
网络家用纺织品资源抽取方法
2018-10-30 07:42吴志明张远鹏
纺织学报 2018年10期
杨 娟, 吴志明, 张远鹏
(1. 南通大学 纺织服装学院, 江苏 南通 226019; 2. 苏州大学 纺织与服装工程学院, 江苏 苏州 215123; 3. 江南大学 纺织服装学院, 江苏 无锡 214122; 4. 南通大学 医学信息学系, 江苏 南通 226001; 5. 江南大学 数字媒体学院, 江苏 无锡 214122)
纺织业是我国重要的传统支柱产业,“十三五”规划对纺织工业进行了定位调整,强调了信息化技术的深入应用[1]。家用纺织品作为纺织业终端用途中的重要组成部分占有相当一部分比重。中国是世界生产、消费和出口家纺产品的大国,拥有全球规模前列的家纺产业集群和床品交易市场,然而在国际上的品牌影响力和竞争力却并不占优势。通过对现有的家纺从业者、研究者及学习者的调研发现,目前家纺行业普遍存在文化资源相对匮乏、资源获取困难、信息资源共享不足、信息分散且检索任务繁重、产学研对接不畅等现象[2]。基于此,建立集文化传承、产业资源、行业资讯、设计开发、学术研究、技术共享、交易流通于一体的特色综合资源库势在必行。
国内的相关资源库主要是图片等基础设计素材的集合,近年来新开发的一些素材库增加了定制模块、花型交易模块等,是对原有素材库的一种突破。2003年中国纺织信息中心开发了一套“纺织行业数据库咨询系统”,奠定了纺织行业信息化的基础,但由于数据更新及资源量的限制,资源库的作用并未得到充分的发挥。曹飞[3]对家纺床品数据库查询系统进行了研究,主要面向家纺设计师建立了风格、图案题材和加工工艺数据库,该资源库的建设模式主要以人工采集数据源和手工录入为主,工作量大且繁琐。从目前的市场应用来看,针对家用纺织品且尚无集文化、设计、市场、教学于一体的综合资源库。互联网各类家纺资源井喷式增长为构建特色家纺资源库提供了丰富的数据来源。然而,庞大、复杂、多样的网络资源也为此类资源的获取带来了极大的挑战,如何有效地从海量的网络资源中自动抽取有价值的信息是家纺资源库构建过程中亟待解决的问题。本文从家纺资源库的构建需求出发,提出一种深网资源的抽取和噪声过滤的方法,实现网络家纺资源的自动化抽取和噪声过滤,为家纺资源库的构建奠定基础。
1 家纺网络资源库构建背景
1.1 构建需求
本文在充分考虑中国家纺产业集群优势的基础上,建立集文化传承、产业资源、行业资讯、设计开发、学术研究、技术共享、交易流通于一体的特色综合资源库。具体来说,所构建的特色家纺资源库需求陈述如下。
1)文化库:包括历史文化,传统工艺,传统纹样,品牌文化和博物馆收藏;
