
海量关系数据去重处理技术研究与优化
2018-10-23 02:02黄奇鹏
计算机与数字工程 2018年10期
黄奇鹏 卢 山
(1.武汉邮电科学研究院 武汉 430074)(2.南京烽火软件科技有限公司 南京 210019)
1 引言
2 传统关系数据处理技术
2.1 关系数据去重简介
公共WiFi设备每天会收到大量的请求日志、上下线日志信息等数据。其中,WiFi登录账号产生的上下线日志便是一种典型的关系数据,它包含数据源与登录账号在线状态的对应关系,可用于资源调查、城市应急等公共社会服务,因此具有较强的研究与应用价值。WiFi账号登录上下线日志数据结构定义为表1。

表1 WiFi账号登陆上下线日志数据结构
据调查统计,南京某城区的公共WiFi一天约有1.6亿活跃的登录账号,平均每个账号1小时会登录2~3次。一个账号会在多个区域范围内登录,随着区域范围、时间范围的扩大,产生的上下线数据量将是海量的。现需要对登陆账号在线时的区域(数据源)、终端类型进行关系分析,一天的数据内约有30%重复上下线数据(账号、数据源、终端类型均相同的数据),庞大的数据会导致数据库查询速度逐步退化,磁盘的消耗空间也会因冗余而浪费。把这些冗余重复的上下线信息去掉将是一项非常重要且有意义的工作。
2.2 传统关系数据去重处理技术
面对海量的关系数据,传统海量数据采集系统通常会把它存在数据服务器中,数据将会以文件、数据库形式保存,且关系型数据库应用更多。传统数据去重处理往往采用的是单线程或多线程的处理方式。由于业务需要获得地区内所有出现过的WiFi登录账号以及每个对应账号使用过的终端类型来进行关系分析,因此需要对登录账号的上下线日志数据进行去重,来确保登录账号与所使用的终端类型当中不会有重复的值影响分析效率。以Or⁃acle10g对WiFi上下线日志数据去重统计为例对传统去重技术进行说明,其流程为
1)初步去重阶段会对每个WiFi登录账号与所对应的数据源为key,通过时间字段,进行分段去重,得到每个时间段的去重结果,并将去重的结果存入一张临时的表当中。得到的数据没有重复的时间字段。
