
基于FPGA的模板滤波IP核的设计与实现
2018-11-20 03:40田劲东
深圳大学学报(理工版) 2018年6期
李 东,敖 晟,田劲东,田 勇
深圳大学光电工程学院,广东深圳51860
在数字图像处理中,空间域对图像进行处理是一类重要的方法.空间滤波操作包含线性和非线性滤波,经常涉及图像卷积运算.由于卷积运算需要非常大的乘法和加法运算量,因此,处理高分辨率图像时非常耗时[1].随着集成电路工艺的进步,现场可编程门阵列(field-programmable gate array, FPGA)的性能得到了显著提升,为用户提供了更多的硬件资源和更高的数据处理速度.由于图像卷积运算的并行特性,使其可结合FPGA的并行运算来提升硬件的数据处理速度,并能利用流水线技术实现1 clocks/pixel的吞吐率[2].为此,不少学者从执行效率、占用资源和接口等方面分析各种卷积结构.BOSI等[3]提出采用多个移位寄存器组构成传统图像卷积器的硬件结构——完全缓冲 (full buffering,FB),利用3×3 pixel的卷积单元采用组合扩展级联结构的方法,实现了窗口可调.这种方法不需外部缓存,但是占用了大量的片上资源,执行效率不高且接口复杂.ZHANG等[4]提出单窗口部分缓冲(single-window partial buffering, SWPB)和多窗口部分缓冲(mutiple-window partial buffering, MWPB)结构.其中,SWPB结构裁剪了FB中采用的像素缓存结构,减少了资源的开销,但同时增加了外部带宽的消耗;MWPB利用相邻窗口共用部分图像数据的原理,最大限度地使用已经缓存在片上的数据来降低外部带宽,以期不增加片上存储器容量.SWPB和MWPB结构增加了控制的复杂度,但很好地平衡了内部缓存资源和外部带宽.然而,这些结构都局限在固定卷积窗口和系数的前提下,需要外部存储器,可复用性较差,不具备良好的通用性和可移植性.桑红石等[5]提出一种带宽需求低,硬件资源开销小的新型2D卷积器结构,但是需要外部存储器缓存图像数据,数据处理的整体速率低于FB硬件架构,且不能灵活调整窗口大小和权重系数.朱学亮等[6]提出一种基于FB架构的卷积运算IP(intellectual property)核的方法,通过对IP核参数的设置来配置内部资源,可根据实际需要生成不同大小的窗口和卷积系数.该方法模板大小受级联结构的约束,改变模板大小的同时需要重新配置系数的数目,且接口调用不够灵活,还存在缓存资源浪费问题.本研究在衡量了效率、资源和接口等因素后,提出一种基于FPGA的可变模板滤波IP核的设计方法,只需修改接口参数即可实现硬件结构的灵活调整,具有很强的可复用性.
1 模板滤波IP核的设计
1.1 图像的卷积运算
在图像处理邻域中,卷积运算是指用一个卷积核对图像中的每个像素进行一系列操作,这种方法也称为滤波.卷积核是图像滤波的核心,是一个二维的滤波器矩阵,该矩阵中每个位置都有一个权重值,通过对原图像进行邻域的加权求和,从而实现图像的卷积运算.先确定一个中心点(x,y), 然后对该中心点邻域内的像素进行卷积运算,并对图像中的每一点进行同样的操作,将运算后的结果做为该点的响应.以3×3 pixel的卷积核为例,一共有9个系数,用矩阵的方式表示,称为掩膜.如图1,黑色部分代表中心像素点,将掩膜中心放置在此像素位置,灰色部分代表图像像素与掩膜重叠的部分.在这个过程中,掩膜在图像矩阵中逐点移动并进行计算,将计算的结果替代中心像素点的值.遍历整幅图像,即完成了一次卷积运算[6].
