
面向HEVC的运动估计快速算法和硬件架构
2018-11-05 07:56陈清坤施隆照高小虹
福州大学学报(自然科学版) 2018年5期
陈清坤,施隆照,黄 博,高小虹
(福州大学物理与信息工程学院,福建 福州 350116)
0 引言
视频编码技术广泛应用于视频会议、安防监控和远程医疗等领域. 随着视频分辨率的提高,视频编码标准H.264的压缩效率已经无法满足需求. 新一代视频编码标准HEVC通过引入一系列新技术,在H.264基础上提高了一倍的压缩效率,但也造成较高的复杂度[1]. 在视频编码过程中,运动估计也是最具挑战和编码时间最高的部分. 在和运动估计相关的运算中,HEVC与上一代压缩标准H.264相比增加更灵活的特征,包括高级运动矢量预测技术AMVP(advanced motion vector prediction),更多不同尺寸预测单元PU (prediction unit),以及更大的PU等[2]. 这些新特征提高了运动估计编码效率,但也增加了运动估计复杂度. 同时,由于AMVP和更大的PU的出现,编码器硬件需要更大的内存空间. 因此,针对硬件实现设计快速算法降低运动估计过程的复杂度,用硬件加速运动估计过程是非常有必要的.
目前已有的HEVC运动估计算法优化思想可分为三类: 一是基于HEVC参考软件中提供的TZ(test zone search)快速搜索的优化算法,例如, 文[3]用旋转六边形搜索模板替代钻石搜索模板,文[4]用三种不同模板替换细化搜索的模板,文[5]优化了起始搜索过程,这些文献都是通过减少搜索点数,降低TZ搜索的复杂度,但优化后的搜索策略仍然过于复杂,并没考虑硬件实现的难易程度; 二是基于经典运动估计快速搜索的改进算法,例如, 文[6]是基于传统六边形搜索的快速搜索算法,文[7]在传统钻石搜索的基础上提出的star diamond搜索算法,尽管这些文献都能有效减少运动估计时间,但并未考虑HEVC引入更大预测单元,不同块大小的迭代搜索复杂度差异较大,不利于硬件电路设计等问题; 三是新提出的综合优化快速搜索算法,例如, 文[8-10]使用运动矢量预测、自适应搜索模板和提前终止等多种技术减少运动估计复杂度,而都保持性能基本不损失,但不确定的搜索路径、不规则的数据读取和不适合并行处理都无法发挥硬件的优点. 因此,已有HEVC运动估计算法多基于软件平台考虑,仍不适合硬件实现.
目前已有的运动估计硬件架构的设计思路主要有两种. 一种是基于全搜索算法的硬件架构,例如, 文[11]通过分层全搜索架构来减少复杂度和片内带宽,文[12]提出的架构能有效提高吞吐率,但这些文献优化后的架构仍然需要很长的处理时钟周期. 另一种是基于快速搜索算法的硬件架构,例如, 文[13-15]提出的架构都能够用较少的时钟数完成运动估计,但仍然存在很多不足. 其中, 文[13]过高的并行度和较低的数据复用,造成很高的片内存储器访问; 文[14]提出的架构最大只支持16 px×16 px的预测单元,无法支持HEVC最大64 px×64 px的预测单元; 文[15]需要频繁读取参考像素,造成了较大的片外存储器带宽,同时增大了硬件功耗. 因此,现有的架构仍无法满足HEVC中运动估计的要求.
针对上述讨论,本研究提出确定共享搜索区域的方法,硬件中使用较大的共享搜索区域,提高数据复用率,减少频繁数据访问和庞大的数据读取对带宽的压力. 进而,在传统钻石搜索算法的基础上,提出面向HEVC且适合于硬件实现的改进的钻石搜索算法,同时算法性能损失基本可以忽略. 最后,提出改进的钻石搜索算法的硬件架构,通过减少数据读取时间、提高硬件资源利用率以及采用并行处理的方式加速运动估计过程,使周期数比现有文[14-15]更少.
