
基于层次分析与主成分分析的云存储资源调度策略
2018-10-15 08:04徐建鹏孙海春
中国人民公安大学学报(自然科学版) 2018年1期
徐建鹏, 李 欣, 孙海春
(中国人民公安大学信息技术与网络安全学院, 北京 100038)
0 引言
云存储是云架构中IaaS层的核心构件,其效率直接影响着整个云平台的性能[1]。目前常见的云存储架构包括Googel的Googel File System[2]、Apache的Hadoop Distributed File System[3]、Amazon的Dynamo[4]以及基于OpenStack[5]开源框架的Swift、Cinder和Ceph。以OpenStack为例,面向用户数据的动态存取业务主要由Cinder块存储来承担,其资源调度策略主要是通过比较存储节点的剩余可用空间来实现,这虽然可以较好地提高资源利用率,但并未考虑该节点是否出现了网络堵塞、内存使用率过高等情况,因此存在一定的局限性。国内外目前都有一些对此问题的研究,比如多维离线调度算法[6]、基于三角模糊数的调度算法[7],以及通过网络延迟、负载均衡等因素来对调度策略进行优化,这些方法都能较好地提高云存储资源调度的效率,但调度的判定因素仍然不够全面,应用场景较为单一。
针对上述问题,本文提出了基于层次分析法与主成分分析法的云存储资源调度策略,首先对调度所涉及的指标进行全方面的研究、归纳,然后利用层次分析法对指标项进行定性与定量的研究,再通过主成分分析法对调度策略所涉及的8个详细指标项进行权重分析,减少层次分析法中主观判断的误差,提高策略的鲁棒性,最后与现有的Cinder资源调度策略进行对比分析,验证本文策略的有效性和稳定性。
1 层次分析法与主成分分析法[9-10]
1.1 层次分析法的概念
层次分析法(Analytic Hierarchy Process,AHP)是由美国运筹学家萨蒂教授于20世纪70年代初提出的一种层次权重决策分析方法,该方法通过将整个决策过程分解为总目标、准则、方案3个层次,并以此为基础进行定性和定量的分析,最终得出决策的结果。AHP的主要过程包括:构建层次结构模型、判断矩阵分析、计算与分析结果。