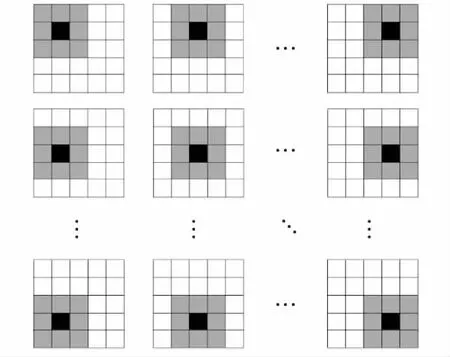
图1 图像卷积运算示意图Fig.1 Image convolution operation diagram
1.2 IP核总体结构的设计
硬件电路中的模块参数化和可重构性要求架构尽量简单化.本设计在传统图像卷积器FB结构上进行拓展,像素缓存结构采用并行的行缓存[8],便于窗口大小能够灵活调整.由于数据输入与处理时钟一致,并且移位寄存器的读取比先进先出(first in first out,FIFO)更易操作,因此用移位寄存器来实现行缓存,本研究直接调用Altera公司的IP核移位寄存器(shift register).通过重新定义IP核的参数,可实现移位寄存器位宽和深度的实时调节.因为卷积窗口是有规律的例化像素缓存结构,可以用循环语句来实现,这样可同时简化代码和调整窗口.在Verilog-2001软件中,generate for语句可以对一个模块产生多次例化,为可变尺度提供了方便.
以N×N的卷积单元阵列为例,其IP核的硬件结构如图2.其中,Line_buffer1, Line_buffer2, …, Line_buffer(N-1)为N-1个行寄存器组,Din和Dout分别是每个行寄存器组的输入和输出端,P0,P1, …,PN2-1是N2个寄存器.移位寄存器之间首尾相连,每个行寄存器组中的寄存器数目和对应的一行图像数据的数目相同,寄存器的深度跟所接收的图像数据位宽相同,且在每个移位寄存器行外部连接N个寄存器,这N个寄存器也是首尾相连.对卷积单元中N2个寄存器的值与外部输入的权重系数做乘法运算,再通过加法树模块两两相加,得到卷积计算结果.从图2可知,除了Din0与数据输入端Pix_in相连,其余第M个(M=0,1,…,N-1)移位寄存器的输出端Dout(M)分别与第M+1个移位寄存器的输入端Din(M+1)和第M×N个寄存器PMN相连,同时,每个窗口寄存器PM都与前一个PM-1组成流水线,满足循环变量、循环体和终止条件的3个因素.