1 共享搜索区域的确定
在硬件设计中,参考帧缓存需要较大的存储空间,所以一般存储在外部的大容量DRAM中. 在运动估计过程中,所需要的搜索区域像素需要提前缓存到片内的SRAM中. 不同预测块的搜索起始点随着预测矢量dmvp的改变而变化,每一块的搜索区域并不相同. 频繁的数据访问将造成巨大的片外参考像素带宽,更严重增加了硬件系统功耗. 为提高数据复用和减少片外参考像素带宽,硬件实现时可以用较大的SRAM存储更大的搜索区域,使CTU(coding tree unit)中不同PU能够复用该区域,实现搜索区域的共享[16]. 但实现共享搜索区域需要限制PU的搜索范围,从而可能会造成编码性能的降低,因此需要合理设计确定共享搜索区域的大小和位置.
本共享搜索区域方案是利用空间域相邻块运动矢量的相关性预测当前CTU内像素整体的运动趋势. 假设以当前CTU为中心,搜索区域上下左右偏移范围各为Npx,同时CTU大小为Mpx. 在宽度为(2×N+M) px的正方形搜索区域基础上,将中心点相对CTU偏移dmv_CTUpx,其中dmv_CTU由邻块A、B、C、D和E运动矢量(如图1所示)的中值确定. 利用空间域相邻块运动矢量的相关性预测当前CTU内像素整体的运动趋势,通过共享搜索区域的整体偏移,减小视频内容对N的影响. 共享搜索区域的大小需要根据统计分析确定N. 实验统计在编码过程中,不同N时PU的运动矢量dmv在共享搜索区域内的频率. 实验结果如图2所示,N从0到100 px增加的过程中,dmv在共享搜索区域内的频率不断增加. 当N大于64 px时,不同视频内dmv在共享搜索区域内的频率都超过98%. 综合考虑性能增益和硬件资源消耗,将N、M均设为64 px,此时,共享搜索区域为宽度192 px的正方形搜索区域.

图1 CTU邻块Fig.1 CTU adjacent block

图2 dmv在共享搜索区域内的频率分布Fig.2 Frequency distribution of dmv in region
2 改进的钻石搜索算法
钻石搜索算法是经典的快速搜索算法,采用先大钻石搜索后小钻石搜索的搜索策略,可以减少搜索点数,降低运动估计复杂度. 但由于HEVC使用更大的预测单元,大钻石搜索在迭代过程中,每次迭代大尺寸(64 px×64 px) PU的复杂度会远大于小尺寸(8 px×4 px) PU. 其次,没有限制的迭代次数是不适合于硬件时序安排的. 因此,在传统钻石搜索算法的基础上,提出改进的钻石搜索算法.
搜索模板对算法的复杂度和硬件实现都有关键性影响. 在硬件实现中,往往采用并行的方式实现运动估计,因此处理运动估计的处理单元(PE)是给定的. 针对这个特点,大块的CU(coding unit)使用小钻石搜索模板,小块CU采用米字型搜索模板,如图3和图4所示. 首先,CU为64 px×64 px、32 px×32 px和16 px×16 px时,PU尺寸较大,单次绝对误差和SAD(sum of absolute difference)计算复杂度较高. 因此,选用5点小钻石搜索模板. 当CU为8 px×8 px时使用9点的米字型搜索模板,SAD计算复杂度低, 通过增加搜索点数减少迭代次数. 其次,通过自适应模板选择,平衡不同块大小搜索迭代过程的复杂度,便于硬件电路兼顾处理速度和高硬件资源利用率. 再者,由于两种模板上下左右偏移一个像素,对于npx×mpx的PU,两种搜索模板需要读取的有效参考像素均为(1+n+1)×(1+m+1)px. 两种模板有相同的有效数据量和很高的数据复用率,因此能进一步简化硬件中数据预读取过程和减少片内参考像素带宽.

