
一种有损压缩车牌图像重建算法
2018-10-08 06:07毕萍,杨洋,刘颖
西安邮电大学学报 2018年4期
毕 萍,杨 洋,刘 颖
(1.电子信息现场勘验应用技术公安部重点实验室,陕西西安710121;2.陕西省无线通信与信息处理技术国际合作研究中心,陕西西安710121;3.西安邮电大学图像与信息处理研究所,陕西西安710121;4.西安邮电大学通信与信息工程学院,陕西西安710121)
有损压缩(Lossy compression)是一种使用不精确近似来表示编码内容的数据编码方法[1]。在科技信息爆炸的时代,采用有损压缩格式存储数据可以节省带宽和存储空间。安防监控领域的图像多为有损压缩格式。图像的有损压缩容易产生方块伪影,不仅降低了车牌图像的视觉质量,还严重影响以压缩图像作为输入的后续图像处理,例如目标检测[2]、目标识别[3]和图像检索[4]等。
车牌数据均采用JPEG压缩处理。JPEG压缩指将图像分割为8×8像素块,并在每个块上分别应用块离散余弦变换(DCT),然后将量化应用于DCT系数,以节省存储空间。当每个块被编码而不考虑与相邻块的相关性时,会产生块效应,导致8×8边界处的不连续性。由于高频分量的粗量化,图像的边缘易发生振铃效应,进而高频成分可能丢失,造成图像模糊现象。
有多种方法可以应对各种压缩伪影。在空域中,设计不同类型的滤波器[5-7]自适应地处理特定区域中的块效应,其方法是沿着块边界进行滤波,以减少块效应。但该类方法不能获得图像锐利的边缘,使得纹理过于平滑。Liew[8]和 Foi[9]提出的算法主要消除振铃伪影,其方法是使用阈值自适应小波变换和形状自适应DCT变换去除伪影,这类方法会产生模糊的输出结果。Jung[10]提出了基于稀疏表示的压缩重建方法,可以获得锐化的输出图像,但会伴有边缘噪声和不自然的平滑区域。
如果将图像压缩视为一种失真,那么其重建算法可以采用凸集投影的方法(POCS)[11]、求解地图问题(FE)[10]、基于稀疏编码的方法[12]和基于回归树场的方法(RTF)[13]。RTF将 SA-DCT的结果作为基础和产生图像重建与回归树场模型。Dong[1]将多层卷积神经网络用于图像压缩重建,取得了非常好的效果。
深度学习可用于图像重建[14-15]。Dong等人提出的SRCNN[16]显示,卷积神经网络在图像重建中的作用,基于稀疏编码的图像恢复模型可以被视为一个深层卷积模型。Ledig[14]提出,随着网络层数加深,特征个数不断增加,特征尺寸不断减小,最后,可通过两个全连接层和最终的sigmoid激活函数获得重建图像。基于卷积神经网络的图像重建算法随着网络层数的加深,性能也逐渐增强,但是网络的复杂性也随之增加,训练的参数增多,目标函数很难快速收敛,致使训练的时间也较长。
本文将利用车牌图像的纹理稀疏性结构,并结合文献[1],给出一种通过增加网络宽度的方式来提高车牌图像重建质量的方法。
1 算法原理
算法的网络结构如图1所示。所给方法增加了第一层特征提取层的滤波器尺寸,并将其得到的特征图进行拼接融合,使得训练网络能够捕捉到车牌图像的更多特征。

图1 网络结构
网络主要由四个卷积层组成,网络仅在初始层采用多尺度提取特征,目的是保证网络特征多样化的同时,使得网络结构简单,训练的时间少。
网络的第一个卷积层为特征提取层,其得到输入图像的特征图可以表示为

其中 W11,W12,W13和 B11,B12,B13分别表示滤波器的权重和偏置,“*”表示卷积运算,“”表示拼接。
网络的第二个卷积层为特征增强层,第三个卷积层为非线性映射层,均可以表示为