因此,利用上述提到的循环迭代多次例化的方法,不仅可大幅减少工作量,且只需修改若干个参数就能灵活调整卷积单元的硬件结构,接口方便,操作省时省力,解决了以往不同大小的卷积核要重新更改硬件结构的不便之处.
本研究设计的IP核是基于FB架构的扩展,因此不需要外部存储器缓存就可直接对前端传入的图像数据进行实时预处理,所以数据处理效率更高.对于不连续的图像数据,如FIFO或者外部存储器输出的间断图像数据,都可进行卷积运算,提高了系统的鲁棒性.
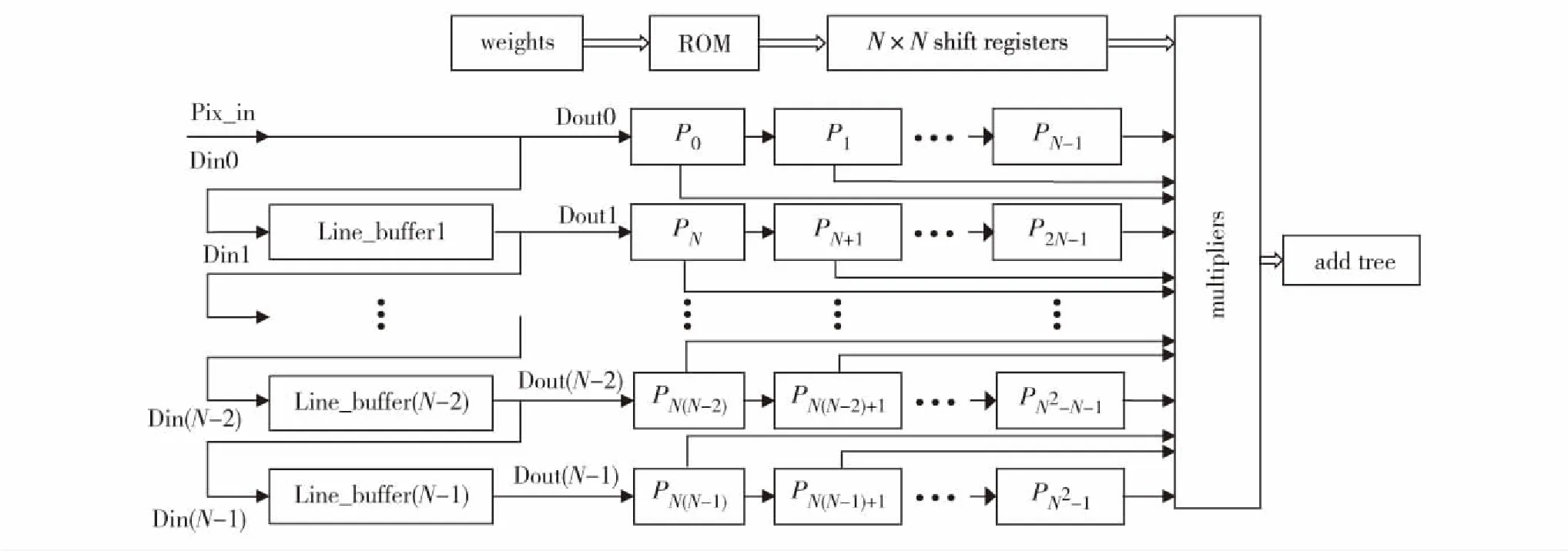
图2 IP核总体硬件结构Fig.2 IP core overall hardware structure
1.3 卷积系数模块的设计

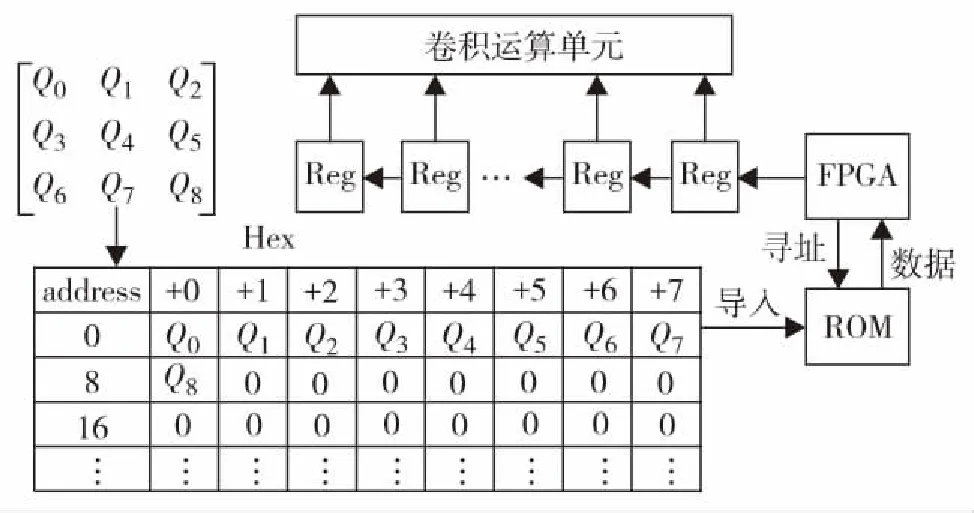
图3 系数接口结构Fig.3 Coefficient interface structure
1.4 加法树模块
加法树模块是将卷积运算中的乘法运算结果累加起来,由于掩膜系数是任意的,乘法运算采用的是有符号乘法,因此加法树中也采用有符号加法器.当卷积窗口较小时,可采用传统办法逐个累加,累加1次做一级流水线,N个数据运算完毕需要(N-1)个时钟周期,即需N-1个加法器.此方法虽然简单,但数据较多时运算耗时久,代码可维护性差,不适于大窗口的卷积运算.利用FPGA并行运行的特点,可在1 clock内实现对多个数据同时进行加法运算.
当卷积窗口大小为N×N时,所需乘法运算的数目也是N2个,所以加法树要对N2个数据进行加法运算.图4给出了基于上述思想的加法树硬件结构.其中,D0,D1,…,DN2-1是输入数据.
