
基于无服务器架构的边缘AI计算平台
2018-11-16 06:34刘畅毋涛徐雷
信息通信技术 2018年5期
刘 畅 毋 涛 徐 雷
中国联通研究院 北京 100176
1 AI计算平台
1.1 AI的定义
AI(Artificial Intelligence)即人工智能,是计算机科学的一个分支领域[1]。1956年夏季,以麦卡赛、明斯基、罗切斯特和申农等为首的一批有远见卓识的年轻科学家在一起聚会,共同研究和探讨用机器模拟人类智能的一系列相关问题,并首次提出了“人工智能”这一术语,它标志着“人工智能”这门新兴学科的正式诞生。
尼尔逊教授对人工智能下了这样一个定义:“人工智能是关于知识的学科,一个关于怎样表示知识以及怎样获得知识并使用知识的科学。”而另一个美国麻省理工学院的温斯顿教授认为:“人工智能就是研究如何使计算机去做过去只有人才能做的智能工作。”这些说法都很好地反映了人工智能学科的基本思想和基本内容,即人工智能是研究人类智能活动的规律、构造具有一定智能的人工系统,研究如何让计算机去完成以往需要人的智力才能胜任的工作,也就是研究如何应用计算机的软硬件来模拟人类某些智能行为的理论、方法和技术。
1.2 AI计算平台
AI计算平台的目标是通过大量的历史数据训练得到一个尽量贴合应用需求的模型,然后通过不断的迭代优化完善模型,最终使该模型在应用推理过程中的结果最贴近期望值[2]。在训练过程中,AI计算平台需要大量的计算,才能保证模型的时效性和准确性,所以需要将系统部署在一个大型的计算集群中,云计算服务刚好满足这种需求,部署在云中是目前主流的部署模式。如图1所示,AI计算平台主要分为三个部分。

图1 传统AI计算平台
1)数据预处理。AI建模所使用的数据源通常是海量的大数据,这些数据的维度众多,数据质量参差不齐,甚至还有很多垃圾数据以及不完整的数据,如果不进行处理,会给建模的过程带来很大的困难,也会影响模型的准确程度,所以,在AI的建模过程中,数据预处理是非常重要的工作。数据预处理主要包括数据清理、数据集成、数据变换以及数据归约,最终把它归类到AI的计算模型中。
2)模型训练。目前,针对不同的应用有不同的训练算法,模型的训练首先要选择与应用相匹配的算法。在选择了合适的算法之后利用计算集群强大的计算资源结合历史数据对模型不断的迭代优化来形成最终的AI模型、算法公式以及一些相关的参数。随着应用过程中数据的不断累积,模型还可以不断地进行优化,以使计算结果更加接近期望值。
3)应用推理。在实际的应用中,将实际数据带入上面第二步训练得到的模型进行推理计算,可以得到期望的推理结果。
2 无服务器架构
无服务器(Serverless)架构可以分成两种类型[3]。一种是BaaS(Backend as a Service,后端即服务),例如消息队列、CDN、云对象存储、云数据库等,这些服务主要是承载数据的存储。另一种是FaaS(Function as a Service,函数即服务),这种方式主要是承载用户的计算功能,更多是对用户的计算进行托管。第二种方式是无服务器架构的核心技术点。
本文主要介绍采用FaaS方式的架构。采用此种架构,用户首先要将代码和配置提交到云平台上,代码即用户为实现某一个函数功能编写的一份代码或者代码包;配置则是指本身对于函数运行环境的配置,使用的是哪种环境、所需的内存、超时时间等,以及触发函数运行的触发器的配置。因为整个FaaS的运行方式是触发式运行,触发就需要有一个事件来源,而事件来源可以有很多种。例如当用户上传一张图片或者删除一张图片时,就会产生一个事件,这个事件会触发云函数的运行;例如和API网关的对接,也可以作为事件来源,在用户的HTTP请求到达网关之后,API网关会把该请求作为事件转发给云函数,触发云函数的运行,云函数拿到请求之后进行处理,生成响应给到用户。
