
基于Python的新浪微博位置数据获取方法研究
2018-11-08 02:27杜翔蔡燕兰小机
江西理工大学学报 2018年5期
杜翔, 蔡燕, 兰小机
(江西理工大学,a.西校区管委会;b.建筑与测绘工程学院,江西 赣州 341000)
0 引 言
智能手机的普及、web2.0技术的日益成熟以及移动网络的迅速发展,使得社交媒体软件迅速发展和被使用.据统计,国内最大的微博平台——新浪微博截至2017年9月,活跃用户就达到了3.76亿[1].用户借助微博平台,在网络上留下各种“足迹”,包括评论、图片、视频、地理位置和个人信息等,尤其在外出游玩过程中,用户到达旅游目的地之后倾向于通过微博随时随地发布心情和照片等,这些数据经过长时间的积累便会形成大规模的数据量.由于数据都是用户根据自己当时的感受、所想而产生的,他人干预的因素较小,因此数据能较为真实的反映出用户当时的状态,具有较高的挖掘价值.
周中华等[2]通过模拟登录微博成功获取了大量的微博文本,对用户社交图谱及感冒数据进行了分析;陈琳等[3]通过爬虫获取了发布微博的时间与微博文本,分析与雾霾相关微博数量在不同时间尺度下的变化关系;A Tumasjan等[4]通过分析twitter上的十万条信息的情感,准确的反映了当时的选举结果;Burns等[5]通过追踪2012年2月至2012年3月24日之间twitter的使用情况,表明社会媒体活动在国家级竞选活动中的相对重要性;刘乙坐和张明旺等[6-7]等通过分析微博特点,提出了一套让政府有关部门可以有力监测和引导舆论的机制;易善君等[8]通过分析微博数据和空气数据,研究空气质量与居民情感之间的关系,得出空气中对居民情感影响较大的为颗粒物质与有刺激性气味的气体.关于微博爬虫和微博数据的研究非常多,但是由于他们没有获取到发布微博的位置数据,研究受到了局限,如果有发布微博位置数据,就能分析舆论的传播路径,还能分析感冒、雾霾、情感等信息与地理位置之间的关系.所以文中提出一个基于Python的微博位置数据的获取方法,来增加微博数据的维度,使微博数据的价值和可研究性提高.
1 微博位置数据的获取方法研究
1.1 基于新浪API的获取方法研究
新浪微博API[9]的功能十分强大且高效,用户可以通过调用新浪API获取海量的微博数据.用户只需在新浪微博开放平台上注册成为开发者后通过OAuth授权即可调用API开始获取微博数据.
虽然这种方法简单、高效,但是新浪微博并没有将所有的API调用权限交给开发者,而且还限制了API的调用频率,如果想要高频率的调用API需要和新浪进入深度合作.
综上所诉,这种方法虽然简单、快捷,但作为普通用户能获取到的数据量不仅较少,而且因为API权限问题,普通用户也不一定能获取到想要的数据,所以这个方法不是一个理想的微博位置数据获取方法.
1.2 基于Python的网络爬虫
基于Python的网络爬虫技术[10-15]研究已经十分成熟,能比较简单的获取特定的数据.大部分采用的是多线程方法,而Python里的多线程是单cpu意义上的多线程,因此采集速度无法提升太多.本文提出的方法为并行化爬虫,该方法包括五个部分:一是模拟登录[11]部分,用于模拟登录新浪微博,解决数据的访问权限问题;二是URL管理部分,使用Redis维护未完成集合(New Set)和已完成集合(Old Set),避免重复爬取且能够使程序并行化,提高数据的获取效率;三是下载部分,用于下载服务器返回的html代码;四是网页解析部分,解析出htm l代码中所包含的微博信息及用户信息;五是输出部分,将解析后得到的内容输出到数据库中保存.
2 爬虫程序设计
2.1 模拟登录部分
通过使用fiddler抓取m.weibo.com网站登录的数据包可以发现,账号密码都是明文POST到https://passport.weibo.cn/sso/login网页,验证成功后返回“retcode:2000000”的 json 数据(如图 1 所示).明文传递使模拟登录变得简单.但是由于要爬取地理坐标数据,单单只是模拟登录手机网页版微博是不够的,所以必须获得一个可以访问所有新浪网站的cookie.