2)二次去重将对初步去重得到的临时表数据进行merge(合并)操作,记录每一个登录账号数据源,并记录历史最晚发现时间与所有登录使用过终端类型,将其录入到一张用于去重比对的表当中,建立当日去重数据的库,即完成当日数据的去重。
3)比对统计阶段会删除初步去重阶段产生的临时表,通过对当天产生的二次去重产生的比对表与历史产生的去重比对表进行merge操作,更新同一账号相同数据源的最晚发现时间与所有登录使用过的终端类型,将结果录入新的比对表。即完成与历史数据的去重。同时当天产生的最终比对表,也会在次日会作为历史产生的去重比对表与次日二次去重产生的比对表进行比对。
由于本业务的特殊性,每天将会对临时表进行频繁操作,导致涉及的表会比较多,进而使维护工作变得繁琐。同时业务需求主要对登陆账号和相对应使用过的终端类型这两列进行关系分析。Or⁃acle是行式存储,为了读取这两列,必须把整个表的行全部读完,才可得到这些列。虽能完成业务需求,但是却具有一定的局限性。若采用列式存储,同一个列会挤在一个块,读某些列,只需要把相关列读到内存中这样可以减少I/O量。
通过图12对比发现,灌浆套筒连接件破坏过程分为弹性、屈服、强化、颈缩4个阶段,试件H500-14承载力高出H400-14承载力10%左右,表明钢筋强度的变化对试件承载力影响明显,钢筋强度越大,试件承载力越高。
使用MapReduce的开源实现Hadoop搭建的平台,能够有效降低并行编程难度,提高编程效率[2]。它对海量数据进行列式分布存储、采用并行计算处理数据,可以解决本业务用Oracle处理的局限性。
3 基于MapReduce的海量关系数据去重技术
3.1 MapReduce去重的基本思想与体系架构
MapReduce是一种并行处理框架,采用分而治之的思想,将一个庞大的数据处理任务,划分成若干个小的计算过程与归并[3~4]。其运行的环境由客户端、主节点和工作节点组成。客户端将用户的并行处理作业提交给主节点,主节点自动将作业分解为Map(分区)任务和Reduce(归并)任务,并将任务调度到工作节点执行[5]。
