
不确定性理论在通信目标识别中的应用
2018-10-09 03:15程嘉远于小红
火力与指挥控制 2018年8期
程嘉远,于小红
(1.长春理工大学电子信息工程学院,长春 130022;2.江苏自动化研究所,江苏 连云港 222006)
0 引言
在作战过程中,作战双方会采取伪装、隐蔽、欺骗和干扰等技术手段,使得目标的可观测性越来越低,从而带来目标信息的不精确、不完整、不可靠等不确定性问题,造成目标识别结果正确性低、跳变、甚至无法识别等。为了解决信息的不确定性对目标识别的影响,提高识别结果的稳定性和识别正确率,人们提出了多传感器目标综合识别方法,对多个传感器的识别结果进行融合。还提出了新的识别方法,如模糊识别、证据理论等。
模糊识别法利用模糊理论进行目标识别。证据理论由Dempster于1967年提出,后经Shafer加以扩充和发展,所以证据理论又称为DS证据理论。DS证据理论信任区间的表示方法和推理方式能够很好地表示“不确定性”、“未知”等认知学上的重要概念,符合人们的逻辑思维习惯,逐渐成为目标综合识别采用较为广泛的一种融合方法。DS证据理论能有效地解决低证据冲突问题,但在证据冲突较高时,会出现与直觉相悖的识别结果。为此人们相继提出多种改进方法不断完善DS证据理论,如Yager改进方法[1]、Murphy 改进方法[2]、邓勇方法[3]等。改进方法一般分为两类,一类是改进组合规则,另一类是对冲突证据再分配。DSmT理论[4]由法国学者Dezert等人在2002年提出,它是经典证据理论的延伸,DSmT保留了证据冲突项作为信息融合的焦元,解决了证据冲突时的组合问题。DSmT在处理高冲突、不确定、不精确的证据源时有较强优势,不仅能解决一般的静态融合问题,也能处理复杂的动态融合问题,但计算量大。
1 不确定性理论
不确定性推理是建立在不确定性知识和证据的基础上的推理,从不确定的初始证据出发,通过运用不确定性知识,最终推出具有一定程度的不确定性但却又合理或基本合理的结论的思维过程[5]。模糊理论、DS证据理论、DSmT等理论因能很好地表示不精确、不完整、不可靠等不确定性知识,在实际工作中得到了广泛应用。无论是模糊识别还是DS证据理论,在目标识别中,都以可信度的形式给出识别结果的各种可能性,解决了传统识别方法非此即彼的问题。
1.1 模糊识别
利用模糊理论进行目标识别,首先要确定隶属函数。隶属函数的确定,一般有模糊统计方法、模糊分布方法等。常见的模糊分布法有:
1)矩形函数
2)梯形函数
3)正态分布函数
4)柯西分布函数
式(1)~式(4)一般称为中间型(矩型、梯形、正态型、柯西型)隶属函数,由式(1)~式(4)可衍生出偏小型(降半矩型、降半Γ型、降半正态型、降半柯西型、降半梯型)、偏大型(升半矩型、升半Γ型、升半正态型、升半柯西型、升半梯型)隶属函数。在通信目标识别时,可以根据参数的不同而选用不同的隶属函数,具体可见3.1节。
1.2 证据理论
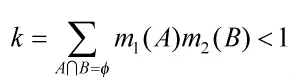
1.3 DSmT理论
DSmT理论是DS理论的延伸。与DS证据理论相比,它不要求识别框架中的元素互不相容。假设识别框架,通过对Θ中的元素进行并和交运算产生超幂集DΘ,则函数。如果满足式(7)中的条件,则称m为基本概率赋值函数。
假设在识别框架Θ下有两个独立证据,基本概率赋值分别为m1和m2,在DSmT模型下,组合规则为:
比较式(6)和式(8)可以发现,DSmT保留了矛盾焦元,不需将其基本概率赋值进行归一化。
2 通信目标识别过程
由于通信侦察设备提供的信息较少,而且不可避免地存在误差,因此,仅靠一次侦察测量信息识别目标,难以得到较好的效果。在实践中通常利用数据融合方法,将多传感器多周期的目标识别结果信息进行有效融合以提高目标识别率。在空域上对多个通信侦察设备信息融合,在时域上对多个时间周期的识别结果进行融合。图1为通信目标识别的基本过程。
目标识别过程如下:
1)传感器信息可信度估计:基于专家先验知识,估计传感器信息先验可信度。根据传感器实时探测数据,对先验可信度进行修正,获取传感器信息可信度。
2)数据库匹配:把通信侦察设备上报的信号特征参数向量与该体制下所有通信进行匹配,选取大于阈值的匹配度对应的模式形成一个证据,为后续的不确定性推理服务。
3)目标相关:根据传感器上报目标位置信息以及特征级目标识别结果,综合考虑位置和身份信息进行目标相关处理,获取不同传感器针对同一目标的相关关系。
4)目标身份信息冲突检测:通过计算各传感器识别结果(证据)之间的冲突系数对目标身份信息冲突情况进行检测,找到与其他传感器识别结果冲突严重的传感器识别结果。
5)人工复判:提取出与其他证据冲突严重的证据,提示决策者进行复判。人工复判要借助冲突证据获取传感器的信源可信度进行后续判断。若信源可信度较低,则可命令传感器对此目标进行查证或者放弃此证据(不参与后续融合);若信源可信度较高,则可进行查证或进入冲突证据处理过程。
