
数据预处理技术和机器学习方法在 质子转移反应质谱中的应用
2018-10-11 01:34陈一冰褚美娟蒋学慧郭冰清
质谱学报 2018年5期
孙 运,陈一冰,褚美娟,蒋学慧,汪 曣,郭冰清
(1.天津大学精密仪器与光电子工程学院,天津 300072; 2.中国人民解放军总医院呼吸内科,北京 100853)
质子转移反应质谱(PTR-MS)由奥地利因斯布鲁克大学的Lindinger等[1]研发于20世纪90年代。经过20多年的发展,PTR-MS的应用从早期的环境污染物分析,扩展到食品科学、生物制药、医学诊断、防化安保等领域,主要用于挥发性有机物(VOCs)检测[2]。VOCs的种类多达上万种,比如,在食品领域,水果的香气物质有2 000多种;在医学领域,人体中呼气、血液、尿液等样品释放的VOCs均在几百种以上[3]。如何更好地在复杂未知混合物中进行VOCs成分的检测,并通过数据分析深度挖掘VOCs的特征是非常重要的。
不同于电子轰击源,PTR-MS采用的是一种软电离方式,通过质子转移反应将VOCs离子化。这是一个需要精密控制的过程,温度、湿度、压强、电场的变动都会对仪器的信号输出产生影响。如果直接用仪器产生的数据来进行统计分析,会带来极大的误差,所以,数据的预处理必不可少[4-5]。随着化学计量学和软件技术的发展,以及蛋白组学、代谢组学等领域分析需求的促进,机器学习算法得到了极大的应用和推广,能够很好的帮助人们进行特征提取,解读数据中有价值的信息[6-8]。目前,已经有很多机器学习方法应用到PTR-MS的数据分析中[9]。
1 质子转移反应质谱仪
PTR-MS主要包括进样系统、空心阴极放电源、漂移管、质量分析器、检测系统5大部分[10-11]。其中,空心阴极放电源主要用于产生水合氢离子(H3O+)。随后,H3O+进入漂移管,与VOCs在电场和气流作用下不断碰撞。在碰撞过程中,质子亲和势比水高的VOCs与H3O+发生质子转移反应,这些携带质子的VOCs以离子形式进入后续的质谱系统。在 PTR-MS中,四极杆、离子阱、飞行时间等质量分析器各具特点[12-14]。其中,四极杆和飞行时间质量分析器的应用最多。四极杆质量分析器具有良好的定量检测能力,最早被用作PTR-MS的质量分析器[12]。飞行时间质量分析器根据不同质量离子到达检测器时间的差异实现对离子的鉴别,具有质量范围宽、分辨率高等优点,并且在高分子质量和混合物分析方面显示了很大优势[14]。
2 质子转移反应质谱数据预处理
从PTR-MS仪器中得到的检测信号是原始数据,需要进行科学合理的预处理才可用于统计分析。数据预处理通常包括降噪、基线校准、峰形校准等[15-17]。PTR-MS数据预处理流程示于图1。

图1 PTR-MS数据预处理流程
Fig.1 Process of the data preprocessing in PTR-MS
2.1 降噪
PTR-MS仪器噪声主要来源于电子器件,此外,也与传输线及屏蔽状况、仪器环境温度等因素有关。仪器噪声往往表现为随机噪声,对于这种随机误差的处理,采用多次测量求取平均值是比较常规的做法,但是该法并不适用所有场合。
Cappellin等[4]强调了质量轴的稳定性是均值法的前提。相比于四极杆质量分析器,飞行时间质谱的谱图质量轴不稳定性更加突出。飞行时间质谱检测中,一次脉冲产生的离子信号非常小,需要叠加多次脉冲产生的离子信号。每次分析都有一定的扫描速度,可能有400张谱图(即400次扫描),甚至是更多的谱图被叠加。对于一个质量数,需要每一张谱图的轴点位置都得到校正,均值法才会可靠。虽然在分析样品之前都会利用标准品对质量轴进行校准,但受限于标准品的个数,只有少数质量数能够得到校准。因此,该课题组采取了较为简单的操作,不改变信号值,仅根据校准的质量数偏移谱图。采用该方法,所得的质量误差小于1×10-6。
Hewitt等[18]提到均值法在VOCs浓度较高并且波动较大时不适用。他们对噪声进行了定量分析,从而优化驻留时间及补偿仪器输出信号。利用m/z63、69、70这3个质量数的信号对仪器噪声进行定量计算,调节驻留时间范围为0.1~20 s,每个质量数至少采样170个数据点,并定义了噪声统计值(noise statistic,NS):
(1)
