
法庭语音证据评价的新范式
2018-10-15 08:04:16张翠玲
中国人民公安大学学报(自然科学版) 2018年1期
张翠玲
(1.西南政法大学刑事侦查学院, 重庆 401120; 2.重庆高校刑事科学技术重点实验室, 重庆 401120)
0 引言
20世纪以来,国际上对法庭证据技术的科学性问题关注越来越多,对科学证据的检验与采信也提出了一系列标准和要求[1-7]。在这一系列标准、报告和规范中都明确提出了提高法庭证据技术的“科学性”的核心要求,即要求检验技术及程序方法具有准确性、可靠性、客观性、透明性、可重复性、可验证性等。Saks和Koehler在《科学》上发表评论[8]指出,“同一认定”“独特性”等法庭科学的核心假设理论正在受到挑战和质疑,法律和科学正合力推动传统的法庭鉴定科学走向新的科学范式,并将新范式描述为“以实证为基础的科学”,像DNA分型一样,“基于数据”进行“概率评估”。他们还建议其他法庭科学分支也效仿DNA检验,“构建样本特征数据库来支持概率方法”,同时通过错误率估算表明其局限性。
这种新范式就是基于似然比框架的证据评估模式。国际上,法庭科学证据的检验与评价正处于新旧范式的转换进程中[8]。2016年9月,为了促进各国法庭科学实验室在统一框架下进行法庭科学证据的检验与评价,以及对评价结果的含义及表述达成共识,欧洲法庭科学研究所联盟(ENFSI)发布了法庭证据评价报告指南[9],推荐包括语音在内的所有法庭科学分支都采用基于似然比框架体系的新的证据评价范式。
法庭说话人识别是法庭科学的重要分支之一。目前,在国内,法庭说话人识别还主要依赖于语音专家的主观评断,缺乏客观的评判标准和足够的量化数据支持。而国际上,法庭说话人识别已经开始转向以似然比框架为核心的法庭证据评价的新范式[10]。为促进国内同行的探讨与交流,本文从国际上法庭采信证据的标准和要求出发,分析法庭证据评价范式转变的必要性,对法庭说话人识别技术的传统范式及发展现状进行评述,进而提出法庭语音证据评价的新范式,并对其基本内涵和核心要素进行解析,阐明其在法庭实践中的科学性、适用性及发展前景。
1 法庭说话人识别的传统范式
法庭说话人识别是指利用语音进行案件录音中说话人的身份辨识,即通过对案件中检材语音与样本语音的比较辨识,判断二者的同源性。其范式包括使用的技术方法和证据评价体系两个方面。
1.1 法庭说话人识别的技术方法
国际上,传统的法庭说话人识别的方法主要有以下前三种,后又逐渐发展形成了后两种[11]:
(1)听觉分析方法:该方法通过听觉感知来鉴别比较检材语音与样本语音的相似性和差异性,最后判断其同源性。
(2)图谱或听觉- 图谱方法:即所谓的“声纹”方法[12],该方法通过对检材语音与样本语音的听觉比较和声学图谱特征的形态比较,分析其相似性和差异性,最后判断其同源性。
(3)听觉- 声学- 语音学方法:该方法除了包括对检材语音与样本语音的听觉分析以外,还包括对其音段特征和超音段特征的声学- 语音学分析及其参数的定量测量,最后综合判断其同源性。
(4)声学- 语音学统计方法:该方法是听觉- 声学- 语音学方法的拓展,不仅包括对检材语音与样本语音的声学测量和比较,还包括对相关背景人群语音的测量、比较和统计分析[13]。该方法对检材语音与样本语音参数特征的相似性及其在相关背景人群中的典型性进行概率估计、统计建模和似然比计算,最后以似然比形式评估语音证据的价值[14-15]。
(5)自动识别方法:该方法采用计算机软件系统进行说话人的自动识别,包括需要专家人工干预的半自动识别和全自动识别两种。这两种方法的相同之处在于语音声学特征都是自动测量和提取的,不同之处是专家人工干预的程度不同。
就这五种方法而言,前两种主要基于专家的经验和主观判断,缺乏客观性、标准性和透明性,容易产生主观偏误。后三种主要基于声学参数的定量测量和比较,程序方法相对客观透明,并具有可重复性和可验证性。但是,声学-语音学方法一般要求检材语音与样本语音语种、方言、言语内容相关,还要有一定数量的相同可比音节,而自动识别则对此要求较低。
1.2 法庭语音证据评价体系