其中Wi对应于尺寸为fi×fi的ni个滤波器,Bi是ni维矢量。
网络的第四个卷积层为重建层,可表示为
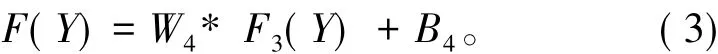
其中W4对应于尺寸为f4×f4的1个滤波器,B4是一个标量。

损失函数采用的是欧氏损失,其表达式为其中,n是训练图像个数,Yi是第插值后的LR图像块,Xi是与Yi对应的第i块HR图像块,F(Yi;Θ)是在Θ网络参数条件下重建后的HR图像块。
2 实验结果及分析
2.1 实验结果
实验环境为 linux14.04,内存4 G,GeForce GTX 950。实验数据为986张车牌图像。其中10张用于测试(图2),976张用于训练(部分见图3)。测试集选取了不同颜色和不同形状的车牌图像。

图2 测试数据集

图3 训练数据集
如图1所示实验网络的参数设置为分别为:32个9×9的滤波器,32个 11×11的滤波器,32个13×13的滤波器;然后经过特征融合层进行特征融合,迭代200万次,其测试结果如表1所示。实验结果表明,测试10张车牌数据,其PSNR的平均值为26.027 3 dB,SSIM 的平均值为 0.929 5。
2.2 网络参数调整
2.2.1 不同尺寸融合
为了更进一步验证融合特征的多样性,改变9-11-13三种不同尺寸为7-9-11三种不同尺寸进行图像特征融合。迭代200万次,测试结果如表2所示。
实验结果表明,测试10张车牌数据,其PSNR的平均值为 26.814 7 dB,SSIM 的平均值为0.928 5。实验数据表明,7-9-11融合的测试结果与9-11-13融合的结果相比,PSNR提升了0.8 dB,SSIM几乎没有变化。
2.2.2 不同压缩系数重建
以上采用的JEPG压缩系数q为10。另外分别设置q=20和q=30,对7-9-11三种不同尺寸进行图像特征融合。迭代200万次,测试结果如表3和表4所示。
测试10张车牌数据,q=20,其PSNR的平均值为29.897 0 dB,SSIM 的平均值为0.962 3。q=30,其PSNR的平均值为32.335 9 dB,SSIM的平均值为0.971 4。实验数据表明,针对不同的压缩系数,车牌图像重建后的效果均有明显的提升。

表1 采用9-11-13三种不同尺寸且q=10时的测试结果

表2 采用7-9-11三种不同尺寸且q=10时的测试结果

表3 采用7-9-11三种不同尺寸且q=20时的测试结果

表4 采用7-9-11三种不同尺寸且q=30时的测试结果
相关实验结果如图4、图5和图6所示。

图4 q=10车牌图像重建结果(7-9-11)

图5 q=20车牌图像重建结果(7-9-11)

图6 q=30车牌图像重建结果(7-9-11)
2.3 实验结论
实验通过增加网络的宽度,把不同尺寸的特征进行融合,增加训练网络特征的多样性,通过不同的实验参数调整、训练、测试,找出网络的最佳参数。通过改变压缩系数q,训练和测试不同系数下JPEG压缩后车牌图像的重建效果。实验表明通过7-9-11的特征融合伪影的去除效果最佳。
3 结语
深度学习是图像领域的研究热点问题,其应用范围比较广泛。随着其网络的发展,网络的深度越来越深,出现了几百层甚至及几千层的网络。车牌图像作为智能交通和公安刑侦的重要数据,通过重建车牌图像是一个值得研究的热点问题。本文车牌图像重建的网络深度还不够深,训练迭代的次数还不够大,未来应该同时增加网络的深度和宽度,增加网络结构的复杂性,进一步提升车牌图像的重建质量。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年12期)2019-07-16
电子制作(2019年11期)2019-07-04
电子制作(2018年16期)2018-09-26
北京航空航天大学学报(2018年1期)2018-04-20
电子制作(2018年1期)2018-04-04
小猕猴智力画刊(2017年5期)2017-05-25
电子制作(2017年22期)2017-02-02
火控雷达技术(2016年2期)2016-02-06