现以南京某城区WiFi上下线日志进行去重为例,说明MapReduce对关系数据去重的思想。其操作流程图如图1。
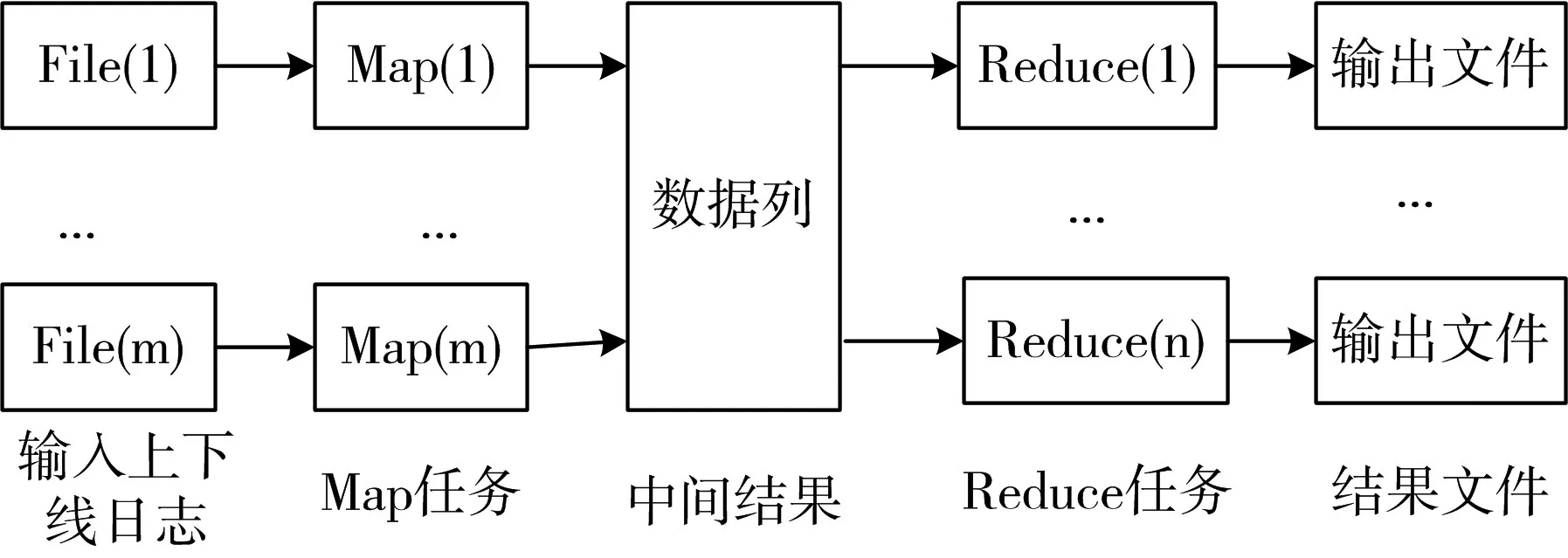
图1 MapReduce操作流程图
MapReduce模型首先会读取数据源传送过来的原始文件,将原始数据按照WiFi登录账号与数据源作为key(键)值,发现时间与终端类型作为value(值)形成哈希散列,交给多个Mapper进程进行计算,接着以<key,value>对形式对中间结果进行排序、合并,根据哈希值将这些结果交给多个Re⁃ducer进程按进行归并计算。最后通过计算对哈希相同的key进行合并,遍历value值将数据按照时间维度进行划分,对一个时间段时间进行排序,以最大的时间作为最后发现时间,并将使用过的终端类型进行汇总,进而完成数据的去重流程。整个阶段key与value的设定如图2。

图2 MapReduce输出<key,value>图
现基于MapReduce的运算框架与海量关系数据的特点,提出一套完整的海量关系数据处理平台架构。体系架构主要包括终端数据层、接入层、数据存储与处理层、数据访问接口层、高级应用层。海量关系数据处理平台体系构架,如图3。
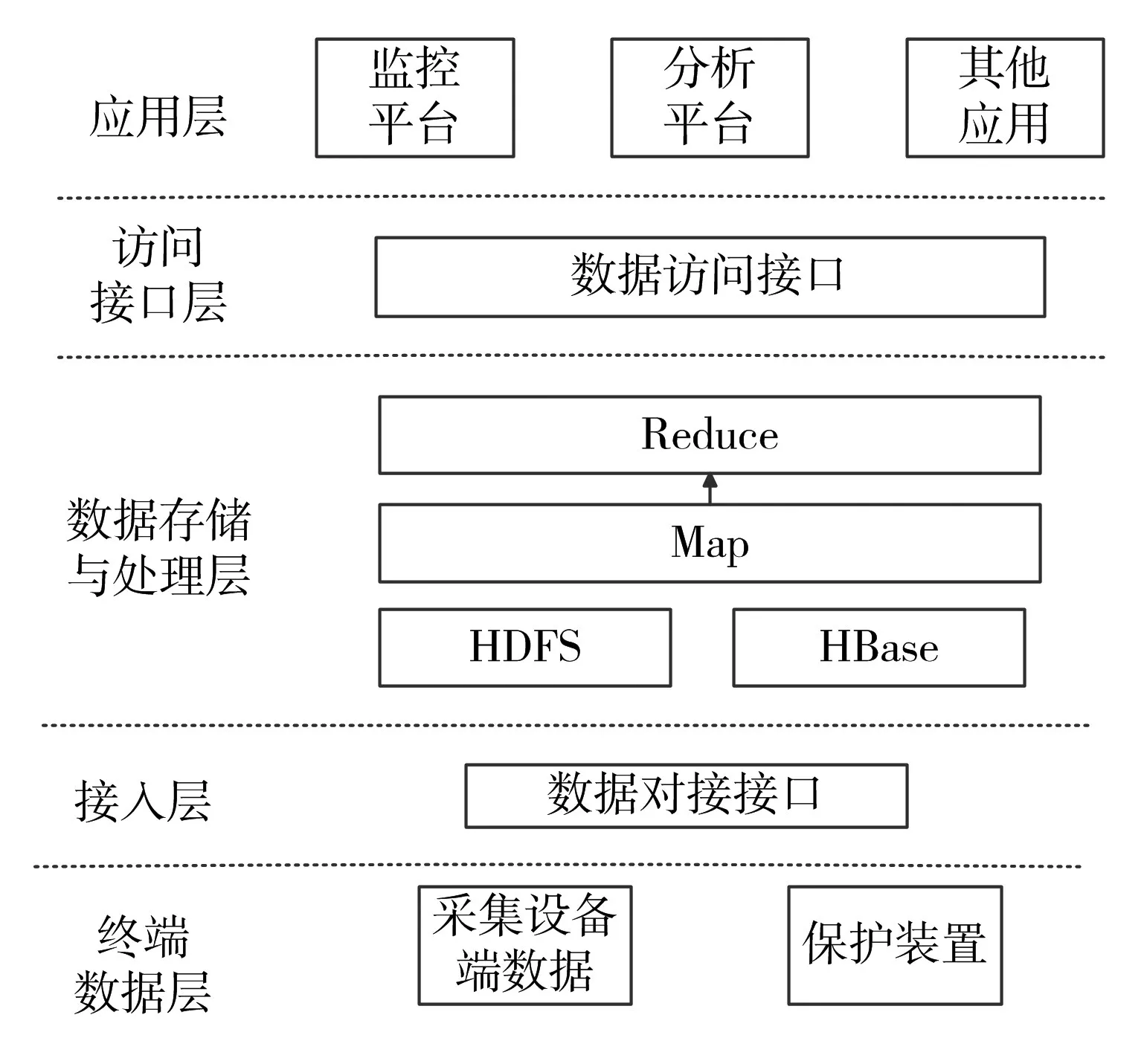
图3 海量关系数据处理平台体系构架
1)终端数据层。作为需要处理的数据来源,将数据以一定的数据流格式发送到接入层;另外还负责设备保护。
2)接入层。接入层会做一些文件格式转换与数据的映射传给数据存储与处理层。并且将对数据源数据进行有效字段的筛选,减少后续层次的处理负荷,减少传输所耗的资源。
3)数据存储与处理层。HDFS与HBase用于海量关系数据的存储,MapReduce阶段对数据进行去重,以及相应字段的更新。
4)访问接口层。对处理层的数据进行协议还原,将之前映射的数据还原成原始数据。向应用层提供一系列的数据访问接口,便于高级应用层的调用。
5)应用层。此层次将处理后的关系数据进行前端展示、交互设计、数据分析等应用。
3.2 基于MapReduce的关系数据去重技术改进