2)资讯库:包括新闻资讯,政策法规和产业分析,家纺知识,展会信息,大赛信息;
3)家纺名录库:包括企业名录,工作室名录和设计师名录;
4)学术资源库:包括行业标准,专利信息,图书检索,文献检索,会议检索;
5)设计资源库:包括花型图片,款式图片,面料图片和家纺展图片;
6)工艺库:包括常规工艺,特殊工艺和装饰工艺;
7)定制库:包括全定制,部分定制和自定制;
8)交易平台:包括产品信息,报价和技术共享;
9)视频资源库:包括教学视频,展会视频和综合视频。
1.2 资源分布
根据家纺资源库的建设需求,组织相关人力在互联网上进行广泛搜索,寻找相关资源的分布。为后续能够利用信息抽取(information extraction, IE)技术自动化抽取,给出所获得部分资源的统一资源定位符(uniform recourse location, URL),如表1所示。
2 家纺网络资源抽取
2.1 基本框架
网络信息抽取作为数据挖掘的重要组成部分,其主要目标是从Web非结构化的资源中获取结构化的信息。由于网络资源所呈现的方式具有多样性、复杂性以及无规律性等特征,为网络信息抽取工作带来了众多的困难。在搜集URL过程中发现,家纺资源在网络上主要以2种方式呈现,即浅网(Surface Web)资源和深网(Deep Web)资源。浅网资源是指以静态方式呈现在网络上的信息,这类信息直接显示在Web页面上,可通过一些通用的网络爬虫软件(如“火车头”)直接获取;深网资源是指隐藏在查询接口背后的资源,这类资源对用户不是直接可见,需要在页面所提供的查询接口中,输入相关查询条件,才能获取[4]。
无论是浅网资源还是深网资源,在获取之后往往包含噪声信息,这些噪声信息包括“页面导航栏”、“广告栏”、“版权栏”等,如何有效地过滤这些噪声信息,亦是本文研究的核心技术。图1示出家纺特色资源抽取的基本架构。深网资源的获取关键是发现查询接口(query interfaces,QIs),并判断接口所属领域,然后填写领域关键词。在本文中,通过构建领域模型(domain model,DM)来实现对查询接口的判别。对于所获取的家纺资源(网页文件),首先利用基于视觉的页面分块算法(vision-based page segmentation, VIPS)[5]对页面进行分块,然后构建分块重要度模型,通过人工标注,训练该模型参数,实现对页面噪声的过滤。
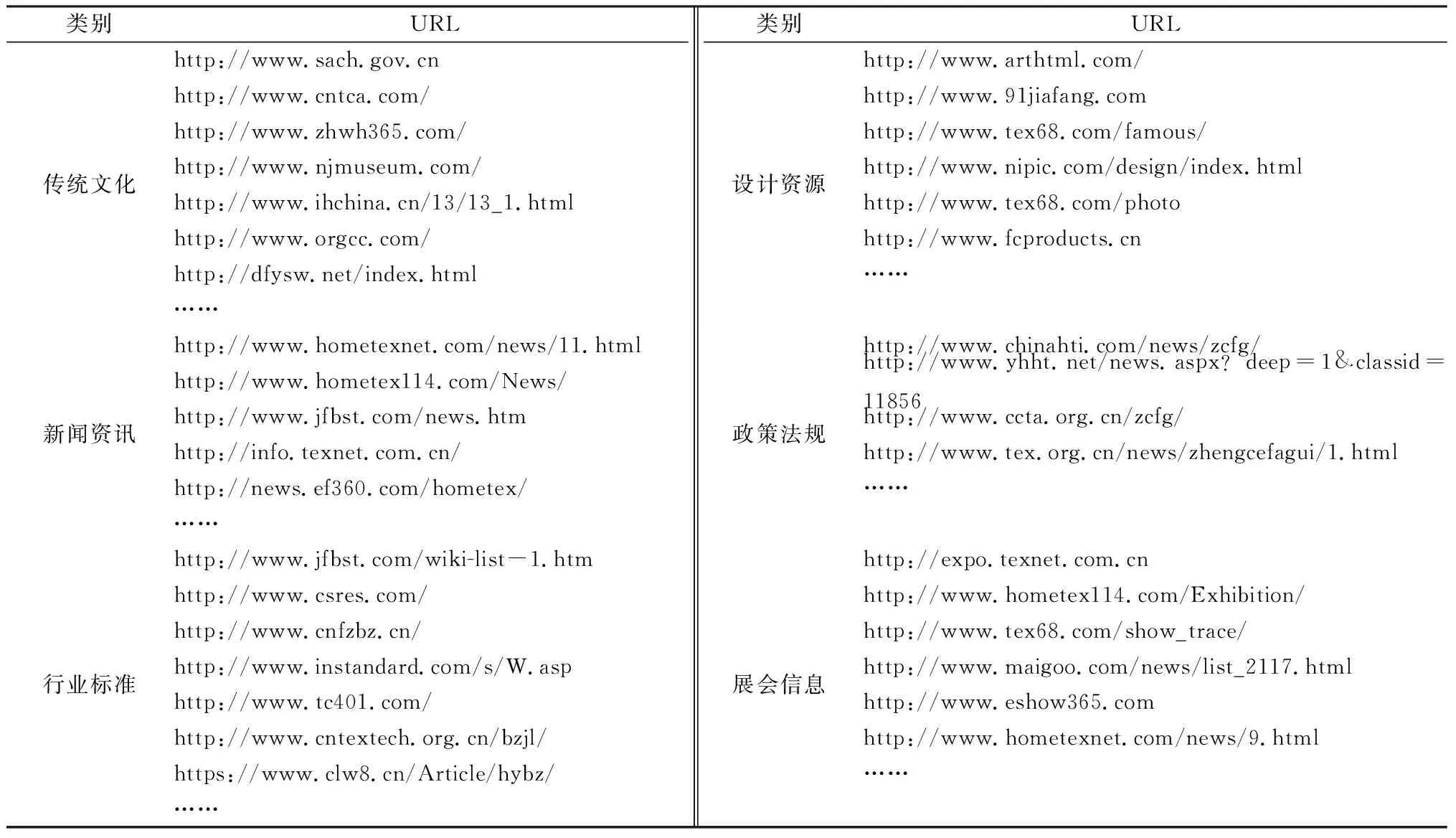
表1 部分家纺资源的URL分布Tab.1 URL for part of home textile resources