自动模拟登录具体流程如下:
1.使用Urllib2库创建三个带cookie的opener分别是 opener1、opener2、opener3;
2.输入登录新浪微博的用户名和密码;
3.使用opener1将用户名、密码和header信息POST到https://passport.weibo.cn/sso/login(称之为URL1);
4.获取返回信息中的weibo.com的ticket为ticket1,sina.com.cn 的 ticket为 ticket2;
5.使用opener2访问https://passport.weibo.com/sso/crossdomain?entry=mweibo&action=login&p roj=1&ticket =ticket1&savestate =1&callback =jsonpcallback1(称之为 URL2).
6.使用opener3访问https://login.sina.com.cn/sso/crossdomain?entry=mweibo&action=login&proj=1&ticket=ticket2&savestate=1&callback=jsonpcallback(称之为 URL3).
7.使用opener3访问http://login.sina.com.cn/sso/login.php(称之为URL4)并解析得到ticket和ssosavestate(如图 2 所示).
8.使用opener2访问http://passport.weibo.com/wbsso/login?ticket=ticket&ssosavestate=ssosavestate&callback=sinaSSOController.doCrossDomainCallBack&scriptId=ssoscript0&client=ssologin.js(v1.4.19)( 称之为 URL5).
9.这样就完成了整个的登录过程,此时opener2中所带的cookie可以访问新浪各个域中的内容.
自动模拟登录流程图如图3所示.

图2 opener3访问http://login.sina.com.cn/sso/login.php返回的htm l
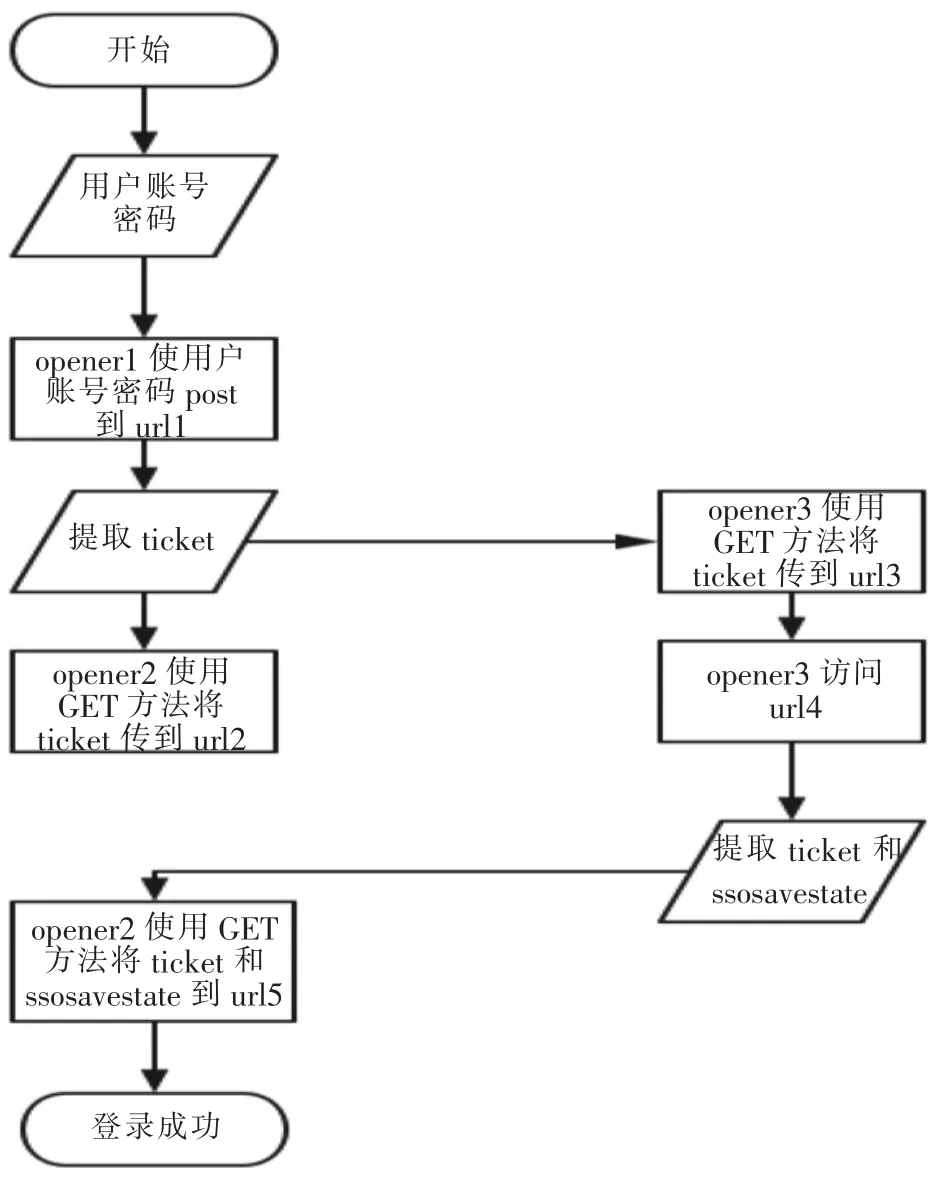
图3 自动模拟登录流程
2.2 下载部分
新浪微博数据需要模拟登录后才能访问,所以本部分使用的是opener2对新浪URL进行访问.由于微博返回数据使用了GZIP压缩,所以需要使用Python自带的StringIO库对内容进行解压,解压后可得到服务器返回的html代码.下载流程图如图4所示.
