
基于用户聚类与Slope One填充的协同推荐算法
2018-11-17 02:50邓珍荣黄文明
计算机工程与应用 2018年22期
龚 敏,邓珍荣,黄文明
1.桂林电子科技大学 计算机科学与信息安全学院,广西 桂林 541004
2.桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004
1 引言
随着互联网上各式各样信息的爆炸式增长,用户经常需面对海量信息数据却无从下手,从而形成了“信息过载现象”。目前基于关键字的搜索引擎虽然能够被动地响应用户的搜索请求,但千篇一律的搜索结果已经无法满足用户个性化的需求,个性化推荐系统作为解决该现状的有效手段得到了深入的研究和发展,但个性化推荐的质量会受到它所采用的推荐算法[1]的影响。推荐算法中协同过滤算法(Collaborative-Filtering)已成为目前应用最广泛的推荐算法之一,根据具体处理方式不同,主要分为基于模型(Model-Based)和基于内存(Memory-Based)的协同过滤算法[2]。其中基于内存的协同过滤算法的最大优势在于它基于集体智慧的思想,通过对用户历史行为数据的挖据,可以找到用户或项目的相似用户集或项目集,依靠这些有共同兴趣的用户或者喜欢这个项目的用户也会喜欢跟他相似项目的理论对目标用户进行推荐,从而能够使得单凭内容难以分析的项目也能够推荐给用户。根据相似对象的不同,基于内存的协同过滤算法主要分为基于用户(User-Based)的协同过滤[3-4]和基于项目(Item-Based)的协同过滤[5-6]。虽然基于内存的协同过滤算法可解释性强,同时又能取得较为可观的推荐效果,但随着时代发展,用户数和项目数都在不断地增加,便带来了其他问题和挑战。其中由于用户对整个项目集的评价非常少,导致用户评分矩阵越来越稀疏,在此情况下,高维的稀疏数据会严重降低推荐的质量。除此之外,传统协同过滤算法必须扫描整个数据集,计算量大,因而导致可扩展性差[7]。
基于上述问题,许多研究人员从不同角度引入基于模型的算法到传统的基于内存协同过滤算法中,例如聚类(Clustering)分析模型[8-9]、主成分分析(Principal Component Analysis,PCA)模型[10]、奇异值分解(Singular Value Decomposition,SVD)模型[11]等引入到传统的基于内存的协同过滤推荐算法中,通过降维,可明显缩小目标对象搜索最近邻居的范围。由于维度的下降,虽然数据量没有发生实质性的改变,但在每个低维矩阵中数据稀疏性得到了缓解,使得推荐的效果得到明显提升。除了上述提到的算法外,基于模型的算法还包括朴素贝叶斯模型(Navie Bayesian Model)[12]、基于概率模型的隐含主题分析(Probabilistic Latent Semantic Analysis,PLSA)[13]、图模型[14]等。
为了使推荐系统既有一定的可扩展性,又有较高的准确率,本文提出了基于用户聚类与Slope One填充的协同推荐算法。首先提取用户特征属性,并以此构造用户属性矩阵,运用基于最小生成树的K-means算法对整个用户集进行聚类。然后在生成的各用户类中利用Slope One算法对评分缺失项进行填充,在此基础上对聚类中的用户分别进行基于用户和基于项目的协同过滤推荐,最终有效融合两次推荐的结果。
2 基于最小生成树的K-means聚类算法
聚类算法中K-means算法是一种基于划分、实现简单、收敛速度快的分析算法[15],正是因为它的这些优点,使其在实际应用中有很大的优势,成为当前使用最为广泛的聚类算法之一。但传统的K-means聚类算法有一个明显的缺点,选取初始聚类中心是随机的,一旦初始聚类中心选择不合理,并以此迭代地改变中心直至达到聚类准则收敛时,易导致算法失去原有的特点,无法得出最优的结果。为了避免选取初始聚类的随机性带来的不稳定聚类结果,本文采用一种基于最小生成树的K-means聚类算法,将用户属性相似度作为两两用户顶点边的权值,通过使用Prim最小生成树算法得到最小生成树,并通过最小生成树找到合理的初始聚类中心,然后进行K-means算法迭代,最终形成K个有效的用户聚类。
2.1 用户属性相似度
用户属性相似度是最小生成树模型构造的重要依据,也是该聚类算法的第一步。用户属性相似度反映的是两个用户属性之间的距离,值越大则两个用户属性距离越远,反之则两个用户属性距离越近。假设每个用户是一个V维向量,而用户向量的维度便代表了用户属性特征,则用户属性矩阵为 A=(aim)n×v,其中aim表示用户i的第m个属性特征。本算法采用的用户相似度定义如式(1)所示,其中Us(i,j)表示用户i与用户 j之间的用户属性相似度:

计算各个用户之间的属性相似度,将其作为由用户集构成的带权值的以用户作为顶点的无向图中的顶点边的权值,依据该边权值构造最小生成树模型。
2.2 最小生成树K-means算法
由式(1)得到了用户的属性相似度,并以此构造了以用户作为顶点,以用户属性相似度作为顶点边的权值的无向赋权图。而最小生成树K-means算法就是建立在这个无向赋权图上,首先利用Prim算法找到最小生成树,再删除最小生成树中权值最大的K-1条边,这样将得到K个互不连通的连通子图,如图1所示。

图1 K个连通子图生成图
然后初始聚类中心便是这K个连通子图中所有对象的中心值。最后K-means算法将以上述得到的初始聚类中心开始进行用户聚类,而不是传统的随机选择初始聚类中心。本文采用的聚类算法具体如下:
算法1基于最小生成树的K-means聚类算法
输入:用户属性矩阵A,目标用户U,聚类个数K。
输出:目标用户U所在的用户簇。
(1)根据用户属性矩阵A,利用Prim最小生成树算法,求出最小生成树,并将权值按照从小到大的顺序排列。
(2)根据权值由小到大排列形成数据集P={u1,u2,…,un},找到距离最近的两个ui和uj,并求出它们之间的中心点Mij。
(3)删除ui和uj,并将 Mij放入余下数据集中形成P={u1,u2,…,Mij,…,un},集合P中元素个数若大于K则回到步骤(2)。
(4)此时集合P中的K个元素即为初始聚类中心。计算用户集中每个用户距离K个质心的距离,把用户加入距离最近的质心所在的簇中。
(5)每个用户都已经属于其中的一个簇,然后根据每个簇中包含的数据向量集合,重新计算得到新的质心。
(6)如果新计算的质心和原来的质心之间的距离达到设置的阈值,算法终止;否则迭代步骤(4)~(6)。
3 Slope One算法填充稀疏矩阵
Slope One算法最早是由丹尼尔教授于2005年提出的推荐算法,该算法以线性回归模型作为预测模型,根据项目评分差值和用户的历史评分记录来近似估计该用户对目标项目的评分[16]。Slope One算法思想简单,实现相对容易,时间和空间复杂度都较小,一旦面对较为稀疏的用户-项目评分矩阵,Slope One算法可利用的项目评分较少,会导致评分预测准确率直线下降,推荐效果随之降低。正因为存在上述问题,本文利用Slope One算法填充2.2节中基于用户聚类后的K个用户-项目评分矩阵作为最终填充矩阵。
Slope One算法的本质思想其实是形式简单的回归表达式w=y+b,其中w为需要预测的用户u对项目i的评分,y为用户u对项目i以外的项目评分,b为项目i相对于项目 j评分的平均偏差,表示为Devi,j,如式(2)所示。其中Si,j(U)为对项目i和项目 j均有评分的用户集合。

因此,通过公式Devi,j+Ru,j可计算出用户u对itemi的预测评分,从而得到预测均值计算公式如下:

其中,Ri表示所有用户已经给予评分满足条件(i≠j且Si,j非空)的item集合。
同时本文在计算评分时是在目标用户所在聚类中进行的。例如,表1中假设U1、U2、U3属于同一聚类,现需计算U2对I1的评分并填充。首先计算项目I1与项目I2的平均偏差((1-2)+(4-5))/2=-1,然后据此可得用户U2对项目I1的评分是3-1=2;接着计算项目I1与项目I3的平均偏差(1-3)/1=-2,并由此计算出用户U2对项目I1的评分是3-2=1;最后预测用户U2对项目I1的评分是(2+1)/2=1.5。利用Slope One算法对初始各用户聚类的用户-评分矩阵进行处理,矩阵中的大部分空缺值就会被填充,从而有效降低了矩阵的稀疏程度。

表1 项目评分矩阵
4 基于用户和项目的混合协同过滤推荐与时间复杂度
协同过滤算法是1992年Goldberg等学者提出的,该算法是以目标对象相似的用户或项目为基础进行推荐。为了提高推荐算法的精度,本文提出一种线性混合基于用户和基于项目的协同过滤推荐算法,在每个用户类下,利用填充后的数据集进行有效的推荐。本文的算法流程可以用图2来表示。

图2 本文算法流程
混合用户和项目的协同过滤推荐具体方法是先用皮尔森相关系数[17],如式(4)所示,定义用户相似度,并通过最近邻搜索得到目标用户的最近邻居集合。其中s(u,v)表示用户u与用户v之间的用户相似度,分别表示用户u、v在所有项目上的评分均值。

通过计算用户的相似度,进行最近邻搜索得到目标用户u的最近邻居集合N(u),则用户u对未评分项目i的预测得分计算公式如式(5)所示:
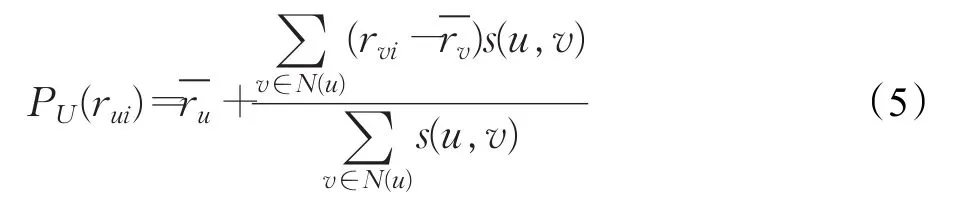
再由余弦相似度如式(6)所示,定义项目相似度,搜索目标项目最近邻。其中s(i,j)表示项目i、j之间余弦相似度[11],同时对项目i、j有过评分的用户集合则由U(ij)表示。

通过计算项目之间的相似度,根据Top-N得到预测项目i的最近邻居集合N(i),则用户u对未评分项目i的预测得分如式(7)所示分别表示项目i、j在所有用户上的评分均值。

为了有效融合用户和项目协同过滤推荐所得的预测评分,本文引入不确定近邻因子的线性融合框架[18],利用一个可调整因子λ将两者的预测结果融合,产生最终的预测评分。λ的计算公式如式(8)所示,其中m′表示基于用户的协同过滤算法中产生的最近邻个数,n'表示基于项目的协同过滤算法中产生的最近邻个数。

