
一种适用于移动设备在线阅卷的答题卡自动识别算法
2018-10-18 10:11,,,,
计算机测量与控制 2018年10期
, ,,,
(西南科技大学 计算机科学与技术学院,四川 绵阳 621010 )
0 引言
答题卡主要用于内容选项较多的考试中。常见的答题卡自动阅卷系统主要有光标阅读机[1]、扫描仪阅卷系统[2]和摄像头阅卷系统[3]。这几种常用的阅卷系统虽已达到了识别速度快、效率高,但工作时却受设备的硬件条件所限,主要在PC或嵌入式端操作,使得办公不够灵活,且存在价格高昂、对纸张质量和印刷的要求高等缺点。因此,它们主要被应用在中高考、研究生考试、公务员考试等一些大型的正式考试场合中。然而对于像学校日常的随堂测验,英语四六级、会计资格证、银行从业资格证等培训考试,这些需要用到答题卡的非正式考试场合,单位或人们更倾向于以一种低廉、简单、便捷的操作方式来进行阅卷。移动互联网的高速发展使得智能手机、智能平板电脑等移动设备越来越普及,在国家教育信息化的推行进程中,移动教育方式不断地受到关注。在此背景下,出现了许多基于移动端的答题卡自动识别系统[4-5]。
目前基于PC端或是基于移动端的答题卡自动识别系统,大部分是独立开发的,程序高度定制化,因而限制了其普遍适用性,相应地增加了开发周期和成本。在实际使用时,由于个体间差异较大,答题卡填涂时可能出现填涂大小和深浅不一致、擦除不干净等情况,进行采集识别时,不同的光照、摆放位置会造成采集的图像出现阴影、反光、倾斜等问题,这些会相应的增大识别难度。
为解决以上问题,本文设计研究一套识别率高、实时性强、能兼容适应不同采集设备的答题卡识别算法。PC机可利用外接摄像头,进行图像采集,随后通过计算机软件识别答题卡,这种方式主要应用在办公室阅卷。移动设备普遍具有较高分辨率的相机,利用其采集答题卡图像,然后在App上进行识别,这种方式便捷、高效、成本低,适合于移动办公,能够配合基于移动设备的教育软件一起使用,具有较大的应用价值和发展前景。
1 答题卡设计
答题卡要求识别正确率达到100%,因为一旦出现识别错误,将直接影响考生本场考试成绩。考虑成本要求,在答题卡纸质质量和印刷方式方面要求不严格,支持普通纸60 g以上的打印、复印等方式的制作答题卡。针对以上需求,标准答题卡模板设计如图1所示,四周采用方框做边界标定,相比传统采用原点作为标记点,在外观上更简洁大方。
答题卡主要包括两大部分:个人信息区和答题区。个人信息区内容为身份证号和试卷号(由数字+“X”构成),在手写体识别中,由于个体间差异较大,书写习惯不同,导致识别率不能得到保证。因此,为达到识别正确率高的目标,设计如下数字填涂方格(1...9)与(X),以小圆点作为标记,引导考生做如下书写:0123456789X。答题区每道题有A、B、C、D四个选项,每个选项之间的间隔相等,行之间的行间距相同,每行的行高也完全一致(可增加题量)。

图1 答题卡模板
2 答题卡图像处理与识别过程
针对答题卡图像特点,设计算法流程图如图2所示。

图2 算法设计流程图
1)答题卡预处理:主要包括对图像降噪、去阴影、灰度拉伸、二值化、形态学等处理,去除图像采集过程中受到的一些外在因素影响。
2)待识别区域定位:根据预处理后的图像特点,建立几何映射关系,变换得到模型参数矩阵,并结合插值算法校正图像。
3)答题卡内容识别:对校正后的答题卡图像,①定位分割填涂项,结合填涂点灰度、面积等属性设计算法,进行识别;②定位分割数字字符,做归一化等预处理操作后,采用模板匹配结合结构化特征的方法进行一一识别。
2.1 答题卡图像预处理
在拍照过程中,受遮挡或光照不均匀等因素影响很容易在拍摄的图像上产生阴影,若答题卡采用铅笔填涂还容易出现反光现象。如图3(a)所示,拍摄时造成了图像右区域存在阴影,答题卡采用铅笔填涂,在26~30题项区域出现反光现象,若直接采用自适应阈值做二值化处理,会出现信息区域部分缺失,如图3(b)所示,这样会影响识别结果。因此,识别前应对答题卡做预处理。分析答题卡图像,发现答题卡内容上表现出许多的细节信息,出现的阴影区域呈片型且亮度变化缓慢。一般情况下,线性滤波会给图像的细节带来模糊问题,这样便可利用梯度滤波器来去除图像中的阴影[6],将阴影作为目标,答题卡内容作为背景,利用均值滤波器和背景差分法[7],即可提取出阴影。设W(x,y)为大小为M×N,中心点在(x,y)处的均值滤波器窗口,Imean(x,y)为均值滤波后的图像,I(u,v)为原始图像,均值滤波器是计算滤波窗口内的像素均值,并将其赋给窗口中心处的像素:
(1)
去除阴影后的图像:
I′=255+Imean-I
(2)
去除阴影后的目标图像表现亮度不均,对比度较差,利用灰度拉伸延展整个灰度级范围,使灰度变化具有分段性,图像边缘更清晰,从而改善图像质量。预处理效果如图3(c)、(d)所示。
由于目前市面上的移动设备相机普遍具有较高的分辨率,获得的目标图像数据量大,为节省设备存储空间,获得更高效的处理效率,系统研发时对采集的原始图像按预设比例归一化成标准规格图像后,再执行答题卡的识别过程。