图3 小钻石搜索Fig.3 Small diamond search

图4 米字型搜索Fig.4 Meter-shaped search

图6 算法流程图Fig.6 Flow chart of algorithm
本文算法的搜索过程. 选择以AMVP技术得到的dmvp作为搜索起始点. AMVP技术能使起始点更接近于全局最优点,从而能减少搜索的点数和避免陷入局部最优对性能的影响[1]. 为使dmvp落在共享搜索区域内,需要对dmvp预处理. 在迭代过程中,使用式(1)为搜索模板的各个点估计率失真代价选择最优的搜索点. 当代价最小点出现的位置在每次迭代中搜索模板的中心点或者搜索区域边界时结束搜索. 同时,由于普通图像不同块之间的运动具有相关性,分析运动矢量差值dmvd,设置了最大迭代次数,避免不必要的迭代过程. 实验统计编码过程中f(x, |dmvd|≤x)的频率分布情况. 实验结果如图5所示,随着x的增加,f(x, |dmvd|≤x)的频率先迅速增加,后增速变缓. 综合考虑复杂度和f(x, |dmvd|≤x)的频率的分布情况,因此将最大迭代次数设置为64次.
J=SAD(dmv)+λ=motionR(dmv-dmvp)
(1)
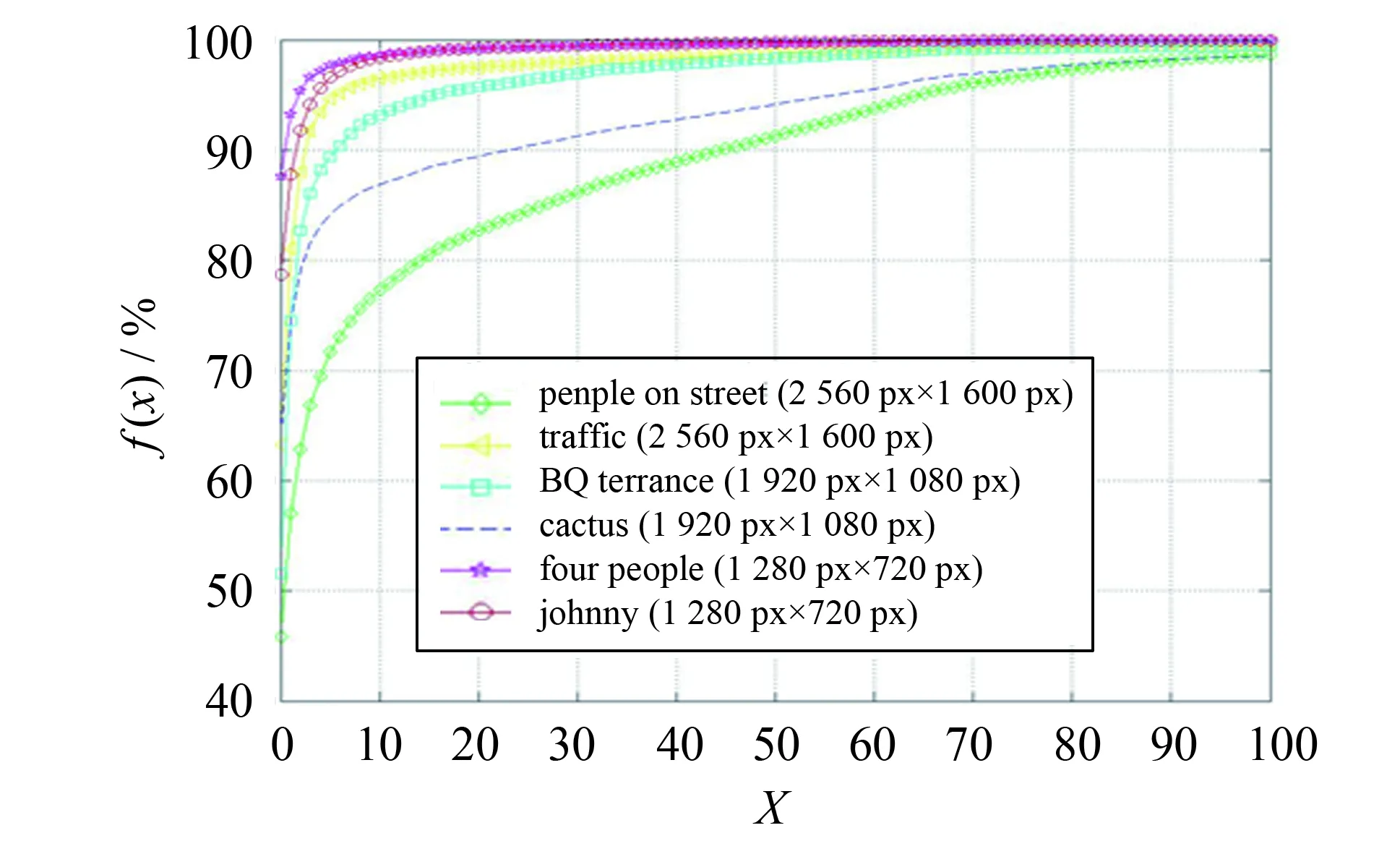
图5 f (x, |dmvd|≤x)的频率分布Fig.5 f (x, |dmvd|≤x) frequency distribution
改进的钻石搜索算法根据预测单元大小自适应选择米字型搜索模板和小钻石搜索模板,使用了共享搜索区域,设置最大迭代次数,具体搜索过程如下,算法流程如图6所示.
