
非连续性文本阅读能力指标初探
2018-11-06 01:23:04赵宁宁朱珅跃腾希纯李文婷
中国考试 2018年8期
赵宁宁 朱珅跃 腾希纯 李文婷
(1.北京师范大学,北京 100875;2.北京劳动保障职业学院,北京 100029)
非连续性文本(Non-continuous text)因其独特的实用性和图文组合的新颖性,已然成为公民在日常生活中常见的文本类型。随着国际测试的发展,非连续性文本由日常的生活领域,进入成人国民素养测试,成为阅读测试的重要组成部分。我国《义务教育语文课程标准(2011年版)》(以下简称《语文课标》)中正式提到非连续性文本,2017年全国高考语文中也有涉及非连续性文本的实用文本阅读的测试题。值得注意的是,除了语文学科之外,数学、地理、历史、物理、化学等学科领域都会涉及非连续性文本的阅读。因此,针对非连续性文本阅读能力的探究对于各学科都有非常重要的指导意义。非连续性文本具有什么特点?它对于学生的阅读能力提出了什么特殊要求?教师又应该按照什么能力指标来设定教学目标?这些问题引发了研究者对非连续性文本的研究热情。
从2011年开始,关于非连续性文本的研究持续增多,到2014年达到高峰。已有研究聚焦在以下3个方面:第一,研究关注了非连续性文本的阅读意义及阅读能力的培养和教学方法[1];第二,研究探究了我国学生在PISA测试中非连续性文本阅读能力偏低的原因[2];第三,对非连续性文本阅读能力展开研究,其中,大多数学者沿用PISA测试的观点,认为非连续性文本试题考查的是学生获取信息、处理信息和评价信息的能力[3-5]。总的说来,国内关于非连续性文本的研究还处于起步阶段,大多数研究集中在非连续性文本的教学内容、教学策略、答题策略方面的探讨,对非连续性文本的特点、类型及有关阅读能力、测试评价等研究不足。而且,已有关于非连续性文本的研究大多基于PISA测试所提出的非连续性文本概念及其阅读能力,缺乏对汉语语境下非连续性文本及其阅读能力的研究。
本研究基于阅读心理模型,追溯非连续性文本概念的历史及其本质特征,并参考已有的课程标准和有关的考试要求,初步制定一个非连续性文本阅读能力的指标体系;而后利用实证调查,根据学生的作答,对初步拟定的指标进行修订。
1 非连续性文本的概念界定
要建构非连续性文本的能力框架,首先要对非连续性文本的概念有一个清晰的认识,推断出由非连续性文本概念及其特征对阅读能力提出的独特要求。
1.1 非连续性文本的概念缘起
非连续性文本曾用名是“文档”(document)。20世纪末,ETS的专家Mosenthal等建立了“文档易读性公式”(the PMOSE/IKIRSCH document readability formula)。在Mosenthal等的理论中,文档包含清单(list)、表格(tables)、图表(diagrams)、计划表(schedules)、目录(catalogues)、索引(indexes)、柱状图(forms)等[6]。在社会科学领域,文档的定义是“用文字、图形、符号、声频、视频等技术手段记录人类知识的一种载体”[7]。