其中,cps(counts per second)表示离子信号计数值。结果发现,仪器噪声近似为高斯分布。对于设定的阈值(平均值±2×NS),检测值中有2%在上偏差范围内,2%在下偏差范围内,并且这一规律独立于质量数、驻留时间、计数率。基于此,他们提出了“2%”法则,认为在阈值(平均值±2×NS)以外的数值变化很有可能不是噪声,而是由真实浓度变化引起的。
此外,还可以应用很多标准的降噪方法[19-20],特别是小波变换[21]。小波变换具有多分辨率性、尺度内相关性和时域局部化等特点,适用于不稳定信号的平滑降噪,同时不引起信号失真,使信号的原始特征得到最大程度的保留。
2.2 水团簇因素的补偿与归一化
在PTR-MS漂移管内,会有水团簇离子生成,这些团簇离子使得谱图复杂化。虽然可以通过增强漂移管内的E/N值(E为电场强度,N为气体数密度)抑制团簇的生成,但不能完全消除。考虑到团簇效应,Gouw等[22]引入了一个新的参数XR进行归一化。通过实验测定,绝大多数VOCs的XR值为0.5,但苯和甲苯的XR值接近0,因为它们与H3O+(H2O)的反应较慢。如果XR为负值,说明有一部分H3O+(H2O)的碎片峰在漂移管和质量分析器的接口处生成。据此对计数值进行归一化,记为NCPS(normalized counts/s):
(2)
Tani等[23]定义了SCPS,对检测的离子进行归一化。SCPS是所检测的物质信号总离子数,按照106计数的母离子,对2 kPa漂移管压强进行归一,示于式(3):
(3)
Sinha等[24]采用PTR-MS检测吡咯,讨论了湿度的影响。以cps计量的检测信号按照漂移管压力200 Pa,温度为298.15 K以及1.0×106母离子的条件进行归一化,并分为4种情况:1) 只有m/z19;2) 只有m/z19、37;3) 只有m/z19、37、55;4) 只有m/z19、37、55、73。
(4)
这里x=1,2,3,4,分别对应上述4种情况。
2.3 计数值转化浓度的计算方法
通常,VOCs的检测都需要有对应的标准物质,利用标准曲线进行定量计算。尽管这种方法的精度较高,但不是所有的物质都有标准品,并且在检测未知混合物时很难确定标准品的种类。PTR-MS可以通过化学反应计算VOCs浓度。当VOCs分子的质子亲和势大于水时,即可发生质子转移反应。用R表示VOCs分子,上述反应可以用式(5)表示:
(5)
式中,k表示质子转移反应过程的反应速率常数。参照文献[1,25]报道,在反应区末端的产物离子浓度[RH+]可以表示为:
[RH+]=[H3O+]0[1-e-k[R]t]
≈[H3O+]0[R]kt
(6)
式(6)中,[H3O+]0为反应试剂H3O+的初始浓度,[R]为待测物R的浓度,t为离子通过漂移管的平均时间。因为待测物R的浓度远小于H3O+的浓度,其只与少量的H3O+发生质子转移反应,H3O+信号强度在反应前后可以近似不变。由此,可得待测物R的浓度计算公式为:
(7)
式(7)中,计数率i[RH+]和i[H3O+]为待测物和H3O+的离子计数值,可由检测系统测得。它们与RH+和H3O+的浓度成比例,比例系数分别为TRH+和TH3O+,反应速率常数k可通过查阅文献得到,平均反应时间t可以直接测得,也可以通过计算公式求出[26],这里不再叙述。
从式(7)可以看出,反应速率k对待测组分浓度的影响很大。Zhao等[27]利用量子化学方法得出反应物结构,然后通过平均极化理论(average-dipole-orientation, ADO)计算了78种烃类物质和58种非烃类VOCs与H3O+的质子转移反应速率。新计算的反应速率常数可以为PTR-MS定量检测VOCs提供可靠的参考值。
Keck等[28]对浓度计算方程做了进一步修正。他们提出,RH+的浓度在漂移管入口到出口间不断增加,并且增速大于H3O+浓度减少的速度,这种流动效应会造成计算结果的偏差。为此,考虑RH+浓度随着时间变化的函数,经过一系列推导,对浓度计算式(7)进行了修正。
3 多变量统计分析
