
应用预测链接的分布式社会网络隐私保护方法
2018-11-17 02:50张晓琳于芳名何晓玉袁昊晨
计算机工程与应用 2018年22期
张晓琳,于芳名,何晓玉,袁昊晨
内蒙古科技大学 信息工程学院,内蒙古 包头 014010
1 引言
针对动态社会网络(Dynamic Social Network,DSN)隐私保护问题,提出了多种隐私保护方法。陈伟鹤等[1]提出基于动态社会网络的敏感边的隐私保护。谷勇浩等[2]提出基于聚类的动态社交网络隐私保护方法。Zhang等[3]提出基于k-邻居同构的动态社会网络隐私保护方法。对于动态社会网络的研究有助于揭示网络性质的起源,并能够对其发展进行预测。预测链接在DSN中的基本思想是:通过当前社会网络的拓扑结构预测未来社会网络中真实存在的边,如果将预测边作为伪边匿名当前图数据,则在匿名下一时刻的社会网络图数据时将会减小匿名代价。Bhagat等[4]比较多种预测链接方法对于隐私保护强度的影响,有效保证结点和边的隐私信息。Liu等[5]提出防止链接推理攻击的隐私保护方法,保护社交网络中边的隐私信息。王路宁[6]提出的隐私保护方法通过加入预测链接方法,较大程度地提升图数据的可用性。但以上算法运行在单机环境下,效率不高,实现社会网络隐私的并行化已成为未来趋势[7]。Zakerzadeh等[8]基于Hadoop框架加速处理图数据匿名的过程。Mehmood等[9]全面概述大数据中的隐私保护机制,利用分布式系统提高数据处理效率。但是由于传统MapReduce模型在多次迭代处理时的数据反复迁移和作业连续调度等问题,数据处理效率较低。BSP(Bulk Synchronous Parallel)模型是云计算环境下处理大规模图数据的典型计算模型,适合大规模图计算过程的并行处理[10]。Google的Pregel系统[11]是基于BSP模型的最成熟的图处理系统,Pregel系统带动了一系列Pregel-like系统[12]发展,如Apache的Hama、Yahoo的Giraph和Spark的GraphX[13-14]等。由于单机工作站环境下,动态社会网络隐私保护方法处理大规模图数据存在很大的局限性,同时为了提高数据可用性,本文提出了D-DSNBLP(Distributed-Dynamic Social Network Based on Link Prediction)。该方法利用DP动态规划算法[15]将结点分成独立的组,每个组k个结点;其次利用预测链接并行构建候选结点集合,使得每个组满足k-度匿名;最后构建互斥边集合添加边,完成图的匿名操作。为便于研究,只考虑不带标签的无向图。
2 相关知识
给定动态社会网络 Gt和 Gt+1,如图1(a)和图1(c)。攻击者知道结点v15的度由d15=1变为d15=2,则通过结点度的变化,能够唯一识别结点v15(度攻击)。传统的动态度匿名方法通过考虑当前图的拓扑结构,然后修改图中结点之间的边,使得每个图都达到k-度匿名,但这种方式选择的伪边忽略了动态图之间的联系。为了解决此类问题,提出预测链接的方式选择伪边,即通过当前图的拓扑结构预测下一个图的连接关系,将此连接关系作为修改图中结点之间的伪边。
定义1(动态社会网络图)动态社会网络图G=(Vt,Et)。Vt={v1,v2,…,vn}代表t时刻社会网络图的结点,Et⊆Vt×Vt代表t时刻社会网络图的边。Γ={G1,G2,…,Gt}表示在T=1,2,…,t时刻的社会网络图集合,表示在t时刻的社会网络匿名图集合。
定义2(k-度匿名序列)动态社会网络图G=(Vt,Et)中的结点v∈V按照度降序所构成的序列称为非递增度序列DS′。若DS′中任意一个结点的度都有k-1个结点和它有相同的度,则称这个度序列为匿名度序列,标记为DS*。满足匿名度序列的图称为k-度匿名社会网络图,表示为G*,令dv表示结点v的度。