非连续性文本阅读最早出现于针对成人开展的国际阅读测试。20世纪90年代,国际成人素养测试(The International Adult Literacy Survey,IALS)把文本分为连续和非连续的[8],其中:连续性文本是指像散文一样由文字组成的句子、段落的文本;而非连续性文本是按照文档的格式组成的文本,包含了如表格、图表、计划表和柱状图等形成的多种段落。联合国教科文组织统计局(UNESCO Institute for Statistics,UIS)组织的素养评估和监控项目(Literacy Assessment and Monitoring Programme,LAMP)把文本分为散文和文档,其中:散文是指连续性文本,文档是指“非连续性领域、计算能力领域”[9];这个测试规定文档就是不连续的文本(discontinuous texts),通常是指不刻意组织的段落,包含了如表格、图表、计划表和柱状图等形成的段落。可见,20世纪90年代初期,国际上已经出现了“不连续的文本”一词。
2009年PISA测试框架中出现了非连续性文本的概念,包括列表、表格、图表、广告、时间表、目录、索引和表格等。与非连续性文本相对的概念是连续文本(continuous text)、混合文本(mixed text)和多重文本(multiple text)[10],其中后两者是连接电子阅读与书面阅读的重要文本形式。
总的说来,最初的非连续文本概念主要是针对成人素养测试开发的,相对连续性文本提出来的。我国2011年版的《语文课标》针对非连续性文本阅读能力提出的要求是:“阅读简单的非连续性文本,能从图文等组合材料中找出有价值的信息;阅读由多种材料组合、较为复杂的非连续性文本,能领会文本的意思,得出有意义的结论。”[11]可见《语文课标》是把文字和图表组合起来的整体材料视为非连续性文本,与PISA测试中的非连续性文本仅指图或表的概念有所差异。本研究是针对我国语境下的非连续性文本的阅读能力进行指标建构的。
1.2 非连续性文本的内涵
我国语境下的非连续性文本具有如下特征。
第一,非连续性文本是一个完整的组合。文本是什么?在文体学中,文本指的是依据一定的语言衔接和语义连贯规律而组成的整体语句或语句系统[12]。由此分析,非连续性文本不是只指表或图,也不仅仅指处于非连续性文本中的文字,而是由图表和文字共同构成的完整文本。非连续性文本的阅读材料,是在承载特定传递任务的前提下,由各种类型的文本构成连贯而完整的意义系统,读者对于文本的理解无须额外的材料就能完成。
第二,非连续性文本的“不连续”包含了形式和内容上的不连续。我国多数学者表示,只要文本存在间断性(无论篇章形式或语义逻辑)都可以称为非连续性文本。黄德新认为,除了用图表等呈现外,还可以用不连续的句子或段落呈现[13]。国内大多数的研究认为,非连续性文本包括形式上的非连续和文意上的不连续两类。