PTR-MS能够获得多达500个不同m/z的谱图,但相比于色谱和光谱等仪器,谱图信息仍不够丰富。此外,PTR-MS仪器的分析检测不含分离过程,谱图中的单个谱峰可能来自不同物质。所以,针对少量的具有代表性的物质成分进行快速检测,弥补因缺少分离过程造成的信息不足是PTR-MS谱图分析的一个策略。机器学习方法提供了多种渠道分析和理解复杂的数据,帮助获取有用信息[29-31]。通常最初的算法选择无监督模式,用于数据探索和挖掘,各个数据的权重是相同的。该算法能够在缺乏经验的前提下,研究VOCs与样品间的复杂关系。当有了先验知识,有监督模式算法将是更好的选择。
3.1 无监督学习方法
3.1.1主成分分析 主成分分析(principal component analysis, PCA)是机器学习中应用非常广泛的无监督学习方法。PCA方法是通过构造原随机变量的一系列线性不相关的组合反映原变量的信息[32]。其目标是用低维子空间表示高维数据,使得在误差平方和意义下能更好地描述原始数据。该法常被用于食品领域中产地、种类的区分[33-41]。
Boscaini等[33]用PCA法处理PTR-MS检测数据的结果示于图2。图中的每一个点对应一种样品,每条线对应一个质量数。线与线之间的角度代表二者的相关性,角度小说明正相关,反之说明相关性较差。从图中可以看出,PCA方法很好地区分了4种不同品种的葡萄酒。
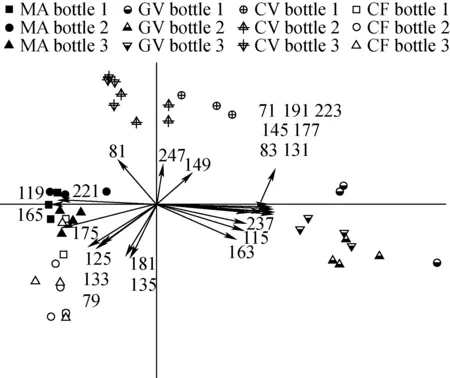
注:缩写字母MA、GV、CV、CF代表4种不同品种的葡萄酒 图2 PCA分析举例Fig.2 An example of PCA
Farneti等[34]用PCA法找出了21种质量数用于描述番茄挥发物的模型,并区分了番茄的不同成熟阶段。张丹丹等[35]将PTR-TOF MS采集到的3个不同产地的闽北水仙茶的挥发性指纹图谱进行数学统计分析,利用PCA法提取了3个主成分,累计贡献率达到84.66%,表明PTR-TOF MS 结合分类算法可以有效区分不同产地的闽北水仙茶。除此之外,PCA法常作为其他多变量分析法的第一步处理[42-44]。
从传统主成分分析方法的计算过程可以看出,进行PCA计算的关键是算出变量的协方差矩阵或者相关矩阵,相关矩阵可以从协方差矩阵得到,所以可以把问题都归结为协方差矩阵的计算。这个过程对离群值非常敏感,所以导致接下来所计算的相关矩阵、特征值和特征向量也受其影响,产生不合理的结果。协方差矩阵对离群值敏感,主要因为其计算过程中要使用均值向量,而均值向量只是对多维数据的简单求平均值,这种计算方法很容易受到离群值的影响,使得协方差矩阵不是稳健的估计量。稳健主成分分析方法则可以有效解决这个问题,通过构造一个稳健的协方差矩阵,降低离群值对协方差矩阵的影响[45]。
3.1.2层次聚类分析法 另一种常用的无监督统计方法是聚类分析。聚类分析是根据各个样品或指标的数量对事物进行分类,在分类过程中不必给出分类的标准,是一种探索性的分析。聚类分析中的层次聚类分析法(hierarchical cluster analysis, HCA)是最常用的,其基本思想是将N个样品看成N类,然后将性质相近的2类合并为1个新类,再从剩下的N-1类找出最接近的2类合并成N-2类,以此类推,直到所有样品合成一类。这个过程可以用一系列的嵌套聚类树完成[46-47]。
Sánchezlópez等[48]利用PTR-TOF MS结合HCA研究了生产浓缩咖啡的热水萃取工艺,并利用Ward最小方差法和半平方欧氏距离法对46个初步确定的化合物规范化时间强度特征进行了层次聚类分析。Ciesa等[49]用PTR-MS法检测7种现代和35种老式苹果品种,分析单个水果在收获和存储期间释放出的VOCs信息,用HCA法评估了各品种释放的VOCs差异。Pozo-Bayón等[50]用HCA法对PTR-MS和GC/MS检测的奶酪饼干数据进行分析,研究其存储时间。
但在处理过程中,每次合并分类将会直接影响接下来对新类的处理,造成每一个步骤的效果变差,降低聚类结果的质量。针对此问题,人们发展了双聚类算法,通过分别对矩阵的行和列聚类,然后合并聚类结果[51-52]。
3.2 有监督学习方法
有监督学习方法利用已知某种特征的样本进行训练,建立数学模型,再利用这一模型将所有新数据样本映射为响应的输出结果,从而实现预测的目的。因此,有监督学习方法的主要目标是发现样本与变量响应之间的关系。为了检测判别模型的识别能力,通常采用另一组已知类别的样本组成测试集,将训练中得到的正确判断率作为识别率,用测试样本集所得到的准确识别率称为预测率,一般情况下,识别率均优于预测率[53]。有监督学习方法包含很多,这里只介绍PTR-MS中常用的分析方法。