使用AHP对一个问题进行分析时,首先要对该问题构建层次结构模型,根据问题所涉及的各因素之间的相互作用以及包含关系,将其分为总目标 、各层子目标、评价准则以及备选方案,然后定性地判断最底层(备选方案)相对于最高层(总目标)的重要性顺序,再采用“1-9”标度法将其转换为定量的分析,生成判断矩阵,最终计算出除最高层外各层相对于上一层的权重分布,并以此求出各备选方案相对于总目标的权重,得到最终的决策结果。
1.2 主成分分析法的概念
主成分分析法是一种把多个变量转化为少数主要变量(即主成分)的多元统计分析方法,即将原来众多具有一定相关性的指标,重新组合成一组新的互相无关的综合指标来代替原来的指标。该方法通常用来寻找判断某种事物的主成分,从而更好地揭示事物内在的规律。
我们设原始指标变量为x1,x2,…,xp,将其进行线性组合构成新的综合指标标量,即主成分z1,z2,…,zq,具体如公式1、2所示:
(1)
且满足:
(2)
其中zm与zn互不相关,z1的方差最大,其余z2,…,zq的方差依次减少,且原始数据的总方差等于p个互不相关的主成分的方差之和,即p个互不相关的主成分包含了原始数据中的全部信息,但主成分所包含的信息更为集中。
2 云存储资源调度策略的实现
2.1 构建层次结构模型
云存储资源调度策略主要解决的是存储节点选择的问题,而该选择所依赖的判定依据主要包括节点静态指标、节点动态指标以及网络指标,其中节点静态指标细分为节点I/O频率与节点故障率。节点动态指标包括节点剩余存储空间、数据传输距离、节点CPU负载情况与节点内存使用率。网络指标主要为节点网络带宽与节点网络延迟。为便于分析,本文在备选方案中设计了3个可选节点。根据以上设计,即可构建出相关的层次结构模型,本文使用yaahp工具进行实现,具体如图1所示。
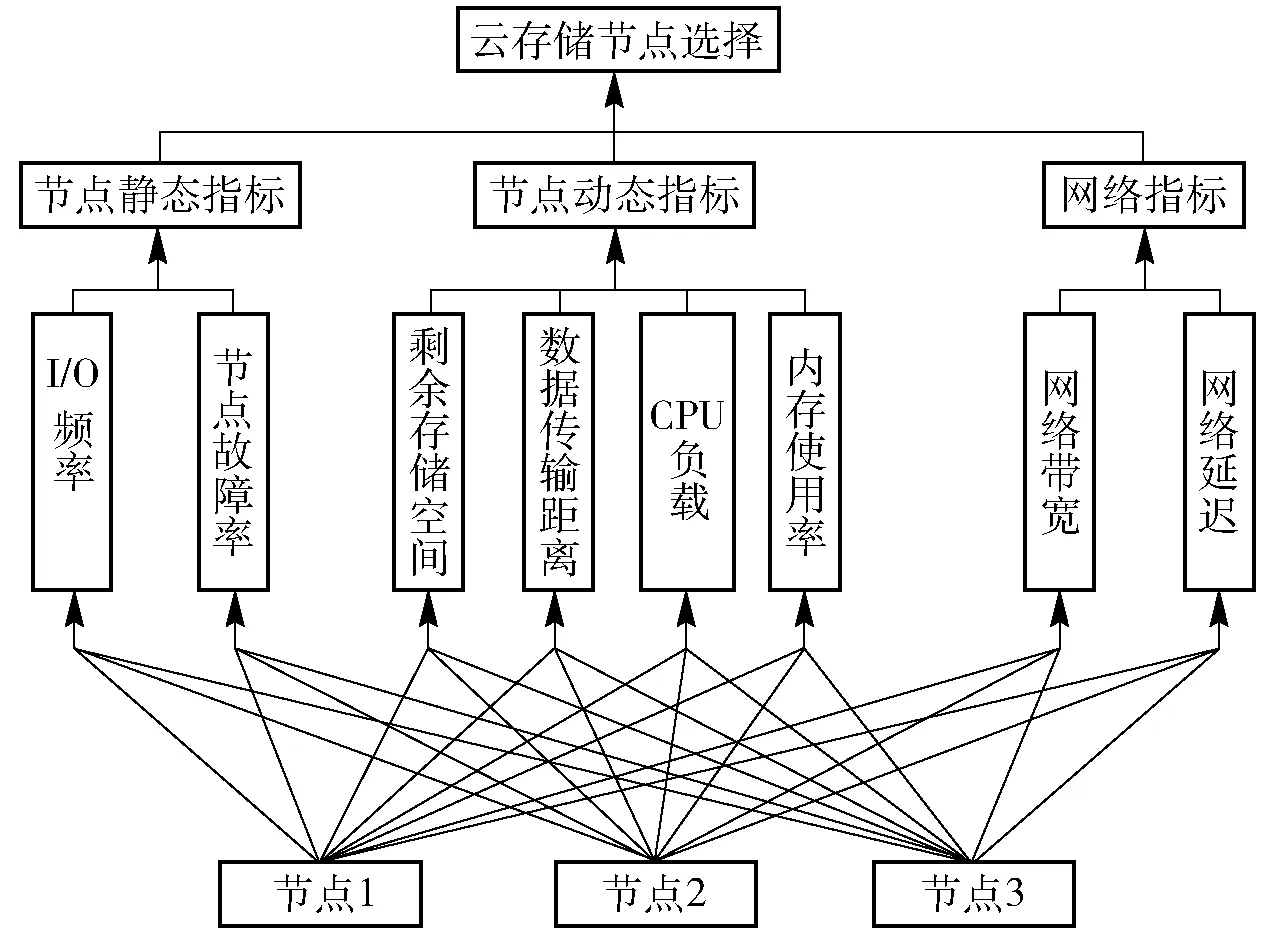
图1 云存储资源调度指标的层次结构模型
2.2 判断矩阵分析
层次分析法中,定性分析转换为定量分析的关键在于“1-9”标度法的使用,具体如表1所示。

表1 “1-9”标度法赋值及其具体含义
不同的云用户,对于各类指标会有不同的要求,例如与个人用户相比,金融企业用户会对网络指标具有极高的要求。因此,本文主要是基于广泛的个人用户的调研,来进行云存储资源调度策略的层次分析。