由于MapReduce是存在一定局限性的,它要求任务之间必须有良好的可并行性,多个任务之间不存在数据共享,那么它无法完成当日数据相对于历史数据的去重任务;正常情况下每天约处理1.6亿条数据,在节假日的时候,会比平时的数量还要多,在Reduce阶段若直接利用HashSet集合去重,在一个Set集合中加入312万条已经去重数据记录后,继续添加记录会导致堆内存溢出。所以需要采取分块读取到内存进行哈希散列来改进。
为解决上述问题,现对MapReduce模型去重流程进行归并改进。在Map和Reduce阶段产生哈希散列的字段上进行了如图4调整。

图4 改进的MapReduce输出<key,value>图
整个处理流程将进行2次MR(分区归并)运算进行去重。首次去重以WiFi登录账号与数据源做MD5运算,产生的MD5值与对应两个字段作为key值,发现时间与终端类型作为value值。产生的中间结果不执行Reduce运算,通过中间数据的保存实现数据共享,在集群各计算节点上分别去重,从而保证局部数据中,没有重复的WiFi登录账号。流程如图5。
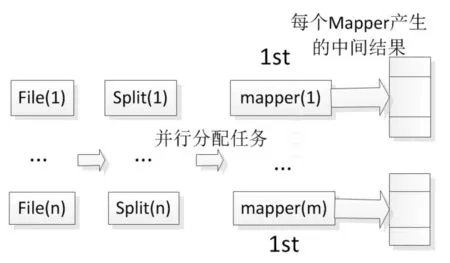
图5 登录账号去重第一次MR运算图
为了进行历史去重,所以得将当日去重的结果输出到中间文件。根据第一步产生的n个中间结果文件,进行归并运算。对于结果文件(tempFile),建立后缀树,并依次再输入后续文件(HistoryFile)中内容,删除后缀树中重复的元素,即保留下来的数据都是不重复的数据,完成与历史数据比对去重。第二次MR运算的整体流程如图6。
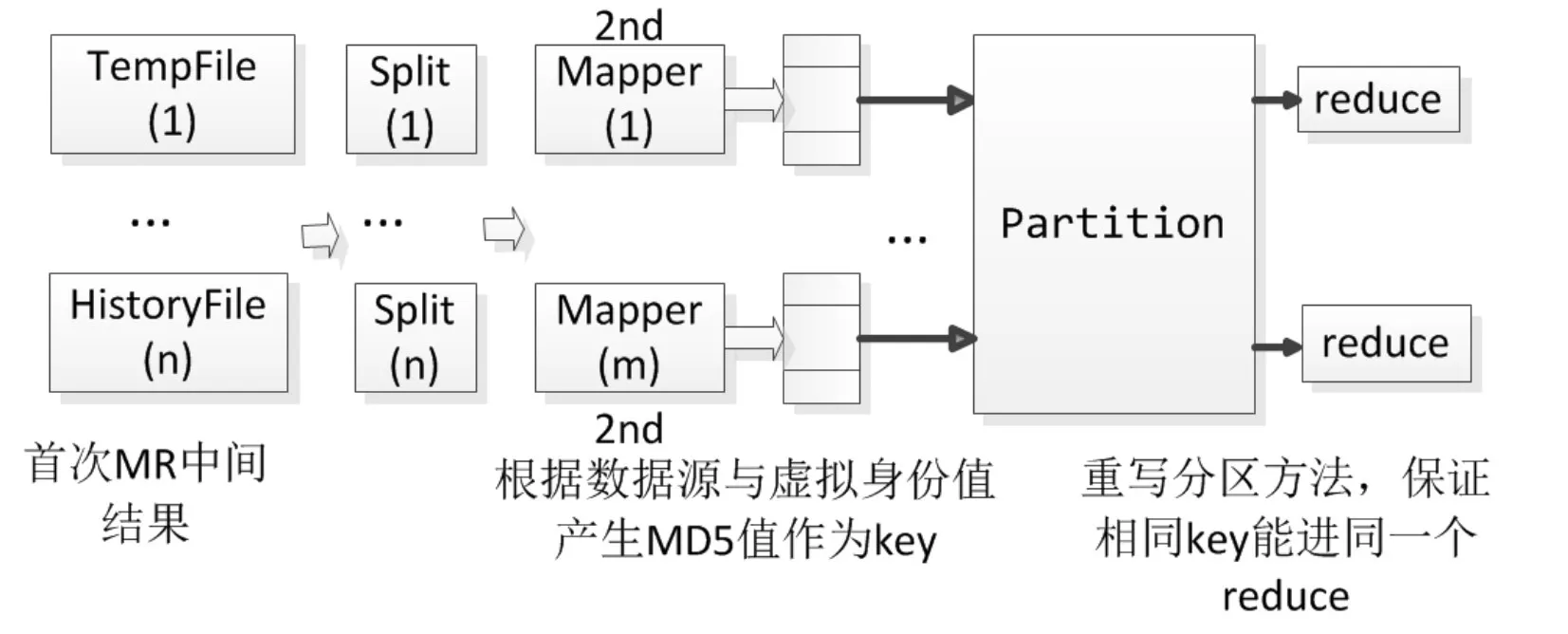
图6 登录账号去重第二次MR运算图
第二次MR的运算中,会对第一次运行的结果进行归并,对MD5值进行比对去重即做到了相对于历史数据的去重。在Map阶段,无论是历史数据还是中间数据都会根据数据源与WiFi登录账号产生MD5值作为key,其他信息作为value。利用MD5值抗碰撞性,保证哈希散列在海量数据条件下不会冲突。