1.3 非连续性文本的外延
由于国内外学者对于非连续性文本的界定有所不同,因此在分类方面也有所差异。
Kirsch和Mosenthal按照组成形式将非连续性文本分为4类:第一类为矩阵式(Matrix)非连续性文本,指纵横排列的二维数据表格;第二类为图表式(Graphic)非连续性文本,指饼状图、柱状图、折线图等,它们以直观的形式呈现数据结果,方便读者比较分析;第三类为位置性(Locative)非连续性文本,指地图类文本,能够较为直观地展示人口和地点的位置、事物的方向或描述不同的地理区域特征;第四类为登记式(Entry)非连续性文本,是需要读者自己提供信息的文本[14]。在国际研究中,非连续性文本的基本单位是列表,包括简单的列表、组合列表、交叉列表、嵌套列表4种;其中,后3种非连续性列表是在简单的矩阵式列表基础之上发展起来的,不同的列表形式通过各种组合生成了形态各异的非连续性文本。
在国内,研究者按照图文形式对非连续性文本进行分类。雍殷梅提出把非连续性文本按图表的不同形式分为表格类、图表类、图画类以及图文结合类[15]。黄德新将非连续性文本分为两大类:第一类是图文结合式的文本,以图表等为文本信息内容的载体,体现为形式结构上的不连续;第二类是文字型文本,多为片断性、不完整段落表述,这类文本“每一段文字不相关,但可能共同说明同一个问题,体现在意义上的不连续”[13]。
通过对文献的研究发现,Mosenthal和Kirsch的分类主要针对成人阅读,侧重对图的形式分类,只包含列表组成的“非连续性”,忽视了非连续性文本中的“文本”内容。国内研究者按照图文类型进行分类的方法更加符合我国对非连续性文本的概念界定。
2 非连续性文本阅读能力的初步构建
本研究以一般阅读心理模型为基础,参考国内外的已有研究成果,初步建构非连续性文本的阅读能力框架。
2.1 一般阅读心理模型
心理学家提出了多种学生阅读心理模型,包括自下而上模式(bottom-up model)、自上而下模式(top-down model)和相互作用模式(interative model)。相互作用阅读模型基于建构主义学习理论和读者主体构建理论,认为阅读的核心就是建构,读者基于自己的先前知识进行阅读[16]。相互作用的阅读模型也有很多分支,本研究采用Perfetti等学者的观点,该理论认为阅读主要是由文字识别、理解过程、先前知识3个组块交互而成[17],见图1。
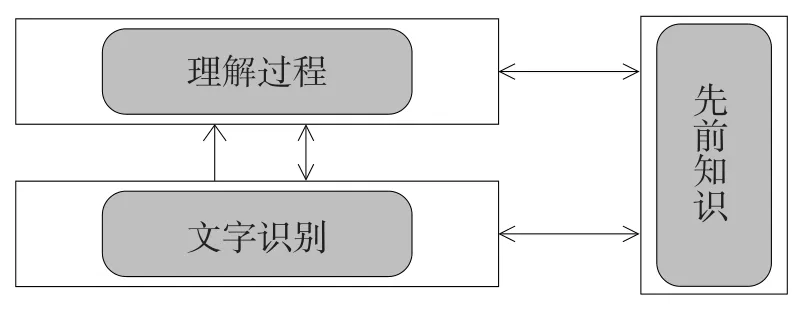
图1 一般的阅读心理模型
文字识别(word identification),是指对文字表述的理解,包括正字法(orthographic)、语音(phonological)等识别,是对每个字词的音、形、义的学习和把握。先前知识(prior knowledge),是指在阅读过程中,学习者使用先前知识来把握文本,包括词汇量、语法、语义语音等语言知识和读者已有的对生活经验的理解。理解过程(comprehension processes),包括句子层面的理解、篇章层面的理解、情景层面的理解3个层级,从句子、篇章再到情景是一个由低到高的阅读过程,阅读者在篇章层面和情景层面需要运用到有关的推论能力。
