
采用击键特征曲线差异度的用户身份认证方法
2018-11-17 02:50贺冰清
计算机工程与应用 2018年22期
王 林,贺冰清
西安理工大学 自动化与信息工程学院,西安 710048
1 引言
近年来,人们使用大量的在线网络应用程序,这些程序包括社交媒体平台(如Facebook、Twitter、Weibo)、云存储服务(如Drobox、Google Drive)和一些在线网络游戏。然而这些网络应用程序带来的网络犯罪竟然在不知不觉中蔓延到了世界各地。严重的网络犯罪是指一些犯罪分子利用互联网侵入受害者的账户,盗取包括密码和金融财产在内的敏感信息。为了解决盗窃问题,人们通过一种额外的生物认证机制进入到在线程序或设备中来提高用户账号的安全性。在目前的各种计算机安全措施中,一种是使用基于口令的传统身份验证技术,但是口令容易泄漏;另一种是使用一些物理令牌(智能卡等)来代替简单口令,但是该方法要求系统配备相应的硬件设备,使得成本增加,而且也存在物理令牌丢失、窃取、复制等问题。由于人的生物特征具有不可复制、难以改变等特性,使得生物特征识别技术成为研究热点。常见的生物特征识别技术有指纹识别技术、人脸识别技术、虹膜识别技术等。但上述技术都需要配备成本较高的硬件设备,使其应用不方便且难以普及。
20世纪80年代初期,美国国家标准局和国家科学基金通过研究已经证实了人的击键行为特征能够被识别。人与人之间按键的力度和节奏会有较明显的差异,在一般情况下可以用来区分不同的人,从而对人的身份进行识别。
击键动态身份认证是一种基于击键特性(例如击键时延、击键力量等)进行身份识别的生物认证技术。该方法通过监测用户的键盘输入,采集击键数据,对用户的击键行为特征进行分类建模,由此来进行用户身份的判别。击键动态身份认证不仅解决了传统基于口令身份验证的安全性问题,同时和其他生物识别技术相比,不需要额外昂贵的硬件设备,具有成本低、灵活性高等优点。
当前研究的击键特征主要分两类[1]:一是分析固定文本(比如用户密码)的击键特征;另一类是分析自由文本的击键特征。下面分别简述这两类的研究现状:
(1)固定文本。2010年,Harun等人[2]针对静态文本下的Latency特征进行了研究,提出了一种人工智能神经网络的分类算法,并将平均错误率降低到3%左右。2012年,Li等人[3]提出了一种将统计和加权算法相结合的改进算法,使得认证的准确度高于单一的统计学算法。2014年,李福祥等人[4]对面向击键动态身份认证的多模板选择算法进行研究,提出均衡概率多模板选择算法,该算法相比单模板具有一定优势,可将认证错误率控制在合理范围内。2015年,易彬等人[5]在朴素贝叶斯分类理论的背景下,提出一种改进的加权贝叶斯方法;Darabseh等人[6]研究了利用遗传、粒子群等优化算法,从大量的击键特征中提取更有效的特征量,进而降低训练和识别的时间和计算量。2016年,Putri等人[7]将击键动态和触摸手势相结合,提出一种可应用于安卓手机系统的混合认证算法。2017年,Alpar等人[8]将时域上的击键特征量通过短时间的离散傅里叶变换转移到时-频域上,采用高斯-牛顿神经网络分类器得到了4.1%的相等错误率;Ho等人[9]利用小批量打包(Mini-Batch Bagging)方法提出一种用于击键认证的机器学习改进算法;何斯译等人[10]提出一种击键认证的模板双更新方法,该方法同时更新模板中的中心点及其容忍半径,能适应用户在前期击键习惯变化较大而在后期基本不变的特点。
上述文献中均采用击键时间间隔和击键持续时间作为特征向量,区别仅在于采用了不同的认证识别算法。另外,大多数文献由于没有公开性能测试中所使用的数据集,相关认证算法的应用范围可能具有一定程度的局限性。
(2)自由文本。相对于固定文本,自由输入的击键特征的分析更困难,识别率也相对低一些。自由输入击键特征的分析方法借鉴了成熟的固定文本的击键特征的分析方法,常用的包括统计学方法[11]、神经网络[12]、决策树[13]、支持向量机[14]、加权相对距离[15]和相对熵[16]等。
本文主要研究固定文本的击键认证算法。通过对大量击键认证算法文献的研究可知,大部分的击键认证算法均使用由击键时间间隔和击键持续时间构成的时间特征向量,主要研究基于不同原理的识别算法,而没有研究如何引入新的特征量以提高认证效果。这些认证算法仅利用了击键时间特征向量中所包含的每个特征值的大小来进行身份识别,而没有考虑任意两个相邻特征值之间的变化率。在一些情况下,可能导致认证准确度并不是十分理想。此外,大多数文献未使用公开的数据集检验认证算法性能,导致相关算法在应用范围方面具有一定程度的局限性。因此,针对上述问题,本文提出了一种击键特征曲线差异度的概念,其既与击键时间特征向量中每个特征值的大小相关,还能体现出任意两个相邻特征值之间的变化率信息。与此同时,利用已公开的数据集进行大量实验以检验所提算法的性能。
本文将击键特征曲线差异度的思想应用于击键动态身份认证,提出了一种新颖的基于击键特征曲线差异度的识别算法。实验表明,与已经广泛应用的传统认证方法相比,本文算法的错误拒绝率(False Reject Rate,FRR)、错误接受率(False Accept Rate,FAR)和相等错误率(Equal Error Rate,EER)更低,识别准确度更高,效果更好,即使在训练样本较少的情况下,依然能取得较好的认证效果。
2 击键特征及性能评价指标
2.1 击键特征
当用户敲击键盘进行输入时,若干特征可以被检测到,主要包括击键时间间隔、击键持续时间、总的输入速度、错误频率、使用键盘上额外按键的习惯、大写字母的输入方式和击键力度(需要使用特殊的键盘)等。但是,一般的击键认证算法的设计并不必采用所有上述特征,其中击键时间间隔和持续时间是最常用的特征量。
击键持续时间指某个按键被按下到其弹起的时间间隔。
击键时间间隔指从某个键被按下到其紧挨着的下一个键被按下的时间间隔。
2.2 性能评价指标
与其他生物认证技术类似,主要有以下指标用于评估击键动态认证的性能。
(1)错误拒绝率(FRR)
合法用户的登录请求被当作非法用户(而被拒绝)的比例。错误拒绝率越高,表明认证系统越严格,系统可行性与便利性越低。