图1 家纺资源抽取框架Fig.1 Framework of home textile resources extraction
2.2 领域模型
对于Deep Web家纺资源的自动抽取,其核心是发现QIs,QIs在Web页面中通常是以Web表单的形式存在,Web表单是HTML中的高级元素,由起始链接签组成,之间一般包含表单域,如文本框等。表单的HTML结构如下:
对于上述表单,name,method,action均为表单的属性,其中:name表示表单的名称;method表示表单提交的方式,可以有get和post 2种提交方式;action指明处理表单程序所在的位置,该属性的值为一个URL。为更好地描述Web表单,定义1个五元组来进行形式化描述,即:Form={{C1,C2,…,Cn},A,N,M,U},其中,C1,C2,…,Cn表示表单中所包含的表单域,如文本框,单选按钮,复选按钮等,A表示表单的action属性,N表示表单的名称,M表示表单method属性,U表示表单所在页面的URL。
此后,通过构建领域模型来实现对QIs进行领域分类以及自动进行关键词填写。
2.2.1领域模型的定义
伊利诺伊大学厄本那-香槟分校的研究人员通过收集和分析Deep Web QIs发现:每个QI所包含的属性个数是有限的;虽然在同一个领域,QI的数量很多,但是,其属性进行聚合后,具有收敛性[6]。依据上述2个特征,提出领域模型对QIs的属性进行建模,其定义如下:
领域模型可被描述为1个包含11元素的有序属性树,即DM=(V,v0,E, Δ,TP, N,Lb, Val, tf, R, ≤),其中:V为节点集,即为领域模型中所有节点的集合;v0∈V,表示领域模型中的根节点;E为边集,即父节点和子节点的集合;Δ为字符集,即领域模型中,所有字符的集合;TP为一映射函数,实现节点到表单域类型的映射,这里,表单域类型集合为{radio button (单选按钮), check box (复选按钮),text box (文本框),select list (下拉列表)},其返回值为表单域类型;N为一映射函数,实现节点到表单域名称的映射,返回值为表单域名称;Lb为一映射函数,实现节点到表单域名称列表的映射,返回值为表单域列表;Val为一映射函数,实现节点到表单域值的映射,返回值为表单域的值;tf为一映射函数,实现节点到使用频率的映射,返回表单域使用的频率;R为一映射函数,实现节点和其父节点的映射,返回它们之间的关系,包括range(节点是其父节点的区间成分)关系,part (节点是其父节点的组成部分)关系,group (表示节点与其他兄弟节点具有相同的语义)关系,constraint (表示节点是其父节点的一个约束)关系;≤表示领域模型中,节点之间出现的先后顺序,例如,如果存在(u,v)∈≤,则表示u先于v出现。
