
改进的YOLOv3红外视频图像行人检测算法
2018-10-08 06:07王殿伟何衍辉李大湘许志杰
西安邮电大学学报 2018年4期
王殿伟,何衍辉,李大湘,刘 颖,许志杰,王 晶
(1.电子信息现场勘验应用技术公安部重点实验室,陕西西安710121;2.西安邮电大学通信与信息工程学院,陕西西安710121;3.哈德斯菲尔德大学计算机与工程学院,英国哈德斯菲尔德,HD1 3DH)
行人检测是指从输入的视频或图像序列中判 断是否包含行人,并快速准确地判断出行人位置。目前各类可见光成像设备在光照不足、光照不均匀等条件下获取的视频图像降质严重,所蕴含的许多特征被覆盖或模糊,使得行人检测变得非常困难[1]。而利用红外成像设备获取的视频图像基本不受光照条件的影响,能够在完全黑暗以及不均匀光照等场景中获取到清晰的视频,为行人检测处理提供了良好的数据来源。因此,基于红外视频图像的行人检测技术对于军事侦察、汽车辅助驾驶系统与智能监控系统等领域具有重要意义。
目前,常用的红外行人检测技术主要分为基于特征分类的方法和基于深度学习的方法两大类。基于特征分类的方法依赖人工设计特征提取器,并利用提取的特征来训练分类器进行行人检测,如基于梯度直方图(histogram of oriented gradient,HOG)和支持向量机(support vector machine,SVM)的实时行人检测系统[2]。通过对行人纹理特征提取,虽然进一步提高了检测效率,但人工设计的行人特征泛化性差,运算复杂度高,限制了实际应用[3]。基于深度学习的方法需要预先建立一个图像训练库作为学习模型[4],并利用卷积神经网络从图像像素中学习行人特征,通过特征训练得到行人检测模型,达到行人检测的目的,这类方法主要有深度卷积神经网络学习法、局域卷积神经网络学习法和端到端学习法等。基于深度卷积神经网络的学习方法不需要人为选择行人特征,但这种方法针对不同场景检测需要单独训练模型[5]。基于区域卷积神经网络的学习方法将特征提取和分类融合进一个分类框架,提高了训练模型的速度和行人检测的准确率,但是该方法由于加入了SVM的训练而变得繁琐[6]。基于深度学习的端到端(single shot multibox detector,SSD)算法[7]可以解决在特征提取过程种由于图像像素过多导致的维度灾难问题,但SSD对小尺寸和模糊目标的检测效果较差,且检测速度较慢。端到端的学习方法(you only look once,YOLO)[8]在检测速度上远远超过 SSD算法,但是YOLO在检测相互重叠或者相邻很近的目标时存在漏检率过高的问题,且泛化能力偏弱。
针对上述问题,YOLO的改进算法YOLOv2和YOLOv3[9-10]先后被提出,虽然增强了YOLO的泛化能力,进一步提高了检测速度,但是在速度和准确率上综合表现最好的YOLOv3也无法精准定位红外视频图像中的行人目标,且在检测分辨率不同的输入图像时,目标识别率较低,尤其是单尺度YOLO模型在行人检测中的鲁棒性较差。因此,本文提出一种改进的YOLOv3红外视频图像行人检测算法。根据行人呈现高宽比固定的特点,通过聚类分析得到初始候选框anchor的个数及宽高比维度,然后调整网络预训练输入图像分辨率,并进行多尺度训练,最后将改进的YOLOv3在CVC-09数据集上进行测试。