根据MD5作为key,在进入Reduce阶段之前,执行重写的partition的步骤,对数据进行全局分区,保证全局域内,所有相同的key都能进入同一个Reduce,再根据哈希值进行比对即完成去重。此方法利用分布式处理的优势,将整个哈希过程分解成了很多个小的归并任务执行,能避免使用HashSet去重因数据量大,导致内存溢出的问题。
4 实证分析
4.1 实验环境
实验采用的集群环境由2台内存为DDR4 16GB*4、硬盘为600G 10K*4的I620-G20服务器组成,机器均运行RedHat操作系统,装有Ha⁃doop2.60集群环境。输入数据集结构如表1所示。
4.2 效率对比测试
为了客观对比传统去重技术与MapReduce去重能力,因此采用4.1节提出的环境,分别用Oracle10g和MapReduce(5个节点)对同一批数据进行去重统计处理(因500G过后MapReduce会发生堆内存溢出,故只测到500G),得到的结果如图7所示。
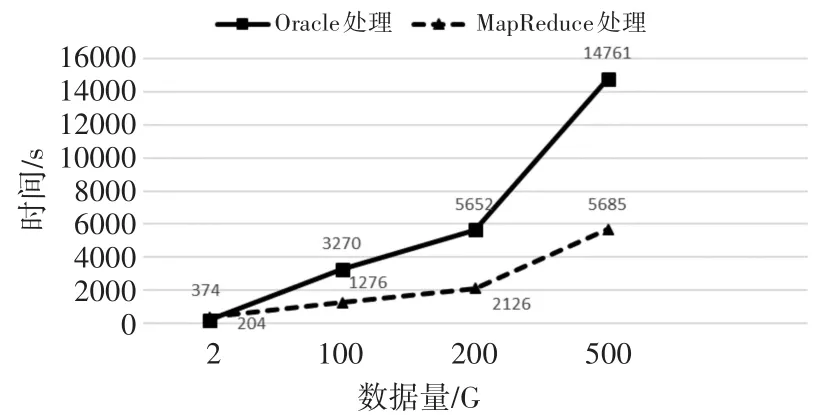
图7 测试结果对比图
此组实验使用的MapReduce流程未改进,没有经过partition重写阶段,在Map阶段切割的时候key用的是WiFi登录账号与数据源。Value字段使用的值为其他信息,Reduce阶段使用HashSet进行去重。
通过图7可见,当数据量不大的时候(低于2GB),MapReduce数据平台处理效率没有传统平台Oracle处理效率高,100G与200G的时候,Ma⁃pReduce的效率略高于Oracle,到了500G的时候,已经明显比Oracle效率高。
4.3 改进方案测试
将改进处理流程后的MapReduce与常规的MapReduce对相同数据进行去重处理进行对比,结果如图8。

图8 测试结果图
