
基于深度学习的智能辅助驾驶系统
2018-11-10 01:55张达峰刘宇红张荣芬
电子科技 2018年10期
张达峰,刘宇红,张荣芬
(贵州大学 大数据与信息工程学院, 贵州 贵阳 550025)
据前瞻产业研究院统计,中国民用车辆数量从2008年到2014年呈直线增长状态。然而,随着汽车数量的增多,交通事故也频频发生,对人身安全和社会经济造成严重损害, 2014年有19.681 2万起交通事故发生,死亡58 523人,直接经济损失高达107 543万元[1]。交通安全问题已成为不能忽视的重大社会问题。
本文设计的基于深度学习的智能辅助驾驶系统[2-3],利用深度学习算法和双目测距原理,不仅可以实现对障碍物距离的判定,而且还可以实现对车辆周围障碍物类型的识别,然后通过语音模块将识别结果播报给驾驶员,以便其进行避障等行为。此外,本设计可进一步实现GPS定位功能,实时显示车辆的位置信息;短信功能,将车辆的位置信息以短信的形式发生给车主等,以此实现停车安全、寻车管理等方面的功能。
1 设计思路
智能辅助驾驶系统结构框图如图1 所示,主要由摄像头采集端和云服务器端两部分构成。摄像头采集端集成了主控单元、双目摄像头、GPS定位模块、语音播报模块和GPRS通信模块;云服务器端则是由多台并行计算的服务器构成的服务器集群。