(2)错误接受率(FAR)
非法用户以合法用户的身份进行登录的请求被系统接受的比例。错误接受率越高,表明认证系统性能越低,系统被非法用户攻入的机会越大。

(3)相等错误率(EER)
FAR与FRR随阈值变化曲线的交点值,该点处FAR与FRR值相等。在算法中,可以通过调节来达到不同安全强度的参数,叫作阈值。EER可以作为一个单项性能指标,因为它表明当FAR和FRR相等时的误差量度,EER值越低,代表这个认证或识别方法的性能越好。
3 基于击键特征曲线差异度的识别方法
3.1 设计思想
由于传统的击键认证算法通常仅采用击键持续时间和击键时间间隔的大小,导致在一些情况下无法正确识别用户身份。例如,采集用户A和B输入相同密码“tire”时的击键特征,用户A某次采集的击键持续时间向量为,击键时间间隔向量为[210,180,230]ms,用户B某次采集的击键持续时间向量为,击键时间间隔向量为[170,220,190]ms。假设用户A和B所有采集样本的平均击键持续时间向量和击键时间间隔向量相同此时如果采用经典的曼哈顿距离(Manhattan)算法,则无法正确区分用户A和B。
但是,通过分析可知,用户A和B任意两个相邻特征值之间的变化率是完全相反的。例如,用户A按键“t”和“i”的持续时间分别为70 ms和60 ms,其变化率为-10 ms;用户B按键“t”和“i”的持续时间分别为60 ms和80 ms,其变化率为20 ms。因此,利用两个相邻特征值之间的变化率,可以很容易地将用户A和B区分开来。
为了将任意两个相邻特征值之间的变化率引入击键认证算法中,本文定义了一种击键特征曲线差异度的概念,既包含了常规的击键特征量,又能体现出任意两个相邻特征值之间的变化率信息。基于上述思想,本文提出一种新颖的识别算法,可以进一步提高击键认证算法的性能,识别准确度更高,效果更好。
3.2 击键特征曲线差异度
对于具体的某个用户,通过预先多次采集其击键数据可以构成一个击键数据集,其中的样本均属于与该用户相对应的模式类。
击键数据集由两个子集组成,分别是输入密码时的击键持续时间数据集Spr和击键时间间隔数据集Spp。
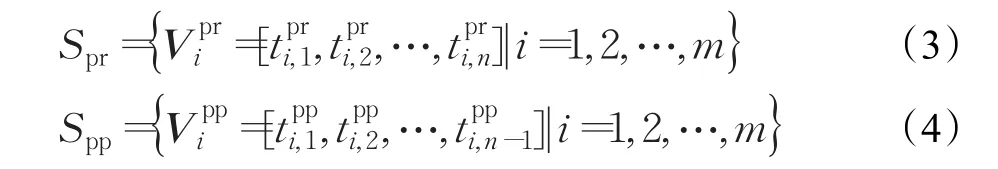
数据集Spr中的任意元素均可用曲线表示,曲线的横坐标为 j,纵坐标为j=1,2,…,n ,如图1(a)所示。同理,数据集Spp中的任意元素也可用曲线表示,曲线的横坐标为k,纵坐标为k=1,2,…,n-1,如图1(b)所示。文中将上述曲线称为击键特征曲线。

图1 击键特征曲线
根据每个数据集Spr和Spp中所包含的元素取值,可获得相应的m条击键特征曲线,然后采用统计学方法计算击键特征曲线的上下边界。
首先,设集合Spr和Spp中所包含元素的均值分别为,则:

其次,设集合Spr和Spp中所包含元素的标准差分别为,则:

最后,设集合Spr中所包含元素的上、下边界分别为,集合 Spp中所包含元素的上、下边界分别为,则:
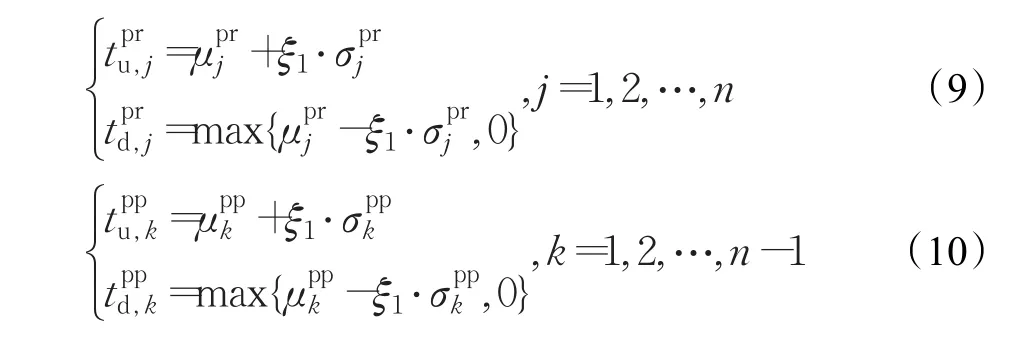
式中,ξ1为可调节的阈值,取值范围为0~3。
注1 ξ1的取值范围是根据中心极限定理(即假定采集的击键时间特征量服从正态分布)而确定的。ξ1值越大,上、下边界的范围越大,样本处于边界内的概率增加,从而使FRR值减小,FAR值增大;ξ1值越大,上、下边界的范围越小,样本处于边界内的概率减小,进而使得FRR值增大,FAR值减小。选取的ξ1值应尽可能使EER值达到最小值,ξ1取值范围是0~3,一般可选取ξ1=2。
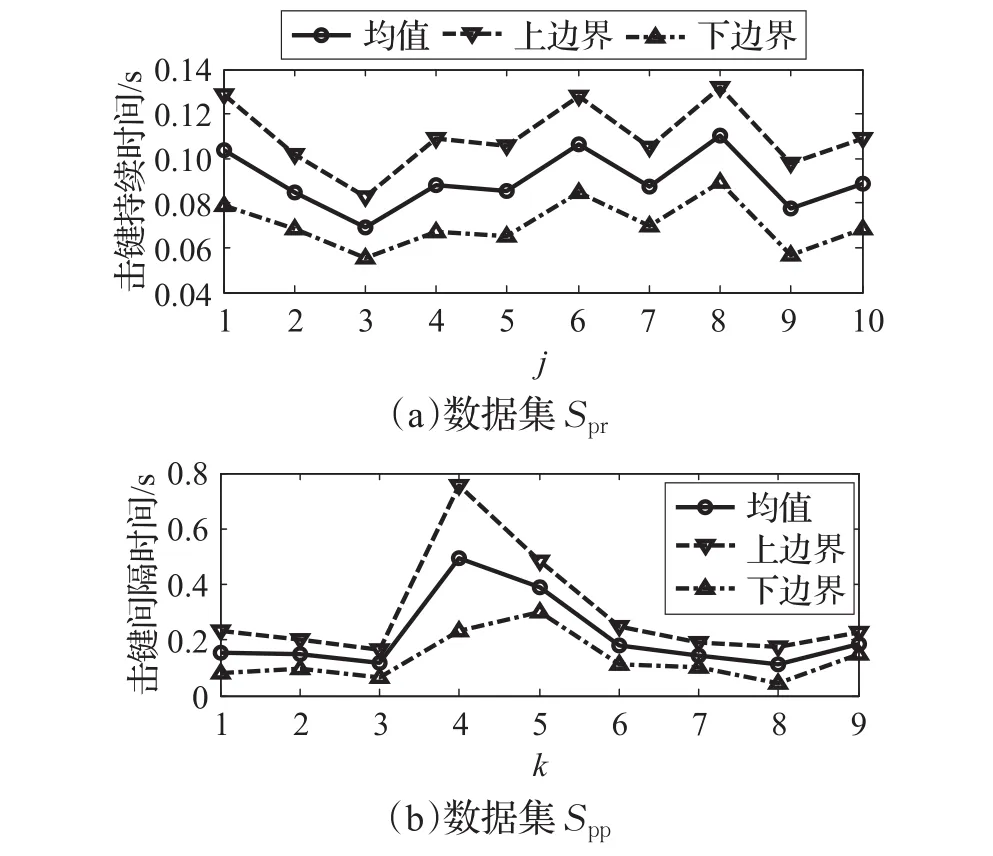
图2 击键特征曲线上/下边界