图1中箭头的指向代表着交互的方式。在文字识别和理解过程中都需要先前知识,先前知识对阅读的影响包含着自上而下和自下而上方式,由于是同时发生的,所以箭头是双向的。文字识别是理解过程的基础,是较为低层级的阅读,箭头是向上的。在理解过程中也会对文字识别的理解产生影响,因此有向下的箭头。
2.2 非连续性文本的阅读心理模型
基于如上的一般阅读心理模型,我们假设非连续性文本的阅读能力包括以下3个组块。
第一,信息识别能力组块,包括文字识别能力和图表识别能力。文字识别能力,这是任何阅读过程都需要的基本能力。非连续性文本的文字识别能力跟一般的阅读模型是一致的,阅读者需要运用语言知识基础,识别出文字是一个有意义的符号,而非一个无关紧要的符号。图表识别能力,是非连续性文本特有的识别能力,是针对文本非连续的特点提出的独有能力。在非连续性文本的阅读中,除了要对文字进行识别之外,还要针对非文字符号的图表和不同文本组织形式进行识别:1)识别非文字符号,即图表类符号。在阅读过程中,阅读者需要用到图表知识,知晓图表是一个特定意义的载体,而非无关紧要的符号,这点对于非连续性文本的阅读来说尤为重要,也是区别于连续性文本的特殊能力。2)识别不同文本组织形式,即非连续性文本的组合形式。在阅读过程中,阅读者需要知晓文本各部分组织的意义,清楚文字顺序及其组合是具有一定意义的。
第二,先前知识组块,分为字词知识、图表知识、生活经验3类。在非连续性文本阅读过程中,阅读者同样需要字词知识和有关语法知识等,这与一般阅读过程是一致的。除此之外,图表知识对于阅读非连续性文本而言,也是非常重要的,如看地图的时候,懂得地图南北图例所代表的意义,包括常见的图中比例尺、表中纵轴和横轴的意义等知识。再者,阅读者需要一定的相关生活经验知识。Mosenthal等在“理解表格”(Understanding forms)中提及,阅读者从自己的先前知识中提取需要的信息,并进行进一步整合[14]。
第三,阅读理解组块。在一般模型中,阅读理解包括句子层面、篇章层面、情景层面的理解。然而,这一划分方式没有体现非连续性文本的独特性。为建构体现非连续性文本阅读理解组块的能力模型,本研究基于对IALS、LAMP、PISA等测试以及我国语文课程标准和有关考试的分析,初步建构出非连续性文本的阅读理解能力一级指标包括定位提取能力、推理整合能力和评价运用能力,二级指标包括图表理解能力、定位检索能力、信息提取能力、逻辑运算能力、推论判断能力、归纳概括能力、评论反思能力和运用表达能力,见表1。据此构建了非连续性文本阅读能力结构模型,见图2。