当驾驶员使用智能辅助驾驶系统时,双目摄像头采集车辆周围环境图像,采集的图像采用本地—云服务器递进识别方案:(1)由双目摄像头将图像通过USB接口传送至主控单元,主控单元对采集的图像进行模板匹配。如无法匹配,则将图像进行压缩,再利用3G通信模块将压缩的图像发送至云服务器端;(2)云服务器利用深度学习与双目测距等算法来获取障碍物的类别和距离信息,并将信息以文本格式发送至眼镜采集端。如果距离低于设定的门限值,语音模块会将文本格式的障碍物类别和距离信息以语音形式告知驾驶员,如果距离大于设定的门限值,语音模块则保持静默运行。
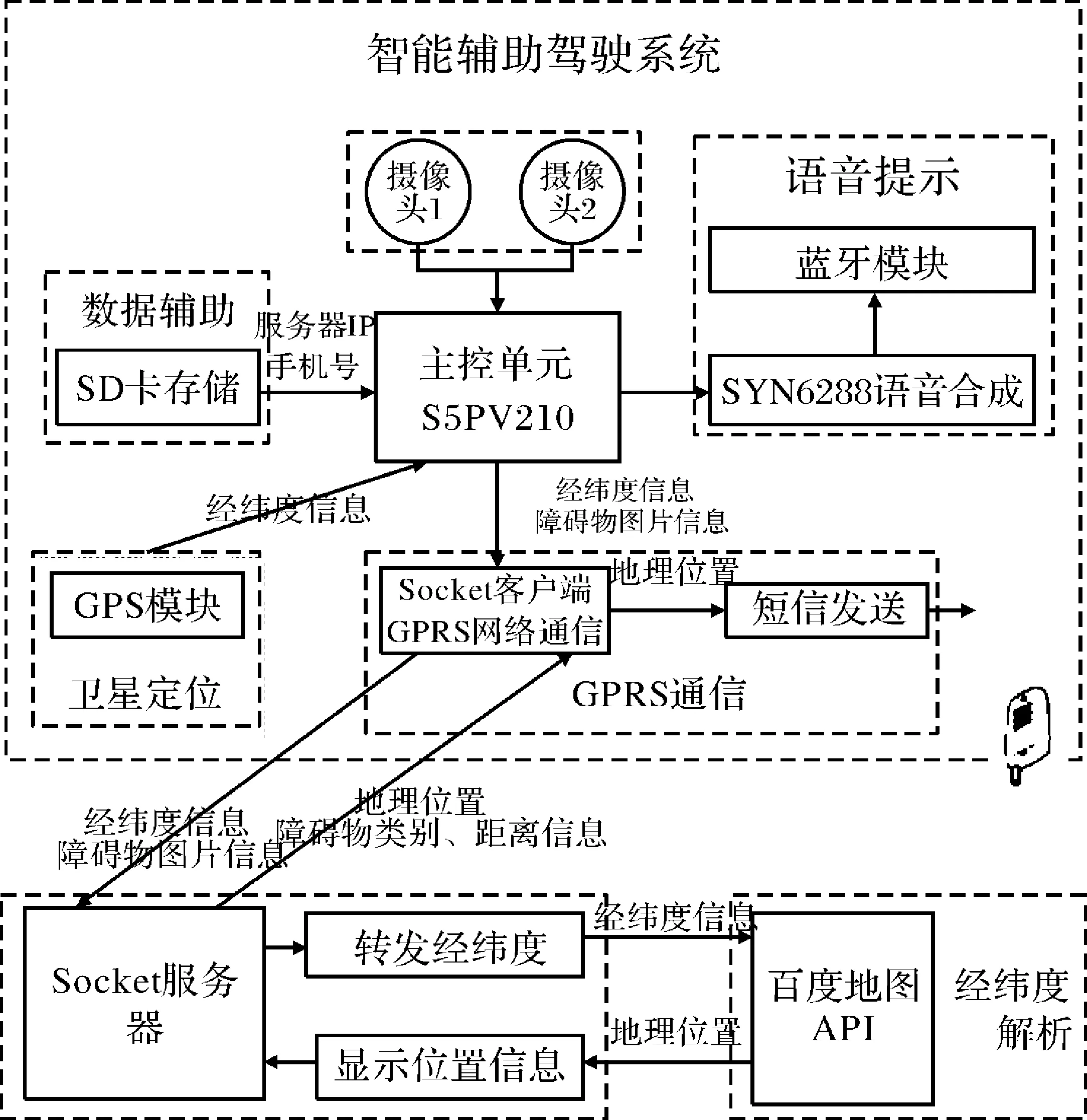
图1 智能辅助驾驶系统结构框图
2 系统设计
2.1 主控单元
主控单元是整个设计的核心,负责对整个智能辅助驾驶采集端各部分功能模块数据和信息的分析和调度,控制着整个系统的正常工作。本设计采用性能高、功耗低的S5PV210芯片作为主控单元,并搭载Linux PAD操作系统,保证各个模块具有更高的效率、更稳定的性能和更方便的实时操作性。
2.2 云服务器
云服务器是由多台并行计算服务器构成的服务器集群,具有较强的运算能力,可提供简单高效、安全可靠、处理能力可弹性伸缩的计算服务。通过在云服务器上搭建软件平台,建立图像学习数据库,并利用深度学习算法和支持向量机SVM(Support Vector Machine)算法[4],可以实现对眼镜采集端传送图像的识别。