首先,我们分析“云存储节点选择”的判断矩阵,如表2所示,其中每一个值,代表其横向指标相比于纵向指标的标度,即对于总目标,横向指标与纵向指标之间重要性的比较。

表2 节点静态指标、节点动态指标及网络指标相对于总目标的重要性分析
由表2,即可得到相关的判断矩阵A:
权重分布为WA=[0.209 8,0.549 9,0.240 2]T,且矩阵A的一致性指标CR=0.017 6<0.1,满足一致性检验。
同理,我们可以得到节点静态指标、节点动态指标及网络指标这3个对象的判断矩阵:
其权重分别为WB1=[0.166 7,0.833 3]T,WB2=[0.261 8,0.527 7,0.105 2,0.105 2]T,WB3=[0.166 7,0.833 3]T,且均通过一致性检验。
最后,我们需要分析3个存储结点的各指标表现情况,具体如表3所示,其中C1~C8代表“I/O频率”至“网络延迟”8个指标,此时表中的标度值可以理解为两节点在某一指标下的优劣程度。综合以上数据,可得表4。
在最后阶段,我们需要计算8个指标项相对于总目标的权重分布,再结合表4中的标度值,求出3个节点最终相对于总目标的权重(得分),并由此做出决策判断。为减少层次分析法中主观判断的误差影响,提高策略的鲁棒性,我们采用主成分分析法来确定8个指标项相对于总目标的权重分布。
2.3 主成分分析法的实现
我们使用SPSS(Statistical Product and Service Solutions)软件对表4内的数据进行主成分分析,首先将原始数据进行标准化处理,根据公式3,将其转化为均值为0,方差为1的无量纲数据,其结果如表5所示。

表3 C1~C8各指标表现情况
(3)
式中k为样本数,i为指标数,且:

表4 3个存储结点的 C1~C8指标表现情况

表5 原始数据的标准化处理结果
由表5,可根据公式(4)求得其相关系数矩阵X:
式中:
(4)
令|X-λI|=0,即可解出X的p个非负特征根λi(i=1,2,…,p),且满足λ1≥λ2≥…≥λp≥0,每个特征根都表示对应主成分的方差,计算结果如表6所示。

表6 主成分分析结果
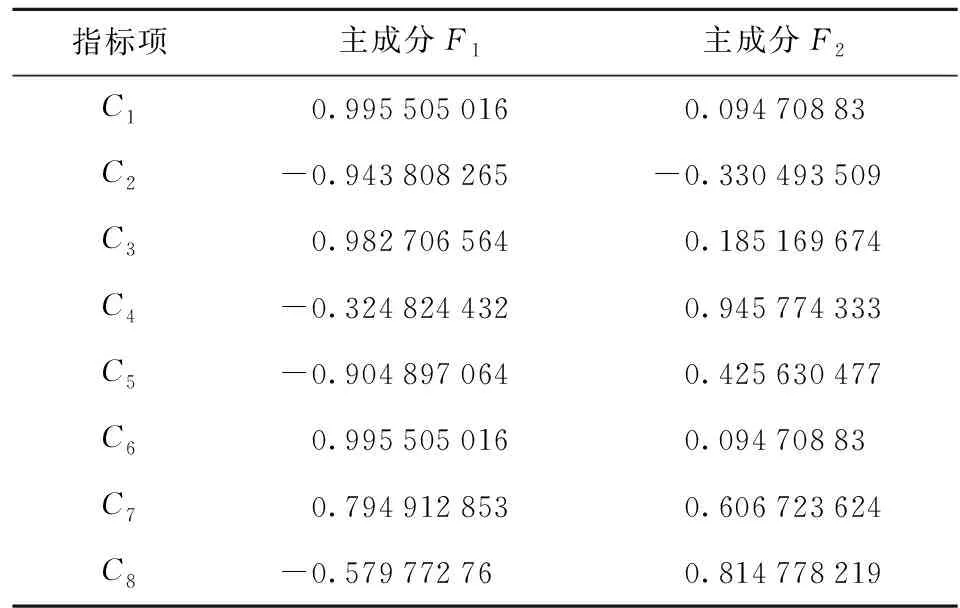
表7 第一与第二主成分的成分矩阵