根据上述击键特征曲线边界的定义可知,上、下边界曲线将整个二维平面划分为内部区域和外部区域,如图3所示。图3中阴影区域称为数据集内部区域,其余的非阴影区域则统称为外部区域。
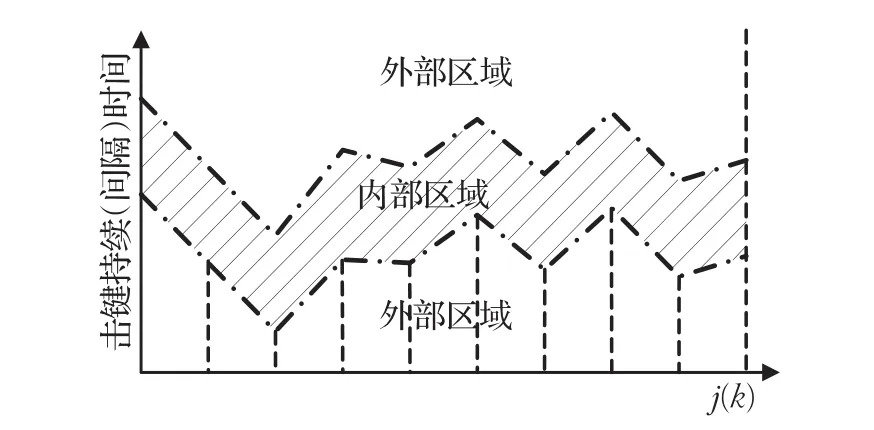
图3 击键数据集区域划分示意图
根据上述定义可知,如果一个样本是某个数据集的外部样本,在相应的外部区域内,这个样本的特征曲线必定会与其数据集的上边界或下边界曲线构成若干个封闭区域(如图4中的阴影区域所示)。所有封闭区域的总面积越大,表示样本与此数据集的差异越大,样本不属于此数据集的可能性越大。因此基于上述原理,本文提出一种新颖的特征曲线差异度的概念,其定义如下:
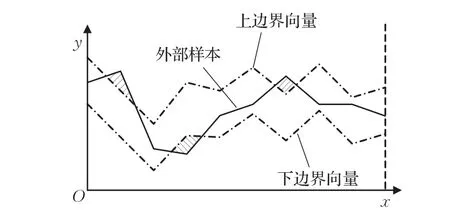
图4 击键特征曲线差异度物理含义示意图