本设计是将深度学习方法与支持向量机(SVM)相结合(分类方法模型如图2所示),利用机器视觉将障碍物的图像信息传送至图像处理系统,继而转成数字信号。图像处理系统利用深度学习方法的深度信念网络(Deep Belief Networks,DBN)通过一种交替进行的无监督和有监督学习过程的方法对采集的信号进行特征提取,将最后一层隐含层的输出作为SVM的输入,对特征信息进行分类训练识别,最后采用模板匹配法实现智能辅助驾驶系统的障碍物识别功能。
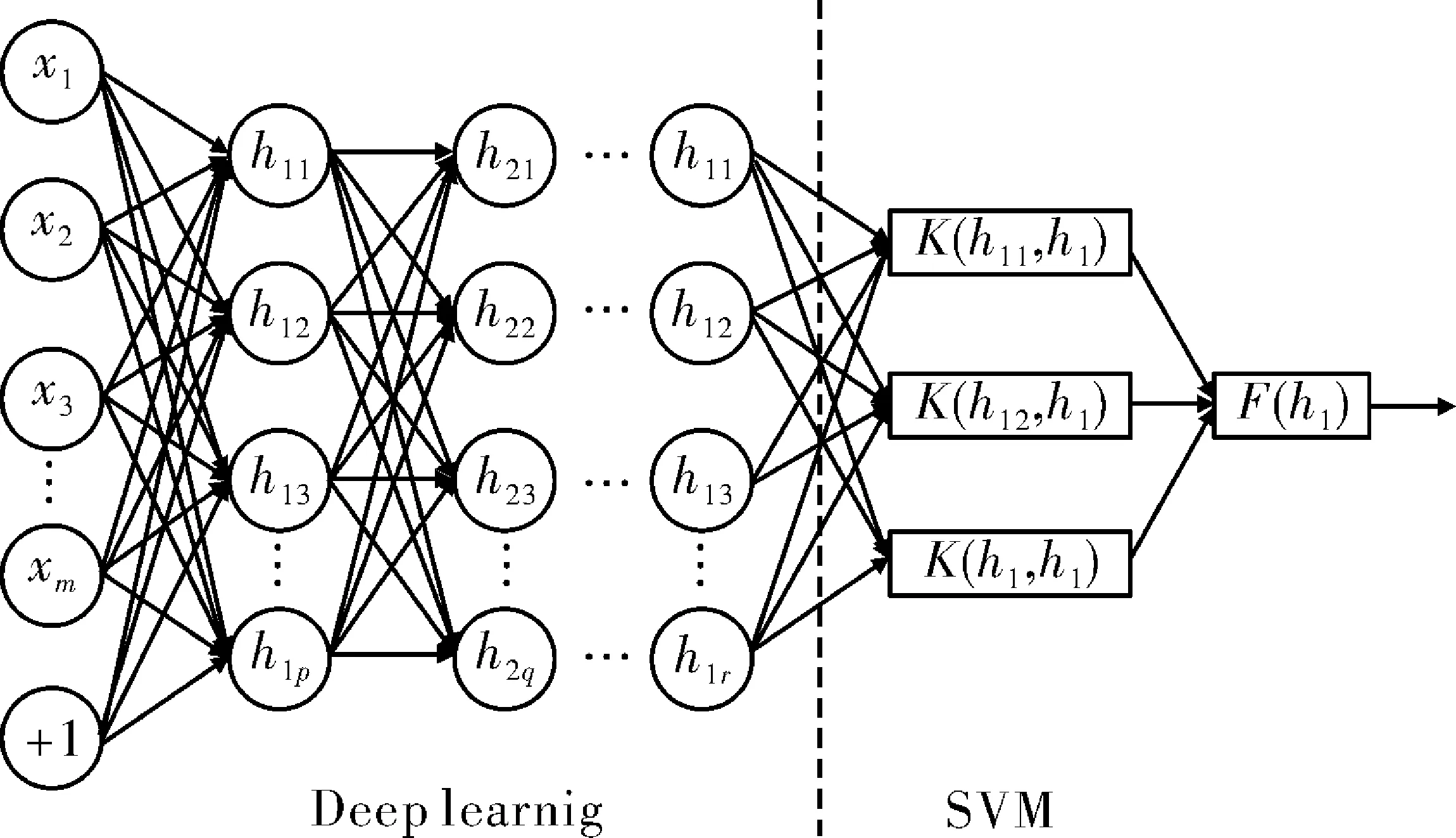
图2 深度学习结合SVM的分类方法模型
深度信念网络是深度学习方法中最为常用的一种概率生成模型,由多层限制性玻尔兹曼机(Restricted Boltzmann Machine,RBM)[5-9]构成,在整个网络中,负责对RBM的每一层采用无监督贪婪方法进行训练。
限制性玻尔兹曼机(RBM)是一个可用随机神经网络来解释的概率图模型(其结构示意图如图3所示),是由二值隐含层单元h和可见层单元v组成。对于一个由n个结点的可见层单元和m个结点的隐含层单元组成的RBM系统的能量(v,h)为
(1)
其中,Wij为隐含层和可视层之间的权重;ai为对每个可见层单元vi的偏置;bj为对每个隐含层层单元nj的偏置。