6)不确定性推理:采用DS证据理论、模糊理论等不确定推理技术对多个证据进行推理及组合,最大程度地消除冲突证据带来的影响,获得目标身份信息,为后续决策提供支持。
7)决策:确定通信目标识别的最终结果。一般选取最大可信度的通信型号为最终识别结果。
3 不确定性推理在通信目标识别中的应用
现有通信侦察设备有短波、超短波、数据链侦察设备等,能够侦察的通信目标参数包括频率、频点个数、信号调整方式、信号带宽、信号电平等。本文主要针对模糊匹配、不确定性推理进行讨论。
3.1 基于模糊理论的数据库匹配方法
数据库匹配方法有模板匹配、模糊匹配等多种方法。模板匹配主要将测量模板与样本模板(数据库中的模板)进行对比,计算测量模板与样本模板之间的距离。计算的距离有Manhattan距离、Euclidean距离、City Block距离等。模糊匹配主要利用模糊理论进行数据库匹配,模糊匹配的关键是隶属函数的确定。
3.1.1 隶属函数的确定
隶属函数的选择与具体应用有关,应根据具体的应用选择合适的分布函数。通信目标参数包括频率、频点个数、信号调制方式、信号带宽、信号电平等。频点个数、信号调制方式、信号类别等参数是离散型参数;工作频率、信号带宽、信息电平等参数是在一定的范围内连续变化的,属于连续型参数。离散型参数可选用离散型隶属函数。对于连续型参数,各种具体通信信号的特征参量的值总是在某一平均值附近摆动,且摆动范围一定,可选用正态型和柯西型隶属函数。
1)离散型隶属函数
信号调制方式的隶属函数定义如下。
2)正态型隶属函数
通信目标频率的正态型隶属函数如下,其中RF为某类通信信号的平均射频,ΔRF为射频摆动的范围,δ为正态型隶属函数的展度。
3)柯西型隶属函数
通信目标频率的柯西型隶属函数如下,其中RF为某类通信信号的平均射频,ΔRF为射频摆动的范围,σ为柯西型隶属函数的展度。
3.1.2 模糊匹配推理
根据式(12),可以计算出第j个测量分别属于n个通信类型的隶属度。
根据式(13),对dj进行归一化处理,得到第j个测量判定为第i个通信类型θi的基本概率赋值。
3.2 基于模糊隶属度的DST与DSmT自适应融合算法