2.3 解析部分
文中使用Python的re库中正则表达式来提取用户基本信息,使用Python的BeautifulSoup库将HTML解析为DOM对象来提取微博数据.由于本文只获取赣州、上海、南昌地区的微博数据,故直接把用户所在地区不是赣州、上海、南昌的微博数据直接过滤、丢弃.解析部分流程图如图5所示.
2.4 URL管理部分
URL管理部分的主要功能是维护两个队列,分别是未完成集合(New Set)和已完成集合(Old Set).文中使用Redis作为队列的存储软件,有以下两个优点:
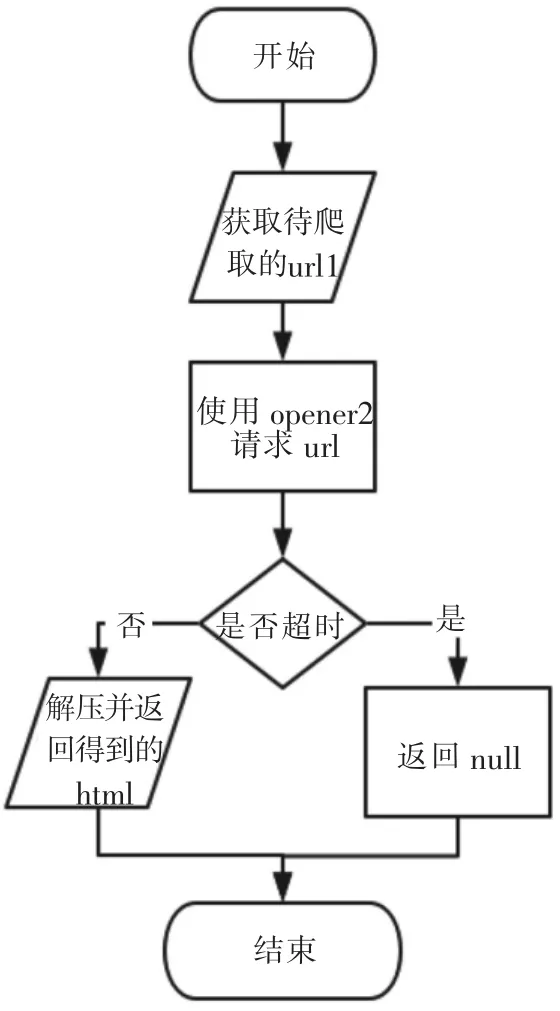
图4 下载流程

图5 解析部分流程
第一,支持集合(SET).因为相同的页面我们只需要爬取一次,通过使用集合(set)可以自动的为我们去重,也就是说,我们在页面中解析到的URL只需要和已完成集合中的URL进行匹配,如果该URL不在已完成集合中就可以往未完成集合中存储,自动去重使得我们的未完成集合中的URL全为未爬取过的且没有重复的URL.
第二,使用Redis可以使爬虫并行化.各个节点只需将解析到的URL交给URL管理器处理,将未爬取的URL存放到未完成集合中,然后各个节点通过URL管理器从未完成集合中取出URL进行数据爬取.URL管理部分流程图如图6、图7所示.