图3 预处理(去阴影、处理反光效果)
2.2 待识别区域定位分割
相机在拍照过程中,由于纸张摆放偏差或者相机未平行拍照都有可能使图像产生旋转或者倾斜,如图3(a)所示。因此,需要对答题卡图像是否发生形变进行检测,同时进行相应的校正处理。答题卡是由方框作为边界,具有突出的4个顶点,对获得的轮廓图像采用多边形逼近方式定位出答题卡的角点坐标位置,建立相应地映射关系对图像进行倾斜和透视校正。多边形逼近[8]算法的基本思想是在获得的轮廓上寻找最远的两个点连成线段,然后在轮廓上查找到该线段最远的点,并将其添加到新轮廓,反复迭代,不断添加新的点到结果中,最后得到逼近的多边形顶点。定位到角点后,通过三角函数变换确定目标图像的倾斜角,采用透视变换的方式对图像进行倾斜校正。透视变换通过将检测得到的目标图像的四个定点坐标(x1,y1),(x2,y2),(x3,y3),(x4,y4)和基准答题卡的四个顶点坐标(X1,Y1),(X2,Y2),(X3,Y3),(X4,Y4)之间建立线性坐标映射关系,得到透视变换参数矩阵,其中a,b,c,d,e,f,m,l是透视变换的参数。
(3)
把上式记作:
B=A*V
(4)
由(4)式得:
V=A-1*B
(5)
求解以上线性方程组得到参数值,将目标图像的每个像素点,变换到新的坐标点,完成图像的校正。图像校正过程中,像素坐标实际为整数,变换后的图像可能出现空隙,所以需要对变换后的目标图像进行插值运算。从理论上来讲,双线性插值[9]性能介于最近领域插值与三次卷积插值之间,若采用三次卷积插值,算法时间复杂度较高,对图像处理速度太慢,而采用最近邻域插值效果不佳。因此,针对答题卡特征表现较为单一的特点,采用双线性插值的方法来使图像信息更接近原图。结果如图4所示。

图4 拍摄角度校正效果
对校正后的答题卡图像利用连通域、正交投影定位分割得到答题区域及个人信息标识区域。
2.3 答题区识别
实际考试过程中,由于考生差异化填涂(例如:用笔不同、填涂大小和深浅不一致等),这些都有可能影响识别结果。为避免上述情况,对分割得到的答题区图像,做形态学处理,采用自适应阈值进行二值化,然后根据填涂点灰度、面积及所处位置作为评价指标,转化得到选项答案。算法使用水平和垂直投影的方式,确定答题区每组题目之间的距离,题间距离及选项距离。利用相互之间的距离特性,对答题卡客观题区域划分网格,每个网格对应题的选项答案(A,B,C,D)位置或者题号(1,2,3等)位置,存储并记录网格所代表的信息,及每道选择题所对应的答案位置。然后提取答题卡填涂区域的质心,按其所处位置转化为选项答案。同时计算该区域像素的平均灰度值及区域面积,进行有效填涂判定。最后,对以上结果进行综合判定,确定选项答案。该方法也适用于多选题。