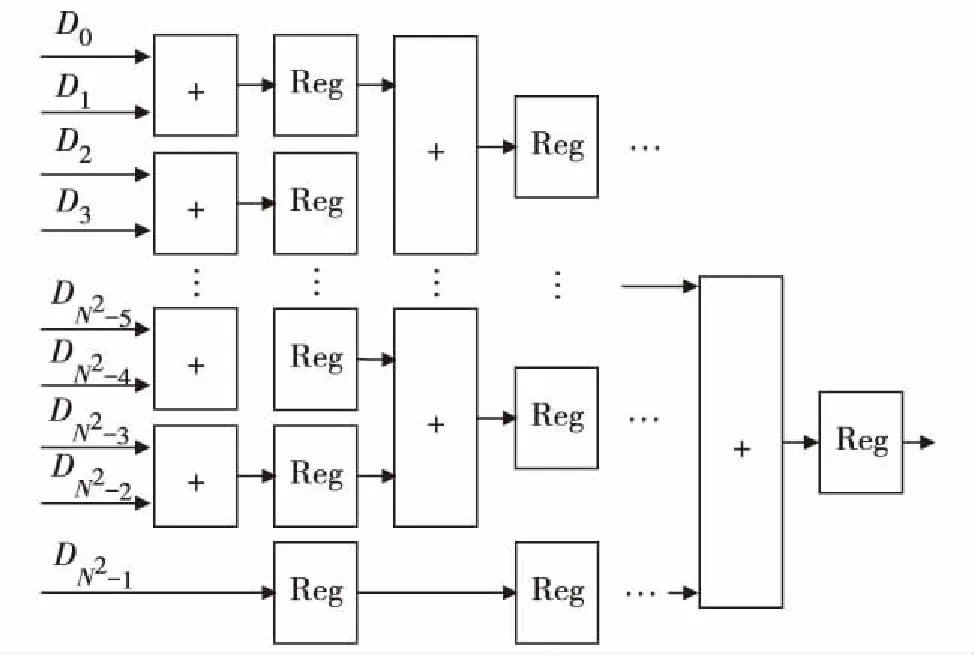
图4 N×N加法树结构Fig.4 N×N addition tree structure
加法运算调用了Altera公司的有符号加法器IP核.首先将相邻的两个数据两两进行加法运算,如果N2是偶数,第1次运算需要N2/2个加法器、N2/2个寄存器,第2次运算需要N2/4个加法器、N2/4个寄存器;如果N2是奇数,第1次运算需要(N2-1)/2个加法器、 (N2-1)/2+1个寄存器,第2次运算需要(N2-1)/4个加法器、 (N2-1)/4+1个寄存器.依此类推,则第n次运算待相加的数据数目为
(1)
其中, 初始值a0=N×N,N×N为卷积窗口大小.每次的运算开支为1 clock.加法树运算全部完成需要的运算次数n应满足式(2),完成全部运算所需时钟数也为n.