1) 初始化vbest_mv、Jbest和Citeration.
2) 根据CU大小选择搜索模板,分别估计模板各点率失真代价. 当CU为8 px×8 px时使用米字型搜索模板,当CU为64 px×64 px、32 px×32 px和16 px×16 px时使用小钻石搜索模板.
3) 迭代判决. 根据代价最小值所在的位置、最优块是否在搜索区域边界和Citeration判断是否结束搜索.
3 改进的钻石搜索算法仿真和性能分析
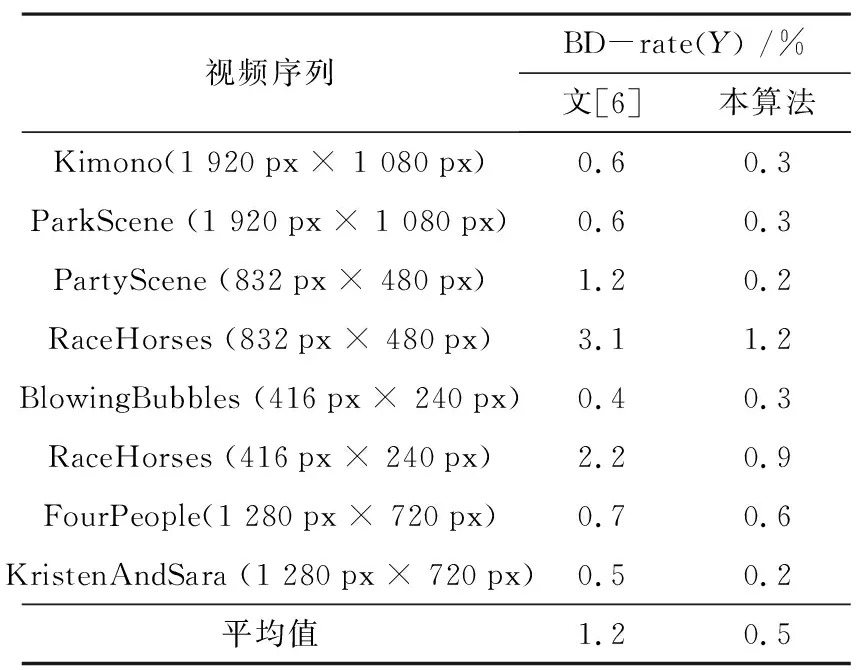
表1 比较编码性能
以HEVC参考软件HM16.7作为实验测试平台,采用BD-rate[17]来评估算法性能. 为验证算法的鲁棒性,视频序列包括了不同的分辨率和运动情况的公共测试视频序列[18]. 量化参数选择22,27,32和37,视频编码100帧,配置文件选择lowdelay_P. 实验结果如表1所示,在PartyScene和KristenAndSara等运动缓慢的视频序列中,编码性能基本与原始HM16.7性能一致. 本算法相比原始HM16.7平均BD-rate(Y)仅仅增加0.5%. 对于最坏的情况下,在RaceHorses (832 px×480 px)视频内物体运动剧烈,由于共享搜索区域对搜索区域的限制会影响性能,但相比原始HM16.7,BD-rate(Y)仅增加1.2%. 因此,证明本编码器性能基本不损失, 但本算法更适合于硬件实现.