1 YOLOv3算法
YOLOv3参考SSD和ResNet网络结构,设计了分类网络基础模型 Darknet-53[11]。Darknet-53兼顾网络复杂度与检测准确率,与常用的目标检测特征提取网络VGG-16相比降低了模型运算量[12]。
Darknet-53 与 Darknet-19、Resnet-101、Resnet-152的性能对比如表1所示。
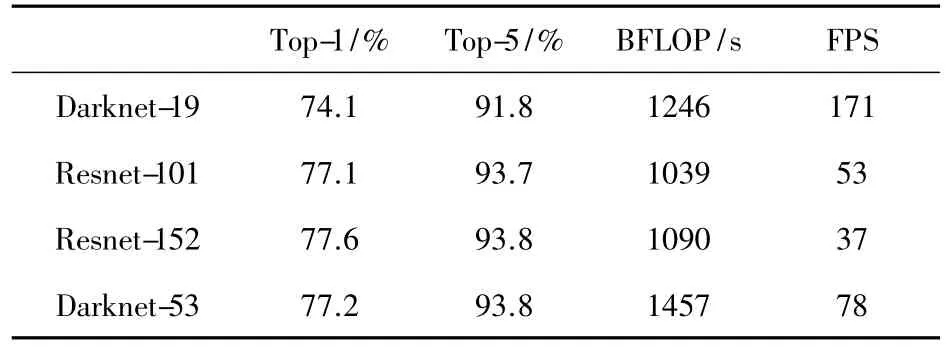
表1 Darknet-53与Darknet-19、Resnet的性能对比表
由表1可以看出,Darknet-53在Top-1和Top-5中的准确率分别为77.2%和93.8%,高于 Darknet-19;浮点运算速度为1 457次/s,高于 Darknet-19、Resnet-101和Resnet-152;每秒可检测78帧图像,高于Resnet-101和Resnet-152,可以达到实时检测。
2 改进的YOLOv3红外行人检测算法
为了使YOLOv3适用于红外视频图像中的行人检测,主要进行3个方面的改进。
(1)对红外图像数据集的目标候选框进行维度聚类分析,选择最优 anchor个数。YOLOv3的anchor个数和维度是由VOC 20类和COCO 80类数据集聚类得到,不适用于红外行人检测。在做红外行人检测时,无论行人处于什么样背景,姿态怎么变化,行人在图片中的长宽比始终是一个相对固定的值,呈现瘦高的框,因此需要对行人候选框进行聚类分析,重新确定anchor个数和宽高维度。
(2)调整分类网络预训练过程,使用不同分辨率的红外图像作为网络输入,用VOC数据集进行模型的预训练。使用不同分辨率的红外图像作为分类数据集,可以取得比较明显的微调效果。
(3)网络迭代过程中,随机改变输入图像的尺寸,进行多尺度网络训练,使模型对不同尺寸图像的检测具有鲁棒性。
2.1 目标框维度聚类
YOLOv3引入了anchor,anchor是一组宽高固定的初始候选框,它的个数由人工设定,其设定的好坏将影响目标检测的精度和速度。在训练网络时,随着迭代次数增加,候选框的参数也在不断调整以接近真实框。利用k均值聚类算法(k-means)[13]对目标框作聚类分析,网络会根据行人标注目标框的特点,学习行人特征,找到统计规律,最终以k为anchor的个数。k-means聚类分析使用欧式距离,意味着较大框会比较小框产生更多的错误,因此YOLOv3采用重叠度(intersection over union,IOU),即候选框与真实框的交集除以并集,消除了候选框所带来的误差。代替欧式距离的最终距离函数为
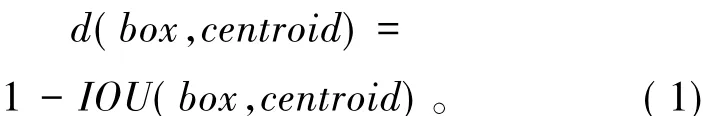
聚类目标函数为