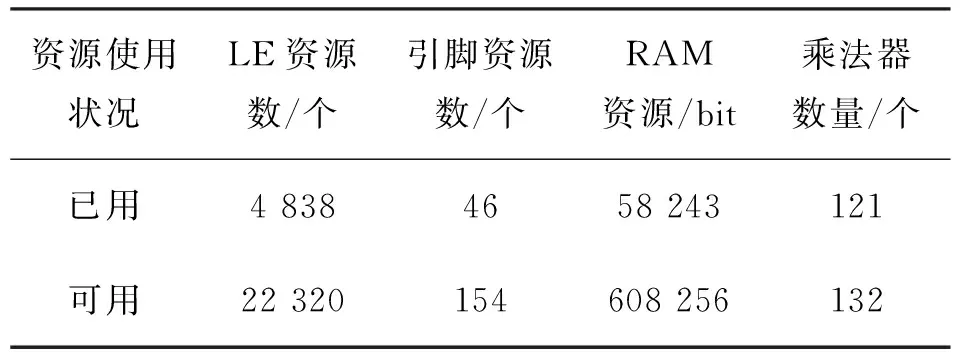
2n-1 (2) 因此,对于N个数据,累加完毕所需的时钟周期数n满足 lbN≤n<1+lbN (3) 与传统累加方法相比,加法树运算所需时钟数目大大减少,因此提高了运算效率和代码可维护性.要实现上述加法树架构,可用循环迭代或者递归运算[9]的方法实现. 本研究使用Altera公司的Cyclone IV系列FPGA(型号为EP4CE22F17C8).利用所设计的模板滤波IP核,分别对不同窗口大小的高斯滤波[10-11]和Sobel算子[12]进行验证.图5分别列出了窗口大小为3×3 pixel和5×5 pixel的高斯滤波模板和Sobel水平和垂直方向上的掩膜. 116121242121 12731474141626164726412674162616414741 (a)3×3 pixel窗口的高斯滤波模板(b)5×5 pixel窗口的高斯滤波模板-1-2-1000121 -101-202-101 (c)Sobel水平方向掩膜(d)Sobel垂直方向掩膜 图5高斯滤波模板和Sobel掩膜 Fig.5GaussianfiltertemplateandSobelmask 图6(a)是相机采集到的初始图像;图6(b)和图6(c)分别是初始图像在FPGA上经过3×3 pixel和5×5 pixel高斯滤波模板的处理结果,边界采用置零处理;图6(d)是FPGA进行Sobel边缘提取算子的结果. 为验证算法的准确性,将FPGA硬件处理结果与Matlab软件处理结果进行对比,结果如图7.图7(a)是初始图像;图7(b)和图7(c)分别是采用Matlab软件对原图进行窗口为3×3 pixel和5×5 pixel高斯滤波模板的处理结果;图7(d)是采用Sobel边缘提取算子处理的结果.对比图6和图7可知,FPGA硬件处理与Matlab软件处理结果基本吻合. 本研究提出的可变模板滤波IP核的设计能很好地实现窗口大小和卷积系数的灵活调整,为综合评估IP核的性能,表1列出了窗口大小为11×11 pixel时FPGA片上资源使用情况. 图6 FPGA结合IP核的处理结果Fig.6 The processing results of FPGA combined with IP core 图7 Matlab处理结果Fig.7 Matlab processing results 表1 FPGA片上资源使用情况Table 1 The usage of FPGA resource on-chip 由表1可见,逻辑元件(logic element, LE)资源占用率约为22%;引脚资源使用率比较高,约为30%,这是因为运算结果的输出位宽比较大,所以占用的引脚数较多;随机存取存储器(random access menory, RAM)资源占用率约为10%,主要是在行缓存时生成移位寄存器组;乘法器资源占用率最高,约为92%,这是因为对于任意模板系数,每个卷积窗口单元要与相应的系数进行有符号的乘法运算,所以乘法器的使用数目与窗口大小相同.本器件的乘法器资源有限,最大能生成11×11 pixel的窗口. 根据上述实验结果,与文献[3]相比,本研究方法不存在资源浪费现象;与文献[5]相比,本研究方法在接口部分实现了灵活的调整,不需增加外部存储器,可复用性好;和文献[6]相比,本研究方法在窗口大小改变时会自动配置权重系数的数目,接口调用更加灵活.若需要对更大的窗口进行卷积运算,可用逻辑单元自行搭建乘法器,或选择更多片上资源的FPGA芯片.文献[13-14]给出了一种能有效减少乘法器和片上资源占用的RD(recurrent decomposable)卷积器架构,通过将大的模板反复分解成若干个较小的模板,然后计算与图像的卷积.文献[15]提出一种使用Bachet权重分解方法设计新的二维卷积滤波器,滤波器通过使用一组预先计算的系数,用简化的浮点加法器,替代乘法器来模拟标准的32 bit浮点乘法器.因此,可利用这两种方法弥补乘法器资源不足的缺陷,从而提高IP核的实用性. 表2分析了各种卷积器结构在资源开销、外部带宽和吞吐率等方面的表现.