国际上,传统的法庭语音证据评价体系主要有下述前三种模式,后逐渐发展形成第四种模式:
(1)认定/否定/无结论模式:即所谓的绝对“二分法”,鉴定意见表述为“非认即否”,也就是说,检材语音与样本语音或者来源于同一人,或者来源于不同人。如果无法判定,即为无结论。
(2)后验概率模式:鉴定意见以概率形式来表述,即基于语音证据条件下,检材语音与样本语音来源于同一人的概率。这种概率可以用数字形式表达,如80%、95%等;也可以用信心程度的文字分级形式来表达,如很可能、非常可能等。
(3)英国模式:该模式目前仅在英国使用。该模式首先考虑检材语音与样本语音的特征一致性,然后考虑其特征的特殊性。如果对检材语音与样本语音的比较结果为不一致,就意味着二者来源于不同人。如果比较结果为一致,再考虑特殊性问题。特征的特殊性分为五个级别:不特殊、适中、特殊、很特殊、非常特殊。而特征一致并不代表检材与样本同源[16]。
(4)似然比模式:即基于起诉假设(也称同源假设,即假设检材语音与样本语音来源于同一人)和辩护假设(也称不同源假设,即检材语音与样本语音来源于不同人),给出这两个竞争假设条件下获得检材语音特征(证据)的相对概率,即概率之比。似然比的表达可以是数字形式,也可以是其文字分级表达形式[17]。
就这四种模式而言,前两种模式只考虑了检材语音与样本语音特征的相似性,对其在相关背景人群中的典型性(或特殊性)考虑不足[18]。第三种评价模式虽然考虑了检材语音与样本语音特征的相似性,也考虑了其在相关背景人群中的典型性,但是对其特殊性的五个等级分类并没有明确加以说明。目前,第四种模式被国际上认为是最正确和最符合逻辑的法庭证据评价模式[19]。
1.3 我国法庭说话人识别的基本范式
在国内,按照司法部2010年发布的语音同一性鉴定技术规范,语音特征分析的主要方法有:听觉检验、声谱检验、实验分析、统计分析等。按照公安部2010年的语音同一认定方法,语音同一认定的主要方法有:听辨分析、声谱分析、声谱分析与听辨分析相结合、定量比对等。然而,从目前国内各鉴定机构的实践来看,鉴定人员在具体的检验方法、技术流程和操作规范上并不统一。
按照2.2中的证据评价模式分类,我国语音证据的评价模式应该属于第二种后验概率中信心程度的文字分级表达形式。目前,按照司法部规范和公安部方法,语音同一性的鉴定意见均分为五级模式。尽管两者在用词上略有差异,但其基本含义是一样的,分为确定性结论(认定或否定)、非确定性结论(倾向认定、倾向否定)和无法判断三种。只有达不到任何指向性意见时,才做出“无法判定是否同一”的结论。
2 法庭语音证据评价的新范式
2.1 以似然比体系为逻辑框架
似然比体系是DNA检验的标准框架体系。在该框架体系下,法庭语音专家的任务就是针对法庭提出的两种竞争性主张(同一话者假设和不同话者假设),计算同一话者假设条件下获得检材语音特性的概率与不同话者假设条件下获得检材语音特性的概率之比—似然比LR值,为法庭提供证据支持假设的强度。例如,LR=100,其含义就是:“不管在引入该语音证据之前你的(先验)信念是多少,现在你应该100倍地相信检材与样本来源于同一人。
似然比LR的计算表达式如下:
式中,E代表证据,即检材语音的声学特征;p(E|H)为假设条件下的证据概率;Hss为同一话者假设,Hds为不同话者假设。LR的分子代表检材与样本特征的相似性,LR的分母代表检材特征在相关背景人群数据中的典型性。检材与样本的语音特征越相似、越不典型(特殊),证据价值越大,即更大程度地支持同一话者假设。反之,检材与样本的语音特征越不相似、越典型(普遍),证据的价值越大。传统的证据比较方法往往偏重比较特征的相似性,而忽略了特征在相关人群中的典型性。
LR值代表证据价值的大小以及证据支持起诉假设或辩护假设的程度。以1为分界,LR越大或越小于1,其证据价值越高。LR越接近于1,证据价值越低。然而,需要强调的是,法庭证据的价值不在于LR值究竟有多大,而在于它是否对事实裁定者的信念有更新作用。
2.2 利用相关数据、量化测量和统计模型计算似然比
2.2.1 相关数据