式中,box为候选框,truth为目标真实框,k为anchor的个数。目标函数变化曲线如图1所示,随着k值增大,目标函数变化越来越缓慢,变化线的拐点可以认为是最佳的anchor个数。当k值大于4时,曲线变得平缓,因此选择k值为4,即anchor的个数为4。
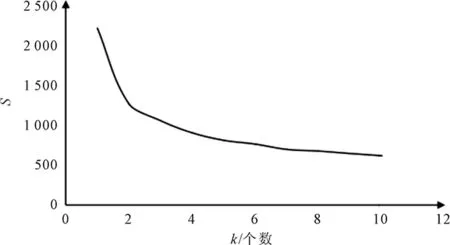
图1 目标函数变化曲线
同时可得红外行人真实框的聚类结果,如表2所示,选择k为4时的候选框作为初始候选框。

表2 红外行人真实聚类框

0.554,1.906 0.498,1.732 1.663,6.262 2.294,8.646 1.337,4.986 2.096,7.631 1.300,4.835 0.435,1.628 0.886,2.982 0.484,1.704 0.968,3.273 2.273,8.199 0.659,2.083 1.351,5.194
2.2 分类网络预训练
分类网络预训练可以提高网络提取特征的能力和速度,然而由于Darknet-53最后一层全连接层的限制,输入图像被调整为固定分辨率,与实际检测情况有较大差距。针对输入图像大小固定的不足,进行如下改进。
(1)采用VOC 20类和COCO 80类数据集对Darknet-53网络进行预训练。
(2)使用低分辨率(320 pixel×320 pixel)的已标注红外图像数据集微调Darknet-53,使网络先适应红外图像中的行人特征。
(3)低分辨率输入网络微调完成后,在高分辨率(512 pixel×512 pixel)的红外图像数据集上进行迭代,让网络逐层调整权重以适应高分辨率红外图像行人特征。
2.3 多尺度检测训练
YOLOv3包含卷积层和池化层,可以在训练过程中随机改变输入图像的尺寸,用多尺度输入的方法训练检测网络模型,使模型对不同尺度的红外图像检测具有鲁棒性。模型池化层共有32个可训练参数,下采样因子为32,因此训练过程中随机改变的图像的尺寸为32的倍数,最小为320 pixel×320 pixel,最大为 608 pixel×608 pixel。
多尺度检测训练能让模型适应不同尺度的输入图像,相较于单一尺度检测,多尺度检测对高分辨率输入图像检测准确率更高。
3 网络训练
以开源深度学习框架Darknet为基础,改进的YOLOv3网络结构为模型,结合维度聚类分析、网络预训练和多尺度训练模型的方法,训练红外图像行人检测器。为了加快训练速度和防止过拟合,网络参数中的冲量常数设置为0.9,权值衰减系数为0.005,初始学习率设定为0.001,并采用多分步策略学习。
分类网络预训练结束后,多尺度检测训练需要从大量样本中学习红外行人特征,若样本集不具有代表性,很难选择出好的特征。因此,先以混合了VOC、COCO中的行人图像和CVC-09中的红外行人图像数据作为第一轮训练集,粗调网络模型。接着将CVC-09红外图像序列作为多尺度检测训练集和测试集,精调网络。
CVC-09红外行人数据集分为训练集和测试集两部分,训练集包含2 200张正样本图像和1 002张负样本图像,正样本中含有5 990人。测试集包含2 884张正样本图像,含5 081个行人。CVC-09拍摄的数据均为红外图像,且存在背景复杂、行人互相遮挡等情况,适合作为红外行人数据集。
4 实验结果及分析
4.1 实验配置与训练结果
实验软硬件配置如表3所示。
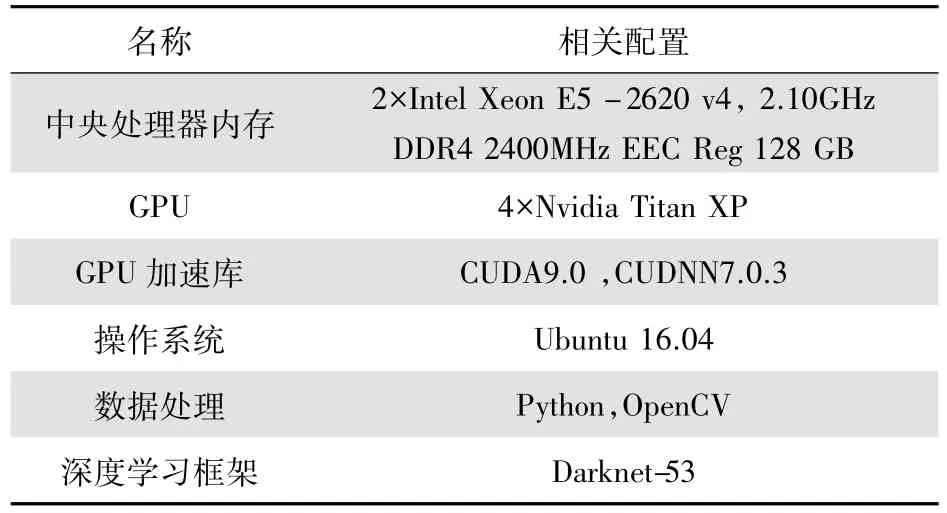
表3 软硬件配置
图2为网络训练过程中损失值的收敛曲线,横坐标表示迭代次数,最大迭代为50 000次。当网络迭代超过4万次时,各参数变化基本稳定,从图2中可以看出,最后损失值下降到约0.12。从这个参数的收敛情况来看,网络训练结果比较理想。

