
基于GA-SVM模型的印刷套准识别*
2018-10-26 05:59:24王世辉王仪明武淑琴焦琳青李林会
传感器与微系统 2018年11期
王世辉, 王仪明, 武淑琴, 焦琳青, 李林会
(北京印刷学院 数字化印刷装备北京市重点实验室,北京 102600)
0 引 言
套印精度检测与控制系统是保证印品生产质量的必要环节[1]。其中,套准识别算法是系统的核心部分。如何高效、准确地判断印品套准状态成为当下印刷机故障诊断的热点。于丽杰等人[2]通过提取印刷标志图像的颜色、纹理特征,设计最小距离分类器,取得良好的分类效果,并得基于纹理特征参数的分类效果优于颜色特征分类。简川霞等人[3]提取了印刷标志图像的灰度共生矩阵,采用了Adaboost分类器进行套准识别,得到了较高的准确率,并分析对比了不同分类器的效果。
本文首先建立了基于支持向量机(support vector machine,SVM)的印刷套准识别模型,随后在选取模型中惩罚参数与核函数参数时,应用遗传算法(genetic algorithm,GA)进行全局寻优,获取更高的分类准确率,最后采集某印刷厂四色胶印机生产的印刷品作为GA-SVM模型的训练集和测试集样本,在样本数据有限的情况下,取得了良好的预测效果。同时将本文模型与SVM模型、交叉验证意义下网格划分[4]优化SVM模型(GS-SVM)、粒子群优化[5]SVM模型(particle swarm optimization,PSO-SVM)比对,验证方法的可靠性和实时性。
1 GA-SVM印刷套准识别模型
1.1 印刷套准识别原理
通常将两色套印误差小于0.1 mm的印刷品视为套准印刷品,否则为非套准印刷品。传统人工识别套准方法效率低下、浪费人力。随着机器视觉技术的发展,通过图像采集系统获取印刷套印标识图像,并交由计算机分析处理,可准确、高效地判断套准状态,已逐渐成为印刷套准识别的主要技术手段。
1.2 印刷标识图像特征提取
1.2.1 印刷标识图像采集
采用电荷耦合器件(charge couple device,CCD)工业相机拍摄印刷标识图像,得到套准图像和非套准图像如图1。
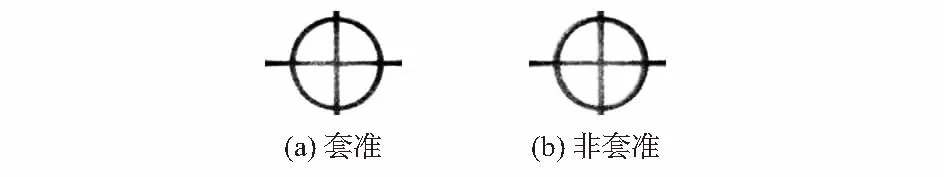
图1 拍摄的印刷标识图像
1.2.2 基于灰度共生矩阵的特征提取
灰度共生矩阵(gray-level co-occurrence matrix,GLCM)是描述图像纹理特征[6]的经典方法,能够精确反映纹理的粗糙程度和重复方向。设(x,y) 为一幅M×N的印刷标识灰度图像,其GLCM可表示为
p(i,j|d,θ)={(x,y)|f(x,y)=i,f(x+dx,y+dy)=j}
(1)
式中i,j分别为图像在像素点(x,y)处的灰度值;dx,dy为偏移矢量,且dx=dcosθ,dy=dsinθ;d为生成步长,一般可取1,2,3,4等值;θ为生成方向,即两个点间的角度。
本文采用了4个重要的特征:惯性矩Ine、能量Ene、相关性Cor和熵Ent[7~10]
(2)
式中Ng为矩阵的行数与列数,L为图像灰度级数,μ为GLCM所有元素的均值,σ2为GLCM所有元素的方差
(3)
2 GA-SVM模型
GA优化SVM参数的具体步骤如下[11]:1)染色体编码及参数初始化;2)确定适应度函数;3)染色体选择、交叉和变异;4)解码,确定最优解。
经GA优化后,可得到SVM最佳惩罚参数c与核函数参数g,随后利用最佳参数对SVM进行训练和分类预测,得出分类准确率,完成印刷套准识别。GA-SVM模型如图2。
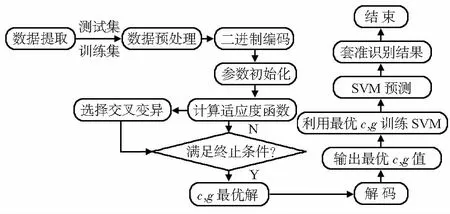
图2 GA-SVM模型
3 实验及分析
实验材料为某印刷厂生产的四色印刷品,通过图像采集装置获取100个印刷标识图像样本,其中,套准图像50张,非套准图像50张。将彩色图像转换为灰度图像,压缩灰度级至16级,以减少图像处理运算量。生成步长d取1,计算GLCM的惯性矩、能量、相关性和熵在0°,45°,90°和135°方向上的均值和标准差,可得8维纹理特征数据,并采用归一化预处理,将原始数据规整到[0,1]范围内,以获取训练集和测试集归一化映射如下
(4)
选取套准样本和非套准样本各30个作为SVM的训练集,其余样本作为测试集。分别采用SVM模型、格式搜索(grid-search,GS)-SVM模型、PSO-SVM模型、GA-SVM模型对100组特征向量进行训练和预测,参数选择结果、分类准确率Ca和测试集分类结果如图3~图6和表1。