3.2.1偏最小二乘判别 偏最小二乘判别分析(partial least squares discrimination analysis, PLS-DA)是偏最小二乘回归分析的变形,是在很大程度上可以取代主成分分析、多元线性回归的判别分析统计方法。不同于主成分分析,PLS是同时对自变量矩阵(样本数据矩阵)X和相应变量Y进行分解,并力图建立它们之间的回归关系。它适用于解释多变量,并且存在多重共线性、观测样本少以及干扰较大的情况,尤其对于二元分类问题,可以获得很好的分类效果[54-55]。
Ruth等[56]通过PTR-MS与PLS-DA的结合,成功区分了牛奶脂肪。首先,利用PTR-MS分析、感官分析和经典化学分析3种方式评估食品的处理过程。随后,利用PLS-DA处理PTR-MS数据,预测基质(黄油/奶油)以及样品的感官等级。采用十倍交叉验证机制模型,正确区分了89%的样品。结果表明,PTR-MS和PLS-DA的结合是质量控制和制度控制的潜在应用方法。
Nooshin等[57]用PTR-MS法分析了来自5个欧洲国家的192个橄榄油样品的顶空挥发性化合物,提出了3个不同偏最小二乘法PLS-DA模型,分别用于区分样品的原产国、意大利国内的原产地和更小范围的产地,并用交叉验证方法评估模型的正确率。第一个模型对于区分橄榄油的原产国有86%的正确率,其中只有法国的正确率较低,为40%;第二个模型,只适用于区分意大利国内不同原产地的橄榄油,其正确率达到了74%;第三个模型,则用于意大利国内更小地域的橄榄油产地区分,正确率只有52%,这可能是因为在该尺度内橄榄油VOCs成分的组成及比例较为近似。
随着对PLS-DA法的应用与研究[58-60],对该方法进行了很多改进。正交偏最小二乘判别分析(orthogonal PLS-DA, OPLS-DA)利用正交信号校正思想,滤除了自变量矩阵和相应变量矩阵的无关信息,所以OPLS-DA能够更好地区分组间差异,提高模型的有效性和解析能力,更加适用于多类区分问题[61]。
3.2.2随机森林 决策树是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树[62]。Brieman等[63]提出的随机森林(random forest, RF)算法是一种包含多个互不关联决策树的分类器,其构建主要考虑数据的随机性选取和待选特征的随机选取,对异常值和噪声具有很好的容忍度,且不容易出现过拟合。
Kistler等[64]利用PTR-TOF首次研究了饮食特点对营养性肥胖症老鼠呼气的影响。在呼气成分数据分析中,用RF进行特征识别,但是存在信息丢失、分类效果差等问题[65]。为了解决这些问题,他们提出了RF++算法,在传统RF算法中执行基于主题的引导过程,通过包外误差对模型进行评估。实验结果表明,从以植物为原料的饮食到几种半纯化加工食物的变化,会影响实验鼠呼气中VOCs的特征。
Granitto等[66-67]利用随机森林-递归特征消除(RF-RFE)算法对PTR-MS分析工农业产品产生的谱图进行相关特征鉴别,并与支持向量机-递归特征消除(SVM-RFE)方法做比对,利用多次重复的实验估计无偏的泛化误差。结果表明,在小种群的特征提取方面,RF-RFE法比SVM-RFE法更可靠,RF-RFE比SVM-RFE更适用于指纹识别工农业产品的PTR-MS谱图。
3.2.3其他有监督学习方法 判别分析是在分类已经确定的条件下,根据某一研究对象的特征判别其类型归属的一种多元统计方法。按照数学模型可分为线性判别和非线性判别。其判别准则有多种,例如费舍尔准则、最小平方准则、最小距离准则、最大概率准则等[68]。Thekedar等[69]利用线性判别分析方法(linear discriminant analysis, LDA)将病人和对照组的呼气成分与室内空气成功进行了区分,进一步减小了外源性环境因素产生的VOCs背景影响。