如图2所示,Serverless的运行方式是按需运行,仅在设定的触发器上有事件产生时才会运行。图中左侧,是用户将代码和配置提交到Serverless平台进行保存,当设定好的事件产生后,针对每一个事件都会拉起一个函数实例,实现触发式运行。

图2 Serverless平台工作流程
因为函数本身是托管型的,用户本身无法感知到实例在哪里运行。Serverless平台背后有个大的计算资源池,用户实例触发之后,平台会从资源池中随机选取可运行的位置,把用户的函数实例在对应位置上跑起来。因此,整个调度过程或者事件来临之后的函数运行环境的扩缩容过程,都是由平台进行的。对用户来说,调度的粒度更细了,而且调度也都托管给平台了,用户自身只需考虑功能的实现,而一切和运维相关的问题都可以由平台的提供商来解决。
3 MEC技术
MEC(Multi-Access Edge Computing)即多接入边缘计算[4]。ETSI对MEC的标准定义是:在网络边缘提供IT服务环境和云计算能力。就是将应用、内容和核心网的部分业务处理和资源调度的功能一同部署到靠近接入侧的网络边缘,通过将业务靠近用户处理,以及应用、内容与网络的协同,来提供可靠、高效的业务体验。
近年来,随着AR/VR、车联网、高清视频以及物联网等应用的兴起,传统的网络结构已经逐渐不堪重负,因此催生了MEC的出现,将网络业务“下沉”[5]到更接近用户的无线接入网侧,从而带来三个好处[6]。
1)用户感受到的传输时延减小;2)网络拥塞被显著控制;3)更多的网络信息和网络拥塞控制功能可以开放给开发者。
4 基于无服务器架构的边缘AI计算平台
本文在传统的AI计算平台基础上进行创新,提出了一个新的基于无服务器架构的边缘AI计算平台方案。本节首先分别介绍引入无服务器架构以及引入MEC技术对AI计算平台的改进情况,之后对整体方案进行介绍说明。
4.1 无服务器架构加速AI计算平台
如第二节所述,从整个的计算过程来说,对于传统的数据存储过程,数据产生后,会先把数据进行缓存或者存储,比如以对象存储文件的形式进行保存,或者在数据库中以结构化形式存储下来,之后再进行分析及应用。
利用无服务器架构后,计算过程可以有很大的加速。如图3所示,可以在事件产生的时候就立刻拉起运行实例对数据进行处理,因此整个处理过程就变成了先计算,再对结果进行保存,从而加速了数据的存储以及后续调取的过程,也大大节省了存储需要的空间。因为AI计算平台在模型训练的过程中需要频繁地对数据进行计算和存储,所以引入无服务器架构可以显著提高计算平台的性能。
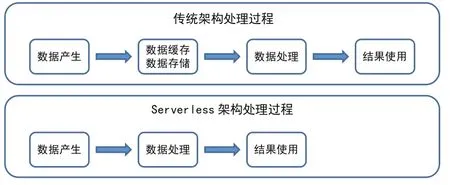
图3 利用无服务器架构加速AI计算平台
4.2 MEC技术加速AI计算平台
在利用无服务器架构对存储过程进行了加速之后,我们仍需要想办法对计算过程进行进一步加速。对于传统应用来说,数据在终端侧产生,上传到云端进行处理并保存结果。在AI的推理阶段,需要频繁地利用数据模型进行推理运算,但是计算量并不是很大。如果每次计算都要将数据上传到云端进行处理,不但增加了数据处理的时延,也给整个网络带来了不小的压力。
如图4所示,利用MEC技术可以使处理过程更加靠近用户,把一部分计算资源下放到靠近用户的网络边缘。传统的云计算方式,无论是使用容器,或是使用云主机,运算能力都是集中部署在云端的,而边缘计算技术可以把运算能力下放到中心云端之外,使计算能力更接近真正的用户,更加靠近设备端,免去了数据从终端到云端的传输过程,从而使计算过程可以尽快地在较近的计算节点中进行处理。因此,利用MEC可以将AI计算平台推理计算过程的时延进一步降低,也增加了系统的可靠性。