图2 损失值函数曲线
4.2 性能对比
4.2.1 候选框生成方案对比
对数据集中的目标框进行k-means聚类分析,得到最优 anchor参数,与 Faster-rcnn[14]、YOLOv3 的候选框生成方案对比,结果如表4所示,改进的YOLOv3最优候选框数量少,减小了运算量,并且保证了较高的平均重叠率。

表4 候选框生成方案对比表
4.2.2 分类网络预训练方法对比
根据分类网络预训练的3个步骤,调整不同阶段预训练网络的输入图像分辨率,得到分类网络预训练方法对比结果如表5。由表5可得,多分辨率微调后的分类网络相较于微调前,检测的平均准确率由60%提高到了82%,提高了网络的特征提取能力。

表5 分类网络预训练方法对比
4.2.3 多尺度网络与单尺度网络的性能对比
多尺度检测训练所得的模型对不同尺度的输入图像有更强的适应性,通过对不同尺寸的红外图像做行人检测,得到多尺度网络与单一尺度网络的性能对比,如表6所示,其中单尺度网络是由所有输入尺寸为416 pixel×416 pixel的红外图像数据集训练所得的模型。由表6可得,当检测图像分辨率变大时,两个网络的检测准确率都随之提高,相比同一尺寸输入图像而言,多尺度网络检测效果更好。
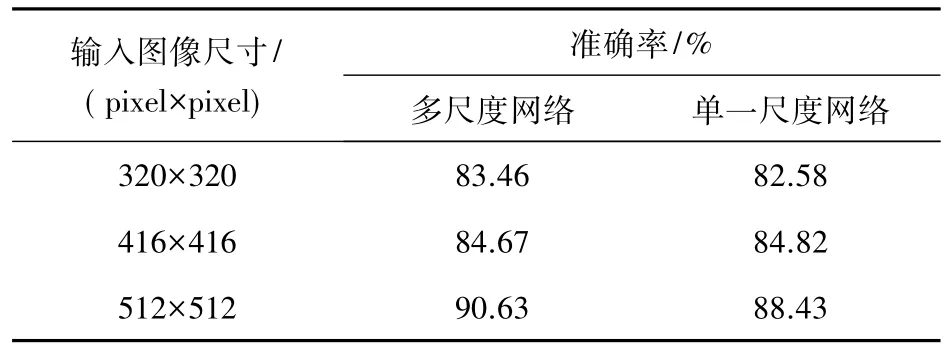
表6 多尺度与单一尺度网络性能对比表
4.2.4 检测验证集
用改进的YOLOv3网络检测红外行人目标,以测试集的样本验证训练模型的检测效果,对比Faster-rcnn和YOLOv3算法,结果如图3所示。由图3可得,经过改进后的YOLOv3在红外视频图像上的检测准确率超过90%,检测效果有明显提升。

图3 各检测方法测试结果对比
部分检测结果如图4所示,可以发现,在红外行人图像序列中,改进后的YOLOv3检测器可以较为精确地定位行人目标。

图4 改进的YOLOv3检测效果
YOLOv3和改进的YOLOv3检测效果对比如图5所示,可以发现因行人的非刚体特性,比较容易发生重叠或遮挡,而改进后的网络可以较好地将重叠部分的行人目标检测出来。同时,在对存在较多模糊的行人图像进行检测时,相较于YOLOv3,改进的YOLOv3网络能够同时检测到更多目标,降低了漏检率。

图5 红外行人检测效果对比
5 结语
通过对红外行人目标重新做维度聚类分析、调整网络预训练过程、多尺度训练模型的方法,将改进的YOLOv3目标检测算法迁移到红外行人检测。以CVC-09红外行人数据集为实验数据,对比Fasterrcnn和 YOLOv3算法,实验结果表明,改进的YOLOv3算法在红外行人检测中的准确率高达90.63%,明显优于Faster-rcnn和YOLOv3算法,且改进后的网络能够同时检测到更多目标,降低了漏检率。
猜你喜欢
光学精密工程(2022年13期)2022-08-02
环球时报(2022-05-23)2022-05-23
计算机工程与应用(2022年1期)2022-01-22
金桥(2021年4期)2021-05-21
意林(2021年5期)2021-04-18
计算机技术与发展(2020年2期)2020-04-15
电子制作(2019年7期)2019-04-25
电子制作(2019年7期)2019-04-25
扬子江(2019年1期)2019-03-08
火力与指挥控制(2018年3期)2018-04-19