人工神经网络(artificial neural network, ANN)是由大量处理单元互联组成的非线性、自适应信息处理系统。它是在现代神经科学研究成果的基础上提出的,试图通过模拟大脑神经网络处理、记忆信息的方式进行信息处理。Cancilla等[70]利用ANN模型对18位肺癌患者和22位健康人员的呼气成分的PTR-MS谱图进行了分析,讨论了是否考虑葡萄糖摄取因素下的统计结果。当不考虑葡萄糖摄取因素时,只用8种质量数作为独立变量就可以建立一个MLP模型,精准度达到93%,所挑选出的质量数有助于检测和诊断肺癌疾病。
3.3 机器学习方法在PTR-MS谱图分析中面临的困难
不同的机器学习方法有各自的优缺点,这决定了它们的适用性。关于算法本身的特点,这里不再论述。本文主要结合PTR-MS谱图的特点,介绍这些算法在应用中面临的困难。相比于GC/MS,PTR-MS虽然具有快速检测的特点,但是定性能力不足,缺少色谱分离过程,且只能获得单一质荷比信息,所以有很多成分无法区分,其谱图中的同一质荷比信号可能对应多个VOCs成分。具有高分辨能力的PTR-TOF MS虽可进一步分离谱图信号,但仍不能分辨同分异构体,例如,二甲苯和乙苯,丙酮和丙醛等。另外,利用质子转移反应这种化学软电离方式得到的VOCs质谱峰,也会存在多个碎片离子峰。例如,乙酸乙酯(C4H8O2)与H3O+发生质子转移反应后,谱图中会有m/z61、43、89三种质荷比信号,它们的比例随着漂移管内E/N比值的大小而变化。所以,PTR-MS中的每个质荷比信号可能对应多个VOC,而每个VOC在PTR-MS产生的谱图中可能对应多个质荷比信号,但目标成分通常是痕量的,极有可能被干扰离子掩盖。此外,同一VOC产生的不同质荷比信号,其内在的比例关系可能干扰统计分析算法在一些筛查标志物实验中的应用。这些问题将给PTR-MS用于VOCs的检测分析带来诸多困难,尤其是对未知混合物的分析。
4 总结与展望
PTR-MS在VOCs检测方面有着独特的优势,随着其在多个领域的广泛应用,数据处理方法面临着越来越多的问题和难点。本文总结了符合PTR-MS仪器特点的数据预处理方法和机器学习方法在PTR-MS谱图分析上的应用。在数据预处理方面,重点描述了无需标定的浓度计算方法;在数据分析方面,概括了不同算法的特点和不足,并归纳了不同算法的典型应用。
本课题组在PTR-MS仪器研制和应用方面做了一些研究并取得了阶段性成果。目前,本课题组自主研制的一台PTR-MS仪器整机已搭建完成,正处于性能参数调试阶段。在呼气检测和食品领域进行了应用研究,取得了一定的成果[71]。李子晓等[72]对呼气成分分析中湿度和CO2的影响进行了分析。申丹宁等[73]用PTR-MS检测了不同品种和同品种不同产地橙汁的顶空挥发性气体,通过PCA区分了不同品种和产地的橙汁,并用费舍尔判别法建立了橙汁品种和产地的鉴别模型。郭冰清等[74]利用PTR-MS对肺癌患者呼气中特异性VOCs进行研究,建立了标准的临床试验方案,利用PTR-MS对40名肺癌患者、32名健康志愿者呼出气体中的VOCs进行检测,并进一步采用秩和分析、人工神经网络、随机森林、支持向量机和二元Logistic回归对全部呼气数据进行数据挖掘,发现了3种高可靠性的呼气特征生物标记物,并建立了相应的分类模型。结果表明,利用支持向量机建立的分类模型灵敏度为99.2%,特异性为98.5%,可对未知人群的患癌情况进行早期预判。
随着大数据时代的到来,不同仪器平台的整合、不同样品的数据融合是未来趋势。在这种背景下,PTR-MS会面临更多的挑战。合理的数据预处理技术以及机器学习方法,将会对数据分析起到越来越重要的作用,使PTR-MS技术的应用更加广泛。
猜你喜欢
趣味(数学)(2021年9期)2022-01-19
中学生数理化·七年级数学人教版(2021年6期)2021-11-22
中学生数理化·七年级数学人教版(2021年6期)2021-11-22
中学生数理化·七年级数学人教版(2021年6期)2021-11-22
中学生数理化(高中版.高二数学)(2020年2期)2020-04-21
中成药(2017年4期)2017-05-17
海峡科技与产业(2016年3期)2016-05-17
中学生数理化·高三版(2016年9期)2016-05-14
Coco薇(2016年2期)2016-03-22
Coco薇(2015年1期)2015-08-13