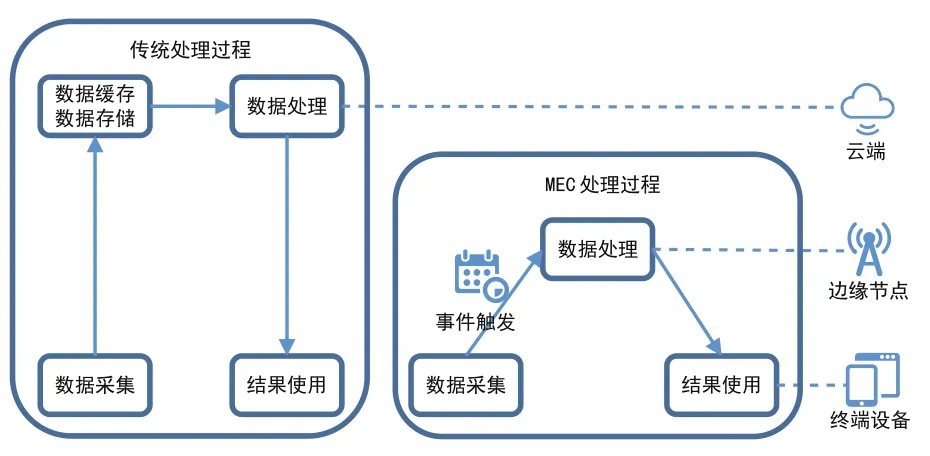
图4 利用MEC技术加速AI计算平台
4.3 基于无服务器架构的边缘AI计算平台
构建一个AI计算平台通常包括三个步骤。第一步是对预处理后的数据进行训练。第二步是验证测试数据的准确率情况。这两个步骤需要多次的迭代重复,直到使该算法实现了预期的精度。通过每次的迭代过程,算法可以学习到更多的数据并发现新的模式,这可以使模型的效率和准确率都得到提升。这两个步骤最终得出的是一个机器学习模型,它的参数被不断调整以处理后续产生的未知数据。第三个步骤也是最后一步,就是使用数据调用模型来计算预期的结果,这可能是基于新数据的预测、分类或分组。
前两个阶段因为涉及到机器学习所以需要大量计算工作,这需要由部署在云端的大量计算资源来满足。但是,第三个阶段的应用推理过程却不需要很多资源,所以非常适合将这部分功能部署在边缘设备上。它是一段代码,其中包含了计算的模型以及基于前两个阶段训练和验证的一系列参数。基于这些预定义的参数,它将在有新数据到来的时候对其进行分析。
如图5所示,本文提出了一种新的系统模型,在构建AI平台的前两个阶段,利用Serverless框架,使训练和测试模块可以按需触发式执行,节省了这个阶段的计算过程和存储过程,也简化了云端的运维工作。在第三阶段,利用MEC技术将AI平台的推理模块下放到网络边缘设备上,从而加速了计算过程。在终端侧有AI计算需求时,部署在网络边缘的Serverless框架可以按需建立AI推理计算实例,可以在请求量抖动时按需进行资源的扩缩容,使整个平台的资源利用率更高,稳定性更强。

图5 基于无服务器架构的边缘AI计算平台
综上,尽管AI计算平台的训练和验证阶段需要在拥有大量计算资源的云端进行,但推理阶段可以通过边缘计算技术在网络的边缘设备上进行计算,再加上与Serverless架构的结合,对整个平台的计算过程和存储过程都有显著的提速,而且也简化了系统的运维工作。
5 挑战和未来研究方向
利用Serverless框架和MEC技术,很好地解决了AI计算平台目前面临的问题。但是,在为我们带来便利和效益的同时,它还存在一些问题和挑战[7]。
1)计费问题。由于在部署边缘计算平台时将服务下沉到了网络的边缘,流量在边缘节点上进行了本地化卸载,而没有通过一个核心的节点,因此计费的功能很难实现。对于该问题,目前各公司已经有了自己倾向的解决方案,但是仍然没有统一的方案,移动边缘计算平台的标准化工作也尚未涵盖该部分。该问题需要设备供应商、OTT、运营商等多方的共同努力并积极探索。
2)安全问题。由于服务的下沉也带来一些安全问题,例如可能存在一些不受信任的终端或移动边缘应用开发者的非法接入问题,因此需要在接入侧和边缘计算节点之间建立鉴权流程以及安全的通信隧道,以保证数据的机密性和完整性,并保证网络的安全。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
汽车工程(2021年12期)2021-03-08
网络安全和信息化(2020年9期)2020-12-31
铁道通信信号(2019年9期)2019-11-25
时代人物(2019年27期)2019-10-23
网络安全和信息化(2019年8期)2019-08-28
计算机测量与控制(2017年6期)2017-07-01
通信产业报(2016年44期)2017-03-13
网络空间安全(2016年3期)2016-06-15
雕塑(1999年2期)1999-06-28