相关数据是指具有相关背景人群的语音特征的统计数据。语音证据评价的新范式不仅要求对语音特征进行量化测量,还要对特征数据的相似性和典型性进行概率评估和统计建模,以及对检验系统的准确性和可靠性评估,这些都必须建立在一个具有一定规模及代表性相关背景人群语音数据库的基础上[20]。这是新范式应用的前提和基础。
相关背景人群指的是检材语音说话人的所属人群,即符合检材语音基本特征的言语人群。这些基本特征一般包括年龄、性别、语种及方言口音等。具有代表性则是指相关背景人群语音数据库应代表或反映被检案件录音的实际条件,包括检材与样本的录音条件和讲话人的言语风格等。实际案件中,由于检材语音与样本语音往往来自不同信道、设备、环境和言语风格等,因而在选择相关人群语音数据库时,必须对检材语音与样本语音的不匹配条件给予充分考虑。
2.2.2 量化测量
在法庭说话人识别中,特征参数分为两种:一种是声学-语音学参数,另一种是自动识别参数。新范式不仅需要测量检材语音和样本语音的特征参数,还要测量相关人群数据库中所有语音的特征参数。相对参数的人工手动测量来说,自动测量的优势更为明显。而先前的研究也表明,相对声学语音学参数系统需要投入大量的人工测量成本来说,基于自动识别参数的法庭说话人识别系统更有优势和潜力,特别是在案件现实条件下[21]。
2.2.3 统计模型
对于语音特征参数的测量数据,需要计算这些数值的概率密度函数分布,即统计建模。利用嫌疑人的样本语音数据构建嫌疑人语音模型(嫌疑模型),利用相关背景人群的语音数据建立相关背景人群语音模型(背景模型)。常用的统计模型有两种:一种是多变量核密度(MVKD)模型[22],另一种是高斯混合模型(GMMs)。前者一般用于声学-语音学数据,后者一般用于自动识别数据。由于语音特征是多维的,因此参数数据的概率密度分布也不是固定不变的,这取决于参数本身的分布特点以及具体的案件录音条件。因此,哪种统计模型最合适还需要进行系统比较和实证检验。
2.2.4 似然比计算
似然比的计算方法如图1所示。其中,同源假设为检材语音与样本语音来自同一个人,非同源假设为检材语音与样本语音来自相关背景人群的不同人,使用的声学特征为基频F0。似然比就是检材语音特征值所对应的嫌疑模型的概率值与检材语音特征值所对应的背景模型的概率值之比。
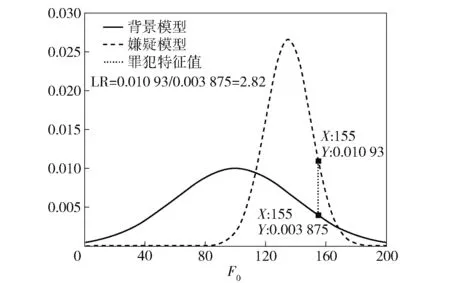
图1 案件语音的似然比计算
2.3 案件条件下系统的有效性和可靠性验证测试
任何法庭科学技术方法都应该表明其有效性(准确性)和可靠性(精确性),并且其错误率应该在法庭接受范围内。因此,必须对系统(包括检验程序和检验方法的组合)进行有效性和可靠性的实证测试[23]。
2.3.1 准确度评测
在似然比框架下,语音证据检验评价的任务不是给出检材语音与样本语音是否同源的二分性结论,而是要证明评价该语音证据是支持同源假设还是支持不同源假设以及支持的程度如何,即表明证据的强度。因此新范式下,系统的准确度评测指标为对数似然比代价函数(log-likelihood-ratio cost,Cllr)[24]。其计算公式如下:
式中,Ns和Nd分别是同一话者和不同话者测试对的数量,LRs和LRd分别是同一话者和不同话者测试对比较的似然比。log2(1+1/LRs)为同源惩罚值,log2(1+LRd)为不同源惩罚值。Cllr是连续值,计算Cllr必须首先计算对每个测试对的似然比结果的惩罚值。与事实不符的结果,偏离事实程度越大,惩罚的力度也就越大。总的说来,Cllr的值越小,表明系统的准确性越好。
2.3.2 精确度评测
精确度是指对相同样品进行重复测定后所得结果的重现性。在法庭证据检验中,结果的可重复性是系统评价的重要考量指标。目前,精确度的评价方法主要有两种,一种是频率学派的表示方法,即提供似然比的最佳估计值和该值可能存在的区间范围,例如LR的最佳估计值为900,95%概率在800~1 000之间。另一种方法是贝叶斯学派的表示方法,即仅报告最靠近似然比为1的边界值,例如95%的概率LR至少为850。尽管两种方法在表现形式上有一定差异,但无论采用哪种形式,在法庭上表明所用分析系统的精确度始终都是必要的。