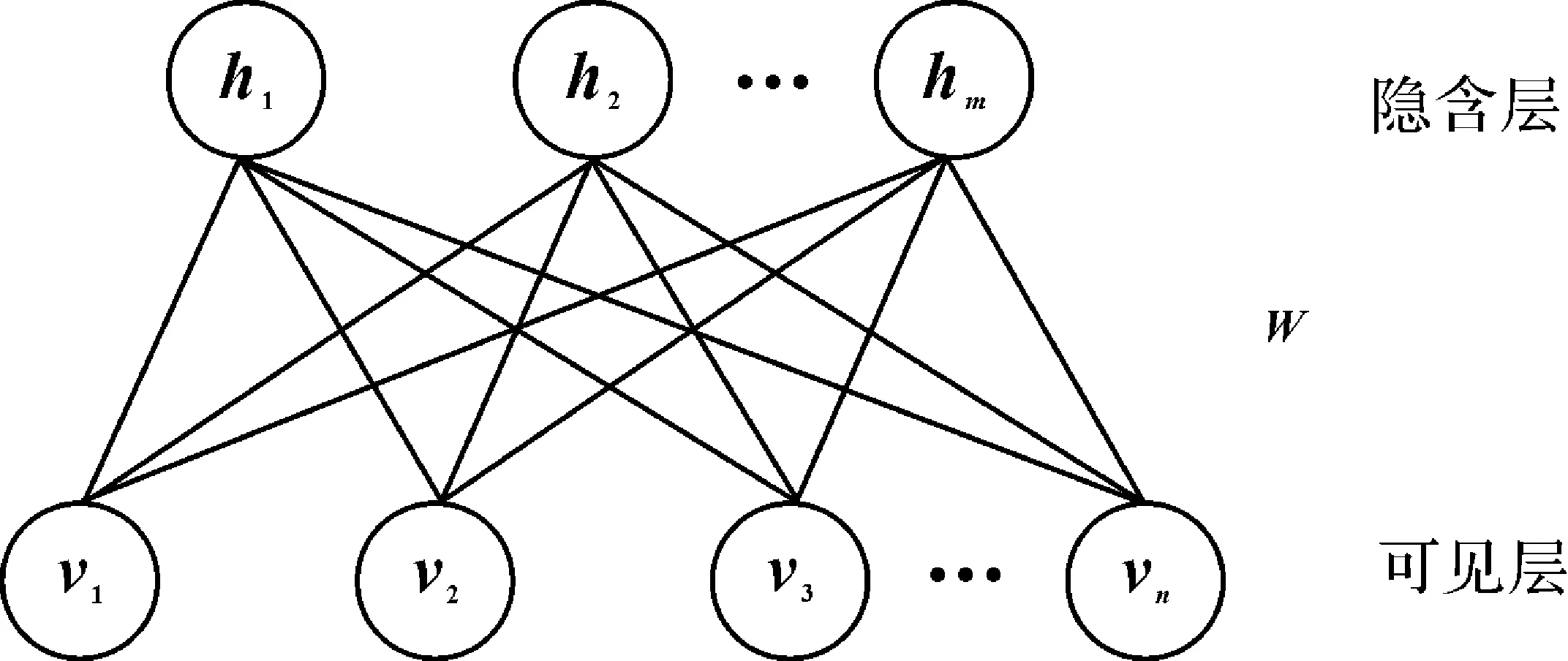
图3 RBM结构示意图
本设计采用的DBN深度学习方法,是一种交替进行无监督和有监督学习过程的方法。上文提到的RBM训练方法是无监督学习,具体流程是对RBM的第一层进行无监督学习,结束之后加入标签,用监督学习的方法来调整RBM网络的参数,然后利用调整后的一层作为下一层的可见层,以此类推,直到最后一层训练结束(训练流程图如图4所示)[10]。在训练过程中采用CIFAR-10自然场景库,其包含10类共60 000个32×32的彩色图像,由50 000个训练图像和10 000个测试图像组成。在本设计中还加入了一些生活中常见的场景,如椅子、垃圾箱、人等,以此来提高识别系统的实用性。
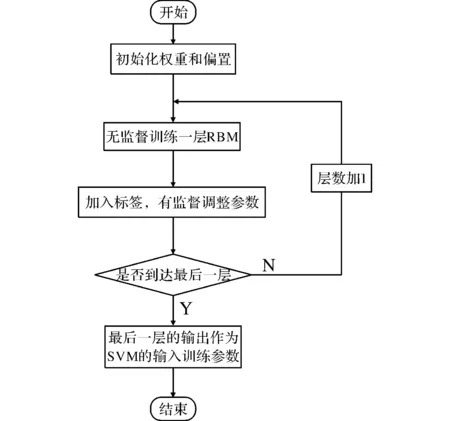
图4 深度学习结合SVM的分类方法训练流程图
2.3 视频采集模块
本设计采用双目摄像头模拟人类双眼视觉原理来采集同一场景的两幅图像,对采集的二维图像结合神经网络算法提取图像中的主要信息,通过BM(Boyer-Moore)算法得出图像的视差,再利用双目测距原理[11-13]得出障碍物的距离信息。利用OpenCV的双目测距原理,图5为双摄像头模型俯视图,此图解释了双目摄像头测距的原理,求深度信息Z的公式为
(2)
