
基于朴素贝叶斯的短文本分类研究
2018-10-21 19:44檀亚宁刘宏玉王子浪
科学导报·学术 2018年40期
檀亚宁 刘宏玉 王子浪
摘要:自然语言处理是目前智能科学领域中的一个非常热门的方向,文本的分类同样也是自然语言处理中的一项关键的技术。随着深度学习发展,朴素贝叶斯算法也已经在文本的分类中取得到了良好的分类效果。本文针对短文本的分类问题,首先对短文本数据进行了预处理操作,其中包括中文分词、去除停用词以及特征的提取,随后阐明了朴素贝叶斯算法构建分类器的过程,最后将朴素贝叶斯算法与逻辑回归和支持向量机分类算法的分类效果进行了对比分析,得出朴素贝叶斯算法在训练所需的效率上及准确率上有较为优异的表现。
关键词:自然语言处理文本分类机器学习朴素贝叶斯
引言
文本分类问题是自然语言处理中的一个非常经典的问题。文本分类是计算机通过按照一定的分类标准进行自动分类标记的有监督学习过程。在文本特征工程中,和两种方法应用最为广泛[1] 。在分類器中,使用普遍的有朴素贝叶斯,逻辑回归,支持向量机等算法。其中朴素贝叶斯是基于贝叶斯定理与特征条件独立假设的分类方法,有着坚实的数学基础,以及稳定的分类效率。基于此,本文采用基于的特征提取的朴素贝叶斯算法进行文本分类,探求朴素贝叶斯算法在短文本分类中的适用性。
1数据预处理
1.1中文分词
中文分词是指将一个汉字序列切分成一个个单独的词。中文分词是中文文本处理的一个基础步骤,也是对中文处理较为重要的部分,更是人机自然语言交流交互的基础模块。在进行中文自然语言处理时,通常需要先进行中文分词处理[2] 。
1.2停用词处理
去除停用词能够节省存储空间和计算时间,降低对系统精度的影响。对于停用词的处理,要先对语料库进行分词、词形以及词性的类化,为区分需求表述和信息内容词语提供基础。去停用词后可以更好地分析文本的情感极性,本文采用广泛使用的哈工大停用词表进行去停用词处理。
1.3特征提取
文本数据属于非结构化数据,一般要转换成结构化的数据,一般是将文本转换成“文档-词频矩阵”,矩阵中的元素使用词频或者。它的计算为,
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低词语频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