定位提取能力可细分为图表理解能力、定位检索能力和信息提取能力,其中:1)图表理解能力是在非连续性文本阅读中对文本中的图、表等各种非语言符号的解读能力。非连续性文本包含了较为抽象的数据图文类的文本,其图文所表达的信息往往不是文字的简单呈现,而是隐匿在图表的数据之中。阅读者在阅读过程中要把数据表格、图片信息转换为相应的文本语言,而图表信息包括了所包含的内容以及表达形式。2)定位检索能力和信息提取能力在大多数情况需要同时运用。非连续性文本有特定需要传递的信息,阅读者可根据特定的需要对信息加以提取。首先,阅读者需要在文本中定位所需信息的位置;其次,能够检索或识别所需要的信息要素;最后,能在较为复杂的文本中选择并匹配特定目的的信息,并能区分干扰信息和有用信息。非连续性文本偏重科学性,阅读者在定位检索信息的过程中需要关注概念的类属、文本的呈现形式等。
推理整合能力可细分为逻辑运算能力、推论判断能力和归纳概括能力,其中:1)逻辑运算能力是在定位提取基本信息的基础上,将图表数据进行逻辑转化和逻辑运算,把图中信息、图例、数据等进行逻辑加工的能力。在阅读非连续性文本的过程中,需要对图表等信息进行转换,挖掘并整合图表中的信息,才能完成相应的任务。2)推论判断能力是指针对初步提取的信息进行推理和判断,分辨与区分相似信息,并能推断出符合标准的新信息;或者能够按照一定标准,将同类信息归类。3)归纳概括能力是指根据特定的任务需求,针对文本中不同材料来源的信息进行整合与归纳,通过对所有材料的审视与分析,概括出所有材料中所共同传递的信息。
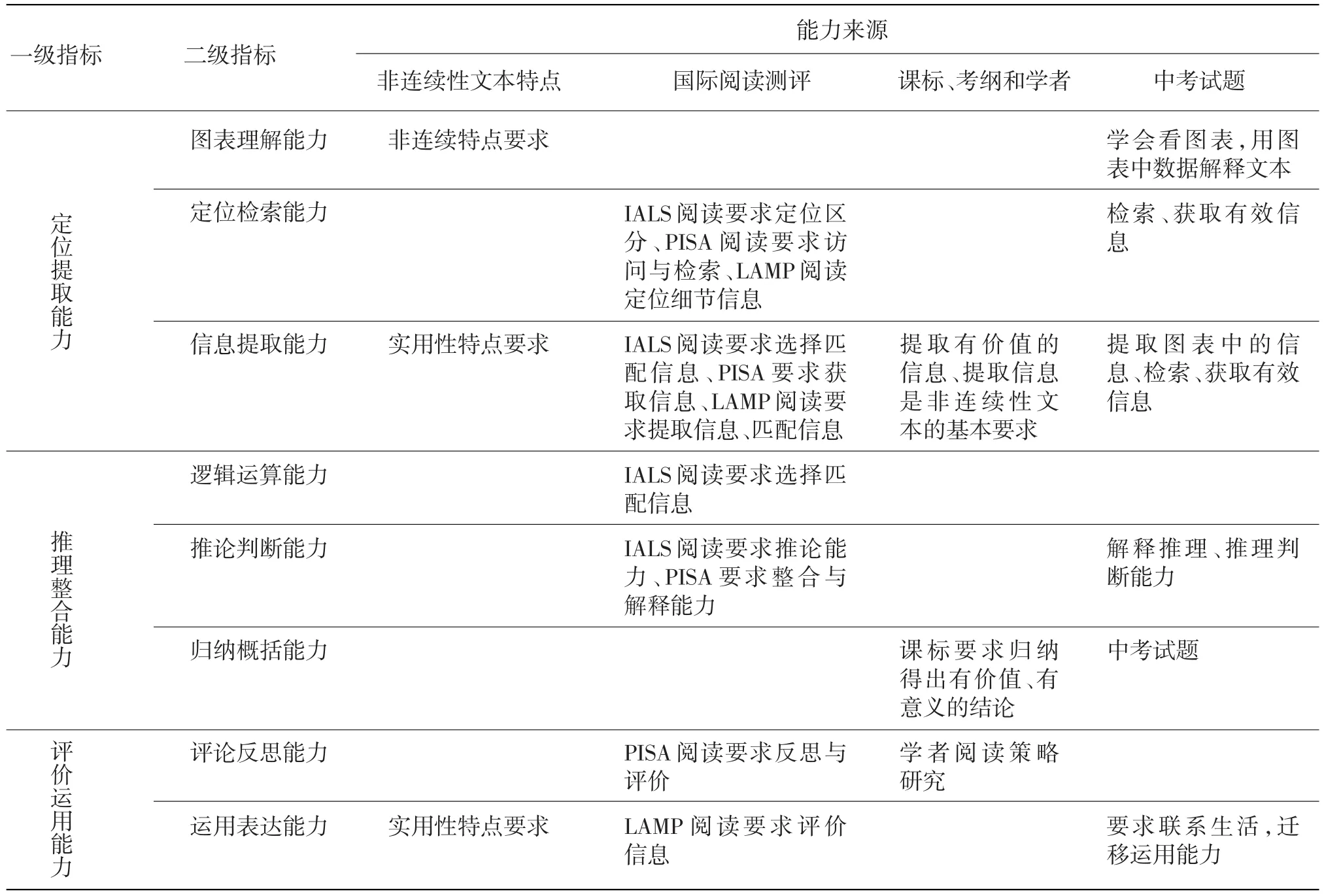
表1 非连续性文本阅读能力二级指标建构小结表

图2 非连续性文本的阅读能力模型
评价运用能力可细分为评价反思能力和运用表达能力,其中:1)评价反思能力,是指依靠理性判断和科学思考,凭借文本内在的证据和阅读者已知的外在准则,客观公正地对文本内容进行价值评估的能力。2)运用表达能力,是指利用非连续性文本中的有关信息,进行信息的整合和新一轮信息传递的能力。非连续性文本中的运用表达,不是偏重写作语言的表达,而是侧重信息的整合和运用,能够将阅读中获得的信息运用于解决生活与工作中的问题。
在此基础上,结合中考语文试题,构建了非连续性文本阅读能力的三级指标,见表2。
3 非连续性文本阅读能力的修订
为了进一步检验连续性文本和非连续文本阅读能力的差异,本研究采用大声思维法(thinkaloud)针对其中的阅读能力指标进行逐一访谈,试图修订基于理论建构的能力指标,并分析学生在阅读连续和非连续文本中所需要的阅读能力的差异。
本研究选取同样的文字,建构成非连续性文本和连续性文本,选取18位来自小学和中学的学生(学习成绩位列班级高、中、低3个级别的各6位)进行作答。
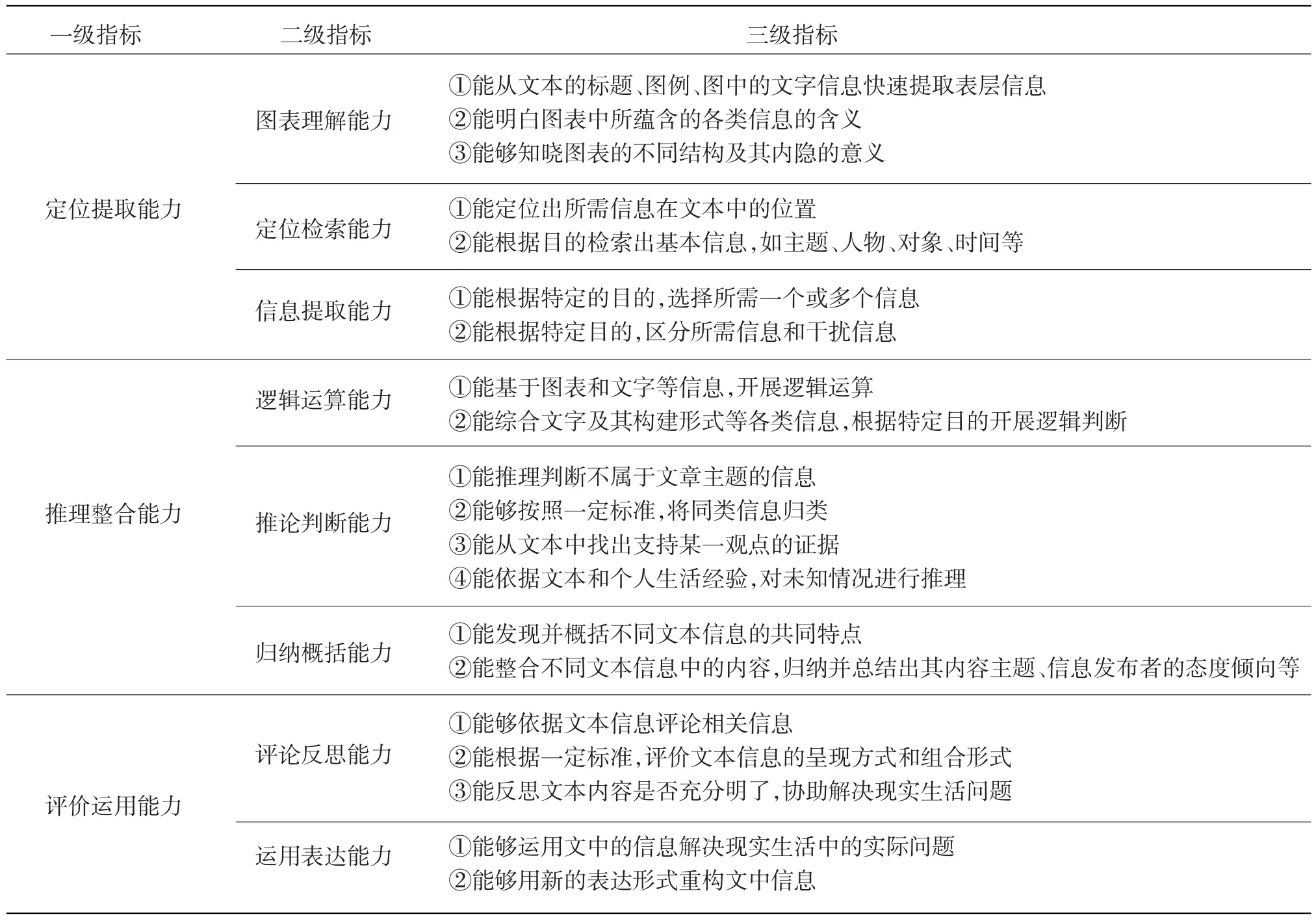
表2 非连续性文本阅读理解能力的指标体系