其中,P为待测物体上的某一点,OL与OR分别为两个相机的光心,点P在两个相机的感光器上的成像的点分别为PL和PR,T为两个相机的中心间距,f为相机的焦距,T-(xL-xR)为点PL和PR之间的距离。在OpenCV中,f和视差d=(xL-xR)的量纲为像素点,Tx的量纲由定标棋盘格的实际尺寸使用者输入的值来确定(一般为mm级)。
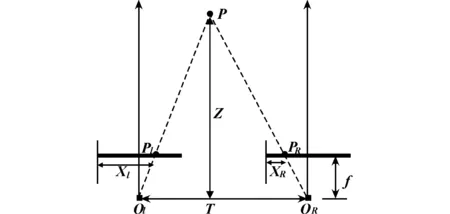
图5 双摄像头模型俯视图
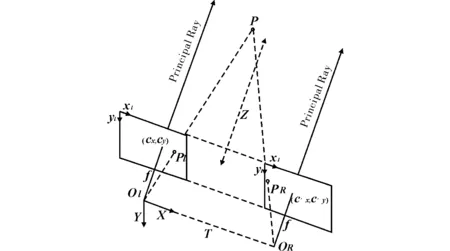
图6 双摄像头模型立体视图
图6解释了双目摄像头获取空间中某点三维坐标的原理。在OpenCV中,先对双目摄像头进行标定、校准和匹配,获得摄像头的参数Tx、f、d=(xL-xR)、cx与cv,对双目摄像头标定和匹配的目的是得到矩阵Q
(3)
匹配的目的是求解视差d=(xL-xR),其次获得P点的坐标(x,y),构造向量W
W=[xydl]T
(4)
通过Q·W求解得到世界坐标向量,进而可求得Z
(5)
3 实验结果分析
前文介绍了智能辅助驾驶系统对障碍物进行类型识别和距离测量的原理和流程。通过以上原理和操作可以实现对障碍物的判断和距离的测定,当障碍物的距离小于设定的阈值时,智能辅助驾驶系统会通过语音模块进行障碍物类型和距离的播报。
3.1 图像识别