2.2.2领域模型的构建
按照上述领域模型的定义,图2示出领域模型的构建流程。在图中,条件1:如果新加入的节点v与DM中所有节点的语义均不同,则执行“添加”操作,在DM中添加以节点v为根节点的子树;条件2:如果新加入的节点v与DM中存在语义相近的节点,若为u,则执行“更新”操作,在DM中将当前节点v的TP,N,Lb,Val等更新至节点u对应属性的列表中;条件3:如果新加入的节点v与DM中存在语义相近的节点,若为u,且节点v中包含了u中没有的属性,则执行“细化”操作,将v作为u的子节点;条件4:如果新加入的节点v与DM中若干节点u1,u2,…的语义相近,且包含这些节点的属性,则执行“泛化”操作,将节点v作为u1,u2,…的父亲节点。
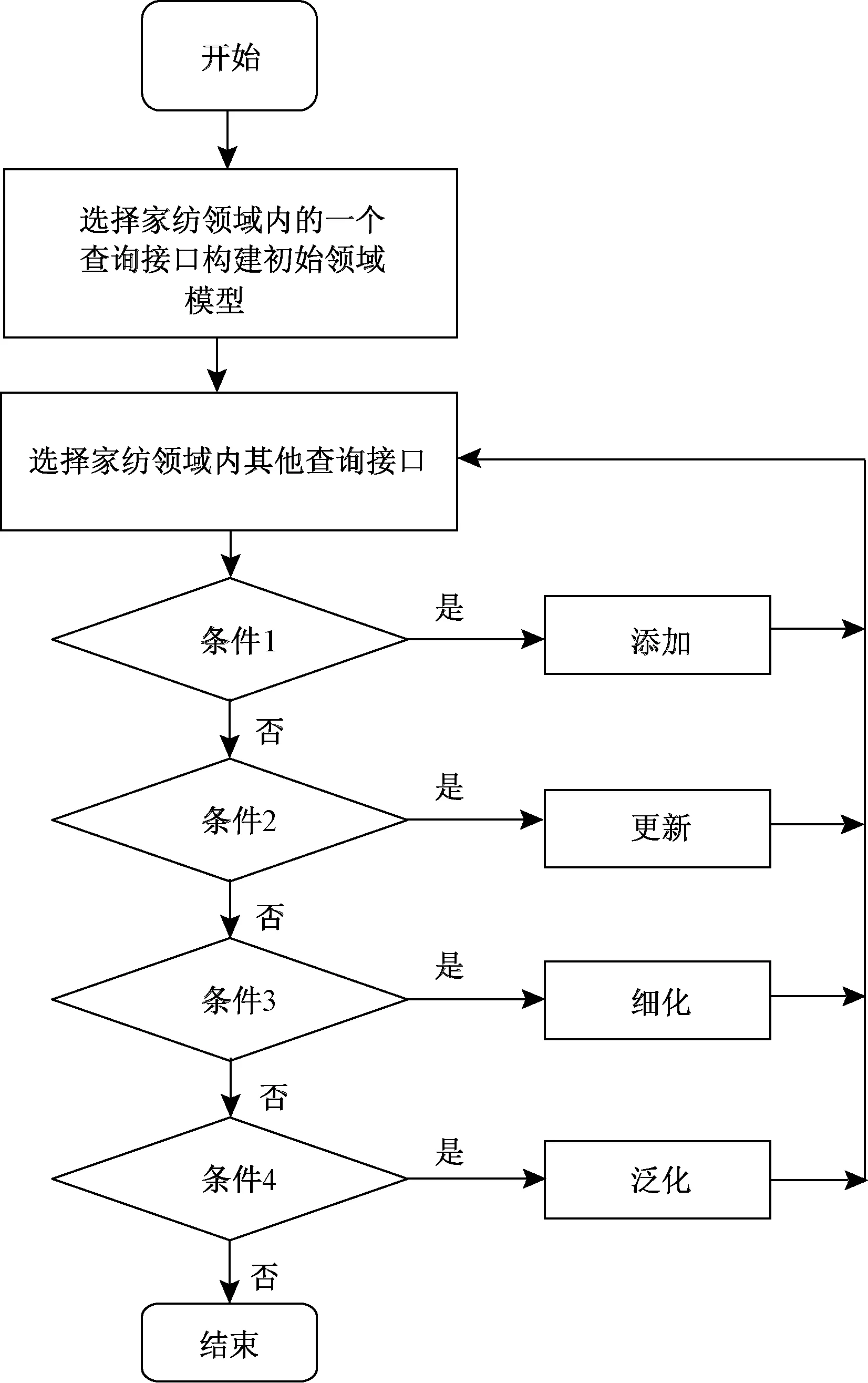
图2 领域模型的构建步骤Fig.2 Construct steps of domain model
图2不断重复执行,直至所构建的DM模型趋于稳定时,则停止,基于此可获取家纺领域模型。
2.2.3DeepWeb查询接口模式抽取
对于需要进行查询的QIs,利用上述所构建的领域模型,进行接口模式抽取,其算法描述如下:
输入:待处理表单,Form={{C1,C2,…,Cn},A,N,M,U};
输出:待处理表单是否为QI及其领域类别。
过程如下:
1)若Ci(1≤i≤n)∈{Password, File, Textarea},则舍弃该表单;
2)抽取Ci(1≤i≤n)中的属性词,并进行规范化处理,包括过滤非法字符,去掉停用词等;
3)遍历所构建的DM,寻找与属性词对应的节点,并记为DMi(1≤i≤n);
4)通过向量空间模型(Vector Space Model, VSM),计算当前待处理Form表单与DMi的相似度,并选择相似度最大的作为Form的领域分类;
5)从当前待处理Form表单所属的领域中,选择关键词填写表单,并进行查询,所返回的结果中包含3个或以上链接,则认为当前待处理表单为QI。
值得注意的是,在1)中,如果Ci(1≤i≤n)∈ {Password, File, Textarea},则表明当前待处理表单中包含的表单域有密码框,或文件上传框,或多行文本框。如果表单中含有这种类型的表单域,则表明其实登录表单,文件处理表单等,这类表单一般不返回有用的查询结果,所以应该舍弃。
