店铺租金越贵(店铺一般处在繁华地段),投入成本较多,需要大量流动资金周转。
猜你喜欢
上海财经大学学报(2019年3期)2019-06-04 08:05:24
经济技术协作信息(2018年1期)2019-01-23 06:59:54
中国军转民(2018年1期)2018-02-06 22:38:45
瞭望东方周刊(2018年4期)2018-02-01 16:56:21
消费导刊(2017年20期)2018-01-03 06:27:21
金融周刊(2016年19期)2016-07-13 18:53:23
黑龙江科学(2016年22期)2016-03-16 00:47:40
中国房地产业(2016年8期)2016-03-01 01:25:56
中国经济信息(2015年8期)2015-05-05 09:13:23
金融法苑(2014年2期)2014-10-17 02:53:27