2模型的建立
2.1贝叶斯理论
朴素贝叶斯分类器是一系列以假设特征之间强(朴素)独立下运用贝叶斯定理为基础的简单概率分类器[3] 。
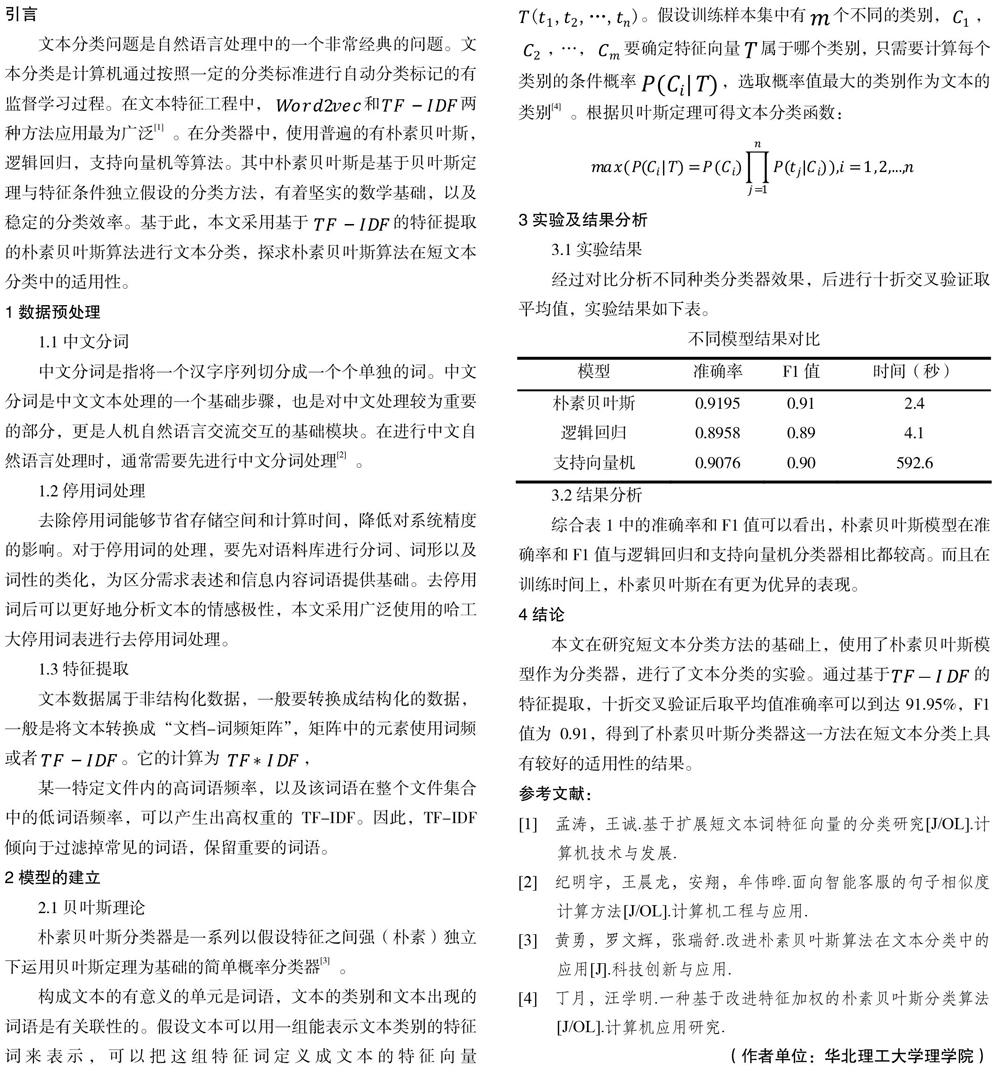
构成文本的有意义的单元是词语,文本的类别和文本出现的词语是有关联性的。假设文本可以用一组能表示文本类别的特征词来表示,可以把这组特征词定义成文本的特征向量。假设训练样本集中有个不同的类别,,,…,要确定特征向量属于哪个类别,只需要计算每个类别的条件概率,选取概率值最大的类别作为文本的类别[4] 。根据贝叶斯定理可得文本分类函数:
3实验及结果分析
3.1实验结果
经过对比分析不同种类分类器效果,后进行十折交叉验证取平均值,实验结果如下表。
3.2结果分析
综合表1中的准确率和F1值可以看出,朴素贝叶斯模型在准确率和F1值与逻辑回归和支持向量机分类器相比都较高。而且在训练时间上,朴素贝叶斯在有更为优异的表现。
4结论
本文在研究短文本分类方法的基础上,使用了朴素贝叶斯模型作为分类器,进行了文本分类的实验。通过基于的特征提取,十折交叉验证后取平均值准确率可以到达91.95%,F1值为0.91,得到了朴素贝叶斯分类器这一方法在短文本分类上具有较好的适用性的结果。
参考文献:
[1] 孟涛,王诚.基于扩展短文本词特征向量的分类研究[J/OL].计算机技术与发展.
[2] 纪明宇,王晨龙,安翔,牟伟晔.面向智能客服的句子相似度计算方法[J/OL].计算机工程与应用.
[3] 黄勇,罗文辉,张瑞舒.改进朴素贝叶斯算法在文本分类中的应用[J].科技创新与应用.
[4] 丁月,汪学明.一种基于改进特征加权的朴素贝叶斯分类算法[J/OL].计算机应用研究.
(作者单位:华北理工大学理学院)
猜你喜欢
电子产品世界(2022年4期)2022-04-21
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
科教导刊·电子版(2017年32期)2018-01-09
数学学习与研究(2017年10期)2017-06-22
软件导刊(2017年4期)2017-06-20
高中生学习·高三版(2017年6期)2017-06-12