Nr(v)表示结点v在第r步到达的所有结点集合,简称r邻居,文中也表示为r-邻居。例如图1(a)中,即v15的两邻居是v11、v13。
定义5(预测链接)给定图Gi和Gj,存在e1=e(v1,v2)∉Gi,e1=e(v1,v2)∈Gj,且 i<j。在 i时刻,利用图Gi的某些特性预测出e1的过程,称为预测链接。
在社会网络图中,共同邻居信息是预测链接的衡量指标之一,但是单独以共同邻居作为预测链接的指标,忽略了共同邻居之间的关系,因此使用路径信息进一步获得结点之间的链接强度。即将共同邻居数量和路径信息同时作为达到匿名图的度量标准UMC(Utility Metric Criteration):

UMC值越大说明两个结点链接关系越强,在下一时刻存在链接的可能性也越大。
如果发布的图G*的度序列满足k-度匿名序列,则可以防止度攻击。
定义6((k,dtarget)-度匿名)由DS′划分成若干个独立的组C1,C2,…,Ci,…,Cm,每个组至少有k个结点。v,u∈Ci,∀dv≥du,1<i<m ,则 dmax(Ci)=dv。在 t时刻,为了使组中的结点有同样的度,结点需要添加Attr个伪边或者结点属性值,即 Attr(vi)=dmax(Cj)-dvi。vi∈Cj,i=1,2,…,|Cj|,j=1,2,…,m 。
定义7(组间匿名)给定两个组Cm、Cn,Cost(Cm,Cn)=dmax=dv。结点v与组C的匿名代价可以看作是只有一个结点的组和C的代价。
3 D-DSNBLP隐私保护方法
D-DSNBLP隐私保护方法的主要思想:首先将社会网络中的结点通过动态划分组得到每个结点的Attr(vi),Attr(vi)≠0的结点及对应的Attr(vi)存放在序列S中;其次S中的结点并行选择候选结点集合Cand Set(vi);最后构建互斥边集合,根据互斥边集合更新序列S。
在对社会网络图采用D-DSNBLP方法之前,需要格式化数据,使数据的格式满足实验需求。
算法1 D-DSNBLP隐私保护方法
输入:社会网络图Γ={G1,G2,…,Gt},匿名参数k。
1.for every graph
2. Stemp←Attr(vi)≠0;DS′=degree(vi)//初始化集合
3. if(the first graph)
4.splitGroup(DS′,k)
5. anonmization(group,S)
6.else
7. Foreach g in group
8. If g.size<k then g union other group by cost and get Attr(vi)
9. If exist new node union other group by cost and get Attr(vi)
10. anonmization(group,S)
11.def splitGroup(array(ID,degree),k){
12. costall=根据k-target度匿名计算所有结点在一个组时的匿名代价,同时给定组编号和结点的Attr