图3 SVM模型

图4 GS-SVM模型(c=0.25,g=11.313 7,Ca=98.333 3 %)

图5 GA-SVM模型(c=6.671,g=9.366 2,Ca=98.333 3 %)
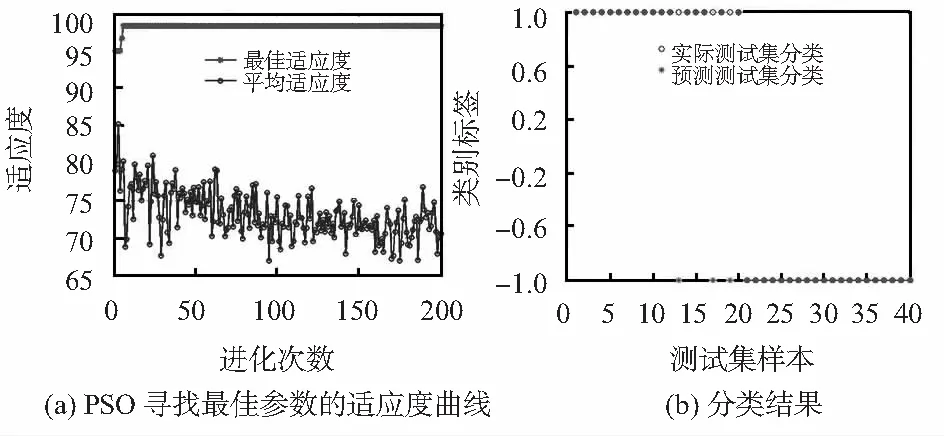
图6 PSO-SVM模型(c1=0.25,c2=1.7,终止代数=200,种群数量pop=20,c=7.950 8,g=9.687 4,Ca=98.333 3 %)
4 结束语
由测试结果可知GA-SVM模型的识别率达97.5 %,仅出现一例样本识别错误,识别能力优于其他模型,识别速度快,满足工业需求。由于遗传算法的选择、交叉和变异操作复杂,需多次迭代才能获得比较好的分类模型,寻优速度较慢,下一步,可通过改进算法进一步优化模型。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02 02:00:02
高技术通讯(2021年3期)2021-06-09 06:57:48
印刷工业(2020年4期)2020-10-27 02:45:52
印刷工业(2020年4期)2020-10-27 02:45:50
软件(2020年3期)2020-04-20 01:45:18
印刷工业(2020年5期)2020-03-29 06:46:44
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:00
Coco薇(2017年8期)2017-08-03 15:23:38
自动化学报(2017年5期)2017-05-14 06:20:56
光学精密工程(2016年1期)2016-11-07 09:01:59