图6 存入URL流程
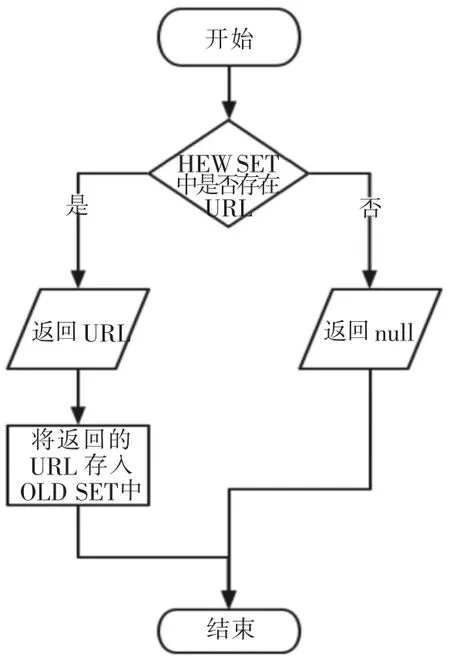
图7 取出URL流程
2.5 输出部分
将解析好的用户信息及微博数据存储到MongoDB,将解析到的URL信息传递给URL管理器管理.其中微博数据包括昵称、用户ID、用户性别、用户所在地区、用户年龄、微博文本、微博文本发布时间、微博文本发布地点及坐标,在MongoDB 中 分 别 使 用 “name”、 “Id”、 “gender”、“addr”、“age”、“Text”、“date”、“pao_dl_address”和“Location”表示.
根据上述的5个部分,将其进行整合得到微博爬虫系统整体流程图如图8所示.
3 实验验证
3.1 实验环境
运行爬虫主程序的计算机配置如表1所示.
运行Redis和MongoDB的计算机配置如表2所示.
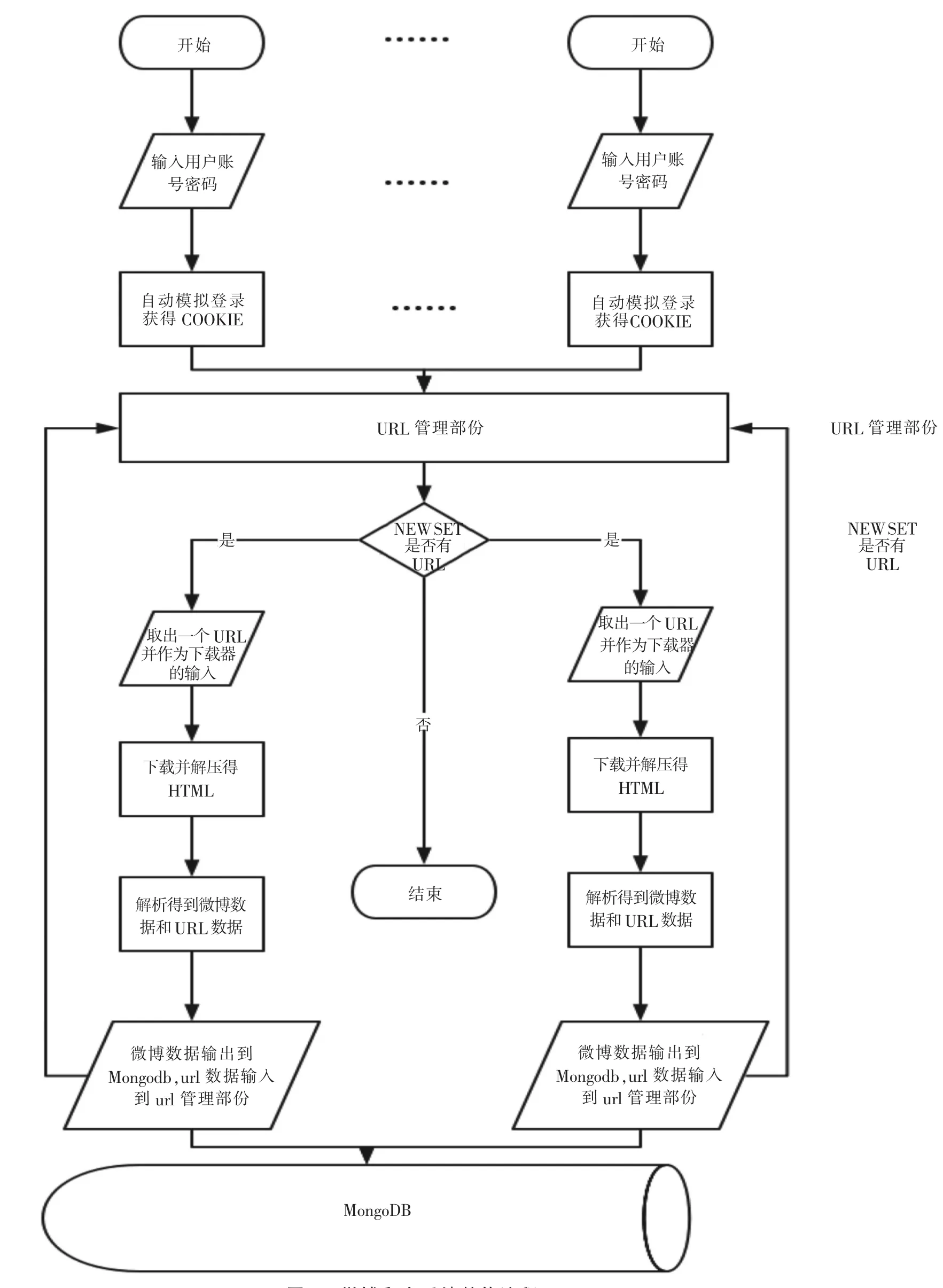
图8 微博爬虫系统整体流程

表1 运行爬虫主程序的计算机配置

表2 运行Redis和M ongoDB的计算机配置
3.2 并行效率分析
本文爬虫运行在表1所示的计算机中,爬虫进程数从1逐步增加至5,得到每小时微博数据采集速率变化曲线如图9所示.

图9 微博数据采集速率与爬虫进程数的关系曲线
根据图9可以发现:①随着进程数的增加,微博数据采集速率逐渐增加;②当爬虫进程数小于等于3时,采集速率基本呈一条直线上升,有些许波动,但是不大,当进程数大于3时,采集速率增加幅度明显下降,这是由于此时计算机性能开始限制爬虫的工作效率.
3.3 爬取界面与微博数据展示
文中通过同时开启3个爬虫进程爬取微博数据,爬取界面如图10所示.
经过10天的爬取,得到微博数据2152122条,其中赣州区域313450条,上海区域1401914条,南昌区域436758条.