在Microsoft Visual Studio 2012环境下,利用上述深度信念网络模型对5种常见物体进行识别,表1为5种常见障碍物的识别率和平均识别率。
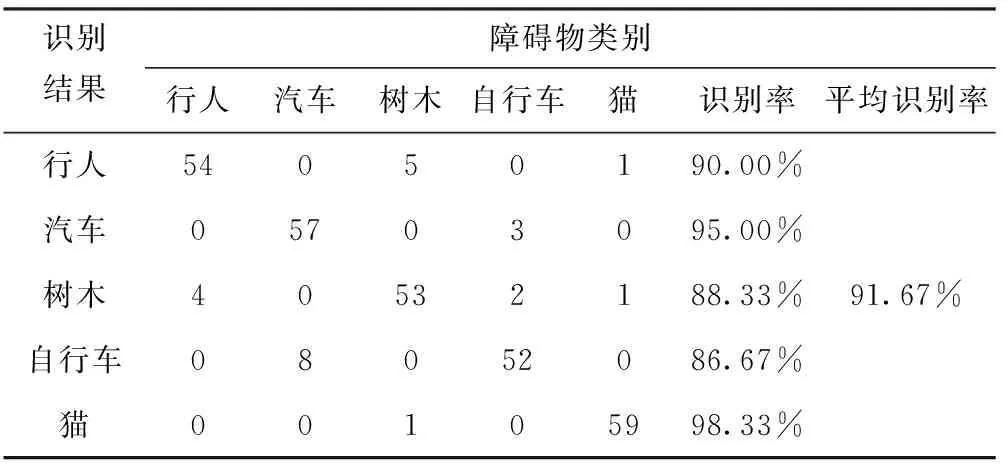
表1 5种常见障碍物的识别率和平均识别率
由表1识别结果可知,利用深度信念网络模型对常见障碍物进行分类训练后得到的平均识别率为91.67%,比基于单纯支持向量机的物体分类训练[15]所获得的识别率要高将近15%。因此,深度学习结合SVM的分类方法模型对常见物体具有良好的识别能力。
3.2 距离测量
利用双目摄像头分别采集同一物体的左右视图,在OpenCV上对采集到的图像进行处理生成视图差,利用双目测距原理对视图差进行分析进而求得物体的距离信息。更多的测试结果如表2所示,通过分析可知,当所测量的目标物体距离摄像机越近时,误差率越低,这也符合双目测距的原理。
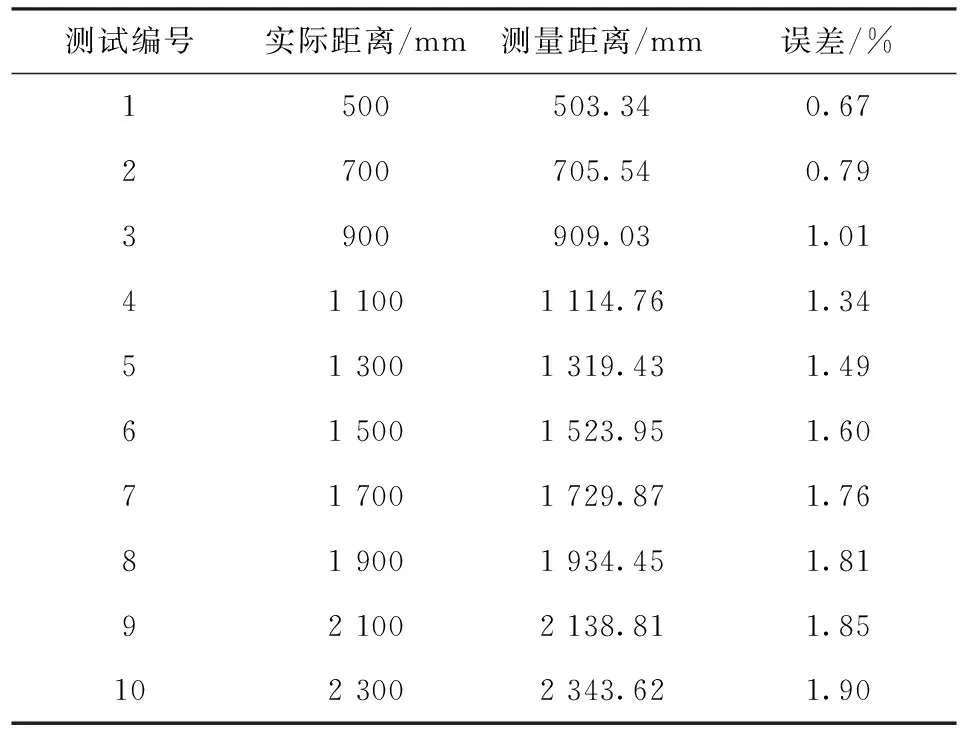
表2 测距结果
图7是双目摄像头采集的同一行人的左右视图。图8在实际场景中对障碍物探测的结果,显示了该智能辅助驾驶系统不仅可以判断前方障碍物的类别信息,而且还可以实现对障碍物距离的测量。因此,当该系统检测到障碍物时,会将障碍物的类别和距离信息通过语音模块[16-17]告知驾驶员,提醒驾驶员及时避障,从而保证行车安全。