由表6中数据可知,第一主成分与第二主成分的方差总占比达到了100%≥85%,由此我们即可使用第一与第二主成分这两个综合指标来代替原来的8个指标。最后,综合表7数据,即可得到主成分的表达式:
F1=0.415 8C1-0.394 2C2+0.410 5C3
-0.135 7C4-0.378 0C5+0.415 8C6
+0.332 1C7-0.242 2C8
F2=0.072 1C1-0.251 5C2+0.140 9C3
+0.719 7C4+0.323 9C5+0.072 1C6
+0.461 7C7+0.620 1C8
最后,我们将3个存储节点的各指标数值代入F1、F2,且令F=F1+F2,最终可得到3个存储节点的评分,如图2所示。可知在所设计的3个存储节点中,节点2得分最高,最适合作为数据的存储节点。
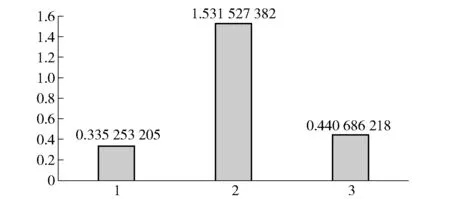
图2 3个节点的最终得分比较
3 实验与分析
3.1 实验设计
本实验对文中提出的云存储资源调度策略的有效性进行了分析,实现了策略的代码设计,完成实验测试。
实验硬件环境:Intel Core i7- 6700HQ四核处理器,8 GB内存,Linux Ubuntu 14.04 LTS操作系统。
软件环境:Kdevelop编译器,C++语言。
实验数据集:程序中设计CloudStrogeNode类与CloudMessage类来分别实现数据中心的存储节点以
及存储的数据。
CloudStrogeNode类:为重点体现调度策略的影响,本文将所有的存储节点的固有属性(I/O速率以及节点故障率)设置为相同的定值,其他指标均由随机函数生成。
CloudMessage类:主要包括距离以及数据大小两个指标,均由随机函数生成。
第一数据集:实验中共实例化生成100个不同的CloudStrogeNode类实例以及1 000个不同的CloudMessage类实例,即需要将1 000个数据包存储到100个存储节点之中。
第二数据集:实验中共实例化生成500个不同的CloudStrogeNode类实例以及3000个不同的CloudMessage类实例,即需要将3 000个数据包存储到500个存储节点之中。
每次实验测试的结果为数据存储完成时的耗时t,并非程序的运行时间,t主要由CloudStrogeNode以及CloudMessage的相关指标计算得到,且Cinder策略与本文策略采用相同的计算方式。