图5 选择题识别
2.4 个人信息识别
目前字符模式识别方法大致可分为统计模式识别[10]、结构模式识别和人工神经网络[11-12]等。模板匹配[13]是统计模式识别方法中常用方法之一,将待识别数字与预先准备好标准模板进行匹配,根据匹配相似度确定当前识别结果。结构模式识别通过寻找字符本身特征,譬如横线、竖线、连通区域等来判定当前识别内容。神经网络通过对大量数据样本进行训练学习,得到每类样本的特征表示,进而分类识别。
由于神经网络识别方法,参数较多计算复杂度较高,训练过程需要有标签的庞大数据集且会花费大量时间。因此,采用模板匹配结合结构化特征的方法对书写结果进行识别。识别过程如图6所示。
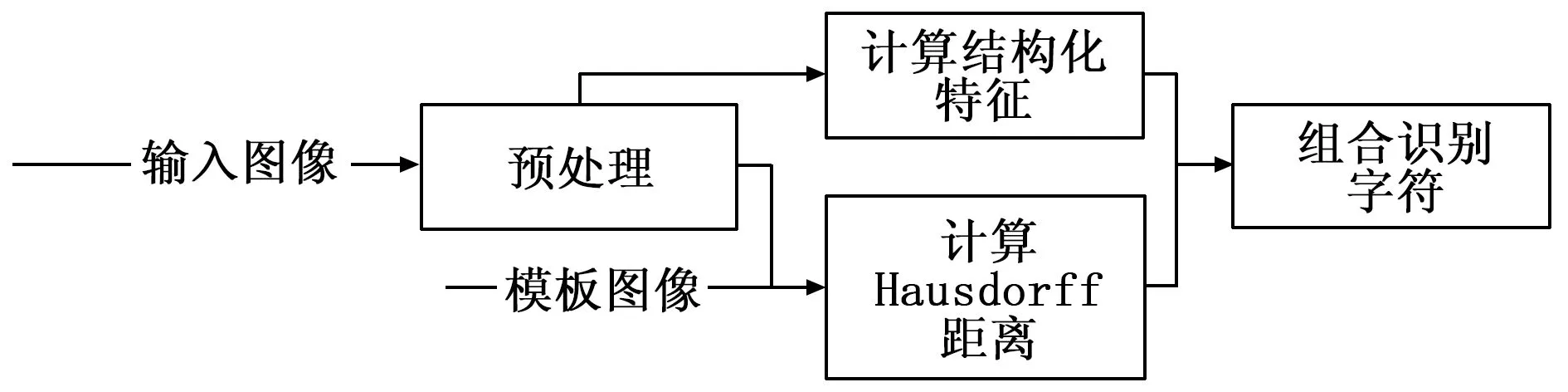
图6 数字识别原理框图
首先依据设计的数字填涂方格中标记原点的位置关系设计如下模板图像(尺寸大小22×34):
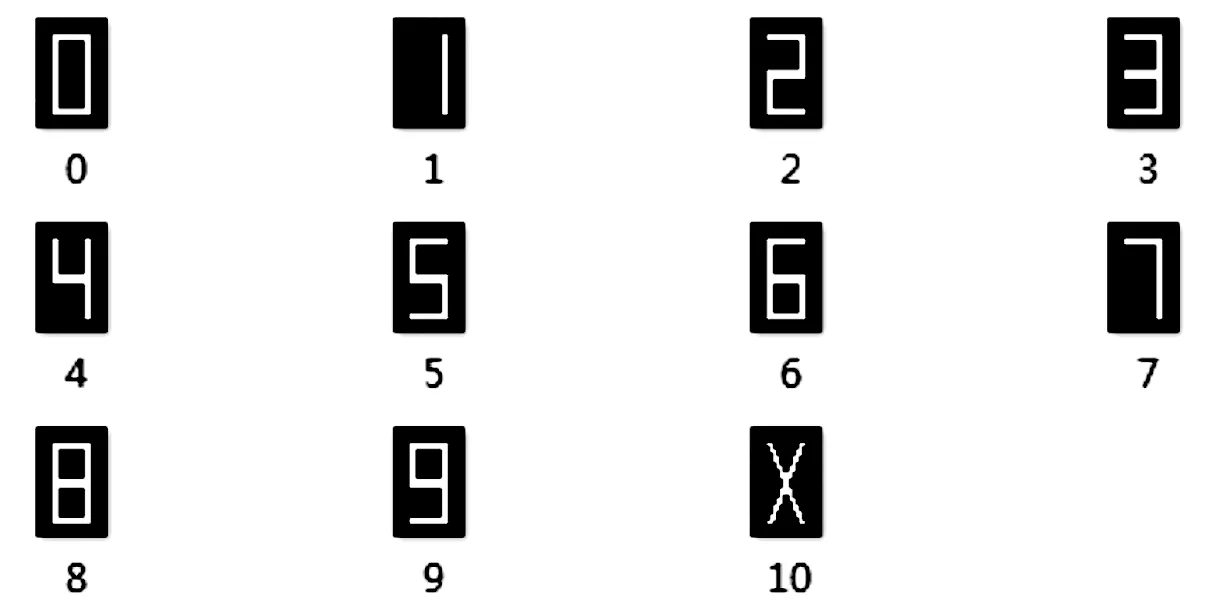
图7 字符模板图像
归一化输入图像大小,使其与模板图像尺寸相同。然后计算模板与待识别图片的Hausdorff距离作为相似性判断,同时计算输入图像的结构化特征。最后组合判定得到识别结果。
2.4.1 Hausdorff距离
Hausdorff距离是用来描述两个实体之间相似性的一种度量方式,因平移、旋转、缩放等变换对其影响较小,而受到广泛运用[14]。假设有两个点集A={a1,... ,an},B={b1,... ,bn},定义A、B点集合之间的hausdorff距离为:
H(A,B)=max(h(A,B),h(B,A))
(6)
其中:

(7)
(8)
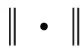
2.4.2 结构化特征
分析填涂数字的特征,可通过数字的孔洞质心位置、欧拉数(欧拉数=连通域数-孔数)、横线、竖线(利用水平投影、垂直投影计算)来区分部分数字,见表1。
欧拉数:用于将数字分为3类:{0,6,9},{8},{1,2,3,4,5,7,X};
孔洞质心位置:用于区分{0},{6},{9};
横线、竖线:用于区分{1},{3},{4},{7},{X}。

表1 各数字结构特征
3 答题卡自动识别算法的实现
3.1 答题卡识别算法实现
跨平台(Cross-platform)的应用程序是指其在多种平台下不改动或稍改动即可编译运行[15-16]。本文跨平台系统主要分为两部分:答题卡自动识别算法库和跨平台实现。总体架构如图8所示。
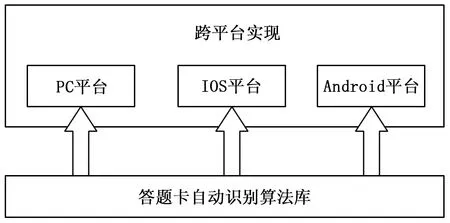
图8 跨平台系统总体框架图
答题卡自动识别算法的开发环境是VS2013+OpenCV3.0,利用C++语言编写实现。C++语言具有很好的跨平台性,面向对象编程适合处理像图像这类具有复杂数据结构的问题。OpenCV是一个跨平台且开源的计算机视觉图像处理算法库,常用于商业和科研用途。在算法库的基础上实现跨平台性,共包括PC平台、Android平台以及IOS平台。Android平台下,将原始算法库封装成符合JNI命名规范的so库,并再次封装为能直接使用的jar包,做成发布版Android SDK。IOS平台下,由于Xcode支持 Object C 与C++的混编,因此可直接将算法库编译成静态类库供开发人员调用。
3.2 测试结果与分析
测试使用的答题卡模板均由6位试卷号、11位身份证号、50个选择项组成。为验证算法的跨平台性,测试平台选择了基于IOS、Android系统的多种采集设备,分别采集了110张答题卡图像。

表2 不同机型正常填涂测试结果
正常填涂采集(正确填涂,拍摄时答题卡方框区域拍摄完全,成像区域不能过小)图像80张,测试结果如表2所示。正常填涂识别正确率为100%。不同操作系统下算法运行时间在2 s内,运行时间主要与设备处理器和运行内存有关,PC采用的是双核处理器,运行时间较长。
异常填涂采集(答题卡的填涂大小、深浅、擦除不干净等特殊情况,采集时不同的光照、摆放位置等情况)图像30张,如图9所示,这些会相应的增大识别难度。经测试,算法能有效处理拍照时出现的阴影、反光、倾斜(-45~45°)情况,异常填涂识别正确率为93.6%。不能识别√、×、Ο类填涂方式,及答题卡旋转倾斜角度较大等情况。

图9 不同条件下拍摄的图片
4 总结
本文针对答题卡图像采集时存在阴影、反光、倾斜等问题进行了研究,采用梯度滤波结合背景差分法的方式去除阴影。对预处理后的图像,采用多边形轮廓逼近的方式定位角点,进而进行倾斜校正等操作,为进一步识别做铺垫。采用网格定位法对填涂区域信息进行定位,并结合填涂区域位置、面积及灰度等信息,形成评判体系,确定选项答案。对个人信息区利用模版匹配结合结构化特征的方式,进行数字的提取识别。最后,根据跨平台编程的思想,设计实现了一套能兼容不同系统下不同的采集设备,实际运用时识别速度快,准确率高的答题卡自动识别算法。下一步将考虑复杂的拍摄背景,以及答题卡出现折皱做进一步研究。
猜你喜欢
军民两用技术与产品(2022年5期)2022-06-28
电脑报(2021年11期)2021-07-01
文苑(2020年11期)2020-11-19
通信产业报(2020年31期)2020-09-10
中国诗歌(2019年6期)2019-11-15
小学生时代·综合版(2016年8期)2016-05-14
数学大王·中高年级(2016年4期)2016-05-14
新媒体研究(2014年4期)2014-04-21
初中生世界·八年级(2009年8期)2009-11-03
初中生世界·七年级(2009年8期)2009-11-03