DST证据能够较好地解决低证据冲突问题,但在证据高度冲突时,会产生与直觉相悖的融合结果。DSmT理论能够很好地解决证据冲突时的融合问题,但是由于其焦元过多,导致计算复杂,计算量大、收敛速度过慢。为了充分利用DST和DSmT的各自优点,研究人员提出了DST与DSmT的自适应融合算法[6-9]。本文利用DSmT的思想,保留证据的冲突项作为融合焦元。在DSmT的比例冲突再分配准则 PCR1~PCR6[4]中,PCR5 组合规则的分配精度公认最高,但是在冲突证据相当时,将冲突信息加权分配给造成冲突的两个焦元X和Y,会出现融合结果聚焦不足现象[10-13],不利于最终决策,且计算复杂度随着非空焦元数量的增多呈指数倍增长。本文在PCR5组合规则基础上,提出了一种自适应的融合算法。该方法将部分冲突信息分配给造成冲突的两个焦元X和Y,将部分冲突信息按DST组合规则进行归一化处理。
假设有两个相互独立的证据源,基本概率赋值分别为m1和m2,则本文提出的融合算法组合公式为:
从式(14)可以看出,当σ=0时,本文算法退化为DSmT算法,所有的冲突信息按照一定准则被分配给产生冲突的焦元;当σ=1时,本文算法退化为DST算法,所有的冲突信息被平均分配到整个分配空间;当时,综合利用了DST与DSmT对冲突信息的处理方式,仅有部分冲突信息被保留,剩余的冲突信息则被平均分配到整个分配空间。
在已有的DST和DSmT融合算法中,需要预先设置控制因子阈值。如果控制因子大于设定阈值,选用DST融合算法,小于阈值,则选用DSmT融合算法。然而阈值的选择比较困难,选择不好会产生错误的结果。
证据之间的相似度反应了证据之间的冲突程度,证据相似度越高,冲突越小。本文选用证据之间的相似度为控制因子,证据间的相似度,为证据间的距离。
证据间的距离计算法有基于隶属函数的距离、Jousselme距离、Tessem 距离等[11],Jousselme距离、Tessem距离考虑焦元的相容性问题,有时也会出现不合理现象。例如下面有3个证据
采用基于隶属函数方法计算证据之间的距离,如式(15)所示。
式(15)中的μ为隶属函数,∧为合取运算(取小),∨为析取运算(取大)。
3.3 算例
假设有两个通信侦察设备,通信类型分为{A,B,C,D},在不同周期数据库匹配后获得目标隶属函数为:
分别利用经典DS理论、DSmT理论、PCR5规则、本文证据融合4种融合算法对上述证据进行融合,结果如表1所示。在6个证据内容不变时,调整6个证据融合次序,PCR5规则和本文证据融合见下页表2所示。