图10 爬虫爬取微博的界面
微博数据在MongoDB中存储的形式如图11所示.
通过文中提出的爬虫能够较好的爬取微博数据,采集速率也可根据情况进行调节,在不超过计算机性能的情况下,爬虫进程数越多,速率越快,如果达到单台计算机性能极限时,仍需提高数据采集效率,只需增加计算机,并在其上运行爬虫进程即可.需要说明的是,本文爬取的微博文本是带地理坐标的,该类微博相比于普通微博数量要少的多,所以有相当一部分不带地理坐标的微博数据被舍弃,使得数据的获取效率显得较低.
4 结 论
通过使用Python提供的丰富的库,本文提出了基于Python的新浪微博位置数的获取方法,并根据该方法实现了一个爬虫程序.该程序只需要使用者输入微博账号密码,就能获得可以访问所有新浪网站的cookie,能够抓取特定区域中的带地理坐标微博数据,并自动存储在MongoDB数据库中.带地理坐标的微博数据,不仅可以研究其文本内容,如情感分析、舆情分析等等,更可以结合地理位置进行分析,如居民活动空间研究[16]等等,提供了更多的微博数据的应用[17].

图11 微博数据存储在M ongoDB中的存储形式
猜你喜欢
房地产导刊(2022年10期)2022-10-18
作文大王·低年级(2022年3期)2022-03-19
读者(2021年20期)2021-09-25
现代信息科技(2021年21期)2021-05-07
电子制作(2018年2期)2018-04-18
小学生作文·小学低年级适用(2018年12期)2018-04-11
电子制作(2017年9期)2017-04-17
阅读时代(2017年3期)2017-03-11
校园英语·下旬(2016年2期)2016-03-18
环球时报(2009-09-29)2009-09-29