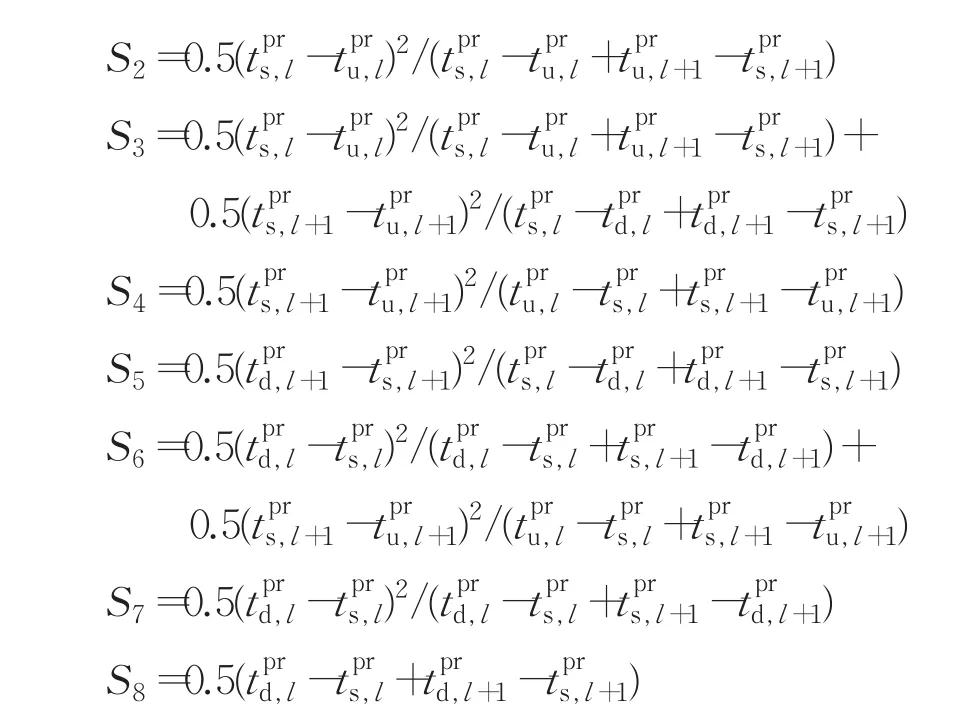
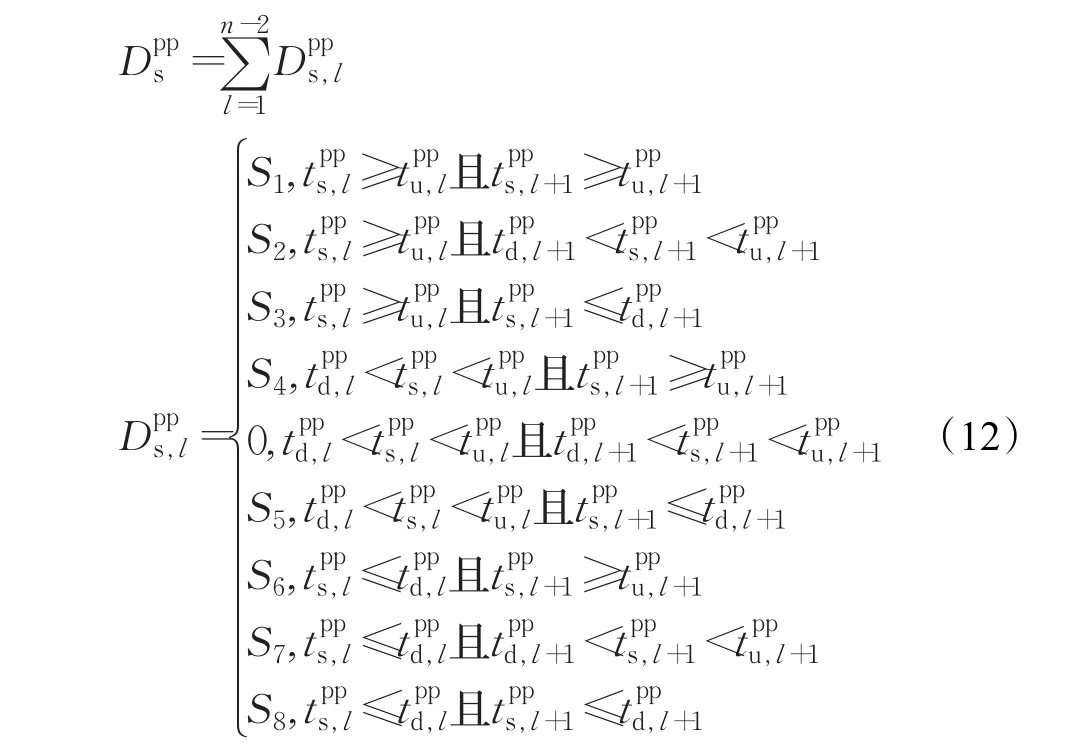
式中:

根据击键特征曲线差异度的定义可知,特征曲线差异度不仅与击键持续时间(j=1,2,…,n)和击键时间间隔相关,还与其任意两个相邻的时间特征值1,2,…,n-2)之间的变化率相关,主要包括变化方向和幅度。因此,与仅使用击键持续时间和击键时间间隔的传统击键认证算法相比,基于特征曲线差异度的用户身份认证识别算法性能更好。
3.3 算法描述
基于击键特征曲线差异度的用户身份认证算法步骤如下:
(1)数据采集
根据式(3)和式(4),设 Spr和 Spp为用户A的击键持续时间数据集和击键时间间隔数据集,数据集的样本个数为m,用户输入的密码长度为n。
(2)训练过程
步骤1根据式(5)和式(6)分别计算数据集Spr和Spp中元素的均值 μpr和 μpp。
步骤2根据式(7)和式(8)分别计算数据集Spr和Spp中元素的标准差σpr和σpp。
步骤3根据式(9)和式(10)分别计算数据集Spr和Spp中元素的特征曲线上、下边界和
步骤4根据式(11)和式(12)分别计算数据集Spr和Spp中每个元素的特征曲线差异度,并构成击键持续时间特征曲线差异度集合Qpr、击键时间间隔特征曲线差异度集合Qpp和总的击键特征曲线差异度集合

步骤5计算集合Qtotal中元素的均值μD和方差σD:

(3)测试过程
步骤1根据式(11)和式(12)分别计算测试样本为和的特征曲线差异度和。
步骤2计算测试样本总的特征曲线差异度Ds:

步骤3根据下式对测试样本进行判定:

式中,ξ2为可调阈值,取值范围为ξ2>0。
如果不等式(18)成立,认定此测试样本属于用户A;否则,认定此测试样本不属于用户A。
注2 ξ2是影响FRR和FAR的重要参数,ξ2取值越大,由式(18)可知,测试样本被判定为属于某用户的可能性越大,因此FRR值越低而FAR值越高。故通常需要根据算法性能指标要求与ξ1的值来选取合适的ξ2,尽可能使EER值最小。
4 实验与结果分析
4.1 实验数据
本文使用的数据来自于卡耐基梅隆大学Benchmark的数据集[9],采用已公开的第三方数据对各个算法进行比较会更客观,产生的结果也更具有可比性。
他们从校园里招募了51名志愿者,覆盖了学校里所有专业的学生。在记录击键信息时,所有的参与者都输入相同的密码,每一个志愿者要求输入400次密码(共分为8轮,每轮输入50遍,每轮之间的间隔至少一天)。密码选定为“.tie5Roanl”,该密码长度为10,且包含了大小写字母、数字和符号,是一个强度较高的密码。
数据集中共包含了51名用户对同一个密码序列(“.tie5Roanl”)的重复录入信息,即密码序列共10位,则包含19个击键特征信息,其中10个描述持续时间,9个描述击键时间间隔。
4.2 数据预处理
该数据集在采集过程中,每个用户的击键信息分8轮采集,每轮之间的间隔至少一天,可能导致所采集的用户击键信息稳定性较差,波动幅度较大。因此,本文采用统计学的方法对原始实验数据进行预处理。
步骤1根据式(5)~式(8),分别计算每个用户的击键数据集Spr、Spp中向量元素的均值 μpr、μpp和标准差σpr、σpp。
步骤2对Spr、Spp中的每个元素计算Δpr=如果(j为维度下标,j=1,2,…,n)或(k为维度下标,k=1,2,…,n-1),则将元素和从 Spr、Spp中删除。
步骤3递归上述步骤,直至Spr、Spp中的所有元素均满足且
经过实验,认证算法的识别效果相比不进行预处理时有较显著的改观。
4.3 实验设计
首先,在算法训练阶段,依次取每个用户采样数据集(预处理后)中前20%、40%、60%和80%的样本作为训练样本来建立该用户的模板。为便于实验结果分析,用变量TP表示上述用户的训练样本数量占总样本数量的百分比。
然后,分别取数据集中后80%、60%、40%和20%的样本作为测试样本,计算该用户的错误拒绝率FRR。
接下来,使用其他50个用户的全部采样样本(预处理后)作为攻击密码,计算该用户的错误接受率FAR。
上述过程会循环下去,直至51个用户的FRR和FAR全部计算出来。最后,取所有用户FRR和FAR的平均值作为身份认证算法的性能指标。
4.4 结果与分析
由于算法性能受阈值ξ1和ξ2的影响,首先实验分析阈值ξ1和ξ2对FRR和FAR的影响规律,为阈值ξ1和ξ2的设置提供参考依据。当ξ2≡1时,FRR和FAR随ξ1的变化曲线如图5(a)所示;当 ξ1≡1时,FRR和FAR随ξ2的变化曲线如图5(b)所示。由此可知,FRR随 ξ1和ξ2的增大而减小,FAR随ξ1和ξ2的增大而增大,应设置合适的阈值ξ1和ξ2使得EER达到最小值。

图5 阈值ξ1和ξ2对FRR和FAR的影响
为验证算法的性能,将本文提出的基于击键特征曲线差异度的用户身份认证算法与Manhattan距离算法[17]、Manhattan(scaled)算法[17]和统计学算法(Statistics)[3]、神经网络算法(Neural networks)[8]和机器学习算法(Machine learning)[9]进行对比。上述5种比对算法是目前在击键动力学中广泛应用且认证效果较好的方法。
实验得到了用户训练样本数量占总样本数量的比例(TP)分别为20%、40%、60%和80%情况下,各种算法的错误拒绝率(FRR)、错误接受率(FAR)和相等错误率(EER)。
通过分析表1~表4中的实验结果可知,在TP取值不同的情况下,本文提出的基于击键特征曲线差异度的认证算法的相等错误率(EER)分别为12.01%、7.88%、7.09%和5.81%,均显著优于其他5种比对算法,识别准确度高,对击键序列的认证效果更理想。