2.3.3 代表具体案件条件
在实际案件中,每个案件的具体条件或多或少都会有所不同,因此不能一概而论,泛泛地说系统的准确性有多高、可靠性有多好,而是应该就被检案件的具体条件进行验证评估。即在最大限度接近实际检材和样本条件情况下进行系统测试,因为同一系统在某一案件中的性能表现并不代表它在其他案件中也会有相同的性能表现。
法庭语音比较系统验证一般通过Tippett图表示(见图2)。其中,横轴为以10为底的对数似然比,纵轴代表对数似然比的累积分布比例。向右上升的实线代表来自同一话者测试对的结果,纵轴上的值代表小于或等于横轴上对数似然比的累积比例。向左上升的实线代表来自不同话者测试对的结果,纵轴上的值代表大于或等于横轴上对数似然比的累积比例。虚线代表的是95%的贝叶斯置信区间(Credible interval,95%CI),表明系统的可靠性或精确度。
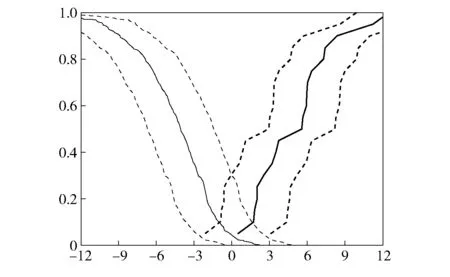
图2 系统测试的Tippett图
3 问题与展望
与传统范式相比,法庭说话人识别及其法庭语音证据评价的新范式采用似然比框架作为评价体系,通过计算起诉假设和辩护假设这两种竞争假设条件下获得证据的相对概率- 似然比来量化评估法庭语音证据的价值及其对控、辩双方主张的支持力度。这既是法庭科学领域的技术革新,也是法庭在事实裁定和证据采信方面的进步,对于提高法庭证据技术的科学性和促进司法公正具有重要意义。
法庭语音证据评价的新范式通过相关数据、定量测量和统计模型等程序方法,不仅可以量化评估语音特征的相似程度和典型程度,还可以保证检验判断的客观性、程序方法的透明性、检验结果的可重复性和可验证性,进而最大限度地减少分析评判的主观成分,降低或避免主观认知偏误。
目前,国际上已经将这种新的法庭语音证据评价范式应用于法庭说话人识别的司法实践[25-26]。2015年,欧洲法庭科学研究所联盟(ENFSI)还专门颁布了基于新范式的法庭说话人识别的最佳实践指南。在国内,关于新范式的理论研究和实验研究也已取得了较大进展[13, 15, 18],目前实证研究也取得了初步的成果[27]。这些研究工作为其将来的实践应用奠定了前提和基础。
当然,新范式在推行过程中不可避免地会面临一定的争议、阻力。一方面,传统的思维模式和惯式阻碍人们对新事物的认识和接受,另一方面“复杂”的逻辑推理和概率统计也确实令人“望而生畏”。因此,我们不仅需要更为深入的理论研究,还需要广泛的实证研究,特别是针对应实践中的具体细节问题,如基础语音数据的采集、相关背景人群的选择、语音特征的量化提取方法、参数统计模型的构建以及具有可操作性的标准与规范的制订等,都是需要研究解决的根本现实问题。
此外,在司法语音相关背景人群基础语音数据的建设和法庭说话人识别专家辅助系统的研制等方面急需进一步加强。由于传统的、基于语音专家分析和手工测量的声学- 语音学方法需要大量的人力投入,因此对于较大规模的相关背景人群语音特征的量化分析和手工测量几乎不可能实现。因此,语音特征的分析及其参数测量提取必须朝自动化方向发展,这样才能最大程度地实现人工专家检验与自动识别技术的优势结合,最终使我国的司法语音检验走向客观化、标准化、自动化和透明化。
猜你喜欢
甘肃教育(2021年10期)2021-11-02 06:14:08
福建江夏学院学报(2021年6期)2021-08-10 08:22:08
民主与法制(2020年16期)2020-08-24 06:54:44
大连民族大学学报(2020年2期)2020-06-16 03:12:56
小火炬·智漫悦读(2019年2期)2019-04-30 02:43:10
英美文学研究论丛(2018年1期)2018-08-16 03:01:00
现代养生·下半月(2017年10期)2017-03-23 16:28:28
公民与法治(2016年7期)2016-05-17 04:11:15
分子影像学杂志(2015年3期)2015-12-04 03:28:54
海峡科学(2015年11期)2015-09-19 06:48:18