2.3 分块重要度模型
在利用领域模型进行QIs判别和分类后,执行查询并返回查询界面,然而,对于返回的结果中,往往含有一些噪声信息,例如导航栏,广告栏,版权栏等。如果过滤这些噪声信息对于本文所研究的家纺资源抽取来说,显得非常重要。通过QIs返回的页面及其布局结构,可以抽取正文栏目中的信息,过滤其他栏目信息。
鉴于此目标,首先要对返回的页面进行分块,用于分块的方法有很多,例如文档对象模型(document object model, DOM)算法[7],DOM算法可以将Web页面格式化为DOM树,虽然DOM树能够反映Web页面的视觉和内在排版信息,但是却依赖于浏览器进行显示,且不同内核的浏览器显示的效果不尽相同。VIPS算法能够显现地表达Web页面的视觉信息和排版信息,易于后续加工处理,因此,在本文进行页面内容抽取时,选用VIPS进行分块处理。
通过使用1个离散的值来表示分块的重要程度,为确定分块的等级,组织人员对获取的分块进行重要等级划分,最后对划分的情况进行投票统计,最终分为3个等级,如表2所示。

表2 分块等级及其描述Tab.2 Levels of blocks and their corresponding descriptions
为确定分块的等级,本文提出分块重要度模型,该模型的基本思想是按照页面分块的空间特征和内容特征,实现其到分块重要程度值的映射,即:

表3 空间特征及其描述Tab.3 Space features and their corresponding descriptions
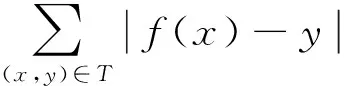

表4 内容特征及其描述Tab.4 Content features and their corresponding descriptions
3 实验分析
为定量地评价本文所引入的领域模型以及分块重要度模型在网络家纺资源抽取中的效果,从1.2所阐述的家纺资源分布的URL中,选取足够的查询接口按照领域模型的构建方法来构建该领域的领域模型(当领域模型趋于稳定时,所选择的查询接口数量为2 385个)。随后,依然从这些家纺资源中分别选取100个Deep Web QIs和50个非Deep Web QIs(包括登录表单,文件上传表单以及注册表单等),用户对领域模型的验证和评价[8]。选择阳性预测值P和正确率A作为评价指标,二者的定义如下:
式中:rQIs为正确识别为QIs的数量;wQIs为错误识别为QIs的数量;rNQIs为正确识别为非QIs的数量;t为所有接口数量。