最终融合后的模型如式(9)所示,利用得到的预测评分,生成Top-N个推荐结果。

关于模型的时间复杂度,虽然模型需要分多步骤完成,但对于用户聚类和对聚类结果进行Slope One填充这两部分,都可以进行离线并行化计算。并且由于已经离线并行化得到聚类且填充后的K个矩阵,人们在查找目标用户或项目的邻居时,只需在目标元素对应的小矩阵中计算簇中元素与目标元素的相似度,这就避免了传统协同过滤推荐算法中对全量评分矩阵进行相似度计算而使得时间复杂度过大的问题,节省了时间和空间,提高了推荐的实时性。
5 实验结果及分析
5.1 数据集
实验数据采用的是美国学者公开的MovieLens数据集,具体实验数据相关信息如表2所示。其中用户特征信息,本文选取了其中三个用户属性作为用户特征聚类的依据,并根据专家意见将每个属性分类表示成数值形式[19],age(1~5)、gender(0~1)、occupation(1~8)。本文随机选取实验评分数据中的80%用作训练集,20%用作测试集。
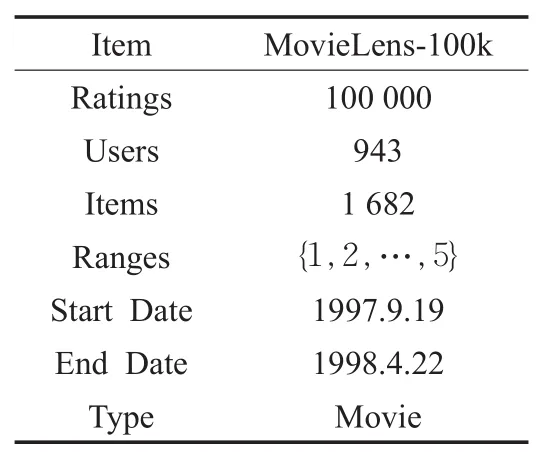
表2 实验数据相关信息
5.2 评价指标
本文主要采用平均绝对偏差(Mean Absolute Error,MAE)、均方误差(Root Mean Square Error,RMSE)来度量预测评分的偏差。MAE和RMSE是目前使用比较广泛、业界认可度较高的评估推荐系统质量的评价指标,这也正是本文选取这两项来测试算法的有效性的原因。MAE和RMSE均为误差值,误差值越小说明算法的预测精度越高,具体的计算方式为式(9)和式(10),其中N表示测试集的大小。

5.3 算法结果对比及分析
为了验证本文算法的有效性,分别对基于用户的协同过滤(UBCF)[20],基于项目的协同过滤(IBCF)[21],混合用户和项目的协同过滤(UICF)[22],先用户特征聚类再混合用户和项目的协同过滤(CUICF)[23],先填充稀疏矩阵再混合用户和项目的协同过滤(FUICF)[24],以及本文的先用户特征聚类再填充稀疏矩阵最后混合用户和项目的协同过滤(CFUICF)进行实验。经过多次实验发现,用户数据集上聚成7个簇时,算法整体精度和扩展性得到一个较好的折中,因此本文实验聚类簇设定为7个。这六种算法都采用五折交叉验证在MovieLens数据集上进行100次实验,统计结果并取平均RMSE和MAE,结果如图3和图4所示。

图3 RMSE对比图
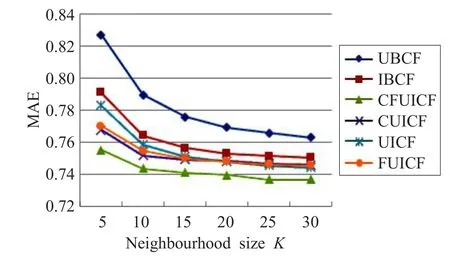
图4 MAE对比图
由图可知,本文提出的推荐算法比其他五种推荐算法确实在RMSE和MAE上有较大的提高,说明此推荐算法可以提高推荐系统的推荐质量,验证了算法的有效性。
6 结束语
本文提出了基于用户聚类与Slope One填充的协同过滤算法。首先基于用户特征进行聚类,其次填充稀疏矩阵,最后线性融合两个基于内存的协同过滤算法。本文算法弥补了聚类算法和协同过滤算法各自的不足。聚类算法的融入使得协同过滤算法在可扩展性上得到提升,而在聚类下填充稀疏矩阵,又可以依靠聚类中用户的隐性相似提高填充准确率,同时缓解数据稀疏性,提高了用户和项目的近邻量,最终效果在推荐质量上得以体现。在协同过滤算法中又结合两种基于内存的协同过滤方法,两种方法发挥了各自推荐的优势,使得推荐质量有了明显的提高。针对本文算法中的不足之处,下一步的工作是对填充算法的优化和时间因子对协同过滤推荐的影响展开研究。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
新班主任(2022年4期)2022-04-27
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
科学大众(2020年23期)2021-01-18
铁道通信信号(2019年6期)2019-10-08
汽车观察(2019年2期)2019-03-15
江苏通信(2018年4期)2018-12-04
自动化学报(2017年7期)2017-04-18
雷达学报(2017年6期)2017-03-26
中国卫生(2016年5期)2016-11-12