13. if结点个数小于2k
14.返回costall
15.else
16. for i←k to结点个数-k
17. costi=计算以i为分界点的代价(此处迭代调用splitPoint)
18. if costi>costall:return costi else costall
19. }
20.def anonmization(group,S)
21.allEdge=null
23.r=2//表示 N2(v)
24.everyNodeCandSet=call 算法2(r)
25.everyNodeCandEdge+=call 算法3(everyNodeCand-Set).EdgeSet
26.S=update by everyNodeCandEdge
27.allEdge+=everyNodeCandEdge
28.r=r+1
29.G*=G.Add(allEdge)
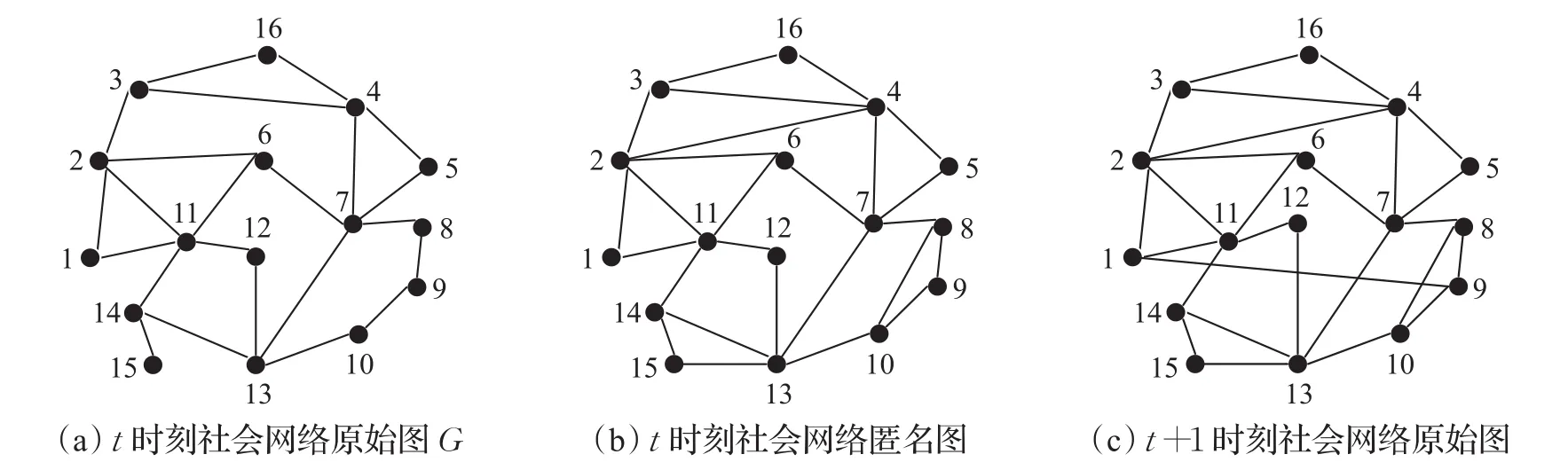
图1 社会网络图
动态图的第一个图需要分组,后续的图需要按照第一个图的分组进行匿名,即仅需要一次分组。算法第3~5行根据DP动态算法划分组,求得每个结点达到匿名需要添加的边数并追加到集合S,然后匿名;第6~10行表示新加入的结点根据组间匿名代价加入Cost最小的组求得Attr(v);若某组结点不满k个,则根据组间匿名代价合并,求得 Attr(v);第11~19行说明了分组算法[15]。第20~29行表示因为互不为1邻居的结点才能添加边,所以r≥2,由“小世界理论”和“六度分割原理”定义r小于等于6。r=2,当N2(v)中结点不能够满足Attr(v)个结点时,将N2(v)的范围变为N3(v),以此类推,直到r=6时停止。如果r=6时仍然无法找到候选结点,则在图G中随机寻找结点作为候选结点,使得候选结点总数能够达到Attr(v)个。第24~25行表示寻找候选结点结合,计算并筛选候选边CandEdge;调用算法3得到互斥边集合并存储,第26行根据互斥边集合更新S。第29行向图G中添加所有互斥边,匿名结束。
例1图1(a)为t时刻原始图,以k=5为例,度序列如表1,通过DP动态算法分组为C1={v7,v11,v13,v4,v2},C2={v3,v14,v6,v8,v10},C3={v9,v1,v15,v16,v5}。假设加入伪边(v2,v4),(v10,v8),(v13,v15)得到匿名图1(b),那么t+1时刻,如图1(c),由于三条伪边真实存在,则由于C1、C2分组内结点没有发生变化,故不需要匿名,匿名代价为0。C3组内dv1=dv9=3,则利用(k,dtarget)匿名得到Attr(v15)=Attr(v12)=Attr(v16)=Attr(v5)=1。结点得到Attr(vi)后,选择候选结点集合Cand Set(v),S={(v15,1),(v12,1),(v16,1),(v5,1)}。

