
基于VSM和余弦相似度的稿件精准送审方法
2018-10-19 02:27孟美任彭希珺
中国科技期刊研究 2018年10期
■孟美任 彭希珺
1)中国科学院文献情报中心,北京市中关村北四环西路33号 1001902)中国科学院大学,北京市石景山区玉泉路19号(甲) 100049
同行评议是学术期刊质量控制的有力手段,为论文匹配合适的外审专家是充分发挥同行评议价值的首要环节,对缩短出版周期、把控论文质量、保证研究成果的时效性等都至关重要。论文的研究主题与外审专家研究方向的一致性是外审专家接受审稿并给出准确审稿意见的必要条件[1]。目前,论文的送审主要是编辑参考期刊留存的审稿专家信息,凭编辑经验进行论文主题与审稿专家研究方向的匹配。然而,期刊留存的审稿专家信息往往存在内容缺失、更新不及时等问题[2],导致因“主题不符”的拒审时有发生[3]。送审有误不仅影响作者对刊物的信任,而且成果发表的时效性也无法保证。因此,采取不同措施维护和更新外审专家信息逐渐受到学者和期刊的重视。如InternationalJournalofAutomationandComputing主要通过群发邮件,让审稿专家自行更新信息。同时,编辑部也通过互联网检索信息,更新信息后让外审专家确认[1]。《中华微生物学和免疫学杂志》在每年10—11月通过群发短信和邮件的方式提醒审稿人更新信息[3]。然而,不论是通过人工主动搜集的方式,还是邀请专家自行更新或确认的方式,即便是构建再完整的专家信息库,都未能很好地解决编辑凭经验进行稿件匹配的主观性问题。
为解决由于编辑经验有限、留存信息陈旧、专家研究方向转变等因素导致拒审[4]的问题,本文拟基于外审专家近年的发文数据,结合向量空间模型(Vector Space Model, VSM)和余弦相似度模型实现稿件与审稿专家的精准匹配。该方法的创新性主要体现在两个方面:(1)基于专家近年发文数据构建专家VSM来准确概括外审专家近期研究方向;(2)结合余弦相似度模型进行外审专家匹配能够避免编辑送审的主观性。稿件精准送审方法在提高稿件送审准确率、降低拒审概率方面具有一定的应用价值。
1 外审情况分析
为发掘外审专家拒审的主要原因,并提出合理的解决方案,笔者以《数据分析与知识发现》为例,对该刊2015年1月1日至2017年12月31日的外审情况进行分析。
1.1 专家库中活跃的外审专家较少
《数据分析与知识发现》的审稿系统中共有155位外审专家,2015年1月1日至2017年12月31日,外审专家的审稿量分布如图1所示。
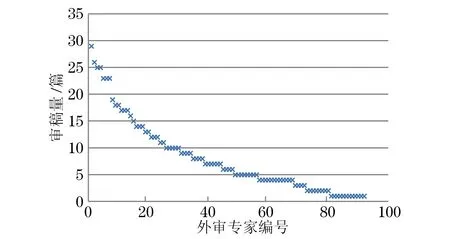
图1 《数据分析与知识发现》外审专家审稿量分布
由图1可知,在此期间只有92位外审专家参与审稿,参与率不到60%。其中:超过20%的外审专家的审稿数量少于3篇;7位审稿专家的审稿量超过了20篇,共计审稿174篇,约占总送审稿件(749篇)的1/4。
可见,凭经验匹配审稿专家会导致经常接受审稿的专家集中在一个相对固定的小群体,而邀请审稿量少的审稿专家过于频繁会增加拒稿的可能,并且对稿件的质量控制存在隐患。因此,亟需设计一种科学、合理的送审方法以避免编辑凭经验送审导致的主观性、局限性以及不准确等问题。
1.2 拒审导致审稿周期延长
进一步对2015年1月1日至2017年12月31日的拒审情况进行分析,3年内共有135篇(18%)稿件被拒审,其中有19篇稿件2次外审被拒,2篇稿件甚至3次被拒,具体统计结果如表1所示。

表1 《数据分析与知识发现》稿件拒审统计
为了解拒审对录用周期的影响,笔者对无拒审记录和有拒审记录的已录用稿件的平均外审周期和平均录用周期进行对比分析,结果如表2所示。

表2 有、无拒审记录稿件的外审周期和录用周期
根据统计结果,158次的拒审中,给出理由的共有86次(55.13%),其中,理由是“太忙”的共22次,“主题不熟悉”的有64次。此外,很快做出拒审决定的审稿人所给出的理由往往都是“太忙”或“主题不熟悉”,而较多拖延很久才拒审的专家并未给出拒审理由。
可见,拒审会延长稿件的发表周期,而为稿件匹配主题相符的审稿专家能够在一定程度上降低稿件拒审概率。
2 研究方法