图7 双目摄像头采集的同一行人的左右视图
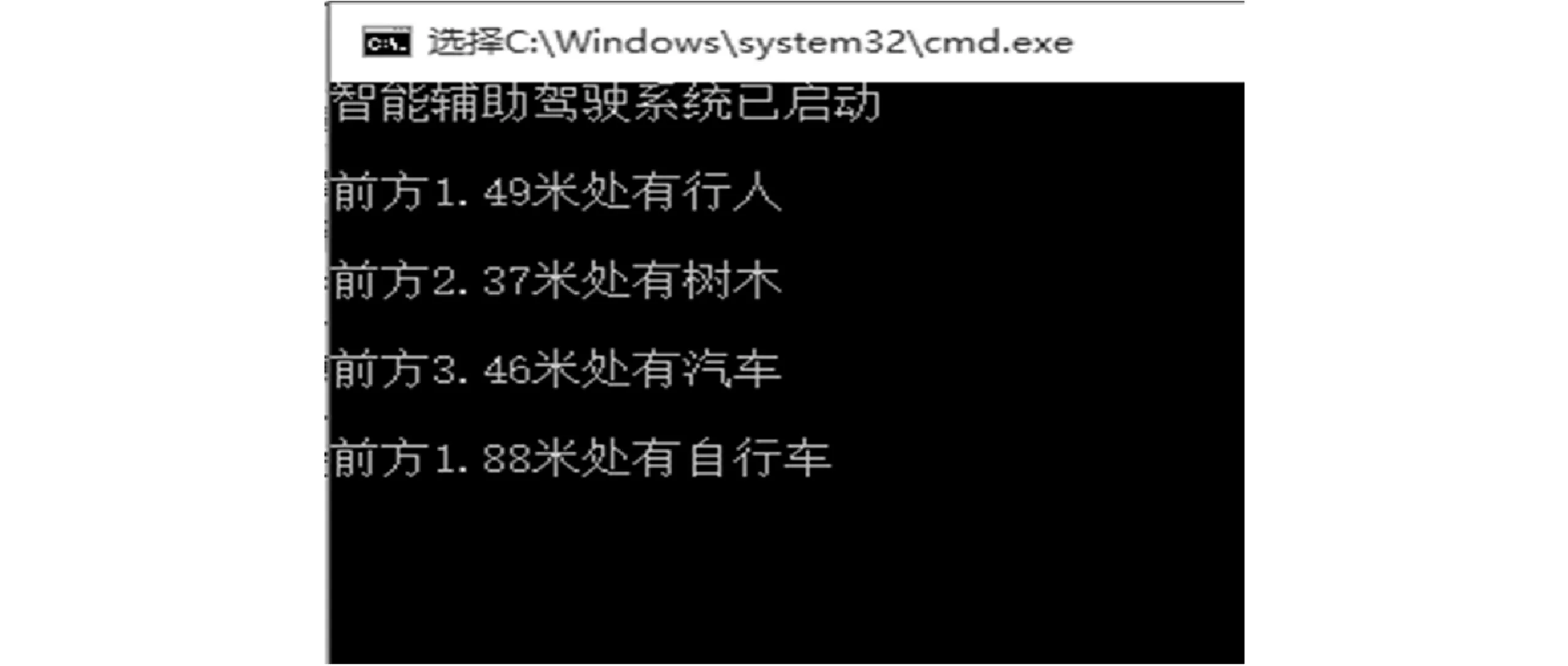
图8 实际场景中对障碍物探测的结果
4 结束语
本文设计的智能辅助驾驶系统综合利用了深度学习、SVM算法模型和双目测距原理,不仅能确定障碍物的距离信息,还实现了对障碍物类别的判断,利用搭载的智能语音播报系统和GPS定位系统可以实时播报前方路况和车辆所处的位置信息,为驾驶员出行提供了便利,在减少交通事故方面具有重要的现实意义。此外,本系统还具有短信通知功能,可以将车辆的位置信息发送至指定联系人的手机,对于寻车管理具有辅助作用。
猜你喜欢
动漫界·幼教365(中班)(2020年3期)2020-04-20
铁道通信信号(2020年9期)2020-02-06
科学(2020年3期)2020-01-06
电子制作(2019年20期)2019-12-04
测控技术(2018年4期)2018-11-25
电子制作(2017年7期)2017-06-05
现代计算机(2016年11期)2016-02-28
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
太空探索(2014年1期)2014-07-10
城市道桥与防洪(2014年5期)2014-02-27