为进一步证明本算法性能的有效性,将本算法与文[6]做比较. 与文[6]的编码性能对比如表1所示. 文[6]相比原始编码器平均BD-rate(Y)增加1.2%,平均性能损失高于本算法. 且在不同视频序列中,本算法编码性能都能优于文[6]. 因此,证明本编码器性能的有效 性.
4 改进的钻石搜索算法的硬件架构
传统钻石搜索常采用9个PE的硬件架构[14]. 首先,该架构每个PE处理1个搜索点的SAD,对于大钻石搜索9个点,但对小钻石搜索5个点时,此时有4个PE处于空闲状态. 其次,该架构主要针对最大预测单元为16 px×16 px,无法支持预测单元64 px×64 px. 另外,该架构需要频繁的数据预读取,对带宽、功耗和运动估计效率都是不利的.
4.1 新的硬件架构
在传统钻石搜索硬件架构的基础上,针对本算法进一步提出新的硬件架构,如图7所示. 主要包括控制模块、初始化PU模块、地址生成模块、参考像素RAM、原始像素RAM、参考像素预处理模块、原始像素预处理模块、多个PE模块、计算运动矢量差值代价模块、运动矢量生成模块、比较模块和迭代判决模块.

图7 硬件架构Fig.7 Hardware architecture
新硬件架构采用10个PE. 根据PU的尺寸大小,既可以每个PE单独处理一个搜索点的SAD,又可以2个PE组合成更大的处理单元计算一个搜索点SAD. 使用米字型模板搜索时,每个PE处理1个搜索点,此时只有PEC1模块是空闲的. 使用小钻石搜索模板时,PEU和PEUL、PEB和PEBR、PEL和PEBL、PER和PEUR、PEC0和PEC1分别组成更大的处理单元,分别计算5个搜索点的SAD,此时所有的PE都处于工作状态.
处理单元PE模块是核心计算模块,综合考虑处理能力、利用率和片内存储架构,PE选择用加法树完成8 px (宽度)×4 px (高度) SAD累加.在CU为8 px×8 px中,当PU宽度为4时,PE只有50%的资源利用率. 但当PU宽度不为4时,PE有100%的资源利用率. 同时为了能够实现所有2Npx×2Npx,2Npx×Npx和Npx×2Npx形式PU的复用,8 px×4 px SAD计算结果还需要累加才能得到更大尺寸PU的SAD. 另外,对于CU大小大于8 px×8 px,可以通过组合两个PE为更大16 px×4 px SAD的处理单元. 因连续的行读取比较方便,这样只要读取4行的数据就可以了. 这种灵活的处理方式,使PE在处理从8 px×8 px到64 px×64 px的PU时,都有较高的处理效率,PE模块结构如图8所示.
对于其它的模块,设计思路如下:
① 控制模块使用状态机控制状态转换; ② 初始化PU模块根据CTU和CU信息计算当前PU宽度、高度和位置等信息; ③ 参考像素RAM存储192 px×192 px; ④ 原始像素RAM需要存储64 px×64 px; ⑤ 地址生成模块产生参考像素RAM和原始像素RAM的地址信号; ⑥ 参考像素预处理模块和原始像素预处理模块,为每个PE单元选择对应的参考块像素和当前块像素; ⑦ 比较模块用于确定代价最小值所在的位置; ⑧ 迭代判决模块判断是否需要继续迭代; ⑨ 计算运动矢量差值代价模块计算各个搜索点的dmvd代价.
4.2 时序安排
整个运动估计时序安排包括初始化、SAD计算和迭代判决. 图7硬件架构中,初始化过程需要3个时钟周期,用于计算搜索起始点和初始化PU的相关信息. 另外,每个CTU需要额外48个时钟更新参考像素RAM和原始像素RAM内数据.
SAD计算时间取决于PU块大小. 本架构使用8 px×4 px SAD和16 px×4 px SAD作为基本处理单元,8级全流水实现PE数据获取到SAD的计算. 当PU为8 px×4 px和16 px×4 px时,SAD计算都只需要8个时钟周期. 当PU为64 px×64 px时,基本处理单元选择16 px×4 px SAD,需要8+(4×16)-1=71个周期完成SAD计算. PU越大,SAD计算时间越长. 在计算SAD的同时,还并行计算搜索点dmvd的代价.

