
基于社交平台数据的文本分类算法研究
2018-11-10 02:10施瑞朗
电子科技 2018年10期
施瑞朗
(杭州电子科技大学 计算机学院, 浙江 杭州 310018)
文本分类是在预定义的分类体系下,根据文本的特征(内容或属性),将给定文本与一个或多个类别相关联的过程。文本分类是文本挖掘、机器学习、自然语言处理等诸多领域的子问题之一,在垃圾邮件识别[1],语义分析[2-4]等诸多应用中都有出现。如何将短文本数据进行分类以及提取出每个类中的具有代表性的词语对社交平台的数据挖掘和热点分析[4-5]具有重要意义。
目前,由于社交网站的数据更新周期快,数据收集困难,所以很少有针对社交网站数据的文本分类算法研究。机器学习是近年来兴起的新兴领域,由于其相关算法有深厚的理论基础,已经被广泛应用于各个领域[6-7]。本文采用支持向量机、朴素贝叶斯、K近邻和决策树共4种常用于文本分类的机器学习算法对收集到的社交平台数据集进行模型训练,然后通过精确率、召回率等机器学习常用的评估指标对模型进行评估,最后采用TF-IDF算法[8]统计出每个类别中的代表性词语。
1 算法理论
支持向量机(Support Vector Machine,SVM)算法[9-10]对于两个种类的分类问题,寻找一个超平面作为两类训练样本点的分割,以保证最小的分类错误率。在线性可分的情况下,存在一个或多个超平面使得训练样本完全分开,SVM的目标是找到其中的最优超平面,最优超平面是使得每一类数据与超平面距离最近的向量与超平面之间的距离最大的这样的平面;对于线性不可分的情况,通过使用核函数(一种非线性映射算法)将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分。由于SVM背后涉及的数学原理过于复杂,本文就不详尽描述其原理,只关注SVM的实践过程[11-12]。
K近邻(K Nearest Neighbor,KNN)算法[10-13]是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例, 这K个实例的多数属于哪个类,就把该输入实例分类到这个类中。
决策树(Decision Tree,DT)算法[14-15]是在已知各种情况发生概率的基础上,通过构成决策树来求取现值的期望值大于等于零的概率,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用于信息检索与数据挖掘的常用加权技术,用于评估一个词对于某类文档的重要程度。TF为词频,代表某个词在一篇文档中出现的频率;IDF为逆文档频率,主要思想是:如果包含某个词的文档越少,则IDF越大,则说明该词具有很好的类别区分能力。最终每个词的得分为其TF值乘以IDF值,得分高说明该词是某类文档的特征词。


2 研究过程
本文不讨论社交平台数据收集的方式,只关注对数据的预处理,实验过程和结果展示。
2.1 实验数据
本文的目的是研究社交平台上短文本的文本分类的问题,Twitter上的数据由于文本短和数量多的特性,很适合作为本研究的数据集。再者,Twitter是著名的社交网络平台之一,对于每个主题文本都可以收集到很多数据,为了确保实验结果的稳定性,对多个种类的文本收集了500条相关的数据,最终选择了“天气”和“食物”这2个类别的数据,基本的数据预处理步骤主要是使用分词工具去除停用词,然后提取出词干信息。
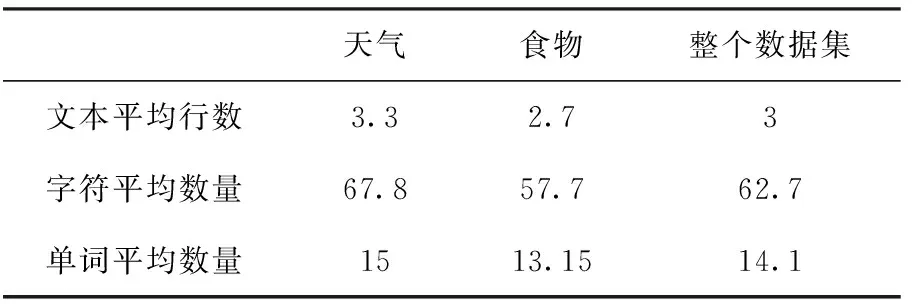
表1 数据集的结构
可见数据集的统计值比正常的文本分类数据集统计值小,表中展示了“天气”类数据集的文本行数均值为3.3行,对应的每篇文本字符平均数量为67.8,单词平均数量为15;而“食物”类数据集的文本行数2.7,对应的每篇文本字符平均数量为57.7,单词平均数量为13.15。可见2个种类的数据集和整体数据集的统计信息相差不大。
2.2 实验过程和结果
这部分将讨论实验的细节和分析实验结果。本研究将通过4种文本分类算法对之前一节获取的数据进行结果比较,这4种算法分别是:支持向量机(SVM),朴素贝叶斯(NB),K近邻(KNN)和决策树(DT)。除了K-近邻算法,其它3种算法都在文本分类问题上有较好的表现[1],之所以添加K近邻算法是因为其在高维文本分类问题上有高敏感度和高稀疏性的特性。
接着把数据集划分为训练集和测试集,其中训练集占2/3的比例,测试集占1/3的比例,训练集用于训练算法模型,测试集用于验证模型的泛化能力。为了衡量分类结果的性能,采用了业界普遍认可的4个指标:精确率、召回率、F1值和准确度。为了说明这些指标的作用,把模型检测出的二分类分为“正相关”(TP)和“负相关”(FP),分别表示正类被模型判定为正类,负类被模型判定为正类;对应的模型未检测出的二分类分为FN和TN,分别表示正类被判定为负类,负类被判定为负类。则可得:
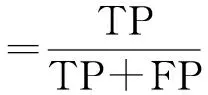

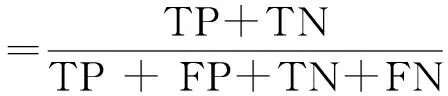
由图1可得,在各项指标上,支持向量机(SVM)算法的表现都优于其它几种算法,朴素贝叶斯(NB)次之,KNN算法虽然有自己的特性,但是总体的表现较其它3种算法来说还是较差的。

图1 数据集上4种分类算法的各项评估指标
在分好类后,最后再使用TF-IDF算法计算每类文本的特征词,由表2得“天气”类文本最常出现的词语分别是:旅游,出行和交通;“食物”类文本最常出现的词语分别是:好看、美味、吃。

表2 两类文本对应的排名前3的特征词
3 结束语
本文聚焦于社交平台上的短文本分类问题,抓取了Twitter上的文本数据,然后对比了4种不同机器学习算法在该文本数据上的表现,其中支持向量机算法在各项评估指标上表现最优。根据TF-IDF算法提取出对应的代表性词汇,实验结果具有很好的参考意义。对于未来的工作,希望能在更多的类别,更大的数据规模和更多的语言的背景下取得理想的实验结果。
猜你喜欢
客联(2022年3期)2022-05-31
数学年刊A辑(中文版)(2021年3期)2021-11-05
中国新闻周刊(2021年26期)2021-07-27
数学年刊A辑(中文版)(2021年2期)2021-07-17
成都信息工程大学学报(2019年3期)2019-09-25
数学物理学报(2019年1期)2019-03-21
电子制作(2018年16期)2018-09-26
信息安全研究(2016年4期)2016-12-01
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