记图像大小为M×N; 卷积窗口大小为R×S;P为FIFO的深度.FB架构是将图像的R-1行像素全部缓存在片上,缓存结构采用列缓存,因此这部分资源开销为(R-1)×(N-S)+P, 卷积窗口的资源开销为R×S, 可不需外部存储器,外部带宽和吞吐率都为1.SWPB架构使用了深度很小的R条FIFO代替移位寄存器进行数据缓存,缓存结构的资源开销为R×P, 卷积窗口的资源开销为R×S, 不过需要R个并行的数据输入,因此外部带宽为R(单位:pixels/clock),吞吐率为1 clocks/pixel.MWPB架构将卷积窗口扩展为(R+S-1)×S,用来保存列方向上相邻的S个卷积计算窗口,这样S个时钟周期内可得到S个卷积计算窗口的结果. 其中,缓存结构的资源开销为(R+S-1)×P; 卷积窗口的资源开销为(R+S-1)×S; 外部带宽则为(R+S-1)/S; 吞吐率也为1 clocks/pixel.虽然SWPB和MWPB架构资源开销较少,但需要并行的数据写入流来保证卷积计算所需的数据量,即利用外部存储器实现多通道输入.当窗口大小改变时,带宽也需随之变化.由于软IP核不涉及物理实现,为了提高灵活性,采用便于集成,且外部带宽仅为1 pixels/clock的FB架构. 表2 R×S卷积器的性能比较Table 2 Performance comparison for a R×S convolver 本研究提出的IP核卷积结构是基于FB架构,像素的缓存结构采用并行的行缓存,因此数据缓存的开销为(R-1)×S+P, 卷积窗口、外部带宽和吞吐率都与FB架构相同.以640×480像素图像为例,设P=8, 得到本研究方法与传统组合扩展方法的性能比较如表3.以5×5 pixel和7×7 pixel的模板滤波为例,传统的组合扩展会造成资源浪费,且当模板越大时,资源浪费越严重.对于5×5 pixel的模板,组合级联扩展方式是将4个3×3 pixel卷积单元组合成6×6 pixel的卷积结构,然后,从中选择需要的5×5 pixel模板.7×7 pixel的模板则是将9个3×3 pixel的卷积单元组合成9×9 pixel的卷积结构,再选择所需要的7×7 pixel大小.本研究提出的扩展结构充分利用了循环结构的优势,利用ROM载入权重系数,并根据需求自动调整窗口,不存在资源浪费现象.根据上述分析,组合扩展方法的窗口大小受限于最大模板,而且选择小模板时需要将冗余的系数接口置零,造成乘法资源的浪费,同时,此硬件结构不易维护,因此不是IP核最优设计.本研究的IP核结构不存在上述问题,充分体现了可再用、可重定义及可配置的优势. 表3 级联扩展方法的性能比较(FB架构)Table 3 Performance comparison of cascaded extension methods(FB architecture) 针对FPGA进行图像卷积运算可重构性差的特点,提出一种可变模板滤波IP核的设计.利用循环迭代多次例化的方法设计卷积结构,实现了模板大小可调;利用ROM读取Hex文件中保存的权重系数,实现了模板系数可调;基于对分思想设计加法树模块,实现了对时间和结构的优化.IP核基于模块化设计,且兼具可扩展性,既简化了硬件设计,节省了片上资源的消耗,又实现了参数化的滤波窗口大小可调,并兼容任意模板系数.本设计不仅适用于各种图像大小进行不同模板滤波的处理,具有很好的可移植性,同时因为不需要外部存储器的缓存,可直接对前端传入的图像数据进行实时预处理,处理速率快,1 clocks/pixel的吞吐率实现了对图像算法的硬件加速.2 结果与验证





结 语
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
有色金属设计(2022年4期)2022-02-04
汽车工程(2021年12期)2021-03-08
计算机应用(2020年5期)2020-06-07
时代人物(2019年27期)2019-10-23
电子技术与软件工程(2018年1期)2018-03-22
计算机测量与控制(2017年6期)2017-07-01
海军航空大学学报(2015年1期)2015-11-11
空间控制技术与应用(2015年3期)2015-06-05
遥测遥控(2015年2期)2015-04-23