稿件送审工作的实质就是论文研究主题与外审专家研究方向的高度匹配。根据调研分析结果发现,目前大多数刊物仍然采用编辑根据审稿专家库的留存信息凭借经验进行主题匹配的方法,也有部分采编系统以关键词匹配功能辅助编辑送审。但实际上,专家信息库中的信息由专家自主填写,一方面没有得到及时更新,另外往往使用较为概括的词汇且概括词汇数量较少。针对以上问题,笔者认为应以审稿专家近年发文作为其研究方向的描述源较为准确、合理,并且有研究发现遴选“小同行”评议他们所熟知的学科领域内的科研项目,能够提高评审专家与被评项目匹配的精准性,能够提高科研评审的评价质量[5],即最能够表征某位审稿专家研究兴趣的关键词,应是该专家较多使用,而他人较少使用的词汇。鉴于此,笔者拟基于专家近年发文构建专家VSM,准确概括外审专家近期研究方向;使用词频-逆文档频度(Term Frequency-Inverse Document Frequency, TF-IDF)方法计算关键词权重,以充分区别每位审稿专家的研究兴趣;使用余弦相似度模型进行稿件主题与外审专家研究兴趣的相似度计算。
2.1 VSM
VSM是由Salton[6]于1968年提出的一种文本表示模型,将文档表示为一组词向量,通过计算向量之间的相似性得到文档之间的相似度。设文档d包含n个关键词(kterm),则d={kterm1,kterm2,…,ktermn},其中每一个ktermi在文档中都会有一个权重(wi)来表示该词在影响文档相关度中的重要程度。即d可以被描述为一组关键词的向量:
V(d)={w1(d)kterm1,w2(d)kterm2,…,wn(d)ktermn}
(1)
2.2 TF-IDF
最能表征一个文档的关键词应该是既在该文档中出现频率较高,又在其他文档中出现频率较低的词语。因此,本研究使用信息检索领域的TF-IDF[7]计算关键词在向量中的权重:
wi=tfidf(i,d)=fTF-id·fIDF-i
(2)
fTF-id=ni/Nd
(3)
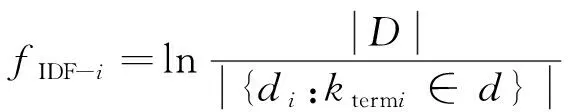
(4)
式中fTF-id为词频,fIDF-i为逆文档频度,ni为词ktermi在文档d中出现的次数,Nd为文档d的总词数,D为总文档数,di为包含i的文档数,{di:ktermi∈d}为包含词语ktermi的文档数,为使分母不为0,一般使用{di:ktermi∈d}+1对其进行平滑处理。可见,如果一个词在所有文档中都高频出现(如“的”“这”等),其fIDF-i就越小,因而可以有效降低该类词的权值。
2.3 余弦相似度计算
通过计算向量空间中两个向量夹角θ的余弦值,并以此衡量两个个体间的差异,余弦值越接近1,夹角度数越接近0,说明两个向量越相似。对于一篇新文档e,同样利用(1)~(4)式可以计算得到文档e的权重,文档e与文档集合D中的文档d的相似度计算公式为
(5)
3 稿件精准送审
3.1 数据采集
笔者在中国知网中使用专业检索获取《数据分析与知识发现》155位外审专家(记为集合P)2013年5月31日至2018年5月31日发表在图书馆学、情报学、信息科学、自动化技术以及计算机技术类的46种期刊[期刊遴选标准:《中文核心期刊要目总览(2014年版)》中G25 图书馆事业、信息事业类18种以及TP自动化技术、计算机技术类的26种期刊;中文社会科学引文索引中图书馆、情报与文献学(非档案类)18种期刊。两类合计去重后共46种期刊]中的所有文章。为准确体现作者研究主题,只保留外审专家是排名前3的作者的文章,共获得文章1805篇(记为集合D)。统计集合P中每一位外审专家p在集合D中的所有发文d,提取di中的所有关键词t={tp1,tp2,…,tpn}。令w={w1,w2,…,wn},为待审文章集合A对应的关键词。
3.2 算法实现
本研究使用Python 2.7软件中gensim库实现相似度计算,核心算法的过程为
输入:t,w;
输出:与待审稿件相似度排名前10的审稿专家名单(list)和相似度s。
(1) 使用gensim库中corpora.Dictionary方法对所有外审专家发文关键词构建字典(key:value),其中key为关键词,value为词编号,
dictionary=corpora.Dictionary(t);
(2) 使用gensim库中doc2bow方法分别构建外审专家向量和待审稿件向量:
corpus=[dictionary.doc2bow(tp)for text int],
new=dictionary.doc2bow(w);
(3) 使用models.TfidfModel(·)初始化tfidf模型,分别利用外审专家向量和待审稿件向量转化为tfidf值:
tfidf=models.TfidfModel(corpus),
tfidf_corpus=tfidf[corpus],
tfidf_test=tfidf[new];
(4) 为tfidf_corpus创建索引index,进行待审稿件的相似度计算:
index=similarities.SparseMatrixSimilarity(tfidf_corpus),
sim=index[tfidf_test];
(5) 对相似度值进行降序,取前10:
sort=sorted(sim, reverse=True)。
本研究数据为文章的关键词,如果增加文章的摘要、正文,则需要进行切词以及停用词、低频词清洗。
3.3 验证实验
为验证该方法的有效性,笔者获取《数据分析与知识发现》2018年1~5期发表的55篇文献的关键词,使用该方法计算得到每篇文章最匹配的10个审稿专家,限于篇幅,只对10篇排序第1的审稿专家的关键词进行分析,结果如表3所示。由于该刊采用单向盲审,因此使用专家编号代替实名。
通过观察表3中的第2、4列可知,该方法推荐的最优外审专家的发文关键词与待审稿件的关键词非常契合。笔者进一步获取这10篇文章的摘要和正文进行深入分析,发现:文章1对移动购物App中用户的信息浏览、用户购买行为进行分析,以预测商品购买决策,而编号135的外审专家致力于电子商务领域的用户行为分析;文章2旨在考察不同类型媒介信息对股票投资者过度交易行为的影响,而编号4的外审专家的一个研究方向即是对股票的数据分析;文章3主要对网络评论情感可视化的相关研究进行综述,而编号117的专家在网络舆情、情感分析方面颇有建树;文章4主要探讨通过深度学习进行自动图像标注,而编号66的专家致力于标注方法、图像识别等相关领域的研究;文章5旨在探讨关联大数据管理技术的对策和解决思路,而编号21的专家研究也同样围绕关联数据、语义网络等;文章6旨在通过主题识别,提高竞争情报收集的准确率和效率,而编号32正是竞争情报领域的专家;文章7旨在探索高维结构化电子病历数据的降维策略,而编号72正是医学领域的数据专家;文章8研究概念设计过程知识的语义建模技术,而编号102的专家正是知识工程领域的专家;文章9研究患者对在线医疗问答系统的使用意愿,而编号106的专家曾对医疗社区的用户交互行为进行研究;文章10旨在准确识别科技论文中数值指标的实际取值,而编号41是自然语言处理、数据挖掘领域的专家。

表3 最优外审专家结果列表(部分)
该程序可以批量对稿件进行审稿人匹配,并且按照相似度对审稿人进行降序排序,同时给出文章关键词,以及审稿专家曾发文关键词供编辑参考,考虑刊物采用单盲审,因此将专家名隐去,效果如图2所示。

图2 稿件送审推荐结果效果图
由图2可知,该程序可以为编辑送审工作提供有力支持,以降低因专家信息陈旧和编辑未能实时、准确跟踪外审专家研究方向的变化而导致“主题不符”类拒审的发生概率。编辑可根据推荐结果,综合考虑并选择审稿专家,如审稿专家正在审稿或已在近期有过审稿记录时,可向后顺位选择;或外审专家与作者同单位甚至正是作者时,也需要向后顺位选择。
为了验证该程序的有效性,笔者于2018年6月14日至2018年8月13日使用所开发的工具对56篇稿件进行送审,除3位审稿专家由于假期原因拒绝审稿外,尚无其他拒审事件发生。而且在使用该工具进行送审后,专家意见更加充实具体,在一定程度上也反映出送审文章的主题与专家兴趣的匹配程度有所提高。在未来的工作中,笔者将持续使用该程序,并阶段性地对审稿专家进行问卷、访谈等多种形式调研,听取反馈意见以不断改进,尽可能降低拒审概率,缩短文章的发表周期。
4 结语
快速、精准地匹配审稿专家对于缩短发表周期、提高编辑工作效率、提高刊物影响力具有重要的现实意义。本研究将基于VSM的余弦相似度计算方法应用到稿件的送审工作中,极大降低了稿件的拒审概率,并且为审稿专家信息更新提供了一种新的途径。
本研究只针对刊物已有的外审专家进行了信息更新,下一步笔者将获取基金立项信息、国际发文情况、专家主页等数据扩充审稿专家库,并同时考虑专家以往审稿记录、审稿偏好等特殊情况,以提高送审准确率。另外,对于交叉学科的文章如何进行更加全面、客观的同行评议也值得进一步研究。
猜你喜欢
中国伤残医学(2022年14期)2022-12-27
政法论丛(2022年5期)2022-09-29
政法论丛(2022年4期)2022-08-16
客联(2022年3期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
政法论丛(2022年1期)2022-02-22
中国新闻周刊(2021年26期)2021-07-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电脑爱好者(2017年7期)2017-05-06
高中生学习·高三版(2016年9期)2016-05-14