对数据分析发现,在处理文件小于200G以前,改进流程后的消耗时间多于没有改进的消耗时间,经分析发现,是由于在数据处理过程中,文件拆分归并等基本操作上所需的定长时间量所占比例过大,以及产生MD5值的运算上。500G的时候改进后的时间会少于没有改进的情况,此时原始Ma⁃pReduce的处理内存消耗快达到饱和,导致运行效率变慢。到800G的时候没改进流程的方案直接报OutOfMemoryError异常,而导致任务运行失败。改进流程后的程序重写了partition的方法,因此在re⁃duce阶段,会根据哈希散列分区且不会产生哈希冲突,即达到去重的目的,同时内存也不会溢出。
4.4 实验小结
本节对传统数据去重方式与MapReduce数据去重的方式进行了效率的对比,验证了在海量数据的条件下对关系数据去重处理,MapReduce具有高效性。但是在小范围的数据处理上,Oracle要优于MapReduce。最后对改进流程的MapReduce进行了测试。由于进行了归并,所以会增加部分内存消耗,但是随着数据量的增大,改进流程后的MapRe⁃duce运行良好,系统的运行效率有着不错的表现,且避免了内存的溢出问题。
5 结语
本文以WiFi上下线日志为例,借鉴传统海量关系数据去重处理技术的经验,提出了基于Ma⁃pReduce的海量关系数据去重处理技术,并论述了去重的基本思想与平台架构体系。就常规MapRe⁃duce模型对海量数据去重会遇到的问题,提出了处理流程上的改进。最后通过实验,验证了在海量条件下MapReduce对关系数据去重的效率。且初步验证了改进后的性能,为后续进一步研究用于海量关系数据处理技术提供了很好的参考依据。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
导航定位学报(2022年2期)2022-04-11
大数据(2021年6期)2021-11-22
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
当代陕西(2019年14期)2019-08-26
智能计算机与应用(2019年2期)2019-05-16
电脑爱好者(2018年14期)2018-08-05
中学数学杂志(初中版)(2016年5期)2016-11-01
电脑知识与技术(2016年8期)2016-05-19