表1 TP为20%时算法性能指标

表2 TP为40%时算法性能指标
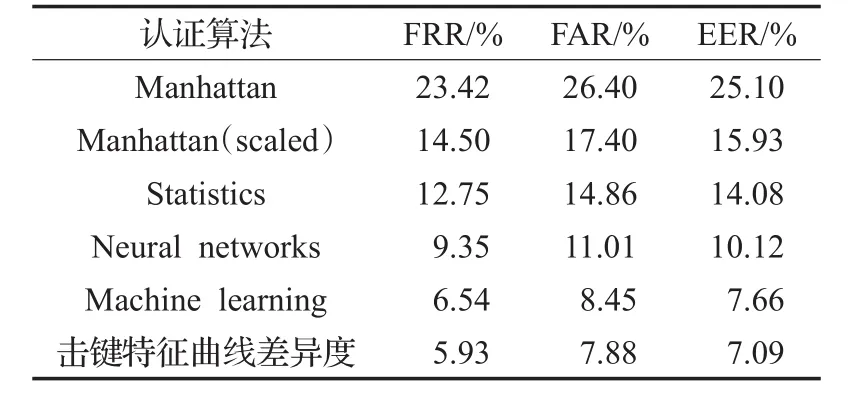
表3 TP为60%时算法性能指标
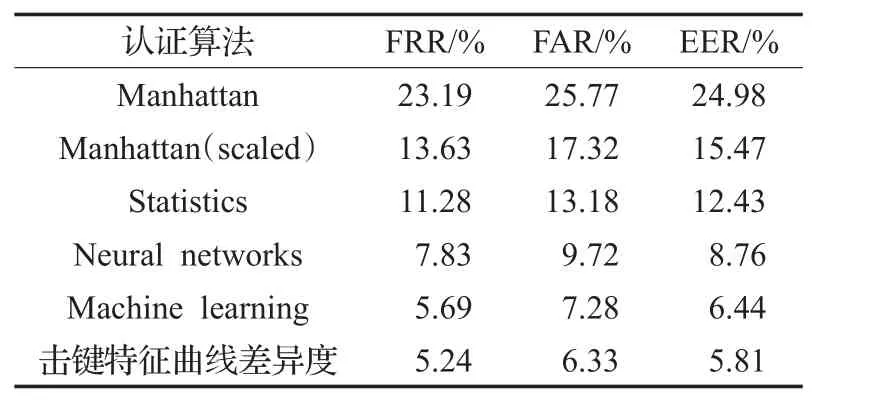
表4 TP为80%时算法性能指标
由图6可知,随着训练样本数量(TP)的增加,各算法的相等错误率(EER)均逐渐减小。但是,与其他5种算法相比,本文算法的EER随TP的收敛速度快。神经网络算法和机器学习算法在训练样本较小的情况下,性能与本文算法存在一定的差距,仅在训练样本足够多的情况下,性能指标才与本文算法接近。例如,在TP为20%时,本文算法的EER为12.01%,显著优于Manhattan算法的 29.32%、Manhattan(scaled)算法的 18.60%、Statistics算法的17.60%、神经网络算法的17.12%和机器学习算法的14.97%。这说明,即使在训练样本较少的情况下,本文算法依然能取得较好的认证效果。

图6 各算法的EER指标随TP的变化曲线
因此,上述实验结果表明,本文提出的采用击键特征曲线差异度的认证算法比目前应用的传统算法的识别准确度更高,性能更好。
5 结束语
本文提出了一种新颖的基于击键特征曲线差异度的用户身份认证方法。相对于传统的认证算法,本文算法不仅使用了常规的击键时间特征量,例如击键持续时间和击键时间间隔,而且引入了任意两个相邻时间特征值之间的变化率,并给出了击键特征曲线差异度的概念和相关的认证算法。通过实验对比,相比于传统算法,采用击键特征曲线差异度的认证算法的错误拒绝率(FRR)、错误接受率(FAR)和相等错误率(EER)更低,即使在训练样本较少的情况下,依然能取得较好的识别效果,在一定程度上反映出本文算法的有效性和优越性。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
数学小灵通(1-2年级)(2020年11期)2020-12-28
石油炼制与化工(2019年9期)2019-09-18
小学生学习指导(低年级)(2019年3期)2019-04-22
知识经济·中国直销(2018年8期)2018-08-23
科技与创新(2016年24期)2017-03-30
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
第二课堂(课外活动版)(2015年5期)2015-10-21
读写算·小学低年级(2014年4期)2014-07-24