表1 度序列及结点属性
3.1 并行构建候选结点集合
Pregel是一个消息迭代更新模型,能够高效地分布式处理大规模社会网络图。一个Pregel任务可分为多个超步(supersteps)。每个superstep分为vprog、sendMsg、mergeMsg三个阶段。vprog阶段结点在本地处理接收到的消息;sendMsg阶段结点将更新后的消息发送给1-邻居;mergeMsg阶段结点合并接收到的消息。当全部结点没有消息更新时或者达到最大的迭代次数时,Pregel操作停止迭代并返回结果。每个超级步并行发送消息。若结点更新消息则将结点状态置为Active,否则置为InActive状态。
结点v的候选结点集合Cand Set(v)是将UMC(v,u)值最大的Attr(v)个结点u∈Nr(v)加入v的候选结点集合Cand Set(v)。因为u和v之间所有的路径信息Path包含了源结点u和目标结点v的1-邻居,所以UMC的计算只需寻找该结点Pathr+1再比较得出候选结点集合Cand Set(v)。以下为并行寻找Pathr+1的过程(以r=2为例):
(1)superstep=0时,每个结点状态设置为Active状态,处于Active状态的结点将自己的信息Info发送给邻居结点。
(2)当superstep≠0时,接收到消息的结点判断消息队列中的每条消息的生命值是否为0,是则停止发送此条消息给邻居,结点置为InActive状态,否则将当前结点的Vertex ID加入路径,生命值减1,继续传递消息,重复执行(2),直到生命值为0或者没有结点更新消息时停止迭代。Info信息为(VertexID,lifeValue,Path(VertexID))。Path是用来存储长度在r+1以内的每一条路径的数据结构,Path初始值为结点本身的VertexID值,初始lifeValue=3(因为查找3步内的所有路径信息)。
算法2构建候选结点集合
输入:带结点属性Attr(v)的原始图G。
输出:每个结点v及其对应的Cand Set(v)。
1.Gn2Pc3=Pregel()
2.{
Initial graph G,Max iterator MaxValue
Call updateMsg()
Call sendMsgToNeibor()
Call mergeMsg()
}
3.updateMsg{
4. if(superstep=0)then
5. send its Info to Neiborhood
6.if(superstep!=0)then
7. if(Info.lifeValue!=0)then
8. add current VertexId to Path
9. lifeValue-1
10. send its Info to Neiborhood
11.}
12.sendMsgToNeibor{
13. send Info to Neiborhood which not contains source VertexId
14.}
15.mergeMsg{
16.mergeallInfo
17.}
18.computeUMCforeveryNodebyGn2Pc3
算法2第1~2行是Pregel算法的调用。调用过程初始化运行时的图、最大迭代次数和消息传递方向,调用消息更新模型、消息发送模型和消息合并模型。第3~17行是第1行调用的三个方法。第3~11行的方法updateMsg是结点处理接收到的消息的方法,若superstep=0,表示结点目前只拥有初始值,直接发送信息即可;如果superstep不等于0,表示结点收到了消息,需要将自己的VertexID加入到每个路径中,lifeValue减1,继续发送信息,直到所有结点信息的生命值为0。第12~14行sendMsgToNeibor的方法是将多次包含源结点信息去除,再发送给邻居,避免环路发送信息。第15~17行是每个结点合并收到的所有信息,处理后发送信息给updateMsg方法更新结点信息。第18行,图Gn2Pc3中每个结点均携带路径信息,根据路径信息和邻居信息计算两个结点UMC值,进而选择候选结点集合。
以图1(a)中结点v16获得的路径Path(v1,v2,v3,v16)为例进行分析。
(1)superstep=0时,如图2(a),结点 v1初始化消息Info((v1,3,Path(v1))并发送给邻居。
(2)superstep=1时,如图2(b),结点 v2接收消息后合并,加入自己的VertexID且生命值减1,处理后得消息Info(v1,2,Path(v1,v2)),最后自身置为Active状态并发送消息。
(3)superstep=2时,如图2(c),结点 v3接收消息后合并,加入自己的VertexID且生命值减1,处理后得信息Info(v1,1,Path(v1,v2,v3)),自身置为Active状态并发送消息。
(4)superstep=3时,结点v16接收到消息、合并,生命值减1为0,因此自身置为InActive状态,Info(v1,0,Path(v1,v2,v3,v16)),停止迭代。