表2 迭代次数
迭代判决需要7个周期. 首先SAD与dmvd代价求和得到总的代价,然后需要3个周期比较代价最小值所在的位置,最后还需要3个周期判断是否继续迭代. 完整运动估计的周期还和迭代次数有关,迭代次数越多,周期越长. 实验统计搜索迭代次数I和迭代次数小于等于3的频率P,统计结果如表2所示.
平均迭代次数只要2.248 3次,迭代次数小于等于3的频率达到了86.33%,即对于大部分PU最多3次迭代就能找到最优匹配块. 迭代次数以3为例,不同尺寸PU的运动估计周期数如表3所示.

表3 不同尺寸PU的周期数
5 改进的钻石搜索算法的硬件架构综合结果
以Synopsys VCS工具验证功能的正确性,运用FPGA器件(Stratix IV系列中EP4S40G2F40I1芯片)在QUARTUS II开发平台中完成综合. 综合结果表明,仅需要17 622个ALUTs,14 122个registers,memory 425.984 kbits,4个DSP(18 bit)的硬件资源,最高工作频率达到317.56 MHz.
编码实时性分析. 如果只考虑对称划分模式,且只有单一参考帧,处理一个64 px×64 px CTU需要26 523个时钟周期. 1 080 px分辨率视频图像一帧需要13.4 M个时钟周期. 720 px分辨率视频图像一帧需要6.0 M个时钟周期. 本架构能实现1 080 px @23.7帧·s-1或者720 px @53.2 帧·s-1. 编码性能如表1所示,相对HM性能基本没有损失.
表4为本实验结果与相关文献比较情况,文献[14-15]都是在钻石搜索算法基础上提出的改进算法和硬件架构,但只处理16 px×16 px的PU块,因此比较了PU为16 px×16 px的时钟数.

表4 与不同文献硬件架构比较
文[14]运动估计每次只要170个时钟周期,因为合理安排时序,将大部分的预读取时间隐藏在流水线中,但仍然有20个周期是用来等待预读取数据结束. 并且该架构只能支持固定16 px×16 px的PU尺寸. 本架构通过共享搜索区域,不需要频繁预读取像素,仅需要66个周期,就能完成16 px×16 px块的预测,且能够支持所有对称划分模式.
文[15]搜索区域为96 px×96 px,对固定16 px×16 px的PU进行4∶1的下采样,减少硬件资源和复杂度,存储资源仅仅用46 kbits. 而本研究最大支持64 px×64 px的PU,共享搜索区域为192 px×192 px,更大的PU和更大的搜索范围,因此需要较大的存储资源. 而本研究逻辑资源略低于文[15],能够用更少的时钟周期完成运动估计,且本架构有更高的主频.
6 结语
1) 提出一种结合算法和硬件实现的优化运动估计方法. 该方法根据硬件资源消耗和预测单元大小自适应地选择搜索模板,通过硬件搜索区域共享实现有效数据复用,并减少参考像素带宽.
2) 基于该自适应搜索算法,进一步提出新的硬件架构. 新硬件架构采用10个处理单元的架构,PE既可以作为独立的处理单元计算一个搜索点的SAD,又能够将2个PE组合成更大处理单元. 通过灵活处理单元的选择,对从8 px×8 px到64 px×64 px不同尺寸的PU,该架构都有较高的处理速度和资源利用率.
3) 仿真结果表明,本算法与参考代码HM16.7相比较,编码性能基本不损失,但更适合于硬件实现. 用Altera的 Stratix IV系列芯片在QUARTUS II里逻辑综合, 得到的最大工作频率为317.56 MHz,能够实现1 080 px @23.7帧·s-1的吞吐率.
猜你喜欢
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
学生天地(2020年15期)2020-08-25
小读者(2019年20期)2020-01-04
小哥白尼(趣味科学)(2019年1期)2019-04-12
中国惯性技术学报(2019年6期)2019-03-04
小猕猴智力画刊(2018年9期)2018-10-24
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
火控雷达技术(2016年3期)2016-02-06
电测与仪表(2015年15期)2015-04-12
河北科技大学学报(2015年5期)2015-03-11