首先,与连续性文本相比,非连续性文本更加依赖于先前知识组块。我们区分了有生活经验和无生活经验两类学生。访谈结果显示,先前知识组块中的背景知识对非连续性文本阅读存在重要影响。在学生能力相同的情况下,有背景知识的学生能够完整地提取所需信息;提取信息不完整的学生多数从没听说过非连续性文本所指涉的事物。在访谈问题“哪一文本更简单”的回答中,初中组有背景知识的学生多数选择了非连续性文本;在小学组的学生多数都为无生活经验的,只有一位有生活经验的学生选择了非连续性文本。通过学生的大声思维访谈证实,在非连续性文本的阅读中,图表的组织形式和生活经验知识是影响学生提取信息的主要因素。
其次,与连续性文本相比,非连续性文本的定位提取能力、推论整合能力显得更为重要。在访谈过程中,研究者询问学生“哪类文本信息能更快速被找到”,其中有14人认为是连续性文本,4人认为是非连续性文本。研究发现,在控制了字词难度的前提下,任何学段的学生都能全部找出在连续性文本中的信息;而在非连续性文本阅读测验中,有5位学生没有找到全部信息,尤其是没有找到图表中所蕴含的信息。访谈结果表明,同等能力水平的学生在阅读时,提取非连续性文本的信息比提取连续性文本的信息难度更大。通过进一步的访谈发现,在非连续性文本的阅读过程中,学生所遇到的困难在于不能将图表中的信息转化,无法理解非连续文本的组织结构及其意义,由此表现为学生对非连续性文本的图表理解能力、逻辑运算能力和推论判断能力较差。根据访谈结果,结合非连续性文本的结构特征,我们将定位提取下的图表理解能力指标中的第①条修改为“能够区别出图表的不同结构及其所要表达的特殊意义”,以此要求阅读者了解每个图形结构的特点、所要表达的含义以及在此出现的作用等,从而形成对表格数据、坐标曲线等的敏感度。
4 总结与反思
总的说来,本研究以一般阅读心理模型为基础,结合非连续性文本的概念及其特征,并基于已有关于非连续性文本的研究成果,初步建构了非连续性文本的阅读能力结构,而后结合对学生的访谈,逐一检验了非连续性文本的阅读能力指标。
本研究初步提出由识别组块、先前知识组块和阅读理解组块构成的非连续性文本阅读能力模型,其中,重点细化了阅读理解组块中的阅读能力指标,为后续的非连续性文本的阅读教学和阅读测试提供了一个初步的框架。后续还需要利用大规模的数据进一步验证其指标体系的信度和效度。
猜你喜欢
美育学刊(2023年1期)2023-02-18 03:04:06
中国海上油气(2021年2期)2021-06-09 08:13:46
厦门航空(2021年4期)2021-03-27 09:43:52
作文成功之路·小学版(2020年9期)2020-10-28 08:07:14
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:34
疯狂英语·读写版(2020年2期)2020-04-14 04:58:48
新世纪智能(语文备考)(2019年12期)2020-01-13 06:04:26
厦门理工学院学报(2016年1期)2016-12-01 04:50:51
中学生数理化·七年级数学人教版(2016年4期)2016-11-19 08:41:24
中国海上油气(2016年1期)2016-06-09 08:58:49