同时,选择文献[9]中的方法,与基于规则的判别方法进行比较,结果如表5所示。

表5 QIs识别结果Tab.5 Identification results of QIs
从表5可看出,对于非QIs,DM和文献[9]具有相当的识别效果,这是因为非QIs具有非常明显的特征,且算法1在应用DM之前按照表单特征进行了类似于规则的判断。然而,对于QIs,DM相对于文献[9]中的算法,识别效果有了明显的提升。
对于分块重要度模型,选择基于RBF核函数的SVM(support vector machines)[8,10-11]来学习模型参数。首先选择3 000个通过QIs返回的页面,并将其分成训练组(2 000)和测试组(1 000),然后且利用VIPS进行页面分块,各得到13 589和7 415个分块。对于训练组,人工对分块进行标注来训练SVM模型参数。对于训练好的模型,利用测试组分块来进行测试,对于测试结果的评价,选择的评价指标为准确率(Pr),召回率(R)以及准确率和召回率的调和平均数(F1),其定义如下:
式中:x表示正确识别出于抽取主题相关的分块数量;y表示正确识别识别的与抽取主题相关和不相关的分块数;z表示所有与主题相关的分块数。表6示出了正确识别准确率的实验结果。

表6 噪声过滤结果Tab.6 Noise filtration results
当面对海量网络资源,按照返回的页面布局很难构建有效的规则函数,因此,利用规则的方法难以奏效。然而,按照页面的内容特征和空间特征,选择机器学习算法进行模式学习,在高维空间分离出与主题相关的分块以及噪声分块。实验结果也表明这种方法优于基于规则的方法。
4 结束语
为构建家纺特色资源库,本文构建了一种自动化的家纺资源抽取方法,该方法通过识别Deep Web查询接口的方式,自动抽取家纺资源,且对返回的页面进行噪声过滤,实验结果表明了该方法的有效性。在后续的研究中,将考虑采用分布式架构,来减少抽取的时间,同时进一步对所抽取的资源进行整合集成以及分类。
猜你喜欢
房地产导刊(2022年4期)2022-04-19
华东科技(2021年9期)2021-09-23
武术研究(2021年2期)2021-03-29
山东农业工程学院学报(2020年12期)2020-03-19
贵州林业科技(2019年2期)2019-08-26
现代职业教育·职业培训(2018年1期)2018-05-14
电子制作(2017年10期)2017-04-18
中国教育技术装备(2016年11期)2016-12-01
湖州师范学院学报(2016年2期)2016-08-21
地理与地理信息科学(2015年4期)2015-10-13