图2 结点接收、发送信息

3.2 互斥边集合
候选边集合Cand Edge按照UMC降序排列,依次加入集合EdgeSet,EdgeSet是所有可以同时添加的边集合。在EdgeSet集合中的边需要满足以下条件:结点v的ID在集合EdgeSet中出现的次数小于等于Attr(v)。构造互斥边集合后,并行添加边时就不会出现边添加异常。
算法3构建互斥边集合
输入:所有结点的候选边Cand Edge(按照UMC值降序排列)。
输出:可添加的边集合EdgeSet。
1.EdgeSet←Φ
2.Foreach edge e in CandEdge
3.If count(e.dstid)<Attr(e.dstid)and count(e.srcid)<Attr(e.srcid) then EdgeSet← e
例1中,候选边Cand Edge={(v16,v5),(v12,v15)},此时两条边均满足条件,则EdgeSet{(v16,v5),(v12,v15)}。此时S中的Attr均为0,直接删除即可,S为空,则t+1时刻匿名图如图3所示。

图3 t+1时刻社会网络匿名图
4 实验结果与分析
本实验使用Pregel-like系统模型Spark-1.3.1,使用12台Dell服务器构建成Spark集群,硬件配置为CPU 1.8 GHz,RAM 16 GB。使用Hadoop 2.5.2作为存储系统,JDK1.7.0_65。实验使用的数据是真实的DBLP论文数据(http://dblp.dagstuhl.de/xml),2015年3月至7月的数据如表2所示。使用此数据集的原因一方面是因为数据量足够大,另一方面是因为其属于真实的DSN,并且可随意拆分成多个规模不同的数据集。为满足实验需求,对原始数据集做了以下操作:将数据集A随机等分为4份,然后按比例1∶2∶3∶4重新将数据整合,整合后的4个数据集作为实验数据。处理后的数据集属性如表3所示。本文选择简单且易于实现的AMBOGP[1]方法作为基准方法,用于测试匿名算法在动态匿名时图的整体改变量以及图结构的保持程度。

表2 数据集
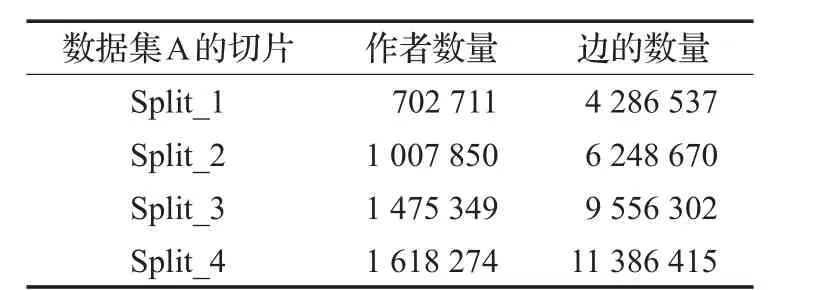
表3 数据切片
4.1 处理时间分析
D-DSNBLP隐私保护方法通过修改结点的链接操作达到k-度匿名,保证图结构信息的同时,提高处理大规模社会网络数据集的效率。对表2的四种数据集执行D-DSNBLP方法。由图4可知在处理小数据集(Split_1,Split_2)时,D-DSNBLP方法在两个数据集上的执行时间相近,随着数据量的增加(Split_3,Split_4),D-DSNBLP方法执行时间相差无几,说明Pregel-like模型更适合大数据的迭代并行操作。从并行处理的角度,资源越多,处理速度越快,由于worker是集群资源的贡献结点,由图5可知,Spark集群在处理任务时,将任务分发到不同的worker上,运行时间随着worker的增大而减小。当worker数量增加时,并行处理的速度也会有所提升。无限地提升worker的数量并不一定能够加快算法执行速度,原因可能是由于worker的数量增多导致worker之间的通信量过大,此时计算性能的提升被网络开销的代价所抵消。