为模拟云环境,所有的存储节点都会随着数据的存储而更新相关的指标,如剩余存储空间、内存使用率、CPU使用率等等,且整个进程采取并行的方式运行。本实验使用不同的随机种子,使用两组数据集分别进行了10组实验,每组实验中进行了20次测试,取耗时的平均值进行分析。
3.2 实验结果分析
首先,我们使用第一数据集进行10组实验,测试结果如图3所示:

图3 使用第一数据集测试Cinder策略与本文策略的耗时
数据显示,本文策略可有效提高存储效率,其耗时平均要比Cinder策略低79%。接下来我们使用第二数据集同样进行10组实验,测试结果如图4所示。
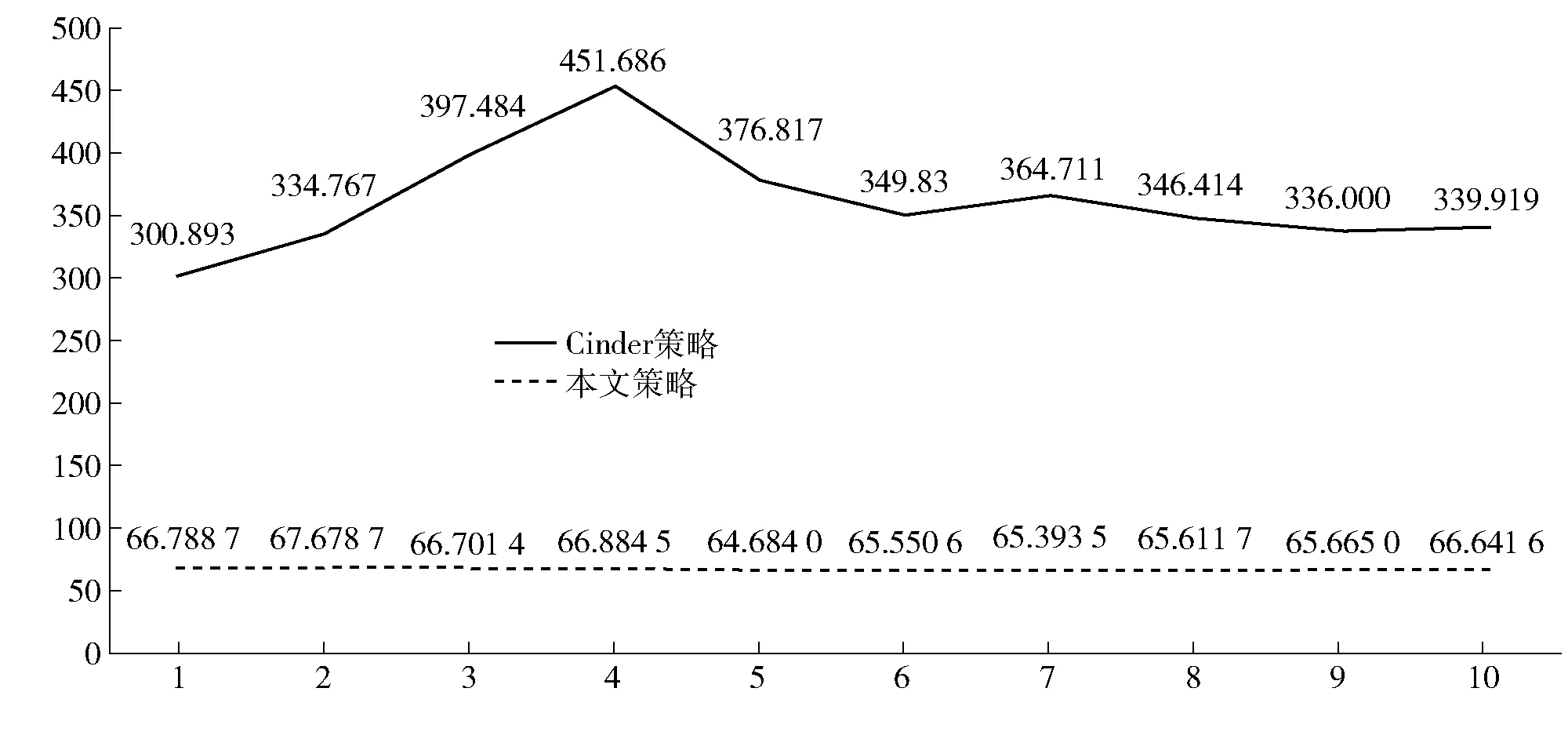
图4 使用第二数据集测试Cinder策略与本文策略的耗时
由以上结果可知,Cinder策略由于只考虑节点的剩余存储空间,未考虑到节点的其他各项指标影响,容易出现耗时不稳定的情况,而本文策略综合考虑各项性能指标,选取最优节点进行存储,确保了结果的稳定性。
4 结束语
本文在理论及实践的基础上提出了基于层次分析与主成分分析的云存储资源调度策略,该策略充分考虑云存储环境中的各项性能指标,通过层次分析法与主成分分析法进行定性及定量的研究,且对其进行了代码实现。经实验验证,该策略具有有效性与良好的稳定性,为云存储源调度提供了一种全新的思路。但另一方面,该策略的缺陷在于层析分析阶段,各指标项的重要性分析仍具有一定的主观性,因此,下一步的研究重点是建立一个客观、科学的云存储性能指标评价标准,实现更加高效、可靠的云存储资源调度。
猜你喜欢
食品科学与人类健康(英文)(2022年2期)2022-11-28
防爆电机(2022年4期)2022-08-17
机械工业标准化与质量(2022年6期)2022-08-12
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
铁道通信信号(2020年10期)2020-02-07
电子制作(2019年20期)2019-12-04
北京航空航天大学学报(2019年9期)2019-10-26
智富时代(2019年5期)2019-07-05
智富时代(2019年5期)2019-07-05