从表1可以看出,由于证据2否定了A,即使其他证据都支持A,经典DS融合算法得到的融合结果对A的分配始终为0,否定通信类型A,产生了与直觉相悖的结果;从表1看出随着通信分类的增加,DSmT计算量大、计算复杂度明显增加。同时由于将冲突信息分配给了产生冲突的焦元,并增加了焦元个数,使得概率赋值过于分散,收敛速度过慢;PCR5规则将冲突信息分配给了产生冲突的焦元,分配精度较高,融合结果比较理想;本文的自适应融合算法与DSmT算法相比,大大减少了计算量。随着新证据的加入,m(A)的增大速度明显快于其他算法,在加入第4个证据后,其他分类概率分配略有减小,m(A)继续增大。可以看出,本文的自适应融合算法的收敛性在4种算法中是最好的。
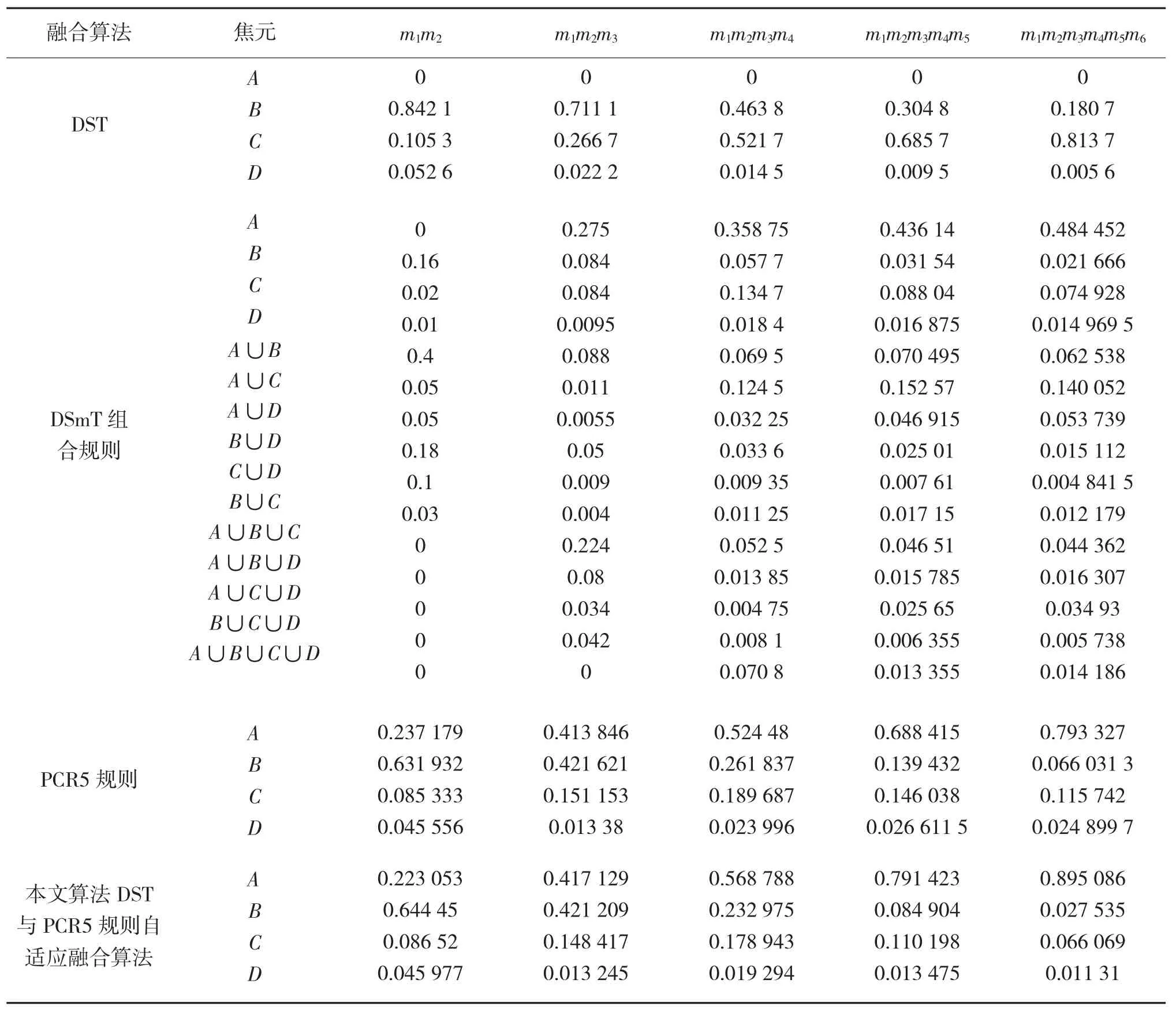
表1 4种方法融合结果
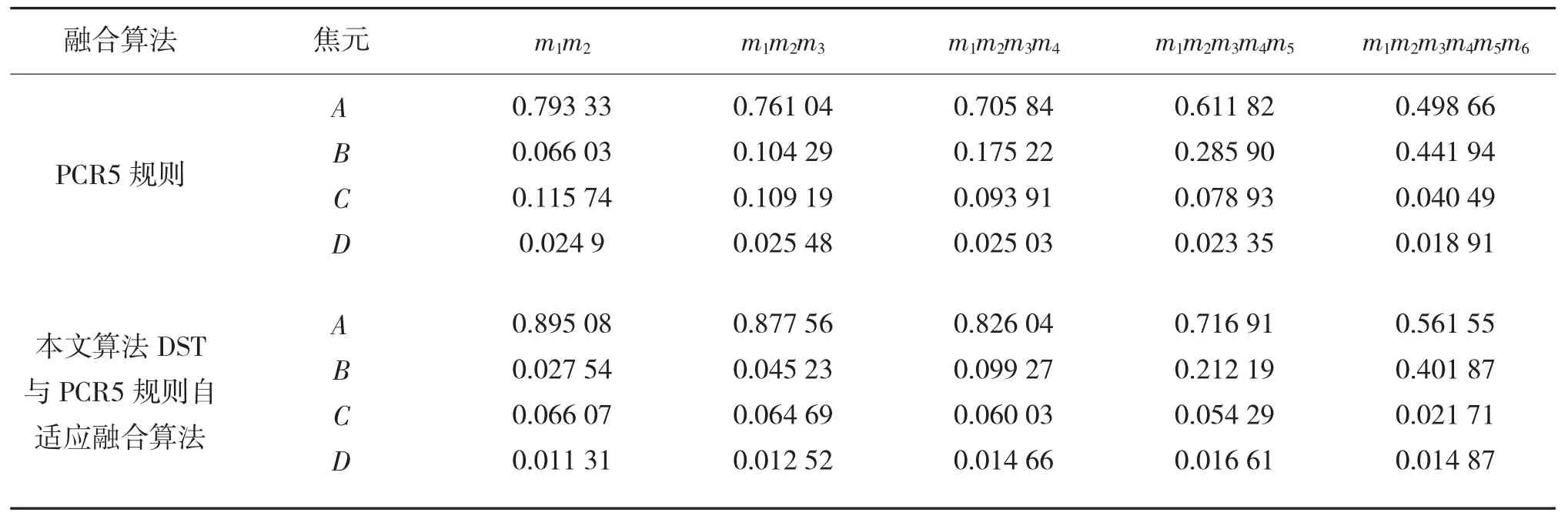
表2 不同证据融合次序下的PCR5规则和本文算法融合对比
从表2可以看出,无论融合次序怎么调整,本文算法融合精度都高于PCR5规则,特别在融合次序为时,PCR5规则出现融合结果聚焦不足现象,不利于最终的决策。分析表1和表2结果,无论哪种情况本文提出的算法融合结果都是最好的。
4 结论
为了解决通信侦察信息带来目标识别结果的不确定性,本文提出了空域时域识别融合模型,并利用模糊理论、DS证据理论、DSmT不确定性推理知识,分析了通信目标参数的特性,提出了隶属函数的选择方法。针对传统DS证据理论和DSmT的缺陷,提出了基于隶属度函数的自适应融合算法。算例分析结果表明,本文算法计算简单、收敛速度快,在任何一种冲突情况下,都能够得到很好的识别结果。
猜你喜欢
北京航空航天大学学报(2022年5期)2022-06-06
环球时报(2022-04-16)2022-04-16
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
幼儿智力世界(2016年6期)2016-05-14
理科考试研究·高中(2016年9期)2016-05-14
祝你幸福·知心(2016年3期)2016-03-29
小雪花·初中高分作文(2015年10期)2015-10-24
人间(2015年21期)2015-03-11
浙江人大(2014年6期)2014-03-20