图4 处理效率分析图

图5 D-DSNBLP方法中worker对运行效率的影响
4.2 数据可用性分析
D-DSNBLP隐私保护方法是基于预测链接和添加伪边进行k-度匿名方法,很好地保护了动态图的结构。通过测试添加伪边前后动态图结构变化情况来分析数据可用性,主要衡量边的变化和平均聚集系数,并说明图结构的变化程度。
图数据可用性与图结构的变化程度呈反相关的趋势,图结构变化越大,则图数据的可用性越低,反之则越高。图结构的变化C是指匿名图G*中边的数量相对于原始图的改变量,C=|E(G*)-E(G)|。如图6所示,将传统方法修改的边的数量与D-DSNBLP方法修改的边的数量进行比较,假定k=5,随着t时刻动态图的发布,原始算法对于图的修改量增加迅速,而D-DSNBLP因为在添加边的时候选择下一个发布图中可能存在的链接关系,所以图的修改量增加较为缓慢,图数据的可用性提高。对于数据集A,由图7可知,AMBOGP对于图的修改量随着k值的增加不断增大,而D-DSNBLP对于图的修改量相对较小。这是由于动态划分组可以最小化图的修改量,使得D-DSNBLP方法更好地保证图数据的可用性。

图6 图修改量随着t时刻的变化

图7 图修改量随着k值的变化
针对动态社会网络的不断变化,评估其匿名图与原始图的拓扑结构的改变,若改变较小,说明其结构保持较好,数据可用性较高。图的拓扑结构有平均聚集系数、平均最短路径、接近中心性等,限于篇幅,分析平均聚集系数在动态图匿名前后的改变。平均聚集系数用来度量图结构的聚集程度。D-DSNBLP方法中边的修改会导致图的聚集系数的改变。图8分析在不同时刻预测边对平均聚集系数(Average Clustering Coefficient,ACC)的影响。预测链接技术通过减少未来图中边的修改量来提高图数据的可用性。随着动态图的发布,原始算法添加的边的数量呈上升趋势,这是由于边的添加使得图中三角形的个数增多,从而平均聚集系数增大。与原始算法相比,D-DSNBLP隐私保护方法对原始图的聚集系数保持较好,数据可用性较高。

图8 不同时刻聚集系数的变化
由于预测精度的高低直接影响图匿名添加的伪边质量高低,图9着重分析了预测边在未来图的匿名过程中,预测的精确度对动态图匿名的影响。相比t时刻,t+1时刻添加的边为E(Gt+1)-E(Gt),在t时刻加入的

即t时刻匿名图添加的伪边与t+1时刻网络中真实添加的边的交集除以t+1时刻真实添加的边。当预测的准确度提高时,匿名代价随之降低,图结构受到的影响较小。而选择添加边的衡量指标由UMC值来决定,因此accurate与UMC值中的a值关系紧密。在a=0.5时,预测的值达到最大,这是因为在关系网中,结点间的相似度与共同邻居个数和他们之间的路径数量均有很大关系。在a=0.9,a=1.0时,预测精准度不高。这说明单独以共同邻居个数作为衡量指标过于片面。在a=0.3,a=0.4时,预测精度更接近最大值,是因为路径个数信息比共同邻居信息更能反映结点之间关系的链接强度。伪边是,预测精确度为:

图9 a值对UMC值的影响
5 结束语
随着互联网技术的发展,社会网络数据呈现出数据规模大,数据多样性等特点,以至于在单机工作站环境下处理大规模图数据时出现数据可用性差和处理效率低的问题。因此,实现社会网络隐私保护技术的并行化计算已成为未来趋势。针对社会网络中的结点隐私保护问题,提出了云环境下利用预测链接的社会网络隐私保护方法D-DSNBLP。该方法通过Pregel-like模型,利用基本的集合操作和消息迭代更新模型,完成了在大规模社会网络图数据中动态划分组,构建候选结点集合,构建互斥边集合等操作。实验结果表明,D-DSNBLP方法提高了处理大规模图数据的速度,保证了隐私保护效果和数据发布的可用性。
猜你喜欢
环球人物(2022年4期)2022-02-22
电子制作(2022年1期)2022-01-28
小资CHIC!ELEGANCE(2021年32期)2021-09-18
电子制作(2021年14期)2021-08-21
科学与信息化(2021年8期)2021-03-31
活力(2019年21期)2019-04-01
快乐作文·中年级(2015年3期)2015-03-26
小学阅读指南·高年级版(2014年2期)2014-05-27
科学之友(2010年17期)2010-08-23
